当前位置:网站首页># ODS及DWD层自动化构建##, 220731,
# ODS及DWD层自动化构建##, 220731,
2022-08-02 02:57:00 【啊六六六】




OracleMetaUtil:根据表名从Oracle中获取这张表的元数据

限定元素类型,,

stored as orc

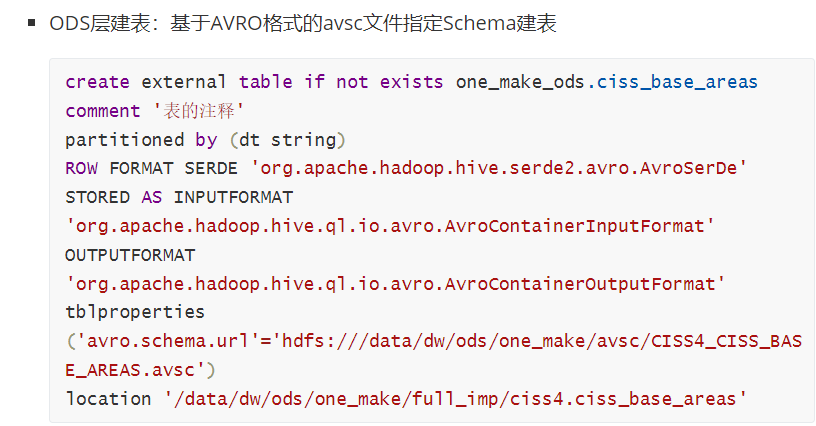
ODS层建表的时候不用指定列
Avro格式的Schema文件
hdfs放文件,自动映射,,
普通表:表的目录下就是文件



手动将数据同步到HDFS
实现自动化建表:表对应HDFS地址
申明分区


修改partition(dt=),修改hdfs,,
为什么没有数据??怎么添加数据??
为了避免读取整张表的所有数据,只读取这个分区的数据
HiveSQL来生成分区
load xxx into table partition
insert into table partition (dt) select …… dt from table
数据清洗(Data cleaning)是对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。空值,,重复值,,
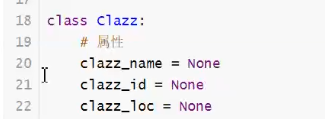
class是关键词,,

