The content comes from my impression notes , Simply summarize and post to blog , For your reference when you need to use .
Original statement : author :Arnold.zhao Blog Garden address :https://www.cnblogs.com/zh94
Catalog :
- ElasticSearch Clustering features
- es Deployment installation , There's a hole to tread on
- ElasticSearch CRUD operation
- ElasticSearch Search operation
- ElasticSearch Word segmentation is analyzer
ElasticSearch, Clustering features
ES The cluster of is based on Master Slave Architecturally
After a node in the cluster is elected as the master node ,
It will be responsible for managing all changes within the cluster , For example, increase 、 Delete index , Or add 、 Delete nodes, etc ;
The master node does not need to involve document level changes and search operations , So when the cluster has only one master node , It won't be a bottleneck even if traffic increases . Any node can become the master node ;
As the user , We can send the request to Any node in the cluster , Including the master node . Each node knows where any document is located , And we can forward our requests directly to the node that stores the documents we need . No matter which node we send the request to , It is responsible for collecting data back from the individual nodes that contain the documents we need , And returns the final result to the client .
Fragmentation
https://www.elastic.co/guide/cn/elasticsearch/guide/current/_add-an-index.html
https://www.elastic.co/guide/cn/elasticsearch/guide/current/routing-value.html#routing-value
Elasticsearch It is the use of fragmentation to distribute data to all parts of the cluster . Sharding is a container for data , The document is saved in slices , Sharding is then distributed among the nodes in the cluster . As your cluster scales up or down , Elasticsearch Shards are automatically migrated between nodes , Keep the data evenly distributed throughout the cluster ;
A slice can be Lord Slice or copy Fragmentation . Any document in the index belongs to a main fragment , So the number of primary partitions determines the maximum amount of data that an index can hold .
Technically , A main segment can be stored at the maximum Integer.MAX_VALUE - 128 A document , But the actual maximum also needs to refer to your usage scenario : Including the hardware you use , The size and complexity of the document , How to index and query documents and how long you expect to respond .
A replica shard is just a copy of a master shard . Replica fragmentation is used as redundant backup to protect data from loss in case of hardware failure , And provide services for reading operations such as searching and returning documents .
The number of primary partitions is determined when the index is created , But the number of copies can be changed at any time .
notes : When creating an index, you need to determine the number of primary partitions , Because once the index is created , The number of primary tiles cannot be changed , Only dynamic changes to the number of copies fragmentation , However, the number of replica fragments can only provide relevant services for reading operations such as searching and returning documents , So increasing the number of copies can increase the availability of cluster read operations ; But for the storage of data in the index , Or it can only be saved on the main fragment , therefore , Reasonably determine the value of the main slice , It is necessary and beneficial for the subsequent cluster expansion ;
Routing policy when creating data
When indexing a document , The document is stored in a main shard . Elasticsearch How do you know where to put a document ? When we create the document , How does it decide that this document should be stored in shards 1 Or fragmentation 2 What about China?
First of all, it's not going to be random , Otherwise we won't know where to look when we get the document in the future . actually , This process is determined by the following formula :shard = hash(routing) % number_of_primary_shards
routing It's a variable value , The default is documentation _ id , It can also be set to a custom value . routing adopt hash The function generates a number , And then this number over here number_of_primary_shards ( Number of main slices ) Get back remainder . This distribution 0 To number_of_primary_shards-1 The remainder between , That's where we're looking for the shard of the document ;
This explains why we need to determine the number of primary slices when we create the index. Right And it never changes that amount : Because if the quantity changes , Then all previous routing values will be invalid , The document was never found .
So how to better design our ES The number of primary partitions in the cluster , To ensure that it can support the follow-up business ?
