当前位置:网站首页>批量归一化(标准化)处理
批量归一化(标准化)处理
2022-07-06 22:40:00 【寅恪光潜】
其实对于样本数据的归一化处理,我们在前面的 Kaggle房价预测的练习(K折交叉验证) 已经做过很好的具体实验,也得到了不错的效果,这里主要侧重单独说下怎么做归一化,以及为什么要做这样一个处理,有什么好处。
当我们拿到数据样本的时候,里面一般都会存在一些比较异常(相对来说偏大或偏小)的样本,或者说样本的离散程度非常的高,这样我们在训练的时候,就需要做一些额外的工作,比如做了归一化处理,会得到以下两点明显的好处。
1、深度模型中的每层输出将更加稳定,因为归一化之后,样本的特征就集中在了一段区间(比如,均值为0,标准差为1),这样就消除了“异常样本”带来的不良影响,由于分布比较均匀,所以将更容易训练出有效的模型。
2、训练的时候,收敛将变快,这对于模型的加深是非常有帮助的。
如何来做归一化呢,方法其实有很多,比如:最大最小标准化、log对数函数归一化、反正切函数归一化、 L2范数归一化等,这里主要介绍在神经网络中比较普遍使用的一种方法,图片比较直观,我们先来看图(挺简单的,求均值与方差,然后做个除法操作即可):

归一化层
先求出平均值和方差,然后特征值减去均值再除以方差,就得到了归一化的处理数据
import d2lzh as d2l
from mxnet import gluon,init,nd,autograd
from mxnet.gluon import nn
#批量归一化
'''
这里多出一个γ和β参数,分别是可学习的拉伸和偏移参数
如果批量归一化无益,这两个参数可以决定对输入X不做归一化处理
moving_mean,moving_var这两个参数为移动平均值和方差,是在整个训练数据集中估算出来的
故训练模式和预测模式的计算结果是不一样的
'''
def batch_norm(X,gamma,beta,moving_mean,moving_var,eps,momentum):
if not autograd.is_training():
#预测模式直接使用估算的移动平均值和方差
X_hat=(X-moving_mean)/nd.sqrt(moving_var+eps)
else:
#训练模式,分为2维(全连接层)与4维(卷积层)
assert(X.ndim in (2,4))
if X.ndim==2:
meanV=X.mean(axis=0)
var=((X-meanV)**2).mean(axis=0)
else:
meanV=X.mean(axis=(0,2,3),keepdims=True)
var=((X-meanV)**2).mean(axis=(0,2,3),keepdims=True)
X_hat=(X-meanV)/nd.sqrt(var+eps)
#更新移动平均的均值和方差
moving_mean = momentum * moving_mean + (1.0 - momentum) * meanV
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y=gamma*X_hat+beta
return Y,moving_mean,moving_var自定义BatchNorm层
#参数num_features在全连接层是输出个数,卷积层是输出通道数
class BatchNorm(nn.Block):
def __init__(self,num_features,num_dims,**kwargs):
super(BatchNorm,self).__init__(**kwargs)
if num_dims==2:
shape=(1,num_features)
else:
shape=(1,num_features,1,1)
#参与求梯度和迭代的拉伸与偏移参数,分别初始化为1和0
self.gamma=self.params.get('gamma',shape=shape,init=init.One())
self.beta=self.params.get('beta',shape=shape,init=init.Zero())
#不参与求梯度和迭代的变量,全在内存上初始化为0
self.moving_mean=nd.zeros(shape)
self.moving_var=nd.zeros(shape)
def forward(self,X):
#如果X不在内存上,将moving_mean,moving_var复制到X所在显存上
if self.moving_mean.context!=X.context:
self.moving_mean=self.moving_mean.copyto(X.context)
self.moving_var=self.moving_var.copyto(X.context)
#保存更新过的moving_mean和moving_var
Y,self.moving_mean,self.moving_var=batch_norm(X,self.gamma.data(),self.beta.data(),self.moving_mean,self.moving_var,eps=1e-5,momentum=0.9)
return Y加了BN层的LeNet模型
#LeNet
net=nn.Sequential()
net.add(nn.Conv2D(6,kernel_size=5),
BatchNorm(6,num_dims=4),nn.Activation('sigmoid'),nn.MaxPool2D(pool_size=2,strides=2),
nn.Conv2D(16,kernel_size=5),
BatchNorm(16,num_dims=4),nn.Activation('sigmoid'),nn.MaxPool2D(pool_size=2,strides=2),
nn.Dense(120),
BatchNorm(120,num_dims=2),nn.Activation('sigmoid'),
nn.Dense(10)
)
lr,num_epochs,batch_size,ctx=1.0,5,256,d2l.try_gpu()
net.initialize(ctx=ctx,init=init.Xavier())
trainer=gluon.Trainer(net.collect_params(),'sgd',{'learning_rate':lr})
train_iter,test_iter=d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch5(net,train_iter,test_iter,batch_size,trainer,ctx,num_epochs)
'''
epoch 1, loss 0.7461, train acc 0.748, test acc 0.827, time 8.1 sec
epoch 2, loss 0.4090, train acc 0.853, test acc 0.858, time 7.9 sec
epoch 3, loss 0.3635, train acc 0.867, test acc 0.822, time 7.8 sec
epoch 4, loss 0.3268, train acc 0.881, test acc 0.775, time 7.7 sec
epoch 5, loss 0.3099, train acc 0.888, test acc 0.857, time 7.6 sec
'''
#打印gamma和beta数据
print(net[1].gamma.data())
'''
[[[[1.5982468]]
[[1.6550801]]
[[1.4356986]]
[[1.1882782]]
[[1.2812225]]
[[1.8739824]]]]
<NDArray 1x6x1x1 @gpu(0)>
'''
print(net[1].beta.data())
'''
[[[[ 1.1335251 ]]
[[-0.18426114]]
[[-0.02497273]]
[[ 0.99639875]]
[[-1.2256573 ]]
[[-2.2048857 ]]]]
'''LeNet模型的简洁实现
从上面可以看出,BN层都放在了激活函数的前面。另外对于批量归一化层,在框架中已有定义,而且不需要指定num_features和num_dims,这些参数都将在延后初始化而自动获取到,我们替换看下效果。
net=nn.Sequential()
net.add(nn.Conv2D(6,kernel_size=5),
nn.BatchNorm(),nn.Activation('sigmoid'),nn.MaxPool2D(pool_size=2,strides=2),
nn.Conv2D(16,kernel_size=5),
nn.BatchNorm(),nn.Activation('sigmoid'),nn.MaxPool2D(pool_size=2,strides=2),
nn.Dense(120),
nn.BatchNorm(),nn.Activation('sigmoid'),
nn.Dense(84),
nn.BatchNorm(),nn.Activation('sigmoid'),
nn.Dense(10)
)
'''
training on gpu(0)
epoch 1, loss 0.6276, train acc 0.779, test acc 0.799, time 5.9 sec
epoch 2, loss 0.3885, train acc 0.859, test acc 0.856, time 5.8 sec
epoch 3, loss 0.3456, train acc 0.875, test acc 0.815, time 5.9 sec
epoch 4, loss 0.3201, train acc 0.885, test acc 0.873, time 5.9 sec
epoch 5, loss 0.3053, train acc 0.888, test acc 0.855, time 6.0 sec
'''不同维度求均值示例
对于求某个维度的均值或方差,这里举例说明下,让大家更直观了解到,在不同维度是如何操作的
import numpy as np
a1=np.arange(10).reshape(2,5)
print(a1)
print(a1[:,0])#查看第一维的第一组数据[0 5]
print(a1.mean(axis=0))#[2.5 3.5 4.5 5.5 6.5]
'''
[[0 1 2 3 4]
[5 6 7 8 9]]
[0 5]
[2.5 3.5 4.5 5.5 6.5]
'''
a2=np.arange(30).reshape(2,3,1,5)
print(a2)
print(a2[:,0,:,:])#查看通道维(NCHW,第二维)的第一组数据
print(a2.mean(axis=(0,2,3)))#[ 9.5 14.5 19.5]
'''
[[[[ 0 1 2 3 4]]
[[ 5 6 7 8 9]]
[[10 11 12 13 14]]]
[[[15 16 17 18 19]]
[[20 21 22 23 24]]
[[25 26 27 28 29]]]]
[[[ 0 1 2 3 4]]
[[15 16 17 18 19]]]
[ 9.5 14.5 19.5]
'''
#保持维度不变
print(a2.mean(axis=(0,2,3),keepdims=True))
'''
[[[[ 9.5]]
[[14.5]]
[[19.5]]]]
形状:(1, 3, 1, 1)
'''边栏推荐
- 关于01背包个人的一些理解
- Terms used in the Web3 community
- Windows are not cheap things
- Comparison between thread and runnable in creating threads
- 程序员上班摸鱼,这么玩才高端!
- Function pointer and pointer function in C language
- npm ERR! 400 Bad Request - PUT xxx - “devDependencies“ dep “xx“ is not a valid dependency name
- A picture to understand! Why did the school teach you coding but still not
- 装饰器基础学习02
- What work items do programmers hate most in their daily work?
猜你喜欢
![Local tool [Navicat] connects to remote [MySQL] operation](/img/e8/a7533bac4a70ab5aa3fe15f9b0fcb0.jpg)
Local tool [Navicat] connects to remote [MySQL] operation

