当前位置:网站首页>CVPR 2022 | transfusion: Lidar camera fusion for 3D target detection with transformer
CVPR 2022 | transfusion: Lidar camera fusion for 3D target detection with transformer
2022-07-04 13:12:00 【Zhiyuan community】

Paper title :TransFusion: Robust LiDAR-Camera Fusion for 3D Object Detection with Transformers
Author's unit : Hong Kong University of science and technology , Huawei IAS BU, City University of Hong Kong
The paper :
https://openaccess.thecvf.com/content/CVPR2022/papers/Bai_TransFusion_Robust_LiDAR-Camera_Fusion_for_3D_Object_Detection_With_Transformers_CVPR_2022_paper.pdf
Code :https://github.com/xuyangbai/transfusion
Reading guide
Although sensor fusion is becoming more and more popular in this field , But for poor image conditions ( Such as poor lighting and sensor misalignment ) The robustness of has not been fully studied . Existing fusion methods are vulnerable to these conditions , It is mainly due to the hard correlation between lidar points and image pixels established through the calibration matrix . We have put forward TransFusion, A powerful solution , With LiDAR-camera Fusion and soft correlation mechanism , To deal with poor image conditions . say concretely , our TransFusion By convolution backbone and based on Transformers The detection head of the decoder consists of . The first layer of the decoder uses sparse object queries Set prediction comes from LiDAR Initial bounding box of point cloud , Its second layer decoder adaptively converts object queries Fusion with useful image features , Make full use of space and context .Transformers Our attention mechanism enables our model to adaptively decide what information to obtain from the image and where to obtain information , So as to form a robust and effective fusion strategy . Besides , We also designed an image guided query Initialize policies to handle objects that are difficult to detect in the point cloud .

contribution
stay nuScenes and Waymo On ,LiDAR-only Method is better than multimodal method . But obviously , The light on LiDAR It's not enough. , Some small objects are just a few points , It's hard to recognize , However, it is still relatively clear on high-resolution images . The current fusion methods are roughly divided into 3 class : Result level 、 Proposal level and point level .
result-level:FPointNet,RoarNet etc. , Include FPointNet and RoarNet , Use 2D Detector to seed 3D proposal, And then use PointNet Locate the object .
proposal-level:MV3D,AVOD etc. . Because the region of interest usually contains a lot of background noise , The results of these coarse-grained fusion methods are not ideal . Include MV3D and AVOD, By sharing proposal In each mode of RoIPool In area proposal Level execution fusion . Due to rectangular region of interest (RoI) It usually contains a lot of background noise , Therefore, the results of these coarse-grained fusion methods are not satisfactory .
point-level : Split score :PointPainting,FusionPainting,CNN features :EPNet,MVXNet,PointAugmenting etc. . lately , Most methods try point level fusion , The result is right . First, find LiDAR points and image pixels The hard connection between (hard association), Then through point by point splicing , Use the segmentation score of the associated pixel or CNN Features to enhance LiDAR features .
Despite impressive improvements , These point level fusion methods still have two main problems : First , They fuse lidar features with image features by cascading or adding elements , When the quality of image features is low , Serious performance degradation . secondly , Look for sparse LiDAR Hard correlation between points and dense image pixels , It not only wastes a lot of image features with rich semantic information , And it depends heavily on the high-quality calibration between the two sensors , Due to the inherent space-time deviation , Such calibration is often difficult to obtain .
In general, there are two problems :(1) The quality of image features cannot be guaranteed (2) The external parameters of the sensor are inaccurate , A small error will cause alignment failure .
Our key idea is to reposition the focus of the integration process , From hard correlation to soft Correlation , To cause robustness degradation, image quality and sensor misalignment . say concretely , We designed one that uses two Transformers The decoder layer is used as the sequential fusion method of the detection head . Our first decoder layer utilizes sparse object queries Set according to LiDAR Feature generates the initial bounding box . And 2D Input independent object queries in [2,45] Different , We make object queries input dependent and category aware , So that the query has better location and category information . Next , The second transformer decoder layer adaptively fuses objects to query spatial and contextual relationships related to useful image features . We use local induced deviation , Space constraints are applied to the cross attention around the initial bounding box , To help the network better access relevant locations . Our fusion module not only provides rich semantic information for the target query , And because the correlation between lidar points and image pixels is soft 、 Adaptive way , Therefore, it has stronger robustness to poor image conditions . Last , For objects that are difficult to detect in the point cloud , The image guided query initialization module is introduced , Image guidance is introduced in the query initialization stage . contribution :
(1) Our research explores and reveals an important aspect of robust fusion , That is, soft correlation mechanism .
(2) We propose a new method based on Transformers Laser radar of - Camera fusion model is used for 3D detection , The model is fused with coarse granularity in detail , It shows excellent robustness to degraded image quality and sensor misalignment .
(3) We introduced several simple and effective adjustment object queries , To improve the quality of the initial bounding box prediction of image fusion . The image guided query initialization module is also designed to deal with objects that are difficult to detect in the point cloud
Method