For details, please refer to : Data modeling - Expansion design chapter
https://www.elastic.co/guide/cn/elasticsearch/guide/current/scale.html
All documents API( get 、 index 、 delete 、 bulk 、 update as well as mget ) All accept one name routing Routing parameters , With this parameter we can customize the document - to - shard mapping . A custom routing parameter can be used to ensure all relevant documentation —— For example, all documents belonging to the same user —— Are stored in the same shard . Except routing is not supported when index creation is performed , Other data import , Search and other operations can be specified routing operations ; Index creation must be done by the master node
Original statement : author :Arnold.zhao Blog Garden address :https://www.cnblogs.com/zh94
ES Deployment installation , There's a hole to tread on
The direct use here is elasticsearch-7.3.2 Version of , So the tip :Elasticsearch Future versions of will need Java 11; Your Java Version from [/opt/package/jdk1.8.0_241/jre] Not meeting this requirement , The local environment variable pairs are commented out here JDK Mapping , Use it directly es Self contained java Start it up
future versions of Elasticsearch will require Java 11; your Java version from [/opt/package/jdk1.8.0_241/jre] does not meet this requirement
As shown below : For safety es Direct use of... Is not supported root User start
[2020-06-15T10:24:11,746][WARN ][o.e.b.ElasticsearchUncaughtExceptionHandler] [VM_0_5_centos] uncaught exception in thread [main]
org.elasticsearch.bootstrap.StartupException: java.lang.RuntimeException: can not run elasticsearch as root
Create a new one here elsearch The user starts
newly build elsearch User group as well as elsearch user
groupadd elsearch
useradd elsearch -g elsearch -p elasticsearch
The corresponding elasticsearch-7.3.2 The catalog is authorized to elsearch
chown -R elsearch:elsearch /opt/shengheApp/elasticsearch/elasticsearch-7.3.2
Switch users es Start of
su elsearch # Switch accounts
cd elasticsearch/bin # Get into your elasticsearch In the catalog bin Catalog
./elasticsearch
# Appoint jvm Memory boot ,
ES_JAVA_OPTS="-Xms512m" ./bin/elasticsearch
Background start mode
./elasticsearch -d
modify ES Configure for all IP All accessible ,network.host It is amended as follows 0.0.0.0
network.host: 0.0.0.0
After revising IP After configuration item , Startup will be abnormal , The tips are as follows :
[VM_0_5_centos] publish_address {172.17.0.5:9300}, bound_addresses {[::]:9300}
[2020-06-15T10:46:53,894][INFO ][o.e.b.BootstrapChecks ] [VM_0_5_centos] bound or publishing to a non-loopback address, enforcing bootstrap checks
ERROR: [3] bootstrap checks failed
[1]: initial heap size [536870912] not equal to maximum heap size [1073741824]; this can cause resize pauses and prevents mlockall from locking the entire heap
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
[3]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
The solution is as follows :
Solve the first warning :
Because I don't have enough memory on my computer, when I start , Directly designated JVM Parameters are activated :ES_JAVA_OPTS="-Xms512m" ./bin/elasticsearch
however :bin/elasticsearch It will load when it starts config/jvm.options Under the jvm To configure , because jvm.options Next Xms and Xmx Configure to 1g, So the prompt conflicts at the start , Initial heap size 512M And the maximum heap size 1g, Mismatch ; The solution is , Change the command to... When you start : ES_JAVA_OPTS="-Xms512m -Xmx512M" ./bin/elasticsearch , Or just modify it jvm.options in Xms and Xmx Size , And then directly ./bin/elasticsearch It's OK to start
Solve the second warning :
Temporarily raised vm.max_map_count Size , This operation requires root jurisdiction :
sysctl -w vm.max_map_count=262144
sysctl -a|grep vm.max_map_count # After setting, you can check whether the setting is successful through the command
Permanent modification vm.max_map_count Size :
vi /etc/sysctl.conf Add the following configuration : vm.max_map_count=655360 And execute the command : sysctl -p then , Restart elasticsearch, You can start successfully .
Solve the third warning :
Cluster node problem , We will only start one node test now , So modify the name of the current node as :node-1, Then configure cluster.initial_master_nodes Initialize the node as its own node-1 The node can be ;
To configure elasticsearch.yml The documents are as follows :
node.name: node-1
cluster.initial_master_nodes: ["node-1"]
And then restart es that will do
Original statement : author :Arnold.zhao Blog Garden address :https://www.cnblogs.com/zh94
ElasticSearch,CRUD operation
The index is limited by the file system . It can only be lowercase , Cannot start with an underline . At the same time, the following rules should be observed :
Can't include , /, *, ?, ", <, >, |, Space , comma , #
7.0 You can use colons before the release :, But it is not recommended to use and use in 7.0 No longer supported after version
Can't use these characters -, _, + start
Can't include . or …
The length cannot exceed 255 Characters
These naming restrictions are due to when Elasticsearch Use the index name as the directory name on the disk , These names must conform to the conventions of different operating systems .
I suspect that these restrictions may be lifted in the future , Because we use uuid The associated index is placed on disk , Instead of using the index name .
type
Type names can include except null Any character of , Cannot start with a dash .7.0 Type is no longer supported after version , The default is _doc.
