当前位置:网站首页>Diffusion模型详解
Diffusion模型详解
2022-07-07 06:59:00 【鬼道2022】
1 引言
在上一篇《基于流的深度生成模型》中详解介绍了有关流的生成模型理论和方法。目前为止,基于GAN生成模型,基于VAE的生成模型,以及基于flow的生成模型它们都可以生成较高质量的样本,但每种方法都有其局限性。GAN在对抗训练过程中会出现模式崩塌和训练不稳定的问题;VAE则严重依赖于目标损失函数;流模型则必须使用专门的框架来构建可逆变换。本文主要介绍关于扩散模型,其灵感来自于非平衡热力学。它们定义了扩散步骤的马尔可夫链,将随机噪声缓慢地添加到数据中,然后学习逆向扩散过程以从噪声中构造所需的数据样本。 与VAE或流模型不同,扩散模型是通过固定过程学习的,并且中间的隐变量与原始数据具有高维数维度。
- 优点: 扩散模型既易于分析又很灵活。要知道易处理性和灵活性是生成建模中两个相互冲突的目标。易于处理的模型可以进行分析评估和拟合数据,但它们不能轻易地描述丰富数据集中的结构。灵活的模型可以拟合数据中的任意结构,但是从这些模型中评估、训练或采样的成本会很高。
- 缺点: 扩散模型依赖于长马尔可夫扩散步骤链来生成样本,因此在时间和计算方面成本会很高。目前已经提出了新的方法来使该过程更快,但采样的整体过程仍然比GAN慢。
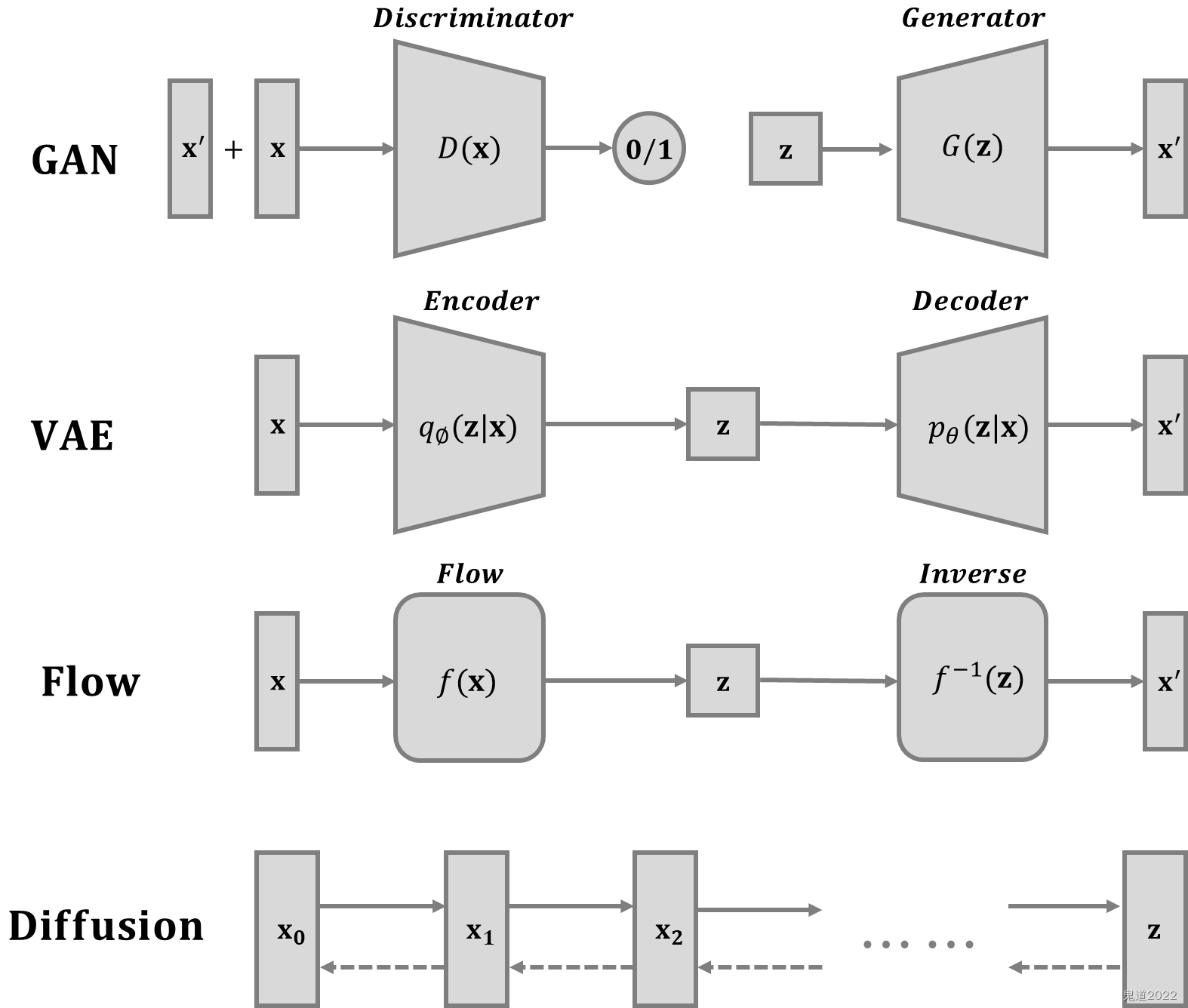
2 前向扩散过程
给定从真实数据分布 x 0 ∼ q ( x ) {\bf{x}}_0\sim q({\bf{x}}) x0∼q(x)中采样的数据点,在一个前向扩散过程,在 T T T步里逐步向样本中添加少量高斯噪声,从而产生一系列噪声样本 x 1 , ⋯ , x T {\bf{x}}_1,\cdots,{\bf{x}}_T x1,⋯,xT,其步长由方差计划 { β t ∈ ( 0 , 1 ) } t = 1 T \{\beta_t\in(0,1)\}_{t=1}^T { βt∈(0,1)}t=1T来控制,则有 q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β x t − 1 , β t I ) q ( x 1 : T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) q({\bf{x}}_t|{\bf{x}}_{t-1})=\mathcal{N}({\bf{x}}_t;\sqrt{1-\beta}{\bf{x}}_{t-1},\beta_t {\bf{I}})\quad q({\bf{x}}_{1:T}|{\bf{x}}_0)=\prod_{t=1}^Tq({\bf{x}}_t|{\bf{x}}_{t-1}) q(xt∣xt−1)=N(xt;1−βxt−1,βtI)q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)在扩散过程进行的时候,随着时长步长 t t t的增大,数据样本 x 0 {\bf{x}}_0 x0逐渐失去其可区分的特征。最终,当 T → ∞ T\rightarrow \infty T→∞, x T {\bf{x}}_T xT等价于各向同性高斯分布(各向同性的高斯分布即球形高斯分布,特指的是各个方向方差都一样的多维高斯分布,协方差为正实数与单位矩阵相乘)。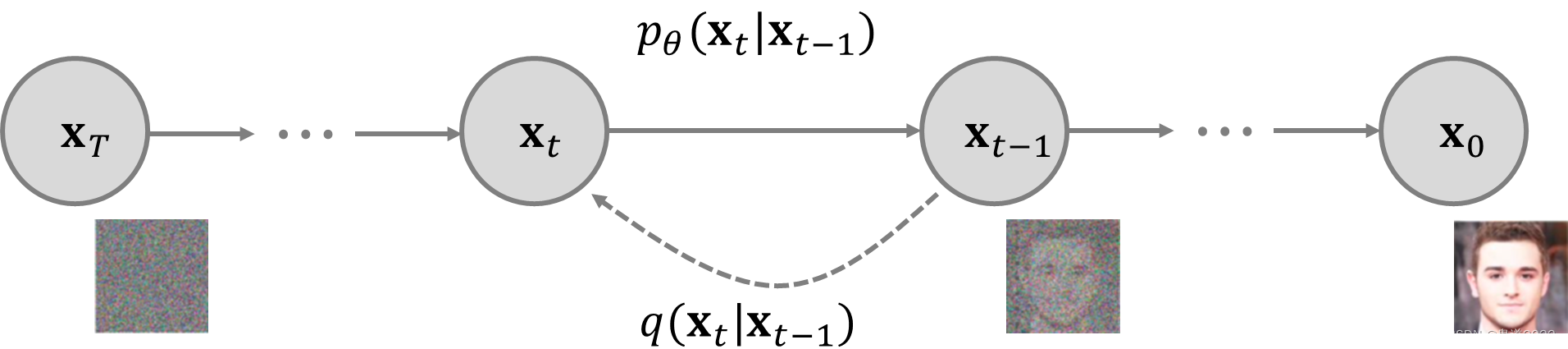
上述过程的一个很好的特性是可以使用重新参数化技巧以封闭形式在任意时间步长 t t t对 x t {\bf{x}}_t xt进行采样。 令 α t = 1 − β t \alpha_t=1-\beta_t αt=1−βt和 α ˉ t = ∏ i = 1 T α i \bar{\alpha}_t=\prod_{i=1}^T \alpha_i αˉt=∏i=1Tαi,进而则有: x t = α t x t − 1 + 1 − α t z t − 1 = α t α t − 1 x t − 2 + 1 − α t α t − 1 z ˉ t − 2 = ⋯ = α ˉ t x 0 + 1 − α ˉ t z q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) \begin{aligned}{\bf{x}}_t&=\sqrt{\alpha_t}{\bf{x}}_{t-1}+\sqrt{1-\alpha_t}{\bf{z}}_{t-1}\\&=\sqrt{\alpha_t\alpha_{t-1}}{\bf{x}}_{t-2}+\sqrt{1-\alpha_t\alpha_{t-1}}{\bf{\bar{z}}}_{t-2}\\&=\cdots\\&=\sqrt{\bar{\alpha}_t}{\bf{x}}_0+\sqrt{1-\bar{\alpha}_t}{\bf{z}}\\q({\bf{x}}_t|{\bf{x}}_0)&=\mathcal{N}({\bf{x}}_t;\sqrt{\bar{\alpha}_t}{\bf{x}}_0,(1-\bar{\alpha}_t){\bf{I}})\end{aligned} xtq(xt∣x0)=αtxt−1+1−αtzt−1=αtαt−1xt−2+1−αtαt−1zˉt−2=⋯=αˉtx0+1−αˉtz=N(xt;αˉtx0,(1−αˉt)I)其中 z t − 1 , z t − 2 , ⋯ ∼ N ( 0 , I ) {\bf{z}}_{t-1},{\bf{z}}_{t-2},\cdots \sim\mathcal{N}({\bf{0}},{\bf{I}}) zt−1,zt−2,⋯∼N(0,I), z ˉ t − 2 {\bar{\bf{z}}}_{t-2} zˉt−2融合两个高斯分布。当合并两个具有不同方差 N ( 0 , σ 1 2 I ) \mathcal{N}({\bf{0}},\sigma^2_1{\bf{I}}) N(0,σ12I)和 N ( 0 , σ 2 2 I ) \mathcal{N}({\bf{0}},\sigma^2_2{\bf{I}}) N(0,σ22I)的高斯分布时,得到的新的高斯分布是 N ( 0 , ( σ 1 2 , σ 2 2 ) I ) \mathcal{N}({\bf{0}},(\sigma^2_1,\sigma_2^2){\bf{I}}) N(0,(σ12,σ22)I),其中合并的标准差为 ( 1 − α t ) + α t ( 1 − α t − 1 ) = 1 − α t α t − 1 \sqrt{(1-\alpha_t)+\alpha_t(1-\alpha_{t-1})}=\sqrt{1-\alpha_{t}\alpha_{t-1}} (1−αt)+αt(1−αt−1)=1−αtαt−1通常情况下,噪声越大更新的步长也会随着调大,则有 β 1 < β 2 ⋯ < β T \beta_1<\beta_2\cdots<\beta_T β1<β2⋯<βT,所以 α ˉ 1 > ⋯ > α ˉ T \bar{\alpha}_1>\cdots>\bar{\alpha}_T αˉ1>⋯>αˉT。
3 更新过程
Langevin动力学是物理学中的一个概念,用于对分子系统进行统计建模。结合随机梯度下降,随机梯度朗之万动力学可以仅使用马尔可夫更新链中的梯度 ∇ x log p ( x ) \nabla_{\bf{x}} \log p({\bf{x}}) ∇xlogp(x)从概率密度 p ( x ) p({\bf{x}}) p(x)生成样本: x t = x t − 1 + ϵ 2 ∇ x log p ( x t − 1 ) + ϵ z t , z t ∼ N ( 0 , I ) {\bf{x}}_t={\bf{x}}_{t-1}+\frac{\epsilon}{2}\nabla_{\bf{x}} \log p({\bf{x}}_{t-1})+\sqrt{\epsilon}{\bf{z}}_t,\quad {\bf{z}}_t\sim\mathcal{N}({\bf{0}},{\bf{I}}) xt=xt−1+2ϵ∇xlogp(xt−1)+ϵzt,zt∼N(0,I)其中 ϵ \epsilon ϵ为步长。当 T → ∞ T\rightarrow \infty T→∞时, ϵ → 0 \epsilon\rightarrow 0 ϵ→0, x {\bf{x}} x_T则等于真实概率密度 p ( x ) p({\bf{x}}) p(x)。与标准SGD相比,随机梯度Langevin动力学将高斯噪声注入到参数更新中,以避免陷入到局部最小值中。