窗口可不是什么便宜的东西

Monitoring cannot be started after Oracle modifies the computer name
C语言中函数指针与指针函数
Programmers go to work fishing, so play high-end!
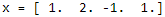
mpf2_ Linear programming_ CAPM_ sharpe_ Arbitrage Pricin_ Inversion Gauss Jordan_ Statsmodel_ Pulp_ pLU_ Cholesky_ QR_ Jacobi

Mysql database (basic)
5G VoNR+之IMS Data Channel概念

JS variable plus

Inventory host list in ansible (I wish you countless flowers and romance)
随机推荐
Oracle -- 视图与序列
Leetcode notes
Code source de la fonction [analogique numérique] MATLAB allcycles () (non disponible avant 2021a)
How to choose an offer and what factors should be considered
Thread和Runnable创建线程的方式对比
Section 1: (3) logic chip process substrate selection
offer如何选择该考虑哪些因素
npm ERR! 400 Bad Request - PUT xxx - “devDependencies“ dep “xx“ is not a valid dependency name
PLC Analog output analog output FB analog2nda (Mitsubishi FX3U)
DFS和BFS概念及实践+acwing 842 排列数字(dfs) +acwing 844. 走迷宫(bfs)
[line segment tree practice] recent requests + area and retrieval - array modifiable + my schedule I / III
STM32 encapsulates the one key configuration function of esp8266: realize the switching between AP mode and sta mode, and the creation of server and client
【Android Kotlin协程】利用CoroutineContext实现网络请求失败后重试逻辑
[practice leads to truth] is the introduction of import and require really the same as what is said on the Internet
ClickHouse(03)ClickHouse怎么安装和部署
Canteen user dish relationship system (C language course design)
In depth analysis of kubebuilder
Ansible报错:“msg“: “Invalid/incorrect password: Permission denied, please try again.“
Oracle - views and sequences
DFS and BFS concepts and practices +acwing 842 arranged numbers (DFS) +acwing 844 Maze walking (BFS)