be based on ES7.0+ edition
1、
Add a document
PUT twitter/_doc/1
{
"user": "GB",
"uid": 1,
"city": "Beijing",
"province": "Beijing",
"country": "China"
}
Above , Create a twitter The index of , And create one called _doc Of type, And insert a document 1,( stay ES7 in , One index There can only be one type, If you create multiple type You will be prompted for an exception , By default, because only one can be created type, So by default it's called _doc that will do ;)
The newly inserted data will not participate in the search in real time , You can call the following interface , send ES Make a strong one refersh operation ;( In addition, we are creating index You can also set referch The cycle of , The default is 1, That is to refresh the new data into the index every second ,)
2、
Add data and refresh it to the index in real time
PUT twitter/_doc/1?refresh=true
{
"user": "GB",
"uid": 1,
"city": "Beijing",
"province": "Beijing",
"country": "China"
}
Execute by default ( Above 1 Of )dsl sentence , The first step is to determine whether the inserted document specifies id, If not specified id, By default, the system will generate a unique id, We have designated id by (1), So insert es when , It will be in accordance with our designated id Insert ,
also , If it's time to Id Is in es That already exists in , Then a second judgment will be made at this time , Check to see if... Is specified when inserting _version, If you do not specify _version, So for the existing doc data ,_version It will be incremented , And update and cover the document , If the insertion specifies _version, Then judge what is currently specified _version Of existing documents _version Whether it is equal or not , Equality covers , If it is not equal, the insertion fails ( Be careful : This is similar to an optimistic lock operation , If there is a similar scenario of data insertion through this _version You can implement an optimistic lock operation );
besides , When inserting data , If you don't want to make changes , Then you can use
Use create type , Indicates that only new is added , Do not modify data when it exists
PUT twitter/_doc/1?optype=create
perhaps
PUT twitter/_create/1
Both of these syntax indicate that the use type is create To create a document , If the current document already exists , Direct error reporting , There will be no overlay updates ;
optype There are two types of ,index and create, We use it by default PUT twitter/_doc/1 When creating data , In fact, it's equivalent to PUT twitter/_doc/1?optype=index
Use post The new document
on top , Specifically assigned a ID. In fact, in practical applications , This is not necessary . contrary , When we assign a ID when , This is checked during data import ID Does the document exist for , If it's already there , So update the version . If it doesn't exist , Just create a new document . If we don't specify the document's ID, Turn to let Elasticsearch Automatically generate one for us ID, It's faster . under these circumstances , We have to use POST, instead of PUT
Use POST The request does not specify ID when ,es Auto corresponding generation ID
POST twitter/_doc
{
"user": "GB",
"uid": 1,
"city": "Beijing",
"province": "Beijing",
"country": "China"
}
GET data
obtain twitter The index document is 1 The data of
GET twitter/_doc/1
obtain twitter The index document is 1 The data of , And only return this document's _source part
GET twitter/_doc/1/_source
Get only source Part of the fields
GET twitter/_doc/1?_source=city,age,province
_MGET data
Get data from multiple documents
GET _mget
{
"docs": [
{
"_index": "twitter",
"_id": 1
},
{
"_index": "twitter",
"_id": 2
}
]
}
Get data from multiple documents , And only part of the field is returned
GET _mget
{
"docs": [
{
"_index": "twitter",
"_id": 1,
"_source":["age", "city"]
},
{
"_index": "twitter",
"_id": 2,
"_source":["province", "address"]
}
]
}
Direct access to id by 1 and 2 The data of ,( Simplified way of writing )
GET twitter/_doc/_mget
{
"ids": ["1", "2"]
}
Modify the document ( Full revision , Specify field modification , Query first and then modify )
Use PUT By default, the data will be updated and added , This is also mentioned above , But use PUT The way to do it is to update it all , If those fields are not specified , Will be updated to a null value ;
PUT twitter/_doc/1
{
"user": "GB",
"uid": 1,
"city": " Beijing ",
"province": " Beijing ",
"country": " China ",
"location":{
"lat":"29.084661",
"lon":"111.335210"
}
}
So you can use POST The way to update , Just list the fields to be modified ;
POST twitter/_update/1
{
"doc": {
"city": " Chengdu ",
"province": " sichuan "
}
}
Query first and then update _update_by_query
POST twitter/_update_by_query
{
"query": {
"match": {
"user": "GB"
}
},
"script": {
"source": "ctx._source.city = params.city;ctx._source.province = params.province;ctx._source.country = params.country",
"lang": "painless",
"params": {
"city": " Shanghai ",
"province": " Shanghai ",
"country": " China "
}
}
}
Modify a document , If the current document does not exist, add the document
doc_as_upsert Parameter check has given ID Whether the document for already exists , And will provide doc Merge with existing documents . If there is no given ID Documents , A new document with the content of the given document is inserted .
The following example uses doc_as_upsert Merge into ID by 3 In the document , Or insert a new document if it doesn't exist :
POST /catalog/_update/3
{
"doc": {
"author": "Albert Paro",
"title": "Elasticsearch 5.0 Cookbook",
"description": "Elasticsearch 5.0 Cookbook Third Edition",
"price": "54.99"
},
"doc_as_upsert": true
}
Check if the document exists
HEAD twitter/_doc/1
Delete a document
DELETE twitter/_doc/1
Search for and delete _delete_by_query
POST twitter/_delete_by_query
{
"query": {
"match": {
"city": " Shanghai "
}
}
}
_bulk The batch operation
Use _bulk You can perform bulk data insertion , Batch data updates , Batch data deletion ,
Batch data insertion , Use index type , It means that being is updating , If it doesn't exist, add
POST _bulk
{ "index" : { "_index" : "twitter", "_id": 1} }
{"user":" Double elm - Zhang San ","message":" It's a nice day today , Go out and go around ","uid":2,"age":20,"city":" Beijing ","province":" Beijing ","country":" China ","address":" Haidian District, Beijing, China ","location":{"lat":"39.970718","lon":"116.325747"}}
