当前位置:网站首页>【CV-Learning】卷积神经网络
【CV-Learning】卷积神经网络
2022-08-04 05:29:00 【小梁要努力哟】
学习路线
————————————————
首先,应该具有全连接神经网络基础后,才能进行本文的学习。
————————————————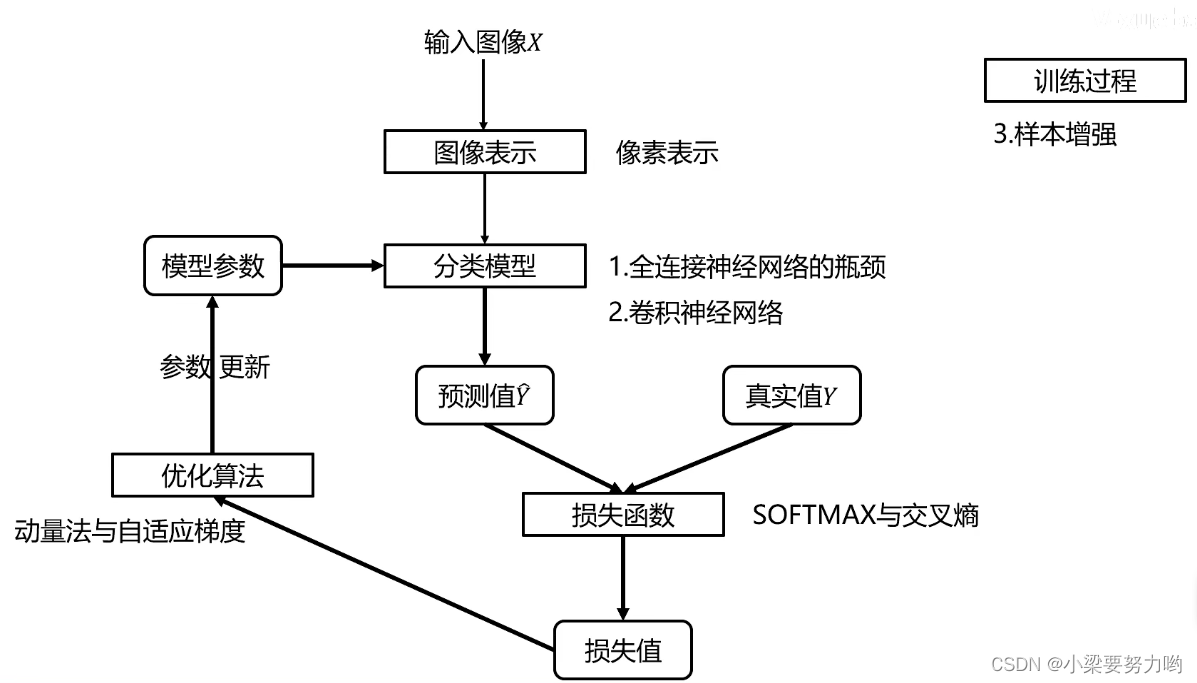
图像表示
像素表示:直接利用原始像素作为特征,展开为列向量。
Ps:CIFAR10数据集每个图像是(32323)3072维向量。
分类模型
全连接神经网络的瓶颈
例:图像尺寸为32323,隐层每个神经元的权值个数为3072+1=3073。
例:图像尺寸为2002003,隐层每个神经元的权值个数为120000+1=120001。
问:为什么要加上1?