4 反向扩散过程
如果将上述过程进行反转并从概率分布 q ( x t − 1 ∣ x t ) q({\bf{x}}_{t-1}|{\bf{x}}_t) q(xt−1∣xt)中进行采样,则能够从高斯噪声输入 x T ∼ N ( 0 , I ) {\bf{x}}_T\sim \mathcal{N}({\bf{0}},{\bf{I}}) xT∼N(0,I)中重新构造真实样本。需要注意的是如果 β t \beta_t βt足够小, q ( x t − 1 , x t ) q({\bf{x}}_{t-1},{\bf{x}}_t) q(xt−1,xt)也将是高斯分布。但这需要使用整个数据集进行估计,因此需要学习一个模型 p θ p_\theta pθ来近似这些条件概率,以便进行反向扩散过程 p θ ( x 0 : T ) = p ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) p_\theta({\bf{x}}_{0:T})=p({\bf{x}}_T)\prod_{t=1}^T p_\theta({\bf{x}}_{t-1}|{\bf{x}}_t)\quad p_\theta({\bf{x}}_{t-1}|{\bf{x}}_t)=\mathcal{N}({\bf{x}}_{t-1};\boldsymbol{\mu}_\theta({\bf{x}}_t,t),{ {\bf{\Sigma}}_\theta({\bf{x}}_t,t)}) pθ(x0:T)=p(xT)t=1∏Tpθ(xt−1∣xt)pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))当条件为 x 0 {\bf{x}}_0 x0时,反向条件概率是容易估计处理的: q ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; μ ( x t , x 0 ) , β ~ t I ) q({\bf{x}}_{t-1}|{\bf{x}}_t,{\bf{x}}_0)=\mathcal{N}({\bf{x}}_{t-1};\boldsymbol{\mu}({\bf{x}}_t,{\bf{x}}_0),\tilde{\beta}_t{\bf{I}}) q(xt−1∣xt,x0)=N(xt−1;μ(xt,x0),β~tI)使用贝叶斯法则可以得到 q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 , x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) ∝ exp [ − 1 2 ( ( x t − α t x t − 1 ) 2 β t + ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ] = exp [ − 1 2 ( x t 2 − 2 α t x t x t − 1 + α t x t − 1 2 β t + x t − 1 2 − 2 α ˉ t − 1 x 0 x t − 1 + α ˉ t − 1 x 0 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ] = exp [ − 1 2 ( ( α t β t + 1 1 − α ˉ t − 1 ) x t − 1 2 − ( 2 α t β t x t + 2 α ˉ t − 1 1 − α ˉ t − 1 x 0 ) x t − 1 + C ( x t , x 0 ) ) ] \begin{aligned}q({\bf{x}}_{t-1}|{\bf{x}}_t,{\bf{x}}_0)&=q({\bf{x}}_{t}|{\bf{x}}_{t-1},{\bf{x}}_0)\frac{q({\bf{x}}_{t-1}|{\bf{x}}_0)}{q({\bf{x}}_t|{\bf{x}}_0)}\\&\propto\exp\left[-\frac{1}{2}\left(\frac{({\bf{x}}_t-\sqrt{\alpha_t}{\bf{x}}_{t-1})^2}{\beta_t}+\frac{({\bf{x}}_{t-1}-\sqrt{\bar{\alpha}_{t-1}}{\bf{x}}_0)^2}{1-\bar{\alpha}_{t-1}}-\frac{({\bf{x}}_t-\sqrt{\bar{\alpha}_t}{\bf{x}}_0)^2}{1-\bar{\alpha}_t}\right)\right]\\&=\exp\left[-\frac{1}{2}\left(\frac{ {\bf{x}}^2_t-2\sqrt{\alpha_t}{\bf{x}}_t{\bf{x}}_{t-1}+\alpha_t{\bf{x}}_{t-1}^2}{\beta_t}+\frac{ {\bf{x}}_{t-1}^2-2\sqrt{\bar{\alpha}_{t-1}}{\bf{x}}_0{\bf{x}}_{t-1}+\bar{\alpha}_{t-1}{\bf{x}}_0}{1-\bar{\alpha}_{t-1}}-\frac{({\bf{x}}_t-\sqrt{\bar{\alpha}_t}{\bf{x}}_0)^2}{1-\bar{\alpha}_t}\right)\right]\\&=\exp\left[-\frac{1}{2}\left(\left(\frac{\alpha_t}{\beta_t}+\frac{1}{1-\bar{\alpha}_{t-1}}\right){\bf{x}}^2_{t-1}-\left(\frac{2\sqrt{\alpha_t}}{\beta_t}{\bf{x}}_t+\frac{2\sqrt{\bar{\alpha}_{t-1}}}{1-\bar{\alpha}_{t-1}}{\bf{x}}_0\right){\bf{x}}_{t-1}+C({\bf{x}}_t,{\bf{x}}_0)\right)\right]\end{aligned} q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0)∝exp[−21(βt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2−1−αˉt(xt−αˉtx0)2)]=exp[−21(βtxt2−2αtxtxt−1+αtxt−12+1−αˉt−1xt−12−2αˉt−1x0xt−1+αˉt−1x0−1−αˉt(xt−αˉtx0)2)]=exp[−21((βtαt+1−αˉt−11)xt−12−(βt2αtxt+1−αˉt−12αˉt−1x0)xt−1+C(xt,x0))]其中 C ( x t , x 0 ) C({\bf{x}}_t,{\bf{x}}_0) C(xt,x0)函数与 x t − 1 {\bf{x}}_{t-1} xt−1无关。