{ "index" : { "_index" : "twitter", "_id": 2 }}
{"user":" Dongcheng District - Lao Liu ","message":" set out , The next stop is Yunnan !","uid":3,"age":30,"city":" Beijing ","province":" Beijing ","country":" China ","address":" Taiji factory, Dongcheng District, Beijing, China 3 Number ","location":{"lat":"39.904313","lon":"116.412754"}}
Batch data insertion , Use create type ,id Insert if it doesn't exist , If there is, throw exception and do nothing
POST _bulk
{ "create" : { "_index" : "twitter", "_id": 1} }
{"user":" Double elm - Zhang San ","message":" It's a nice day today , Go out and go around ","uid":2,"age":20,"city":" Beijing ","province":" Beijing ","country":" China ","address":" Haidian District, Beijing, China ","location":{"lat":"39.970718","lon":"116.325747"}}
Batch data deletion ,delete type
POST _bulk
{ "delete" : { "_index" : "twitter", "_id": 1 }}
Batch data update
POST _bulk
{ "update" : { "_index" : "twitter", "_id": 2 }}
{"doc": { "city": " Changsha "}}
System commands
see ES Information
GET /
Close index ( When the index is closed , Will prevent reading / Write operations )
POST twitter/_close
Open index
POST twitter/_open
Freeze index ( After freezing the index , The index will block writes )
POST twitter/_freeze
After the index freezes , Search with ignore_throttled=false Parameters to search
POST twitter/_search?ignore_throttled=false
Index unfreezing
POST twitter/_unfreeze
Original statement : author :Arnold.zhao Blog Garden address :https://www.cnblogs.com/zh94
ElasticSearch,Search operation
query Do a global search ,aggregation It can be used for global data statistics and analysis
Search all documents
Search for the cluster All under index, Default return 10 individual
GET /_search = GET /_all/_search
GET /_search?size=20
At the same time for multiple index To search
POST /index1,index2,index3/_search
For all with index Search for the index at the beginning , But exclude index3 Indexes
POST /index*,-index3/_search
Search only the index named twitter The index of
GET twitter/_search
After searching, only the specified fields are returned
Use _source To return only user, and city Field
GET twitter/_search
{
"_source": ["user", "city"],
"query": {
"match_all": {
}
}
}
Set up _source by false To return nothing _source Information
GET twitter/_search
{
"_source": false,
"query": {
"match": {
"user": " Zhang San "
}
}
}
Using wildcards means only return user* as well as location* The data of , But for *.lat Fields are not returned
GET twitter/_search
{
"_source": {
"includes": [
"user*",
"location*"
],
"excludes": [
"*.lat"
]
},
"query": {
"match_all": {}
}
}
Create return fields script_fields
When we want to get field May be in _source There is no time at all , Then we can use script field To generate these field;
GET twitter/_search
{
"query": {
"match_all": {}
},
"script_fields": {
"years_to_100": {
"script": {
"lang": "painless",
"source": "100-doc['age'].value"
}
},
"year_of_birth":{
"script": "2019 - doc['age'].value"
}
}
}
The return is :
"hits" : [
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"fields" : {
"years_to_100" : [
80
],
"year_of_birth" : [
1999
]
}
},
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"fields" : {
"years_to_100" : [
70
],
"year_of_birth" : [
1989
]
}
},
...
]
It must be noted that this use script For a large number of documents , May take up a lot of resources .
match and term Explain the difference between the two
term It's a perfect match , That is, the exact query , Before the search, the word segmentation will not be disassembled .
https://www.jianshu.com/p/d5583dff4157
While using match When searching , Will be the first word to search for word segmentation , After the disassembly, match it again ;
Create an index data structure mapping
The following demonstrations are based on the following structure ;
PUT twitter/_mapping
{
"properties": {
"address": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"age": {
"type": "long"
},
"city": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"country": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"location": {
"type": "geo_point"
},
"message": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"province": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"uid": {
"type": "long"
},
"user": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
Query data (Match query Search word segmentation matching )
Search for twitter Index user Field is “ Chaoyang District - Lao Jia ” The word ;( Be careful , Here we use match, That is, it will take our “ Chaoyang District - Lao Jia ” According to the default word breaker After segmentation, search and match )
GET twitter/_search
{
"query": {
"match": {
"user": " Chaoyang District - Lao Jia "
}
}
}
When we use the above match query When querying , The default action is OR The relationship between , Such as the above DSL Statement is actually equivalent to the following statement :
GET twitter/_search
{
"query": {
"match": {
"user": {
"query": " Chaoyang District - Lao Jia ",
"operator": "or"
}
}
}
}
default match query The operation of or The relationship between : Aforementioned dsl Statement is the query result of any document as long as it matches :
“ the ”,“ Yang ”,“ District ”,“ The old ” And “ Jia ” this 5 Any word in a word , Will be matched to ;
By default we specify the search word , If you don't specify a word breaker , That is, the default word breaker used , The default word segmentation device is used for Chinese word segmentation , It just takes the corresponding Chinese words one by one for word segmentation , So we use the above because match, Retrieved “ Chaoyang District - Lao Jia ” So the result of participle is “ the “ Yang ” District ”“ The old ” Jia ”; So as long as it's a document user There is any of these words in , It's going to be retrieved
Set the minimum number of words to match minimum_should_match
Use minimum_should_match To set at least the matching index words term, That is to say, in our search results :
At least match to :
“ the ”,“ Yang ”,“ District ”,“ The old ” And “ Jia this 5 Among them 3 Only one word can
GET twitter/_search
{
"query": {
"match": {
"user": {
"query": " Chaoyang District - Lao Jia ",
"operator": "or",
"minimum_should_match": 3
}
}
}
}
Change to and Relational match query
By default, our match query yes or The relationship between , This has been explained above , But we can also dynamically change it to and The relationship between , such as , As follows dsl sentence :