答:计算隐层每个神经元的权值个数时,除了要考虑每个连接边,还需要考虑一个偏置b。
由此可见,当图像尺寸增大时,每个神经元的权值个数大幅增多,若再考虑一个隐层上的多个神经元以及多个隐层,计算量将相当的大。
结论:全连接神经网络仅适合处理小图像。
卷积神经网络
由于全连接网络适合处理小图像,即输入层的维数小。由此我们先可以使用卷积核处理图像,例如将上节预备知识中得到48维特征向量作为输入进行处理,之后进行全连接网络处理。

卷积层
基于卷积核组的图像表示
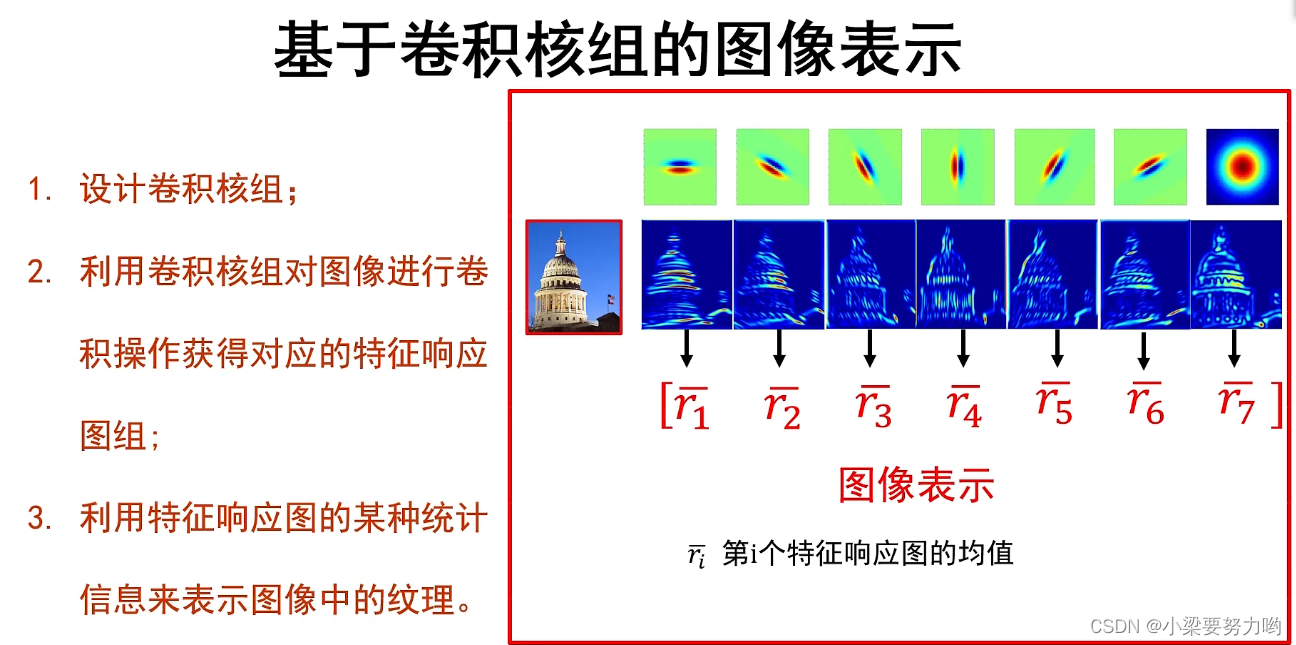
卷积核(与卷积核组中的略有不同)
1.不仅具有宽和高,还有深度。常写成以下形式:宽度 * 高度 * 深度。
2.卷积核参数不仅包括核中存储的权值,还包括一个偏置值。
卷积操作

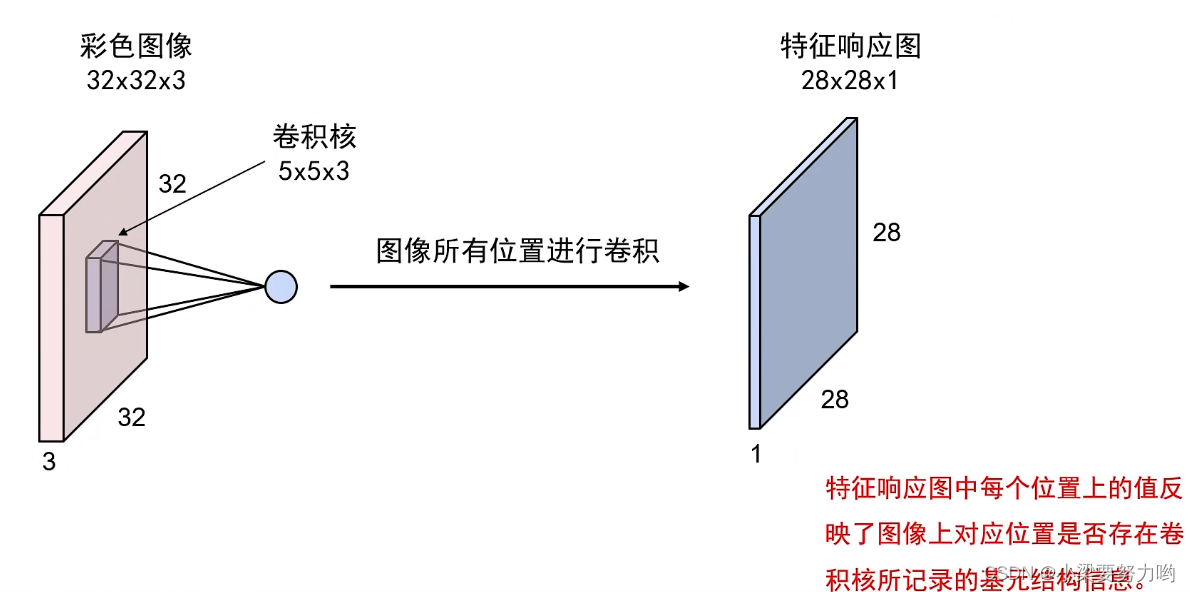