As shown in the figure above , Given a LiDAR BEV feature map and image feature map, Our work is based on Transformer The detection head of the first use LiDAR Information will Object query Decode to the initial bounding box prediction , Then through the attention mechanism Object query Fusion with useful image features , Conduct LiDAR-camera The fusion .
3.1. Preliminary: Transformer for 2D Detection

DETR

from DETR Start ,Transformer Began to be widely used in target detection .DETR Used a CNN Extraction of image features , And use Transformer Architecture will be learned by a small group embeddings( be called object queries) Convert to a set of predictions . There are some ways to object queries Further added location information . In our work , Every object queries Contains a query position And a query feature Code instance information , Such as the size of the box 、 Direction, etc .
3.2. Query Initialization
Input-dependent. In groundbreaking works [2,45,71] in ,query position Random generation or learning as network parameters , It has nothing to do with the input data . This input independent query position Additional stages are required ( Decoder layer ) For their model [2,71] Learn the process of moving to the center of real objects . lately , In two-dimensional target detection [57] Found in , Through better object queries initialization , Can make up 1 Layer structure and 6 The gap between layer structures . Inspired by this , We propose a method based on center heatmap Input related initialization strategy , To achieve competitive performance using only one decoding layer .
Just specific , Given a XYD Of LiDAR BEV features , We first predict the heat map of a specific class ,X*Y*K,XY Is the size of the feature map ,K Is the number of species . then , We regard the heat map as X × Y × K Object candidates , And select the top of all categories n Candidates as our initial object queries. In order to avoid queries with too closed space , stay [66] after , We select the local maximum element as our object query , Its value is greater than or equal to their 8 Connected neighbors . otherwise , Need a lot of queries Cover BEV Plane . The positions and characteristics of the selected candidate objects are used for initialization query positions and query features. such , Our initial object query will be located at or near the center of the potential object , Eliminate the need for multiple decoder layers to refine location .
Category-aware. BEV All objects on the plane are of absolute scale , The scale variance between the same category is small . In order to make better use of these attributes for multi class detection , We pass for each object queries Category embedding , send object queries Category Awareness . To be specific , Use each selected candidate category ( for example Sˆijk Belong to the first k Categories ), By linearly projecting a popular category vector onto Rd The category generated by the vector is embedded , Sum the elements of query features wisely . Category embedding has two advantages : One side , It can be used as an object in the modeling self attention module - Objects in the object relation and cross attention module - Useful side information of context ; On the other hand , In the prediction of the , It can transfer the valuable prior knowledge of the object , Make the network focus on the variance within the category , Thus, it is conducive to attribute prediction .
3.3. Transformer Decoder and FFN
The decoding structure follows DETR,object queries And feature mapping ( Point cloud or image ) The cross attention between them gathers the relevant context on the candidate objects , and object queries Self attention between leads to pairwise relationships between different candidates .query positions Through multilayer perceptron (MLP) Embedded in d Dimensional position coding , And sum the elements one by one according to the query characteristics . This enables the network to infer context and location at the same time .
N Contains rich instance information object queries By feedforward network (FFN) Independently decoded into boxes and class labels . from object queries The predicted center point offset ,log(l),log(w),log(h). Yaw angle sin(α), cos(α) ,x,y Speed in direction , We also predict a class probability . Each attribute consists of a separate two layers 1×1 Convolution calculation . By parallelizing each object queries Decode to prediction , We get a set of predictions {ˆbt, pˆt}N t As the output , among ˆbt It's No i Prediction bounding box of queries . similar 3DETR, We use the auxiliary decoding mechanism , After each decoder layer FFN And supervision ( That is, each decoding layer counts as one LOSS). therefore , We can get the initial boundary box prediction from the first decoder layer . We are LiDAR-camera These initial predictions are used in the fusion module to constrain cross attention , As described in the following section .
3.4. LiDAR-Camera Fusion
Image feature extraction We do not obtain multi view image features based on the hard correlation between lidar points and image pixels . contrary , We keep all image features FC∈RNv×H×W ×d As our repository , And make use of Transformer Cross attention mechanism in decoder , With sparse dense 、 Feature fusion in an adaptive way .
SMCA for Image Feature Fusion
In order to reduce the sensitivity of hard correlation strategy to sensor calibration and the inferiority of image features , We use the cross attention mechanism to establish LiDAR Soft association with images , The network can adaptively determine what information and where to get from the image .
suffer [9] Inspired by the , We designed a spatial modulation cross attention (SMCA) modular , The module measures cross attention through a two-dimensional circular Gaussian mask , This module revolves around the projection of each query 2D center ( Only the prediction results of point cloud are used to project onto the image according to external parameters ). Two dimensional Gaussian weight mask M The generation method and CenterNet similar . Then this weight graph is multiplied by the cross attention graph between all attention heads . such , Every object queries Focus only on projection 2D The relevant area around the box , In this way, the network can according to the input LiDAR Features learn which image features to choose better and faster . The attention map is shown in the figure below 3 Shown .