GET twitter/_search
{
"query": {
"match": {
"user": {
"query": " Chaoyang District - Lao Jia ",
"operator": "and"
}
}
}
}
Change to and After relationship , In other words, the result of every participle is and The relationship between , And our participle results
“ the ”,“ Yang ”,“ District ”,“ The old ”“ Jia ” Between these words is and Relationship , in other words , Our search results must contain these words , Can only be ;
This kind of writing , In fact and direct use term Very similar , Because use term Search terms for , They will not be used for word segmentation , The default is that it must match exactly , So for the above scenario , Use it directly term It will be more efficient , omitted match This step of participle , And the results are also the results of accurate matching ;
Multi_query( Match multiple fields )
In the above search , We all specifically point out one by one user Field to make a search query , But in practice , We may not know which field contains this keyword , So in this case, you can use multi_query To search ;
GET twitter/_search
{
"query": {
"multi_match": {
"query": " The rising sun ",
"fields": [
"user",
"address^3",
"message"
],
"type": "best_fields"
}
}
}
The above is for three at the same time fields: user,adress And message To search ,
At the same time address contain “ The rising sun ” The score of the document carried out 3 Times the weight of ;
The function of weighting is to calculate the value of similarity of returned results , It's better than this “address” the 3 Times the weight of , Now if it's address Contained in the “ At sunrise ” The corresponding returned results have the highest similarity , The higher the order of the corresponding ranking ;
By default, if you don't use order by In order to sort , They are all sorted according to the degree of photographic similarity ;
Prefix query( Match only prefixes )
Returns the document that contains a specific prefix in the provided field .( It just matches the prefix ,)
GET twitter/_search
{
"query": {
"prefix": {
"user": {
"value": " the "
}
}
}
}
Term query( Exactly match )
Term query Precise word matching in a given field , The search term will not be broken down before searching .
GET twitter/_search
{
"query": {
"term": {
"user.keyword": {
"value": " Chaoyang District - Lao Jia "
}
}
}
}
Term query It's exactly matching a word , If it's matching multiple words , It will not work , As shown below :
Inquire about “ Chaoyang District “ Space ” Lao Jia “ Because there are spaces , So by default, these are two words , So for the results of the search ,
It could be ineffective ( Not verified , It is to be verified whether the specific effect is true )
GET twitter/_search
{
"query": {
"term": {
"user.keyword": {
"value": " Chaoyang District Lao Jia "
}
}
}
}
Terms query( Multiple words match exactly at the same time )
therefore , For an exact match of two words , You should use terms
Use terms Match , By default, it matches exactly the corresponding words , And is OR The relationship between ; in other words : Just match “ Chaoyang District ” perhaps “ Lao Jia ” It's all matching ;
therefore , Use here term Solved the problem of multiple exact matching , But if it's for matching exactly to “ Chaoyang District Lao Jia ” In the context of such a word , Then use Terms It's also inappropriate , You need to use boot query Conduct must Of term and term That's right ;
So in fact, this is also a corresponding scene problem , If you enter this data according to “ Chaoyang District - Lao Jia ” If you don't enter it with a blank space , Then it will be much more convenient to query , But it's different query Inquire device , The corresponding application scenarios have their own advantages and disadvantages ;
GET twitter/_search
{
"query": {
"terms": {
"user.keyword": [
" Chaoyang District ",
" Lao Jia
]
}
}
}
city In our mapping There is a multi-field term . It is both text It's also keyword type . For one keyword Type of item , All characters in this entry are treated as a string . They're creating documents , There is no need for index.keyword Field is used for precise search ,aggregation And sort (sorting), So we also use it here term To match ;
bool query( Composite query )
A conforming query combines the above query methods , So as to form more complex query logic ,
bool query In general, the query format is :
must: Must match . Contribution counts ( Multiple term Between and Relationship )
must_not: Filter clause , Must not match , But no contribution is a score (and Relationship )
should: Selective match , Meet at least one . Contribution counts ( Multiple term Between or The relationship between )
filter: Filter clause , Must match , But no contribution is a score (filter Determine if it is included in the search results , And then I'll point out that )
POST _search
{
"query": {
"bool" : {
"must" : {
"term" : { "user" : "kimchy" }
},
"filter": {
"term" : { "tag" : "tech" }
},
"must_not" : {
"range" : {
"age" : { "gte" : 10, "lte" : 20 }
}
},
"should" : [
{ "term" : { "tag" : "wow" } },
{ "term" : { "tag" : "elasticsearch" } }
],
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}
Represents a query ,user Fields contain both Chaoyang District It also contains Lao Jia's words , Then go back
GET twitter/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"user": " Chaoyang District "
}
},
{
"match": {
"user": " Lao Jia "
}
}
]
}
}
}
following dsl It means ,age Must be 30 year , But if the document contains “Hanppy birthday”, The correlation will be higher , So the search results will be at the top of the list ;
GET twitter/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"age": "30"
}
}
],
"should": [
{
"match_phrase": {
"message": "Happy birthday"
}
}
]
}
}
}
If you are not using must,must_not as well as filter Under the circumstances , Use it directly should Match , It means or The relationship between ; One or more should There must be a match to have a search result ;
query range( Range queries )
Query age between 30 To 40 Years old document data
GET twitter/_search
{
"query": {
"range": {
"age": {
"gte": 30,
"lte": 40
}
}
}
}
Whether the query field exists (query exists)
If the document just city This field is not empty , Then it will be returned . conversely , If in a document city This field is empty , Then there will be no return .
