当前位置:网站首页>flink-sql自定义函数
flink-sql自定义函数
2022-08-04 05:27:00 【第一片心意】
版本说明
本文档介绍的各种flink sql的语法基于flink-1.13.x,flink版本低于1.13.x的用户,在sql运行出错误时,需要自行去flink官网查看对应版本的语法支持。
另外,flink新版本支持的语法,文档中会进行特殊标注,说明对应语法在 flink 哪个版本开始支持,但凡是没有特殊标注的,均支持flink-1.13.x及以上版本。
简介
概述
Flink Table API和SQL允许用户使用函数对数据进行转换处理。
函数类型
在Flink中有两个维度可以对函数进行分类。
一个维度是系统(或内置)函数和catalog函数。系统函数没有命名空间,可以直接使用它们的名字来引用。catalog函数属于指定catalog和数据库,因此它们具有catalog和数据库命名空间,它们可以通过完全/部分限定名(catalog.db.func 或 db.func)或只使用函数名。
另一个维度是临时函数和持久函数。临时函数是不稳定的,只能在会话的生命周期内使用,它们总是由用户创建的。持久函数存在于会话的整个生命周期中,它们要么由系统提供,要么在catalog中持久存在。
这两个维度为Flink用户提供了4种函数:
- Temporary system functions
- System functions
- Temporary catalog functions
- Catalog functions
使用函数
在Flink中,用户可以通过两种方式使用函数:精确使用函数或模糊使用函数。
精确使用
精确的函数使用户能够跨catalog和跨数据库使用catalog函数,例如select mycatalog.mydb.myfunc(x) from mytable
和 select mydb.myfunc(x) from mytable.。
从Flink 1.10开始支持。
模糊使用
在模糊函数使用中,用户只需要在SQL查询中指定函数名,例如select myfunc(x) from mytable。
函数解析顺序
当有不同类型但名称相同的函数时,需要注意函数的解析顺序。例如,当有三个函数都命名为“myfunc”,但分别是临时catalog、catalog和系统函数。如果没有函数名冲突,函数将被解析为唯一的一个。
精确函数解析
因为系统函数没有名称空间,所以Flink中的精确函数引用必定指向临时catalog函数或catalog函数。
解析顺序:
- Temporary catalog function
- Catalog function
模糊函数解析
解析顺序:
- Temporary system function
- System function
- Temporary catalog function,在会话的当前catalog和当前数据库中。
- Catalog function,在会话的当前catalog和当前数据库中。
自定义函数
用户自定义函数(udf)是用于调用经常使用的逻辑或在查询中无法以其他方式实现的自定义逻辑的扩展功能。
用户自定义函数可以用JVM语言(如Java或Scala)或Python实现。实现者可以在UDF中使用任意的第三方库。
本章将重点介绍基于jvm的语言,请参阅PyFlink文档,了解用Python编写通用udf的详细信息。
概述
目前,Flink区分了以下几种函数:
- 标量函数:将标量值映射到一个新的标量值。
- 表函数:将标量值映射到新行,新行数据可以有多个字段。
- 聚合函数:将多行标量值映射为新的标量值。
- 表聚合函数:将多行标量值映射到新行,新行数据可以有多个字段。
- 异步表值函数:是用于执行查找表源的特殊函数。
下面的示例展示了如何创建一个简单的标量函数,以及如何在Table API和SQL中调用该函数。
对于SQL查询,函数必须使用特定名称注册之后才能使用。对于Table API,函数可以注册或直接内联使用。
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.ScalarFunction;
import static org.apache.flink.table.api.Expressions.*;
public class SubstringFunction extends ScalarFunction {
public String eval(String s, Integer begin, Integer end) {
return s.substring(begin, end);
}
}
class UseFun {
public static void main(String[] args) {
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();
TableEnvironment env = TableEnvironment.create(settings);
// 在table api中使用不注册的内联方式调用函数
env.from("MyTable").select(call(SubstringFunction.class, $("myField"), 5, 12));
// 注册函数
env.createTemporarySystemFunction("SubstringFunction", SubstringFunction.class);
// 在table api中调用注册过的函数
env.from("MyTable").select(call("SubstringFunction", $("myField"), 5, 12));
// 在SQL中调用注册过的函数
env.sqlQuery("SELECT SubstringFunction(myField, 5, 12) FROM MyTable");
}
}
对于交互式会话,也可以在使用或注册函数之前对它们进行参数化。在这种情况下,可以将函数实例而不是函数类用作临时函数。
它要求参数是可序列化的,以便将函数实例传递到集群。
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.ScalarFunction;
import static org.apache.flink.table.api.Expressions.*;
// 定义可参数化函数逻辑
public class SubstringFunction extends ScalarFunction {
private boolean endInclusive;
public SubstringFunction(boolean endInclusive) {
this.endInclusive = endInclusive;
}
public String eval(String s, Integer begin, Integer end) {
return s.substring(begin, endInclusive ? end + 1 : end);
}
}
class UseFun {
public static void main(String[] args) {
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();