list[学生对象]
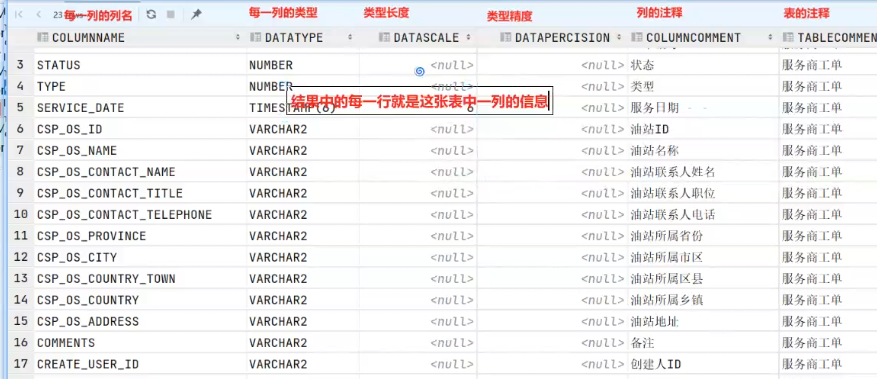


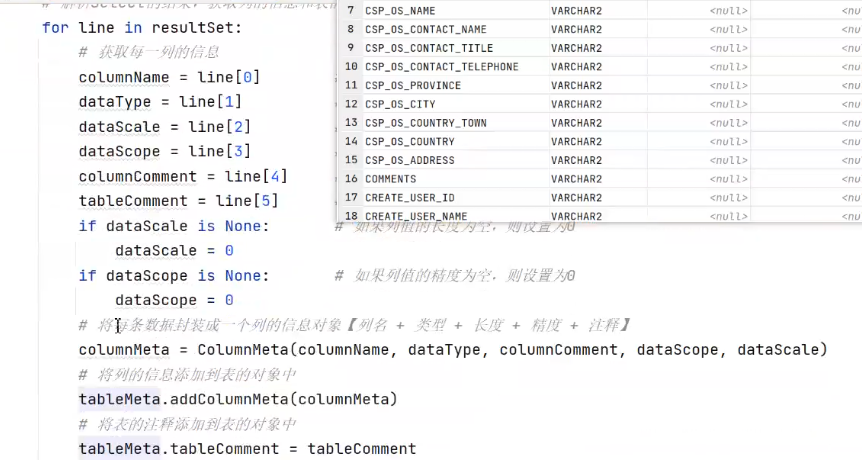



dwd字段提取思路????????
表名
字段名
select
for
元数据对象,,添加对象,
注释,

列表推导式
flatmap


int:整形
float:浮点型

自动化就是1拼接字段,2schma文件格式,,,
难点就是封装类,模块,
读文件可以复用一个工具类,,

指定了分区的值:叫做静态
根据一列的值自动划分:叫做动态
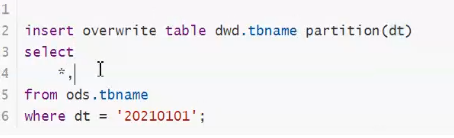
差一列,就注意动态分区和静态分区问题,,,
review,,,,,,
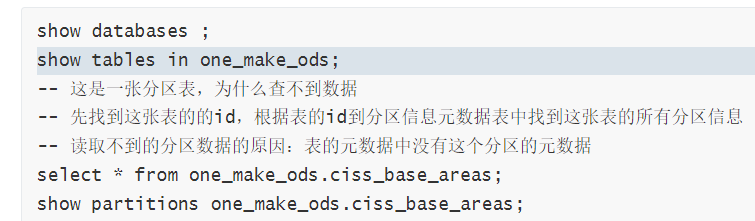
视频注释???
有时间总结一下大致思路,总的+细节难点,,
ods层
获取数据库连接,创建库,
表名列表循环创建表,全量增量表,
拼接SQL,(获取连接,表名),(拼接建表语句,),获取表的注释通过Oracle,通过表名对应存储格式,location中判断分层 全量增量表 表名前缀 表名,
游标执行SQL(.join),
ods映射表流程,申明分区,
说明分区位置,
1msck修复分区,
2alter xxx partition(dt=20210101),循环拼接SQL,alter xxx partition(dt=20210101),修改location修改所在的hdfs地址,
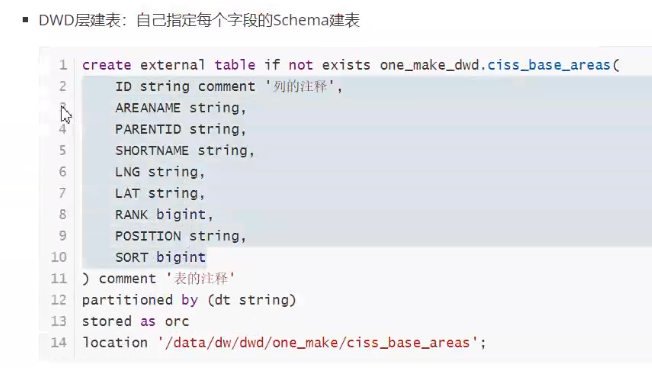
dwd层,
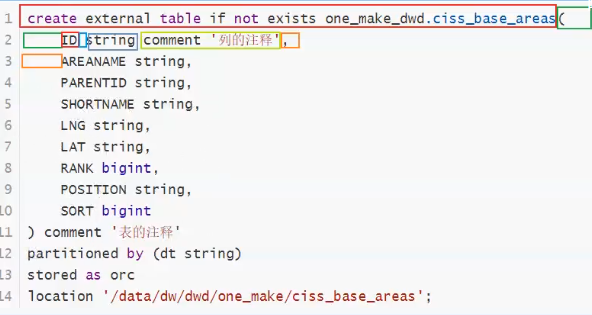
建表,select,for每一行遍历各个列,获取到字段信息,表名,注释,
全量增量表区分,sqoop数据同步不一样,,Oracle数据类型和sparkSQL不一样,
步骤
SparkSQL连接,
拼接建库语句,库名变量,
获取表名,append拼接,
获取Oracle字段,
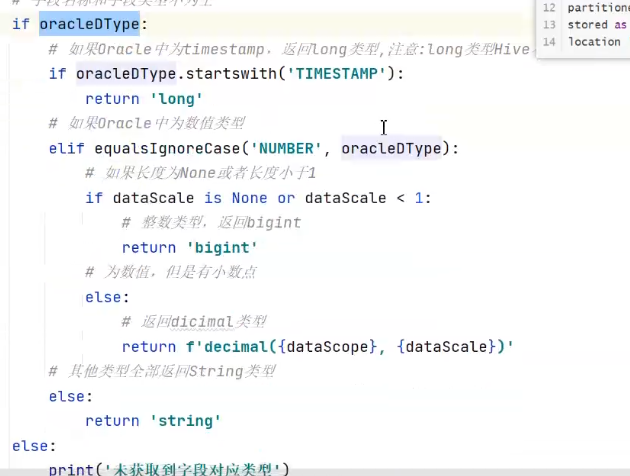
数据类型,(if判断,timestamp--long,精度为0或1--bigint或decimal,string),pop(-1)删除最后一位,,
dwd的hdfs路径,,
自动化建表,循环表名,拼接SQL,游标执行,
抽取数据,,partition固定值抽取数据要少一个,,