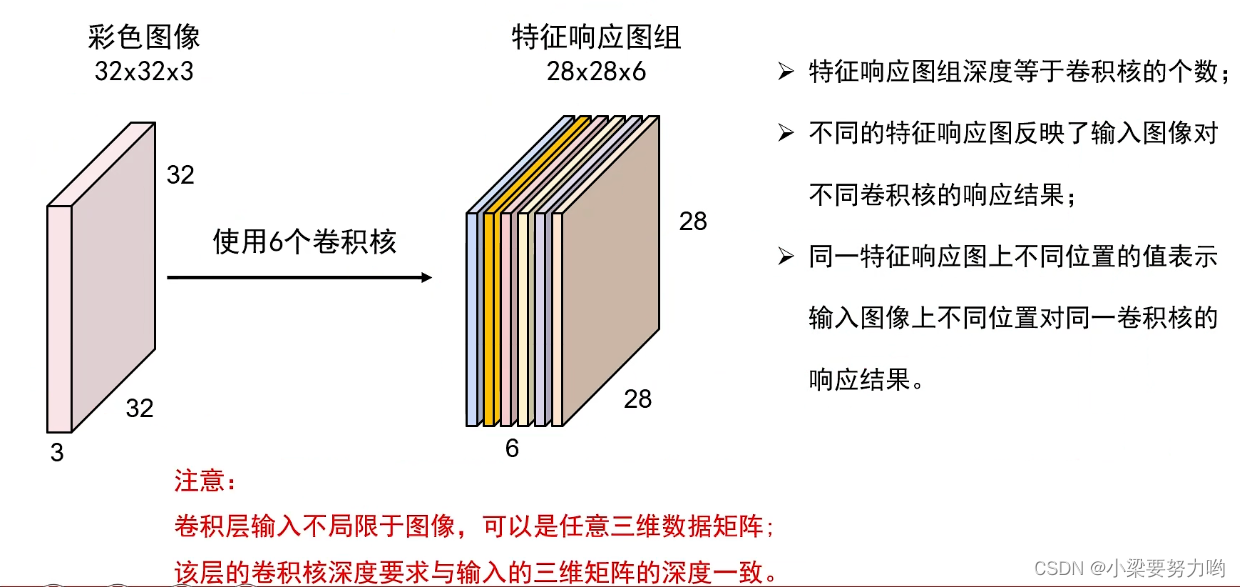
下一层卷积操作的卷积核深度要与特征相应图层的深度一致,即要和上一层卷积操作的卷积核个数一致。
卷积步长
卷积步长(stride):卷积神经网络中,卷积核可以按照指定的间隔进行卷积操作,这个间隔就是卷积步长。
卷积步长越大,输出特征图组的尺寸越小。

边界填充
为防止多次卷积操作后,输出图像越来越小,我们需要进行边界填充以达到输入、输出图像尺寸大小一致的要求。
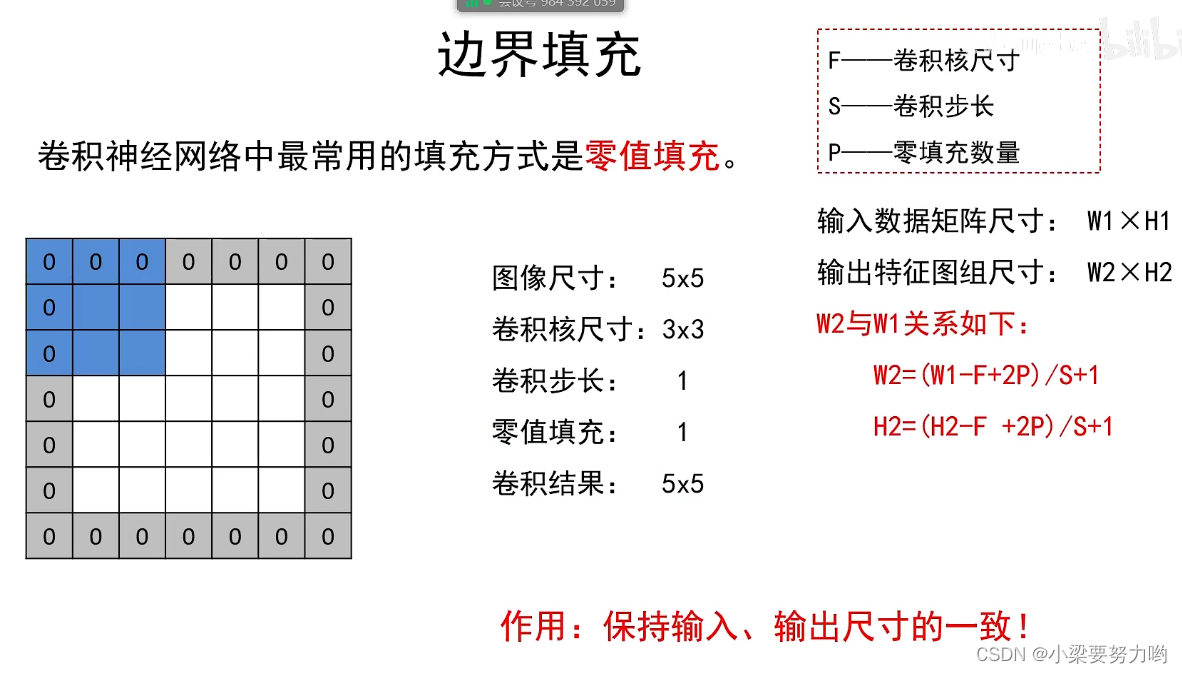
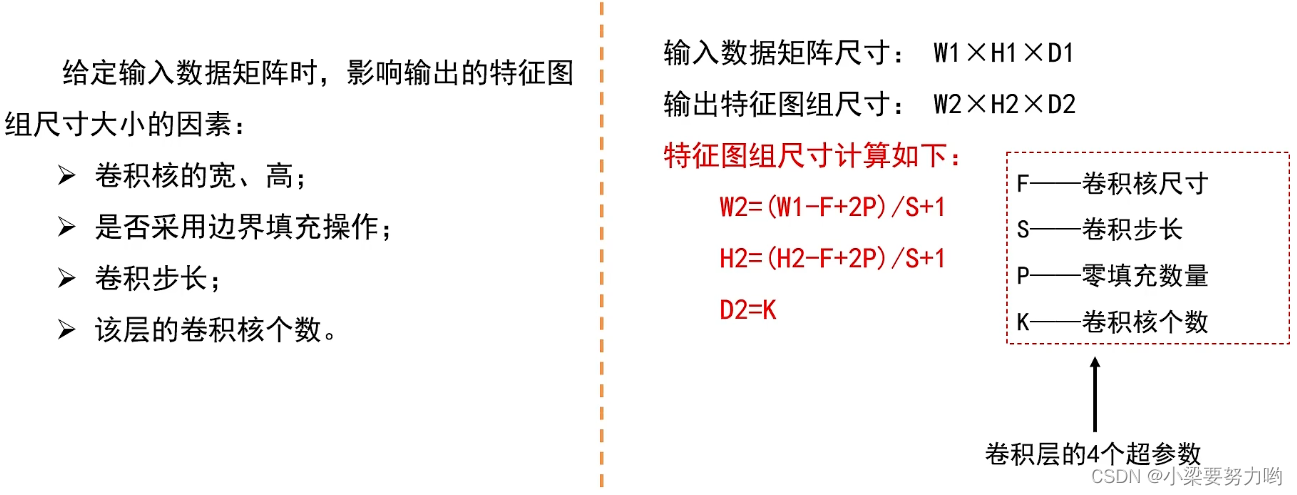
特征相应图尺寸计算
激活层
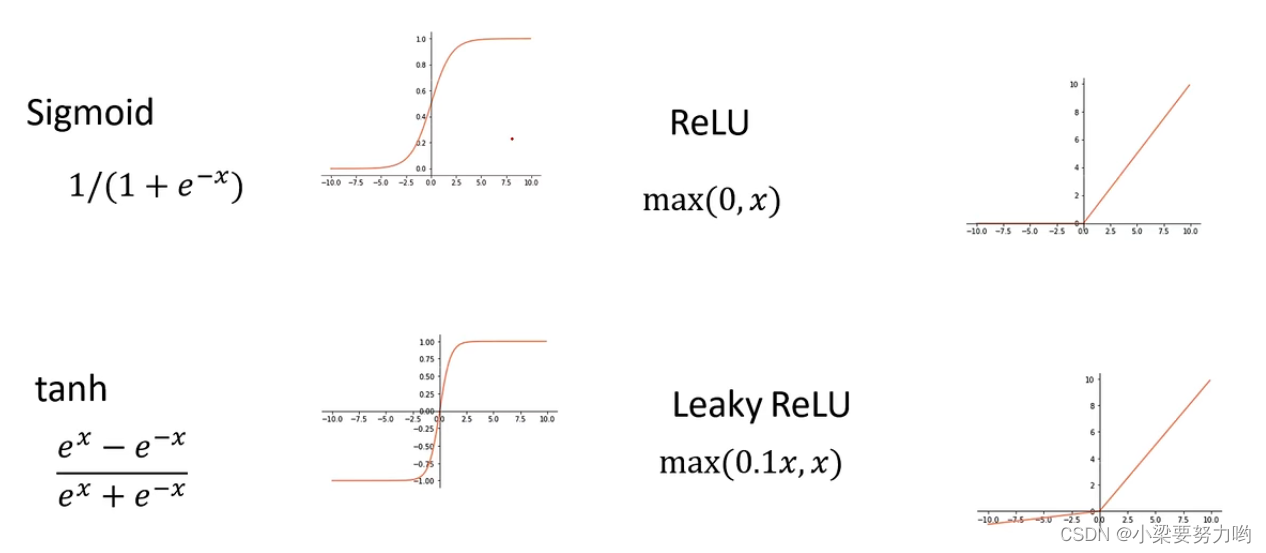
本文的卷积神经网络采用ReLU函数进行激活处理。
池化层