TableEnvironment env = TableEnvironment.create(settings);
//在table api中使用不注册的内联方式调用函数
env.from("MyTable").select(call(new SubstringFunction(true), $("myField"), 5, 12));
//注册函数,直接传递初始化参数,而不是在调用时传递
env.createTemporarySystemFunction("SubstringFunction", new SubstringFunction(true));
}
}
从1.14.x开始支持以下语法:
可以使用星号 * 作为函数调用的参数,在Table API中充当通配符,表示表中的所有列都将被传递给函数对应的位置。
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.ScalarFunction;
import static org.apache.flink.table.api.Expressions.*;
public static class MyConcatFunction extends ScalarFunction {
public String eval(@DataTypeHint(inputGroup = InputGroup.ANY) Object... fields) {
return Arrays.stream(fields)
.map(Object::toString)
.collect(Collectors.joining(","));
}
}
class UseFun {
public static void main(String[] args) {
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();
TableEnvironment env = TableEnvironment.create(settings);
// 使用 $("*") 来调用函数,如果 MyTable 有三个字段 (a, b, c), 则这三个所有的字段都将传递给 MyConcatFunction。
env.from("MyTable").select(call(MyConcatFunction.class, $("*")));
// 上述做法和下面这种显式的指定所有的字段有相同的效果。
env.from("MyTable").select(call(MyConcatFunction.class, $("a"), $("b"), $("c")));
}
}
实现步骤
不管是实现哪种自定义函数,所有用户自定义的函数都遵循一些基本的实现原则。
函数类
实现类必须继承于可用的基类(例如org.apache.flink.table.functions.ScalarFunction)。
类必须声明为公有的,而不是抽象的,并且是全局可访问的。因此,不允许使用非静态的内部类或匿名类。
为了在持久catalog中存储用户自定义函数,类必须具有默认构造函数,并且在运行时必须是可实例化的。
evaluation方法
基类提供了一组可以被重写的方法,如open()、close()或isDeterministic()。
但是,除了那些声明的方法外,对于每条传入数据的主要处理逻辑必须通过专门的方法去实现。
根据函数类型的不同,代码生成的操作符会在运行时调用eval()、**accumulate()或retract()**等求值方法。
这些方法必须声明为公有,并接受一组定义好的参数。
常规JVM方法定义在这儿也适用。因此可以:
- 实现重载方法,如
eval(Integer)和eval(LocalDateTime), - 使用可变参数,如
eval(Integer...), - 使用对象继承,如
eval(object),同时接受LocalDateTime和Integer, - 可变参数加对象继承
eval(Object...),接受各种参数。
如果想在Scala中实现函数,请添加Scala.annotation.varargs注释来处理变量参数。此外,建议使用包装类(例如java.lang.Integer而不是Int)来支持NULL。
下面的代码片段显示了重载函数的示例:
import org.apache.flink.table.functions.ScalarFunction;
//重载eval这个方法
public class SumFunction extends ScalarFunction {
public Integer eval(Integer a, Integer b) {
return a + b;
}
public Integer eval(String a, String b) {
return Integer.parseInt(a) + Integer.parseInt(b);
}
public Integer eval(Double... d) {
double result = 0;
for (double value : d)
result += value;
return (int) result;
}
}
类型推断
表生态系统(类似于SQL标准)是一个强类型API。因此,函数参数和返回类型都必须映射到之前章节中提到的数据类型。
从逻辑的角度来看,开发人员需要关于预期类型、精度和规模信息。从JVM的角度来看,规划器需要关于调用用户定义函数时如何将内部数据结构表示为JVM对象的信息。
验证输入参数以及为参数和函数结果派生数据类型的逻辑在类型推断中实现。
Flink的用户自定义函数实现了一个自动类型推断提取,通过反射从函数的类及其估值方法派生数据类型。
如果这种隐式反射提取方法没有成功,可以通过使用@DataTypeHint和@FunctionHint注解来改变的参数、类或方法来支持提取过程。下面展示了更多关于如何适用注解的示例。
如果需要更高级的类型推断逻辑,实现者可以在每个用户自定义函数中显式覆盖getTypeInference()方法。推荐使用注解方式,因为它会将自定义类型推断逻辑保持在受影响的位置附近,然后回退到默认行为,并不会影响其余的实现。
自动类型推断
自动类型推断会检查函数的类和计算方法,以派生函数的参数和结果的数据类型。@DataTypeHint和@FunctionHint注释支持自动提取。
有关可以隐式映射到数据类型的完整类列表,请参阅数据类型提取部分
。
@DataTypeHint
在许多场景中,需要支持函数的参数和返回值类型的自动内联提取。
下面的示例演示如何使用数据类型提示。更多信息可以在注解类的文档中找到。
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.InputGroup;
import org.apache.flink.table.functions.ScalarFunction;
import org.apache.flink.types.Row;
//重载eval这个方法
public class OverloadedFunction extends ScalarFunction {
// 没有类型提示
public Long eval(long a, long b) {
return a + b;
}