按照标准高斯密度函数,均值和方差可以参数化如下 β ~ t = 1 / ( α t β t + 1 1 − α ˉ t − 1 ) = 1 / ( α t − α ˉ t + β t β t ( 1 − α ˉ t − 1 ) ) = 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t μ ~ t ( x t , x 0 ) = ( α t β t x t + α ˉ t − 1 1 − α ˉ t − 1 x 0 ) / ( α t β t + 1 1 − α ˉ t − 1 ) = ( α t β t x t + α ˉ t − 1 1 − α ˉ t − 1 x 0 ) 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t x 0 \begin{aligned}\tilde{\beta}_t&=1\left/\left(\frac{\alpha_t}{\beta_t}+\frac{1}{1-\bar{\alpha}_{t-1}}\right)\right.=1\left/\left(\frac{\alpha_t-\bar{\alpha}_t+\beta_t}{\beta_t(1-\bar{\alpha}_{t-1})}\right)\right.=\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t}\cdot \beta_t\\\tilde{\boldsymbol{\mu}}_t({\bf{x}}_t,{\bf{x}}_0)&=\left(\frac{\sqrt{\alpha}_t}{\beta_t}{\bf{x}}_t+\frac{\sqrt{\bar{\alpha}_{t-1}}}{1-\bar{\alpha}_{t-1}}{\bf{x}}_0\right)\left/\left(\frac{\alpha_t}{\beta_t}+\frac{1}{1-\bar{\alpha}_{t-1}}\right)\right.\\&=\left(\frac{\sqrt{\alpha}_t}{\beta_t}{\bf{x}}_t+\frac{\sqrt{\bar{\alpha}_{t-1}}}{1-\bar{\alpha}_{t-1}}{\bf{x}}_0\right)\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t}\cdot\beta_t\\&=\frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}{\bf{x}}_t+\frac{\sqrt{\bar{\alpha}_{t-1}\beta_t}}{1-\bar{\alpha}_t}{\bf{x}}_0\end{aligned} β~tμ~t(xt,x0)=1/(βtαt+1−αˉt−11)=1/(βt(1−αˉt−1)αt−αˉt+βt)=1−αˉt1−αˉt−1⋅βt=(βtαtxt+1−αˉt−1αˉt−1x0)/(βtαt+1−αˉt−11)=(βtαtxt+1−αˉt−1αˉt−1x0)1−αˉt1−αˉt−1⋅βt=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtx0将 x 0 = 1 α ˉ t ( x t − 1 − α ˉ t z t ) {\bf{x}}_0=\frac{1}{\sqrt{\bar{\alpha}_t}}({\bf{x}}_t-\sqrt{1-\bar{\alpha}_t}{\bf{z}}_t) x0=αˉt1(xt−1−αˉtzt)带入到以上公式中则有 μ ~ t = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t 1 α ˉ t ( x t − 1 − α ˉ t z t ) = 1 α t ( x t − β t 1 − α ˉ t z t ) \begin{aligned}\boldsymbol{\tilde{\mu}}_t&=\frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}{\bf{x}}_t+\frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1-\bar{\alpha}_t}\frac{1}{\sqrt{\bar{\alpha}_t}}({\bf{x}}_t-\sqrt{1-\bar{\alpha}_t}{\bf{z}}_t)\\&=\frac{1}{\sqrt{\alpha_t}}\left({\bf{x}}_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}{\bf{z}}_t\right)\end{aligned} μ~t=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtαˉt1(xt−1−αˉtzt)=αt1(xt−1−αˉtβtzt)这种设置与VAE非常相似,因此可以使用变分下限来优化负对数似然,进而则有 − log p θ ( x 0 ) ≤ − log p θ ( x 0 ) + D K L ( q ( x 1 : T ) ∣ x 0 ∣ ∣ p θ ( x 1 : T ∣ x 0 ) ) = − log p θ ( x θ ) + E 1 : T ∼ q ( x 1 : T ∣ x 0 ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) / p θ ( x 0 ) ] = − log p θ ( x 0 ) + E q [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) + log p θ ( x 0 ) ] = E q [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] L V L B = E q ( x 0 : T ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] ≥ − E q ( x 0 ) log p θ ( x 0 ) \begin{aligned}-\log p_\theta({\bf{x}}_0)&\le -\log p_\theta({\bf{x}}_0)+D_{\mathrm{KL}}(q({\bf{x}}_{1:T})|{\bf{x}}_0||p_\theta({\bf{x}}_{1:T}|{\bf{x}}_0))\\&=-\log p_\theta({\bf{x}}_\theta)+\mathbb{E}_{1:T\sim q({\bf{x}}_{1:T}|{\bf{x}}_0)}\left[\log \frac{q({\bf{x}}_{1:T}|{\bf{x}}_0)}{p_\theta({\bf{x}}_{0:T})/p_\theta({\bf{x}}_0)}\right]\\&=-\log p_\theta({\bf{x}}_0)+\mathbb{E}_q\left[\log \frac{q({\bf{x}}_{1:T}|{\bf{x}}_0)}{p_\theta({\bf{x}}_{0:T})}+\log p_\theta ({\bf{x}}_0)\right]\\&=\mathbb{E}_q\left[\log \frac{q({\bf{x}}_{1:T}|{\bf{x}}_0)}{p_\theta({\bf{x}}_{0:T})}\right]\\L_{\mathrm{VLB}}&=\mathbb{E}_{q({\bf{x}}_{0:T})}\left[\log \frac{q({\bf{x}}_{1:T}|{\bf{x}}_0)}{p_\theta({\bf{x}}_{0:T})}\right]\ge -\mathbb{E}_{q({\bf{x}}_0)}\log p_\theta({\bf{x}}_0)\end{aligned} −logpθ(x0)LVLB≤−logpθ(x0)+DKL(q(x1:T)∣x0∣∣pθ(x1:T∣x0))=−logpθ(xθ)+E1:T∼q(x1:T∣x0)[logpθ(x0:T)/pθ(x0)q(x1:T∣x0)]=−logpθ(x0)+Eq[logpθ(x0:T)q(x1:T∣x0)+logpθ(x0)]=Eq[logpθ(x0:T)q(x1:T∣x0)]=Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]≥−Eq(x0)logpθ(x0)使用Jensen不等式也很容易得到相同的结果。