池化的作用:对每一个特征响应图独立进行,降低特征响应图组中每个特征响应图的宽度和高度,减少后续卷积层的参数的数量,降低计算资源耗费,进而控制过拟合;还可以使卷积核看到更多的东西,提取到更加粗犷的图像(相当于大方差效果)。
池化操作:对特征响应图某个区域进行池化就是在该区域上指定一个值来代表整个区域。
池化操作对每一个特征响应图独立进行。
常见的池化操作:
1.最大池化——使用区域内的最大值来代表这个区域
类似于非极大值抑制。
2.平均池化——采用区域内所有值的均值作为代表
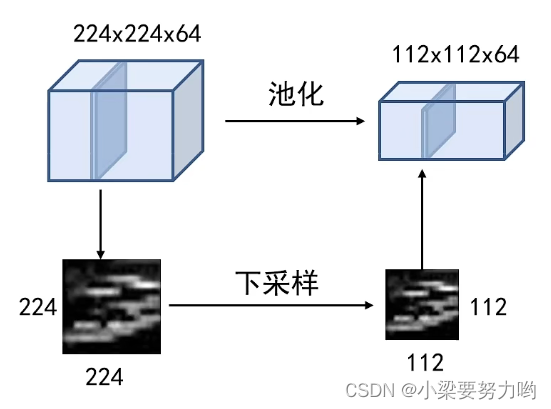
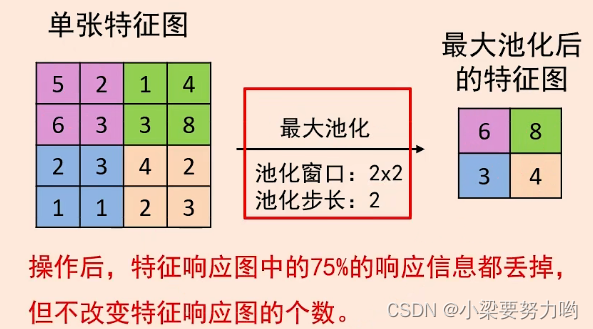
池化层的超参数:池化窗口和池化步长。
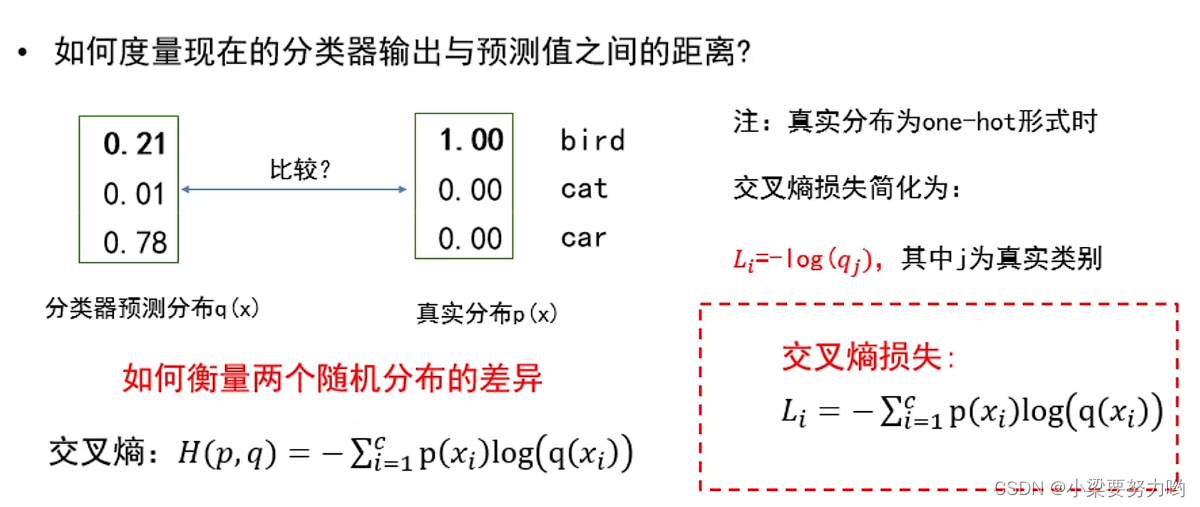
损失函数