GET twitter/_search
{
"query": {
"exists": {
"field": "city"
}
}
}
Matching phrase (query match_phrase)
query match_phrase All participles must appear in the document at the same time , At the same time, the position must be close to the same ,
Use slop 1 Express Happy and birthday In the past, it was possible to allow one word The difference between .
GET twitter/_search
{
"query": {
"match_phrase": {
"message": {
"query": "Happy birthday",
"slop": 1
}
}
},
"highlight": {
"fields": {
"message": {}
}
}
}
Profile API
Profile API It's a debugging tool . It adds details about the execution of each component in the search request . And it provides insight into why each request can be performed slowly .
GET twitter/_search
{
"profile": "true",
"query": {
"match": {
"city": " Beijing "
}
}
}
on top , We added "profile":"true" after , In addition to displaying the search results , It also shows profile Information about :
"profile" : {
"shards" : [
{
"id" : "[ZXGhn-90SISq1lePV3c1sA][twitter][0]",
"searches" : [
{
"query" : [
{
"type" : "BooleanQuery",
"description" : "city: north city: Beijing ",
"time_in_nanos" : 1390064,
"breakdown" : {
"set_min_competitive_score_count" : 0,
"match_count" : 5,
"shallow_advance_count" : 0,
"set_min_competitive_score" : 0,
"next_doc" : 31728,
"match" : 3337,
"next_doc_count" : 5,
"score_count" : 5,
"compute_max_score_count" : 0,
"compute_max_score" : 0,
"advance" : 22347,
"advance_count" : 1,
"score" : 16639,
"build_scorer_count" : 2,
"create_weight" : 342219,
"shallow_advance" : 0,
"create_weight_count" : 1,
"build_scorer" : 973775
},
"children" : [
{
"type" : "TermQuery",
"description" : "city: north ",
"time_in_nanos" : 107949,
"breakdown" : {
"set_min_competitive_score_count" : 0,
"match_count" : 0,
"shallow_advance_count" : 3,
"set_min_competitive_score" : 0,
"next_doc" : 0,
"match" : 0,
"next_doc_count" : 0,
"score_count" : 5,
"compute_max_score_count" : 3,
"compute_max_score" : 11465,
"advance" : 3477,
"advance_count" : 6,
"score" : 5793,
"build_scorer_count" : 3,
"create_weight" : 34781,
"shallow_advance" : 18176,
"create_weight_count" : 1,
"build_scorer" : 34236
}
},
{
"type" : "TermQuery",
"description" : "city: Beijing ",
"time_in_nanos" : 49929,
"breakdown" : {
"set_min_competitive_score_count" : 0,
"match_count" : 0,
"shallow_advance_count" : 3,
"set_min_competitive_score" : 0,
"next_doc" : 0,
"match" : 0,
"next_doc_count" : 0,
"score_count" : 5,
"compute_max_score_count" : 3,
"compute_max_score" : 5162,
"advance" : 15645,
"advance_count" : 6,
"score" : 3795,
"build_scorer_count" : 3,
"create_weight" : 13562,
"shallow_advance" : 1087,
"create_weight_count" : 1,
"build_scorer" : 10657
}
}
]
}
],
"rewrite_time" : 17930,
"collector" : [
{
"name" : "CancellableCollector",
"reason" : "search_cancelled",
"time_in_nanos" : 204082,
"children" : [
{
"name" : "SimpleTopScoreDocCollector",
"reason" : "search_top_hits",
"time_in_nanos" : 23347
}
]
}
]
}
],
"aggregations" : [ ]
}
]
}
We can see from the above that , This search is a search “ north ” And “ Beijing ”, Instead of searching Beijing as a whole . We can learn to use the Chinese word segmentation machine to search for word segmentation in future documents . Interested students can modify the above search to city.keyword Let's see .