假设要最小化交叉熵作为学习目标,则有 L C E = − E q ( x 0 ) log p θ ( x 0 ) = − E q ( x 0 ) log ( ∫ p θ ( x 0 : T ) d x 1 : T ) = − E q ( x 0 ) log ( ∫ q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) d x 1 : T ) = − E q ( x 0 ) log ( E q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) ) ≤ − E q ( x 0 : T ) log p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) = E q ( x 0 : T ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] = L V T B \begin{aligned}L_{\mathrm{CE}}&=-\mathbb{E}_{q({\bf{x}}_0)}\log p_\theta({\bf{x}}_0)\\&=-\mathbb{E}_{q({\bf{x}}_0)}\log\left(\int p_\theta({\bf{x}}_{0:T})d {\bf{x}}_{1:T}\right)\\&=-\mathbb{E}_{q({\bf{x}}_0)}\log\left(\int q({\bf{x}}_{1:T}|{\bf{x}}_0)\frac{p_\theta({\bf{x}}_{0:T})}{q({\bf{x}}_{1:T}|{\bf{x}}_0)}d{\bf{x}}_{1:T}\right)\\&=-\mathbb{E}_{q({\bf{x}}_0)}\log\left(\mathbb{E}_{q({\bf{x}}_{1:T}|{\bf{x}}_0)}\frac{p_\theta({\bf{x}}_{0:T})}{q({\bf{x}}_{1:T}|{\bf{x}}_0)}\right)\\ &\le -\mathbb{E}_{q({\bf{x}}_{0:T})}\log\frac{p_\theta({\bf{x}}_{0:T})}{q({\bf{x}}_{1:T}|{\bf{x}}_0)}\\&=\mathbb{E}_{q({\bf{x}}_{0:T})}\left[\log\frac{q({\bf{x}}_{1:T}|{\bf{x}}_0)}{p_\theta({\bf{x}}_{0:T})}\right]=L_{\mathrm{VTB}}\end{aligned} LCE=−Eq(x0)logpθ(x0)=−Eq(x0)log(∫pθ(x0:T)dx1:T)=−Eq(x0)log(∫q(x1:T∣x0)q(x1:T∣x0)pθ(x0:T)dx1:T)=−Eq(x0)log(Eq(x1:T∣x0)q(x1:T∣x0)pθ(x0:T))≤−Eq(x0:T)logq(x1:T∣x0)pθ(x0:T)=Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]=LVTB为了将方程中的每个项转换为可解析计算的,可以将目标进一步重写为几个KL散度和熵项的组合 L T V B = E q ( x 0 : T ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] = E q [ log ∏ t = 1 T q ( x t ∣ x t − 1 ) p θ ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ p ( x t ) ) ] = E q [ − log p θ ( x T ) + ∑ t = 1 T log q ( x t ∣ x t − 1 ) p θ ( x t − 1 ∣ x t ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t ∣ x t − 1 ) p θ ( x t − 1 ∣ x t ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log ( q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) ⋅ q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) + ∑ t = 2 T log q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) + log q ( x T ∣ x 0 ) q ( x 1 ∣ x 0 ) + log q ( x 1 ∣ x 0 ) p θ ( x ∣ x 1 ) ] = E q [ log q ( x T ∣ x 0 ) p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) − log p θ ( x 0 ∣ x 1 ) ] = E q [ D K L ( q ( x T ∣ x 0 ) ∣ ∣ p θ ( x T ) ) + ∑ t = 2 T D K L ( q ( x t − 1 ∣ x t , x 0 ) ∣ ∣ p θ ( x t − 1 ∣ x t ) ) − log p θ ( x 0 ∣ x 1 ) ] \begin{aligned}L_{\mathrm{TVB}}&=\mathbb{E}_{q({\bf{x}}_{0:T})}\left[\log \frac{q({\bf{x}}_{1:T}|{\bf{x}}_0)}{p_\theta({\bf{x}}_{0:T})}\right]\\&=\mathbb{E}_q\left[\log\frac{\prod_{t=1}^T q({\bf{x}}_t|{\bf{x}}_{t-1})}{p_\theta({\bf{x}}_T)\prod_{t=1}^T p_\theta({\bf{x}}_{t-1}|p({\bf{x}}_t))}\right]\\&=\mathbb{E}_q\left[-\log p_\theta({\bf{x}}_T)+\sum\limits_{t=1}^T\log \frac{q({\bf{x}}_t|{\bf{x}}_{t-1})}{p_\theta({\bf{x}}_{t-1}|{\bf{x}}_t)}\right]\\&=\mathbb{E}_q\left[-\log p_\theta({\bf{x}}_T)+\sum\limits_{t=2}^T \log\frac{q({\bf{x}}_{t}|{\bf{x}}_{t-1})}{p_\theta({\bf{x}}_{t-1}|{\bf{x}}_{t})}+\log\frac{q({\bf{x}}_1|{\bf{x}}_0)}{p_\theta({\bf{x}}_0|{\bf{x}}_1)}\right]\\&=\mathbb{E}_q\left[-\log p_\theta({\bf{x}}_T)+\sum\limits_{t=2}^T\log\left(\frac{q({\bf{x}}_{t-1}|{\bf{x}}_t,{\bf{x}}_0)}{p_\theta({\bf{x}}_{t-1}|{\bf{x}}_t)}\cdot\frac{q({\bf{x}}_t|{\bf{x}}_0)}{q({\bf{x}}_{t-1}|{\bf{x}}_0)}\right)+\log\frac{q({\bf{x}}_1|{\bf{x}}_0)}{p_\theta({\bf{x}}_0|{\bf{x}}_1)}\right]\\&=\mathbb{E}_q\left[-\log