交叉熵损失:度量分类器预测分布与真实分布之间的距离。
两个分布越接近,交叉熵的损失越小。
优化算法
1.SGD、带动量的SGD
动量法优势:由于动量的存在,算法可以冲出局部最低点或鞍点,找到最优解。

2.ADAM

图像增强
图像增强
存在的问题:过拟合的原因是学习样本太少,导致无法训练出能够泛化到新数据的模型。
数据增强:是从现有的训练样本中生成更多的训练数据,其方法是利用多种能够生成可信图像的随机变换来增加样本。
数据增强的目标:模型在训练时不会两次查看完全相同的图像。这让模型能够观察到数据的更多内容,从而具有更好的泛化能力
增强方法:
1.翻转
2.随机缩放&抠图
3.色彩抖动
4.平移
5.旋转
6.拉伸
7.径向畸变
8.裁剪
…


边栏推荐
猜你喜欢


随机推荐
MySql--存储引擎以及索引
flink-sql所有表格式format
PHP课堂笔记(一)
自己学习爬虫写的基础小函数
简单明了,数据库设计三大范式
Androd Day02
【深度学习21天学习挑战赛】1、我的手写被模型成功识别——CNN实现mnist手写数字识别模型学习笔记
pgsql函数中的return类型
个人练习三剑客基础之模仿CSDN首页
flink问题整理
【深度学习21天学习挑战赛】3、使用自制数据集——卷积神经网络(CNN)天气识别
SQl练习 2022/6/29
8.30难题留坑:计数器问题和素数等差数列问题
【树 图 科 技 头 条】2022年6月27日 星期一 今年ETH2.0无望
with recursive用法
sklearn中的pipeline机制
逻辑回归---简介、API简介、案例:癌症分类预测、分类评估法以及ROC曲线和AUC指标
剑指 Offer 2022/7/2
PostgreSQL模式(Schema)
ISCC2021——web部分