The network usually tends to focus on foreground pixels close to the center of the object , Ignore irrelevant pixels , It provides valuable semantic information for object classification and bounding box regression . stay SMCA after , We use another FFN, Use contains LiDAR And image information object queries To produce ffinal bound box forecast .
3.5. Label Assignment and Losses
reference DETR, We find the two-part matching Hungarian algorithm between the predicted object and the real object [13].

3.6. Image-Guided Query Initialization
Because our object query only uses the characteristics of lidar , It may lead to sub optimal detection recall . From experience , Our model has achieved high recall , And showed superior performance on the baseline ( The first 5 section ). However , In order to further use the ability of high-resolution images to detect small targets , And make our algorithm more robust to LIDAR point clouds in sparse cases , We propose an image guided query initialization strategy . utilize LiDAR And camera information selection object queries.

experiment
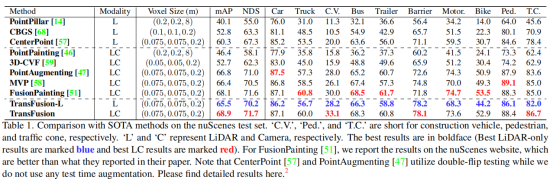
This article is mainly about nuScenes、Waymo Open Experimental analysis was carried out on two data sets . stay nuScenes The experimental results on are shown in the table above , As shown in the table 1 Shown , our TransFusion-L It has been significantly superior to the most advanced LiDAR methods (+5.2%mAP,+2.9%NDS), Even more than some multimodal methods . We attribute this performance gain to Transformer The relationship modeling ability of decoder and the proposed query initialization strategy .

The author is in the table 2 Reported in Waymo On validation set , The performance of this model on all three classes . among , The integration strategy combines pedestrians and bicycle classes mAPH Improved respectively 0.3 Times and 1.5 times . We suspect that there are two reasons for the relatively small improvements brought about by image components . First , The semantic information of the image may be right Waymo The coarse-grained classification has little influence . secondly , The initial bounding box from the first decoder layer already has a precise location , because Waymo The point cloud in is denser than that in other scenes . As shown in the table 3 Shown , Our model is significantly better than the central point , And in nuScenes New and most advanced results are set on the tracking leaderboard .

First of all, according to nuScenes The scenario description provided divides the verification set into day and night , And on the table 4 The performance gains under different conditions are shown in . Our method brings a greater performance improvement at night , Among them, the poor optical note pair is based on the fusion strategy of hard Correlation CC and PA Have a negative impact .

As shown in the table 5 Shown , Compared with other fusion methods ,TransFusion Better robustness .
边栏推荐
- Runc hang causes the kubernetes node notready
- CTF竞赛题解之stm32逆向入门
- 17. Memory partition and paging
- Golang sets the small details of goproxy proxy proxy, which is applicable to go module download timeout and Alibaba cloud image go module download timeout
- Definition of cognition
- 【Android Kotlin】lambda的返回语句和匿名函数
- Excuse me, have you encountered this situation? CDC 1.4 cannot use timestamp when connecting to MySQL 5.7
- Efficient! Build FTP working environment with virtual users
- 阿里云有奖体验:用PolarDB-X搭建一个高可用系统
- Fundamentals of container technology
猜你喜欢


随机推荐
用fail2ban阻止密码尝试攻
Deploy halo blog with pagoda
Zhongang Mining: in order to ensure sufficient supply of fluorite, it is imperative to open source and save flow
R language -- readr package reads and writes data
C語言函數
CANN算子:利用迭代器高效实现Tensor数据切割分块处理
2022年中国移动阅读市场年度综合分析
Detailed explanation of mt4api documentary and foreign exchange API documentary interfaces
强化学习-学习笔记1 | 基础概念
Definition of cognition
VIM, another program may be editing the same file If this is the solution of the case
从0到1建设智能灰度数据体系:以vivo游戏中心为例
CANN算子:利用迭代器高效实现Tensor数据切割分块处理
runc hang 导致 Kubernetes 节点 NotReady
一个数据人对领域模型理解与深入
Annual comprehensive analysis of China's mobile reading market in 2022
Fastlane one click package / release app - usage record and stepping on pit
Vit (vision transformer) principle and code elaboration
C語言:求100-999是7的倍數的回文數
阿里云有奖体验:用PolarDB-X搭建一个高可用系统