p_\theta({\bf{x}}_T)+\sum\limits_{t=2}^T\log \frac{q({\bf{x}}_{t-1}|{\bf{x}}_t,{\bf{x}}_0)}{p_\theta({\bf{x}}_{t-1}|{\bf{x}}_t)}+\sum\limits_{t=2}^T\log \frac{q({\bf{x}}_t|{\bf{x}}_0)}{q({\bf{x}}_{t-1}|{\bf{x}}_0)}+\log \frac{q({\bf{x}}_1|{\bf{x}}_0)}{p_\theta({\bf{x}}_0|{\bf{x}}_1)}\right]\\&=\mathbb{E}_q\left[-\log p_\theta({\bf{x}}_T)+\sum\limits_{t=2}^T\log \frac{q({\bf{x}}_{t-1}|{\bf{x}}_t,{\bf{x}}_0)}{p_\theta({\bf{x}}_{t-1}|{\bf{x}}_t)}+\log\frac{q({\bf{x}}_T|{\bf{x}}_0)}{q({\bf{x}}_1|{\bf{x}}_0)}+\log \frac{q({\bf{x}}_1|{\bf{x}}_0)}{p_\theta({\bf{x}}|{\bf{x}}_1)}\right]\\&=\mathbb{E}_q\left[\log \frac{q({\bf{x}}_T|{\bf{x}}_0)}{p_\theta({\bf{x}}_T)}+\sum\limits_{t=2}^T\log \frac{q({\bf{x}}_{t-1}|{\bf{x}}_t,{\bf{x}}_0)}{p_\theta({\bf{x}}_{t-1}|{\bf{x}}_t)}-\log p_\theta({\bf{x}}_0|{\bf{x}}_1)\right]\\&=\mathbb{E}_q\left[D_{\mathrm{KL}}(q({\bf{x}}_T|{\bf{x}}_0)||p_\theta({\bf{x}}_T))+\sum\limits_{t=2}^T D_{\mathrm{KL}}(q({\bf{x}}_{t-1}|{\bf{x}}_t,{\bf{x}}_0)||p_\theta({\bf{x}}_{t-1}|{\bf{x}}_t))-\log p_\theta({\bf{x}}_0|{\bf{x}}_1)\right]\end{aligned} LTVB=Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]=Eq[logpθ(xT)∏t=1Tpθ(xt−1∣p(xt))∏t=1Tq(xt∣xt−1)]=Eq[−logpθ(xT)+t=1∑Tlogpθ(xt−1∣xt)q(xt∣xt−1)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt∣xt−1)+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlog(pθ(xt−1∣xt)q(xt−1∣xt,x0)⋅q(xt−1∣x0)q(xt∣x0))+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)+t=2∑Tlogq(xt−1∣x0)q(xt∣x0)+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)+logq(x1∣x0)q(xT∣x0)+logpθ(x∣x1)q(x1∣x0)]=Eq[logpθ(xT)q(xT∣x0)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)−logpθ(x0∣x1)]=Eq[DKL(q(xT∣x0)∣∣pθ(xT))+t=2∑TDKL(q(xt−1∣xt,x0)∣∣pθ(xt−1∣xt))−logpθ(x0∣x1)]分别标记变分下界损失中的每个分量为 L V L B = L T + L T − 1 + ⋯ + L 0 L T = D K L ( q ( x T ∣ x 0 ) ∣ ∣ p θ ( x T ) ) L t = D K L ( q ( x t ∣ x t + 1 , x 0 ) ∣ ∣ p θ ( x t ∣ x t + 1 ) ) L 0 = − log p θ ( x 0 ∣ x 1 ) \begin{aligned}L_{\mathrm{VLB}}&=L_T+L_{T-1}+\cdots+L_{0}\\L_T&=D_{\mathrm{KL}}(q({\bf{x}}_T|{\bf{x}}_0)||p_\theta({\bf{x}}_T))\\L_t&=D_{\mathrm{KL}}(q({\bf{x}}_t|{\bf{x}}_{t+1},{\bf{x}}_0)||p_\theta({\bf{x}}_t|{\bf{x}}_{t+1}))\\L_0&=-\log p_\theta({\bf{x}}_0|{\bf{x}}_1)\end{aligned} LVLBLTLtL0=LT+LT−1+⋯+L0=DKL(q(xT∣x0)∣∣pθ(xT))=DKL(q(xt∣xt+1,x0)∣∣pθ(xt∣xt+1))=−logpθ(x0∣x1) L V L B L_{\mathrm{VLB}} LVLB中的每个KL项(除了 L 0 L_0 L0)都测量两个高斯分布之间的距离,因此可以以闭式解来计算它们。 L T L_T LT是常数,在训练过程中可以被忽略,其原因在于 q q q没有可学习的参数并且 x T {\bf{x}}_T xT是高斯噪声, L 0 L_0 L0可以从 N ( x 0 , μ θ ( x 1 , 1 ) , Σ θ ( x 1 , 1 ) \mathcal{N({\bf{x}}_0,\boldsymbol{\mu}_\theta({\bf{x}}_1,1),{\bf{\Sigma}}_\theta({\bf{x}}_1,1)} N(x0,μθ(x1,1),Σθ(x1,1)中推导出来。
5 训练损失的参数化
当需要学习一个神经网络来逼近反向扩散过程中的条件概率分布 p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) p_\theta({\bf{x}}_{t-1}|{\bf{x}}_t)=\mathcal{N}({\bf{x}}_{t-1};\boldsymbol{\mu}_\theta({\bf{x}}_t,t),{\bf{\Sigma}}_\theta({\bf{x}}_t,t)) pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))时,即想训练 μ θ \boldsymbol{\mu}_\theta μθ预测 μ ~ t = 1 α t ( x − β t 1 − α ˉ t z t ) \tilde{\boldsymbol{\mu}}_t=\frac{1}{\sqrt{\alpha_t}}\left({\bf{x}}-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}{\bf{z}}_t\right) μ~t=αt1(x−1−αˉtβtzt)。 因为 x t {\bf{x}}_t xt在训练时可用作输入,可以重新参数化高斯噪声项,以使其从时间步长 t t t的输入 x t {\bf{x}}_t xt中预测 z t {\bf{z}}_t zt:
μ θ ( x t , t ) = 1 α t ( x t − β t 1 − α ˉ t z θ ( x t , t ) ) x t − 1 = N ( x t − 1 ; 1 α t ( x t − β t 1 − α ˉ t z θ ( x t , t ) ) , Σ θ ( x t , t ) ) \begin{aligned}{\boldsymbol{\mu}}_\theta({\bf{x}}_t,t)&=\frac{1}{\sqrt{\alpha_t}}\left({\bf{x}}_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}{\bf{z}}_\theta({\bf{x}}_t,t)\right)\\{\bf{x}}_{t-1}&=\mathcal{N}\left({\bf{x}}_{t-1};\frac{1}{\sqrt{\alpha_t}}\left({\bf{x}}_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}{\bf{z}}_\theta({\bf{x}}_t,t)\right),{\bf{\Sigma}}_\theta({\bf{x}}_t,t)\right)\end{aligned} μθ(xt,t)xt−1=αt1(xt−1−αˉtβtzθ(xt,t))=N(xt−1;αt1(xt−1−αˉtβtzθ(xt,t)),Σθ(xt,t))损失项 L t L_t Lt是被参数化目的是最小化来自 μ ~ \tilde{\boldsymbol{\mu}} μ~的差异 L t = E x 0 , z [ 1 2 ∥ Σ θ ( x t , t ) ∥ 2 2 ∥ μ ~ t ( x t , x 0 ) − μ θ ( x t , t ) ∥ 2 ] = E x 0 , z [ 1 2 ∥ Σ θ ∥ 2 2 ∥ 1 α t ( x t − β t 1 − α ˉ z ) − 1 α t ( x t − β t 1 − α ˉ z θ ( x t , t ) ) ∥ ] = E x 0 , z [ β t 2 2 α t ( 1 − α ˉ t ) ∥ Σ θ ∥ 2 2 ∥ z t − z θ ( x t , t ) ∥ 2 ] = E x 0 , z [ β t 2 2 α t ( 1 − α ˉ t ) ∥ Σ θ ∥ 2 2 ∥ z t − z θ ( α ˉ t x 0 + 1 − α ˉ t z t , t ) ∥ 2 ] \begin{aligned}L_t&=\mathbb{E}_{ {\bf{x}}_0,{\bf{z}}}\left[\frac{1}{2\|{\bf{\Sigma}}_\theta({\bf{x}}_t,t)\|_2^2}\|\tilde{\boldsymbol{\mu}}_t({\bf{x}}_t,{\bf{x}}_0)-{\boldsymbol{\mu}}_\theta({\bf{x}}_t,t)\|^2\right]\\&=\mathbb{E}_{ {\bf{x}}_0,{\bf{z}}}\left[\frac{1}{2\|{\bf{\Sigma}}_\theta\|_2^2}\left\|\frac{1}{\sqrt{\alpha}_t}\left({\bf{x}}_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}}}{\bf{z}}\right)-\frac{1}{\sqrt{\alpha}_t}\left({\bf{x}}_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}}}{\bf{z}}_\theta({\bf{x}}_t,t)\right)\right\|\right]\\&=\mathbb{E}_{ {\bf{x}}_0,{\bf{z}}}\left[\frac{\beta^2_t}{2\alpha_t(1-\bar{\alpha}_t)\|{\bf{\Sigma}}_\theta\|_2^2}\|{\bf{z}}_t-{\bf{z}}_\theta({\bf{x}}_t,t)\|^2\right]\\&=\mathbb{E}_{ {\bf{x}}_0,{\bf{z}}}\left[\frac{\beta^2_t}{2\alpha_t(1-\bar{\alpha}_t)\|{\bf{\Sigma}}_\theta\|_2^2}\|{\bf{z}}_t-{\bf{z}}_\theta(\sqrt{\bar{\alpha}_t}{\bf{x}}_0+\sqrt{1-\bar{\alpha}_t}{\bf{z}}_t,t)\|^2\right]\end{aligned} Lt=Ex0,z[2∥Σθ(xt,t)∥221∥μ~t(xt,x0)−μθ(xt,t)∥2]=Ex0,z[2∥Σθ∥221∥∥∥∥αt1(xt−1−αˉβtz)−αt1(xt−1−αˉβtzθ(xt,t))∥∥∥∥]=Ex0,z[2αt(1−αˉt)∥Σθ∥22βt2∥zt−zθ(xt,t)∥2]=Ex0,z[2αt(1−αˉt)∥Σθ∥22βt2∥zt−zθ(αˉtx0+1−αˉtzt,t)∥2]根据经验Ho等人的经验,发现在忽略加权项的简化目标下,训练扩散模型效果更好: L t s i m p l e = E x 0 , z t [ ∥ z t − z θ ( α ˉ t x 0 + 1 − α ˉ t z t , t ) ∥ 2 ] L^{\mathrm{simple}}_t=\mathbb{E}_{ {\bf{x}}_0,{\bf{z}}_t}\left[\|{\bf{z}}_t-{\bf{z}}_\theta(\sqrt{\bar{\alpha}_t}{\bf{x}}_0+\sqrt{1-\bar{\alpha}_t}{\bf{z}}_t,t)\|^2\right] Ltsimple=Ex0,zt[∥zt−zθ(αˉtx0+1−αˉtzt,t)∥2]所以最终简化后的目标函数是: L s i m p l e = L s i m p l e + C L_{\mathrm{simple}}=L^{\mathrm{simple}}+C Lsimple=Lsimple+C其中 C C C是不取决于 θ \theta θ的常数。
6 噪声评分条件网络(NCSN)
Song和Ermon等人提出了一种基于分数的生成建模方法,其中样本是通过Langevin动力学使用分数匹配估计的数据分布梯度生成的。每个样本 x \bf{x} x的密度概率得分定义为其梯度 ∇ x log p ( x ) \nabla_{\bf{x}}\log p({\bf{x}}) ∇xlogp(x)。训练一个分数网络 s θ : R D → R D s_\theta:\mathbb{R}^D\rightarrow\mathbb{R}^D sθ:RD→RD来估计它。为了在深度学习设置中使用高维数据使其可扩展,有研究建议使用去噪分数匹配(向数据添加预先指定的小噪声)或切片分数匹配。Langevin动力学可以仅使用迭代过程中的分数从概率密度分布中采样数据点 ∇ x log p ( x ) \nabla_{\bf{x}}\log p({\bf{x}}) ∇xlogp(x)。然而,根据流形假设,大多数数据预计集中在低维流形中,即使观察到的数据可能看起来只是任意高维。由于数据点无法覆盖整个空间 R D \mathbb{R}^D RD,因此对分数估计产生了负面影响。在数据密度低的区域,分数估计不太可靠。添加一个小的高斯噪声使扰动的数据分布覆盖整个空间后,分数评估网络的训练变得更加稳定。 Song和Ermon等人通过用不同级别的噪声扰动数据来改进它,并训练一个噪声条件评分网络来共同估计所有扰动数据在不同噪声级别下的分数。
7 β t \beta_t βt和 Σ θ {\bf{\Sigma}}_\theta Σθ的参数化