filter Query and query Different queries :
https://blog.csdn.net/laoyang360/article/details/80468757
How to specify a word breaker when searching
How to specify the word breaker to use the field ,
How to adjust java rest client api Number of threads for , And the whole picture client api The capture of exception handling of , Timeout time, etc
es Cluster load mode of , node , Copy, etc , And the data recovery after the node is offline ( It is mainly after all nodes are dropped , How to recover data ? This should not be the point ) The other is , How to do es Cluster migration , For example, data from an existing cluster is migrated to another cluster , For example, when upgrading , These can be found in elastic About es Of 2.x In the version introduction, there are some instructions about the operation and maintenance of the cluster ;
There are also instructions for garbage collectors and so on , This is in the document :《 Don't touch the details of these configurations 》 But these also need to know and be familiar with ;
https://www.elastic.co/guide/cn/elasticsearch/guide/current/dont-touch-these-settings.html
Original statement : author :Arnold.zhao Blog Garden address :https://www.cnblogs.com/zh94
ElasticSearch, Word segmentation is analyzer
ElasticSearch3 Word segmentation is analyzer
analyzer The parser decomposes the input character stream into token The process of , It mainly happened on two occasions :
1、 stay index When creating an index ( That is to say, to index When creating document data in )
2、 stay search When , That is, when searching , Analyze the words you need to search for ;
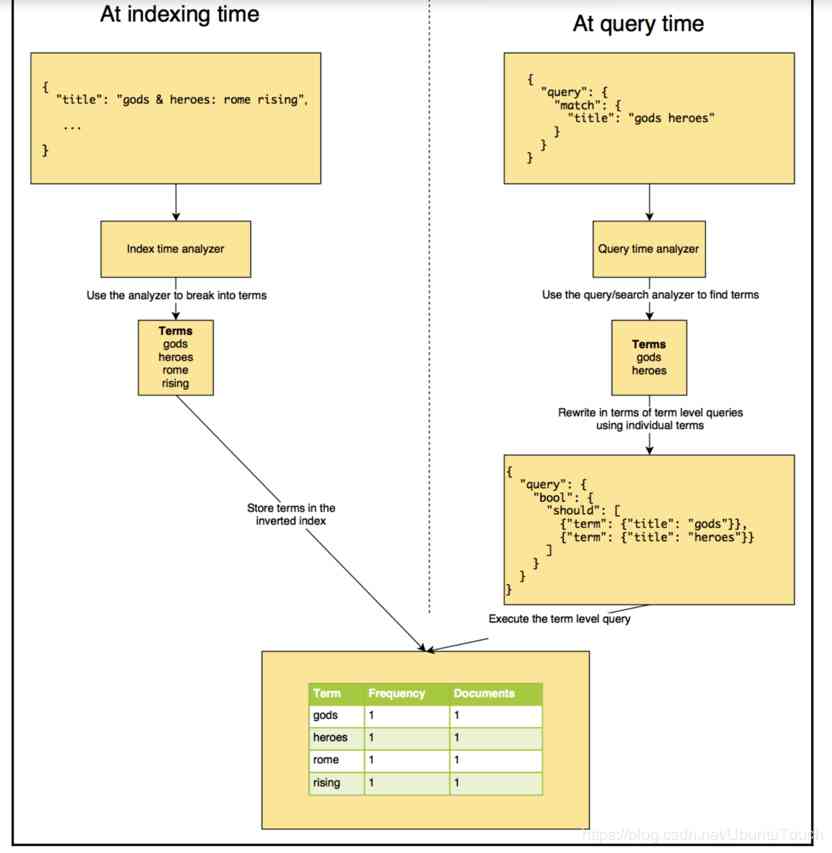
analyzer yes es The process of executing the body content of a document before it is stored , To add to the reverse index ; Before adding a document to an index ,es The corresponding... Is executed for each field to be analyzed analyzer step ;
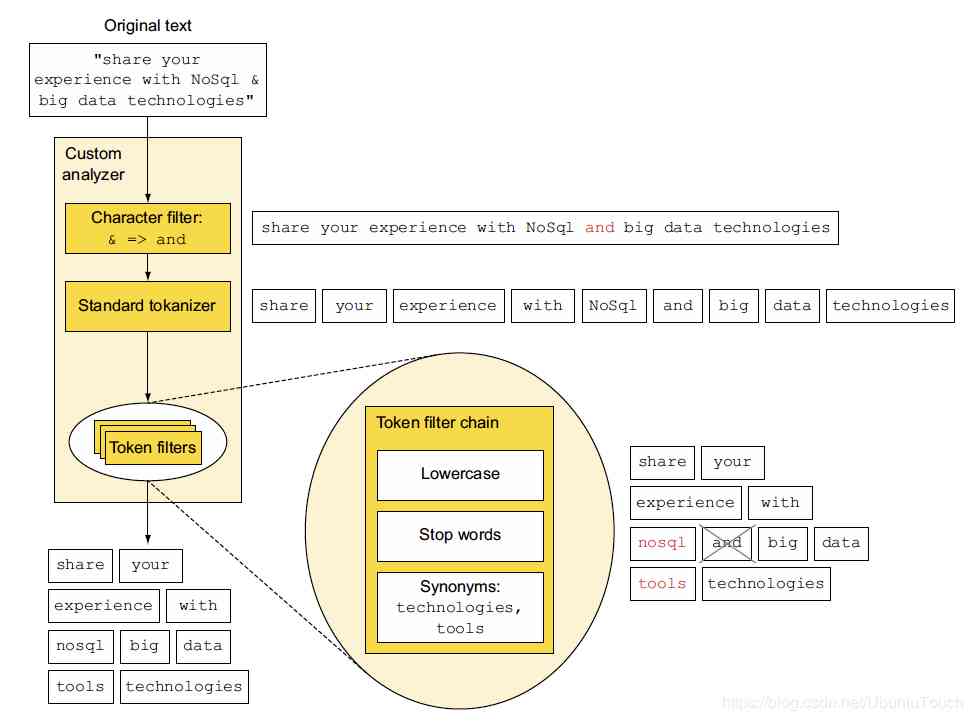
Such as : We are now customizing a new analyzer, The difference is caused by :character filter , The standard tokenizer And token filter form ;
The following figure shows a piece of original text , after analyzer The whole process of analysis ;
Finally, after a series of analysis , The corresponding analysis results will be , Add to the corresponding reverse index , Pictured 1 The steps are as follows ;
analyzer The composition of the analyzer
analyzer analyzer , Common in three parts :
- Char Filter: The job of the character filter is to perform the cleanup task , For example, stripping HTML Mark .
