[ Paper reading notes ] Community-oriented attributed network embedding
The structure of this paper
- solve the problem
- Main contributions
- Algorithm principle
- reference
(1) solve the problem
Most of the existing methods only retain the local structure of nodes in the process of network representation , Ignore their community information and rich attribute information .
(2) Main contributions
Contribution 1: A novel representation method of attribute network is proposed (COANE), Introduce topic model LDA Generate node community information , Guide random walk to capture community information in the network .
Contribution 2: A community oriented random walk strategy is designed —— The edge of the community is introduced to adaptively control the range of random walk , this It solves the problem that the random walk method can't sample the effective walk sequence in dense network .
(3) Algorithm principle
Firstly, it briefly introduces the algorithm used to generate node community information LDA Model ( Please refer to other materials or the original paper for details ).LDA It's an iterative algorithm , Gibbs sampling is used to estimate the following two probability distributions in the form of statistical frequency ( The number of communities needs to be given in advance ).
- Given the community c, Where nodes v In the community c The probability of
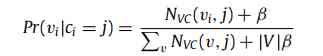
- Given a sequence of nodes s, Choose a node from which to belong to the community c Probability )
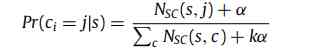
It first gives the sequence s Every node in vi Randomly assign a community ci. Based on the sampling sequence , Every node is traversed , And its community is constantly updated based on the following probability , until LDA The model parameters converge .
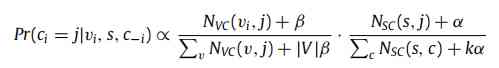
COANE The algorithm includes the following three parts :
- Random walk based on edge generates node sequence .
- Based on the above sampling node sequence , Train two... With different parameters LDA Models are learned separately based on structure ( Short for LDA-S) And based on text properties ( Short for LDA-X) Community distribution of .
- adopt Skip-Gram Model to learn the vector representation of nodes .
Next we start from the algorithm pseudo code step by step analysis COANE Principle of algorithm .
COANE The pseudo code of the algorithm is shown in the figure below :

From the pseudo code above, I can see that the input of the algorithm is shown in the figure 、 Parameters of random walk 、 Number of communities (LDA Parameters of the topic model )、 The moment the edge appears Mm、 Edge expansion speed Ms. The output is the embedding matrix of the network .
So what is edge based random walk ? How to achieve it ? First , In the early days, we generated a sequence of nodes by random walk and input LDA-S Model update node ownership . After several iterations of node community ownership update , There will be margins between nodes belonging to different communities , As shown in the figure below . The gap between different communities is also becoming more and more obvious , That is, the membership degree of nodes to more likely communities will gradually increase , In the picture, the color is deepened .
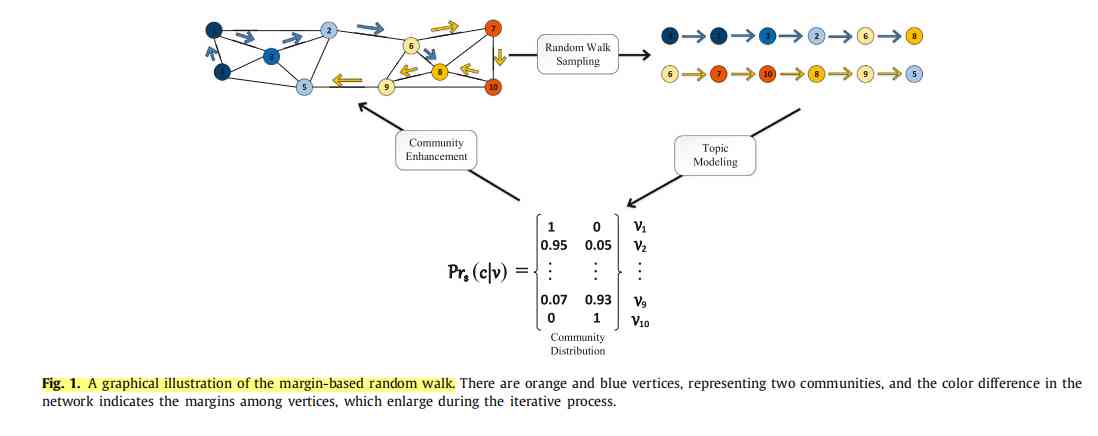
You can find , After repeated training LDA The model can find the community structure more accurately . Therefore, based on LDA Estimated probability of community belonging , We can calculate the transition probability of two nodes in the random walk process as follows :
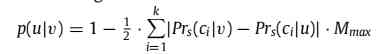
Mmax It's a by 0 It's going up to 1 Parameters of . When the maximum margin Mmax=0 When , Random walk based on margin is equivalent to traditional DeepWalk Random walk . With Mmax An increase in , The probability of node cross community access is reduced .Mmax It can be thought of as confidence in the division of communities , This confidence level is increasing , Because after constant training LDA The community structure discovered by the model is more and more obvious .
The above is random walk based on edge , The edge follows LDA The training level of the model is more and more obvious , The constraints of community on random walk are becoming stronger and stronger .
By pseudo code No 13,14 Line , Each random walk sequence is used to iteratively update two LDA Model .
Now? , The node sequence obtained by random walk based on edge is input into Skip-Gram model training , We can get node vector representation based on node topology and community structure . So how to fuse node attribute information ?
We mentioned a text attribute based model LDA Model (LDA The probability distribution model is the subject processing , Here we just need to sample the sequence of text ), Again , We do edge based random walks in the graph , Replace the node in the sequence with its corresponding text attribute , These texts are aggregated to produce a single document , Input to text-based LDA In the model ,. Final LDA The model can generate the topic probability distribution of the document , In this paper, the distribution is directly regarded as the representation vector of the text attributes of nodes , Finally, the fusion node topology can be obtained by merging it into the original structure based representation vector 、 The node representation of community information and attribute information .
The above is the whole content of the network representation learning algorithm .
(4) reference
Gao Y, Gong M, Xie Y, et al. Community-oriented attributed network embedding[J]. Knowledge-Based Systems, 2020, 193: 105418.