参数化 β t \beta_t βt的过程中,Ho等人将前向方差被设置为一系列线性增加的常数,从 β 1 = 1 0 − 4 \beta_1=10^{-4} β1=10−4到 β T = 0.02 \beta_T=0.02 βT=0.02。与 [ − 1 , 1 ] [-1,1] [−1,1]之间的归一化图像像素值相比,它们相对较小。在此设置下实验中的扩散模型生成了高质量的样本,但仍然无法像其他生成模型那样实现具有竞争力。Nichol和Dhariwal等人提出了几种改进技术来帮助扩散模型获得更低的NLL。 其中一项改进是使用基于余弦的方差计划。调度函数的选择可以是任意的,只要它在训练过程的中间提供一个近线性的下降和围绕 t = 0 t=0 t=0和 t = T t=T t=T的细微变化 β t = c l i p ( 1 − α ˉ t α t − 1 , 0.999 ) α ˉ t = f ( t ) f ( 0 ) w h e r e f ( t ) = cos ( t / T + s 1 + s ⋅ π 2 ) \beta_t=\mathrm{clip}(1-\frac{\bar{\alpha}_t}{\alpha_{t-1}},0.999)\quad \bar{\alpha}_t=\frac{f(t)}{f(0)} \quad \mathrm{where}\text{ } f(t)=\cos(\frac{t/T+s}{1+s}\cdot \frac{\pi}{2}) βt=clip(1−αt−1αˉt,0.999)αˉt=f(0)f(t)where f(t)=cos(1+st/T+s⋅2π)其中当 t = 0 t=0 t=0时小偏移量 s s s是为了防止 β t \beta_t βt接近时太小。
参数化 Σ θ {\bf{\Sigma}}_\theta Σθ的过程中,Ho等人选择固定 β t \beta_t βt为常量,而不是使它们可学习并设置 Σ θ ( x t , t ) = σ t 2 I {\bf{\Sigma}}_\theta({\bf{x}}_t,t)=\sigma^2_t{\bf{I}} Σθ(xt,t)=σt2I, 其中 σ t \sigma_t σt是不可学习的。实验发现学习对角方差 Σ θ {\bf{\Sigma}}_\theta Σθ会导致训练不稳定和样本质量下降。Nichol和Dhariwal等人提出将学习 Σ θ ( x t , t ) {\bf{\Sigma}}_\theta({\bf{x}}_t,t) Σθ(xt,t)作为 β \beta β和 β ~ t \tilde{\beta}_t β~t之间的插值,通过模型预测混合向量 v {\bf{v}} v,则有: Σ θ ( x t , t ) = exp ( v log β t + ( 1 − v ) log β ~ t ) {\bf{\Sigma}}_\theta({\bf{x}}_t,t)=\exp({\bf{v}}\log \beta_t+(1-{\bf{v}})\log\tilde{\beta}_t) Σθ(xt,t)=exp(vlogβt+(1−v)logβ~t)简单的目标 L s i m p l e L_{\mathrm{simple}} Lsimple并不依赖于 Σ θ {\bf{\Sigma}}_\theta Σθ。为了增加依赖性,他们构建了一个混合目标 L h y b r i d = L s i m p l e + λ L V L B L_{\mathrm{hybrid}}=L_{\mathrm{simple}}+\lambda L_{\mathrm{VLB}} Lhybrid=Lsimple+λLVLB,其中 λ = 0.001 \lambda=0.001 λ=0.001很小并且停止在 μ θ \boldsymbol{\mu}_\theta μθ的梯度,以便 L V L B L_{\mathrm{VLB}} LVLB仅指导 Σ θ {\bf{\Sigma}}_\theta Σθ的学习。可以观察到,由于梯度噪声,优化 L V L B L_{\mathrm{VLB}} LVLB是非常困难的,因此他们建议使用具有重要性采样的时间平均平滑版本。
8 加速扩散模型采样
通过遵循反向扩散过程的马尔可夫链从DDPM生成样本非常慢,可能长达一个或几千个步骤。从DDPM中采样 50000 50000 50000个大小为 32 × 32 32\times32 32×32的图像大约需要 20 20 20小时,但从Nvidia 2080 Ti GPU上的GAN中采样不到一分钟。一种简单的方法是运行跨步抽样计划,每一步都进行抽样更新,以减少中间的采样过程。对于另一种方法,需要重写 q σ ( x t ∣ x t , x 0 ) q_\sigma({\bf{x}}_t|{\bf{x}}_t,{\bf{x}}_0) qσ(xt∣xt,x0)以通过所需的标准偏差 σ t \sigma_t σt进行参数化: x t − 1 = α ˉ t − 1 x 0 + 1 − α ˉ t − 1 z t − 1 = α ˉ t − 1 x 0 + 1 − α ˉ t − 1 − σ t 2 z t + σ t z = α ˉ t − 1 x 0 + 1 − α ˉ t − 1 − σ t 2 x t − α ˉ t x 0 1 − α ˉ t + σ t z q σ ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; α ˉ t − 1 x 0 + 1 − α ˉ t − 1 − σ t 2 x t − α ˉ t x 0 1 − α ˉ t , σ t 2 I ) \begin{aligned}{\bf{x}}_{t-1}&=\sqrt{\bar{\alpha}_{t-1}}{\bf{x}}_0+\sqrt{1-\bar{\alpha}_{t-1}}{\bf{z}}_{t-1}\\&=\sqrt{\bar{\alpha}_{t-1}}{\bf{x}}_0+\sqrt{1-\bar{\alpha}_{t-1}-\sigma^2_t{\bf{z}}_t}+\sigma_t{\bf{z}}\\&=\sqrt{\bar{\alpha}_{t-1}}{\bf{x}}_0+\sqrt{1-\bar{\alpha}_{t-1}-\sigma^2_t}\frac{ {\bf{x}}_t-\sqrt{\bar{\alpha}_t}{\bf{x}}_0}{\sqrt{1-\bar{\alpha}_t}}+\sigma_t{\bf{z}}\\q_\sigma&({\bf{x}}_{t-1}|{\bf{x}}_t,{\bf{x}}_0)=\mathcal{N}\left({\bf{x}}_{t-1};\sqrt{\bar{\alpha}_{t-1}}{\bf{x}}_0+\sqrt{1-\bar{\alpha}_{t-1}-\sigma^2_t}\frac{ {\bf{x}}_t-\sqrt{\bar{\alpha}_t}{\bf{x}}_0}{1-\bar{\alpha}_t},\sigma^2_t{\bf{I}}\right)\end{aligned} xt−1qσ=αˉt−1x0+1−αˉt−1zt−1=αˉt−1x0+1−αˉt−1−σt2zt+σtz=αˉt−1x0+1−αˉt−1−σt21−αˉtxt−αˉtx0+σtz(xt−1∣xt,x0)=N(xt−1;αˉt−1x0+1−αˉt−1−σt21−αˉtxt−αˉtx0,σt2I)因为 q ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; μ ~ ( x t , x 0 , β ~ t I ) ) q({\bf{x}}_{t-1}|{\bf{x}}_t,{\bf{x}}_0)=\mathcal{N}({\bf{x}}_{t-1};\tilde{\boldsymbol{\mu}}({\bf{x}}_t,{\bf{x}}_0,\tilde{\beta}_t{\bf{I}})) q(xt−1∣xt,x0)=N(xt−1;μ~(xt,x0,β~tI)),因此则有 β ~ t = σ t 2 = 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t \tilde{\beta}_t=\sigma^2_t=\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t}\cdot \beta_t β~t=σt2=1−αˉt1−αˉt−1⋅βt令 σ t 2 = η ⋅ β ~ t \sigma^2_t=\eta \cdot \tilde{\beta}_t σt2=η⋅β~t,进而可以通过调整为超参数 η ∈ R + \eta\in \mathbb{R}^{+} η∈R+来控制采样随机性。 