- Tokenizer: The next step is to split the text into terms called tags . This is from tokenizer Accomplished . It can be based on any rule ( Such as spaces ) To complete the split
- Token Filter: Once created token, They will be passed on to token filter, These filters will do something to token Standardize . Token filter You can change token, To delete a term or to token Add terms .
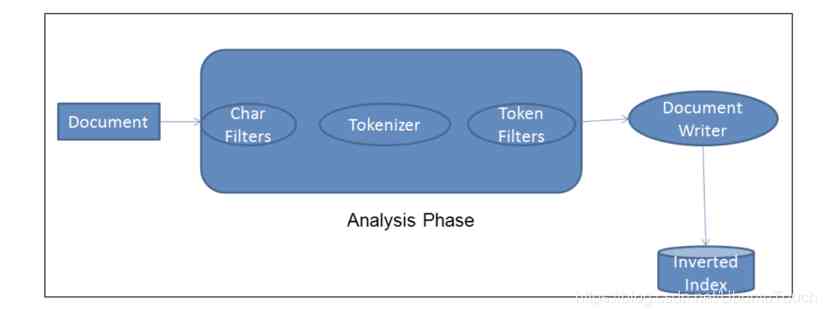
It's very important :Elasticsearch It has provided a wealth of analyzer analyzer . We can create our own token analyzer, You can even take advantage of what you already have char filter,tokenizer And token filter To recombine into a new analyzer, And you can define your own... For each field in the document analyzer.
By default ,ES The analyzer used in is standard analyzer analyzer ;
standard analyzer The features used by the analyzer are :
1、 No, Char Filter
2、 Use standard tokonzer
3、 Convert the corresponding string to lowercase , At the same time, there are some selective deletion stop words( Pause words ); By default stop words by none, And don't filter anything stop words( Pause words )
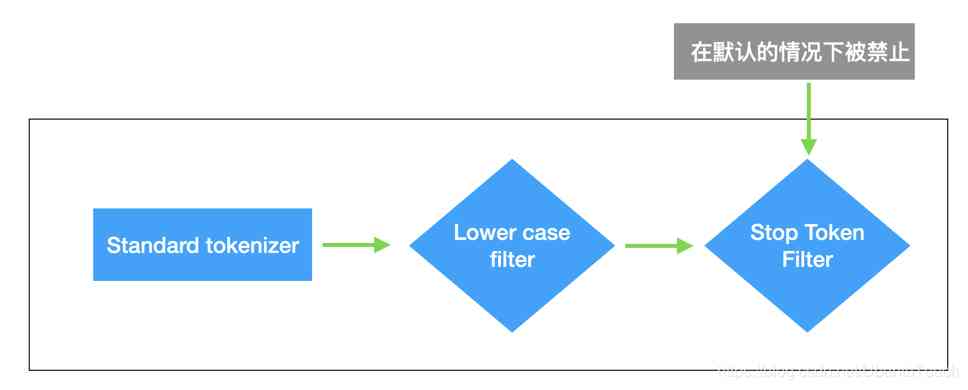
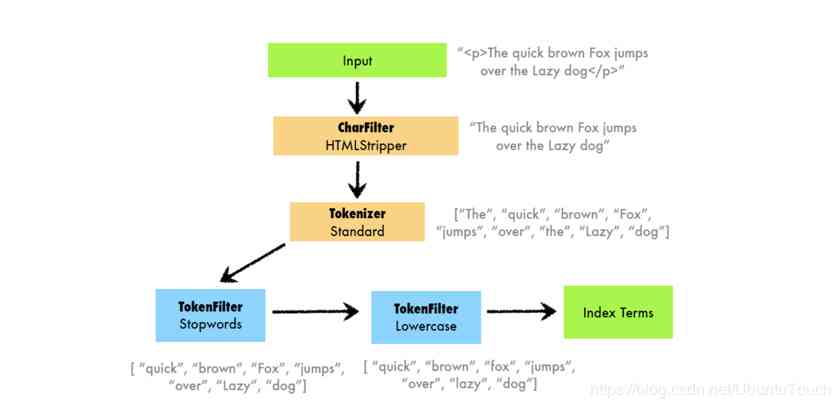
Another picture below illustrates , Different analyzers analyzer , about token The split of :

https://elasticstack.blog.csdn.net/article/details/100392478



![[论文阅读笔记] Large-Scale Heterogeneous Feature Embedding](/img/00/df94bfe594e17ab120c30fd6b31931.jpg)