preview
边栏推荐
- 架构:分布式任务调度系统(SIA-Task)简介
- Navicat cannot connect to database Mysql because of WiFi
- 7-43 字符串关键字的散列映射 (25 分) 谜之测试点
- pyqt上手体验
- 2022年最新一篇文章教你青龙面板拉库,拉取单文件,安装依赖,设置环境变量,解决没有或丢失依赖can‘t find module之保姆教程(附带几十个青龙面板脚本仓库)
- CentOS7安装Oracle数据库的全流程
- 【LeetCode】94.二叉树的中序遍历
- MySQL8--Windows下使用压缩包安装的方法
- MySQL函数(经典收藏)
- Tree Chain Segmentation-
猜你喜欢





随机推荐
OperatingSystemMXBean获取系统性能指标
MySQL函数(经典收藏)
第 304 场力扣周赛
【LeetCode】102.二叉树的层序遍历
Chapter 10_Index Optimization and Query Optimization
【LeetCode】145. Postorder Traversal of Binary Tree
2022年最新一篇文章教你青龙面板拉库,拉取单文件,安装依赖,设置环境变量,解决没有或丢失依赖can‘t find module之保姆教程(附带几十个青龙面板脚本仓库)
mysql8.0.28 download and installation detailed tutorial, suitable for win11
MySQL8 - use under Windows package installation method
iVX低代码平台系列详解 -- 概述篇(二)
Nacos source code analysis topic (1) - environment preparation
JSP Webshell 免杀
VPS8702 VPSC(源特科技)电源管理(PMIC) 封装SOT23-6
面试必备!TCP协议经典十五连问!
指针数组和数组指针
VPS8505 微功率隔离电源隔离芯片 2.3-6V IN /24V/1A 功率管
MySQL8.0.28 installation tutorial
- daily a LeetCode 】 【 9. Palindrome
2W字!详解20道Redis经典面试题!(珍藏版)
DVWA安装教程(懂你的不懂·详细)