η = 0 \eta=0 η=0的特殊情况使采样过程具有确定性,这样的模型被命名为去噪扩散隐式模型(DDIM)。DDIM具有相同的边际噪声分布,但确定性地将噪声映射回原始数据样本。在生成过程中,只对扩散步骤的一个子集 S S S进行采样为 { τ 1 , ⋯ , τ S } \{\tau_1,\cdots,\tau_S\} { τ1,⋯,τS},推理过程变为: q σ , τ ( x τ i − 1 ∣ x τ t , x 0 ) = N ( x τ i − 1 ; α ˉ t − 1 x 0 + 1 − α ˉ t − 1 − σ t 2 x τ i − α ˉ t x 0 1 − α ˉ t , σ t 2 I ) q_{\sigma,\tau}({\bf{x}}_{\tau_{i-1}}|{\bf{x}}_{\tau_t},{\bf{x}}_0)=\mathcal{N}({\bf{x}}_{\tau_{i-1}};\sqrt{\bar{\alpha}_{t-1}}{\bf{x}}_0+\sqrt{1-\bar{\alpha}_{t-1}-\sigma_t^2}\frac{ {\bf{x}}_{\tau_i}-\sqrt{\bar{\alpha}_t}{\bf{x}}_0}{\sqrt{1-\bar{\alpha}_t}},\sigma^2_t{\bf{I}}) qσ,τ(xτi−1∣xτt,x0)=N(xτi−1;αˉt−1x0+1−αˉt−1−σt21−αˉtxτi−αˉtx0,σt2I)可以观察到DDIM在较小采样数的情况下可以产生最佳质量的样本,而DDPM在较小采样数的情况下表现要差得多。使用 DDIM可以将扩散模型训练到任意数量的前向步骤,但只能从生成过程中的步骤子集进行采样。总结来说,与DDPM相比,DDIM优点如下:
- 使用更少的步骤生成更高质量的样本。
- 由于生成过程是确定性的,因此具有“一致性”属性,这意味着以相同隐变量为条件的多个样本应该具有相似的高级特征。
- 由于一致性,DDIM可以在隐变量中进行语义上有意义的插值。
9 条件生成
在ImageNet数据上训练生成模型时,通常会生成以类标签为条件的样本。为了明确地将类别信息纳入扩散过程,Dhariwal和Nichol对噪声图像 x t {\bf{x}}_t xt训练了一个分类器 f ϕ ( y ∣ x t , t ) f_\phi(y|{\bf{x}}_t,t) fϕ(y∣xt,t),并使用梯度 ∇ x log f ϕ ( y ∣ x t , t ) \nabla_{ {\bf{x}}} \log f_{\phi}(y|{\bf{x}}_t,t) ∇xlogfϕ(y∣xt,t)来引导扩散采样过程朝向目标类别标签 y y y。消融扩散模型 (ADM) 和带有附加分类器引导的模型 (ADM-G) 能够获得比当前最好生成模型(BigGAN)更好的结果。此外,Dhariwal和Nichol等人通过对UNet架构进行一些修改,显示出比具有扩散模型的GAN更好的性能。模型架构修改包括更大的模型深度/宽度、更多注意力头、多分辨率注意力、用于上/下采样的BigGAN残差块、残差连接重新缩放和自适应组归一化 (AdaGN)。
边栏推荐
- Windows starts redis service
- 超十万字_超详细SSM整合实践_手动实现权限管理
- Mysql数据库-锁-学习笔记
- Over 100000 words_ Ultra detailed SSM integration practice_ Manually implement permission management
- Cesium load vector data
- Leetcode daily questions (2316. count unreachable pairs of nodes in an undirected graph)
- STM32 and motor development (from stand-alone version to Networking)
- The configuration and options of save actions are explained in detail, and you won't be confused after reading it
- Oracle installation enhancements error
- ViewPager2和VIewPager的区别以及ViewPager2实现轮播图
猜你喜欢
Sublime Text4 download the view in bower and set the shortcut key
Huawei HCIP - datacom - Core 03 jours
![[4g/5g/6g topic foundation-146]: Interpretation of white paper on 6G overall vision and potential key technologies-1-overall vision](/img/fd/5e8f74da25d9c5f7bd69dd1cfdcd61.png)
[4g/5g/6g topic foundation-146]: Interpretation of white paper on 6G overall vision and potential key technologies-1-overall vision
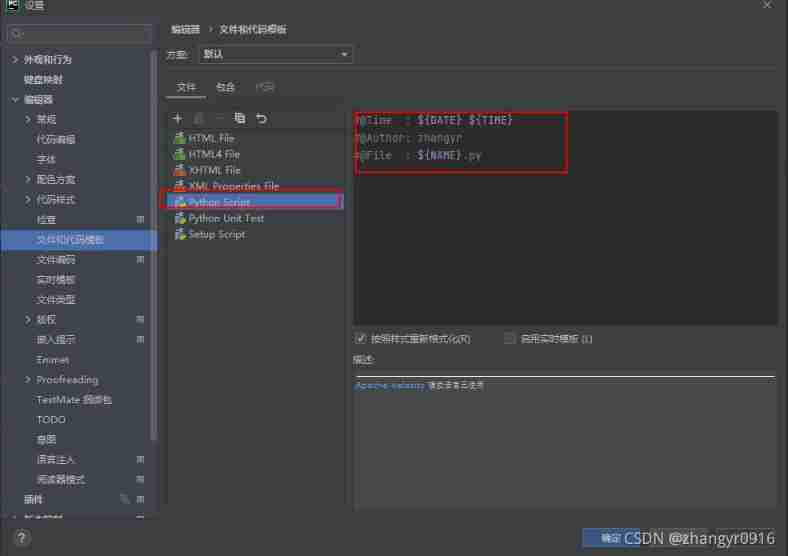
Pycharm create a new file and add author information

Mysql database lock learning notes
第一讲:寻找矩阵的极小值
四、机器学习基础

ComputeShader
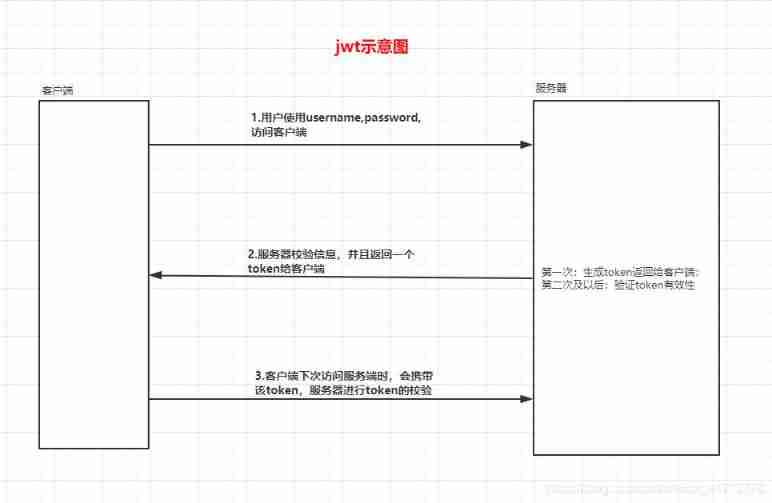
Using JWT to realize login function

战略合作|SubQuery 成为章鱼网络浏览器的秘密武器
随机推荐
牛客网——华为题库(61~70)
在EXCEL写VBA连接ORACLE并查询数据库中的内容
如何成为一名高级数字 IC 设计工程师(5-2)理论篇:ULP 低功耗设计技术精讲(上)
Kubernetes cluster capacity expansion to add node nodes
嵌套(多级)childrn路由,query参数,命名路由,replace属性,路由的props配置,路由的params参数
进程和线程的区别
Binary tree high frequency question type
Postman setting environment variables
Windows starts redis service
scrapy爬虫mysql,Django等
Variable parameter of variable length function
Difference between process and thread
Interface test API case, data and interface separation
sqlplus乱码问题,求解答
Idea development environment installation
The use of recycling ideas
Pycharm importing third-party libraries
H5 web player easyplayer How does JS realize live video real-time recording?
超十万字_超详细SSM整合实践_手动实现权限管理
JS逆向教程第一发