// 指定小数的长度和精度
public @DataTypeHint("DECIMAL(12, 3)")
BigDecimal eval(double a, double b) {
return BigDecimal.valueOf(a + b);
}
// 定义一个嵌套数据类型
@DataTypeHint("ROW<s STRING, t TIMESTAMP_LTZ(3)>")
public Row eval(int i) {
return Row.of(String.valueOf(i), Instant.ofEpochSecond(i));
}
// 允许任何输入和自定义的序列化输出
@DataTypeHint(value = "RAW", bridgedTo = ByteBuffer.class)
public ByteBuffer eval(@DataTypeHint(inputGroup = InputGroup.ANY) Object o) {
return MyUtils.serializeToByteBuffer(o);
}
}
@FunctionHint
在某些场景中,一个求值方法可以同时处理多个不同的数据类型。而且,在某些情况下,如果重载的求值方法有一个公共的结果类型,则应该只声明一次。
@FunctionHint注解可以提供从参数数据类型到结果数据类型的映射。它支持为输入、累加器和结果数据类型注解整个函数类或求值方法(相当于这些类型的公共注解)。
可以在类上声明一个或多个注解,也可以为重载函数签名的每个求值方法单独声明一个或多个注解。所有提示参数都是可选的。如果未定义参数,则使用默认的基于反射的提取。所有计算方法都继承于在函数类上定义的提示参数。
下面的示例演示如何使用函数提示。更多信息可以在注解类的文档中找到。
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.FunctionHint;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;
// 重载eval方法,使用全局定义的输出类型
@FunctionHint(output = @DataTypeHint("ROW<s STRING, i INT>"))
public class OverloadedFunction extends TableFunction<Row> {
public void eval(int a, int b) {
collect(Row.of("Sum", a + b));
}
public void eval() {
collect(Row.of("Empty args", -1));
}
}
// 将类型推断和求值方法解耦,将类型推断交给函数提示
@FunctionHint(input = {
@DataTypeHint("INT"), @DataTypeHint("INT")}, output = @DataTypeHint("INT"))
@FunctionHint(input = {
@DataTypeHint("BIGINT"), @DataTypeHint("BIGINT")}, output = @DataTypeHint("BIGINT"))
@FunctionHint(input = {
}, output = @DataTypeHint("BOOLEAN"))
@FunctionHint(output = @DataTypeHint("ROW<s STRING, i INT>"))
public class OverloadedFunction extends TableFunction<Object> {
// 实现只需要确定方法可以被JVM调用即可
public void eval(Object... o) {
if (o.length == 0) {
collect(false);
}
collect(o[0]);
}
}
自定义类型推断
对于大多数场景,@DataTypeHint和@FunctionHint应该足以满足用户自定义的函数建模。然而,通过重写getTypeInference()中定义的自动类型推断,实现者可以创建类似内置系统函数的任意函数。
下面用Java实现的示例说明自定义类型推理逻辑的潜力。它使用字符串字面值参数来确定函数的结果类型。该函数接收两个字符串参数:第一个参数表示要解析的字符串,第二个参数表示目标类型。
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.catalog.DataTypeFactory;
import org.apache.flink.table.functions.ScalarFunction;
import org.apache.flink.table.types.inference.TypeInference;
import org.apache.flink.types.Row;
public class LiteralFunction extends ScalarFunction {
public Object eval(String s, String type) {
return switch (type) {
case "INT" -> Integer.valueOf(s);
case "DOUBLE" -> Double.valueOf(s);
case "STRING", default -> s;
};
}
// 通过下面的逻辑代替自动基于反射的类型推断
@Override
public TypeInference getTypeInference(DataTypeFactory typeFactory) {
return TypeInference.newBuilder()
// 指定类型参数
//如果需要的haunt,参数将会被隐式转化为这些类型
.typedArguments(DataTypes.STRING(), DataTypes.STRING())
// 指定函数的结果类型策略
.outputTypeStrategy(callContext -> {
if (!callContext.isArgumentLiteral(1) || callContext.isArgumentNull(1)) {
throw callContext.newValidationError("Literal expected for second argument.");
}
// 返回基于字面量的数据类型
final String literal = callContext.getArgumentValue(1, String.class).orElse("STRING");
return switch (literal) {
case "INT" -> Optional.of(DataTypes.INT().notNull());
case "DOUBLE" -> Optional.of(DataTypes.DOUBLE().notNull());
case "STRING", default -> Optional.of(DataTypes.STRING());
};
})
.build();
}
}
有关自定义类型推断的更多示例,请参见带有
高级函数实现
的flink-examples-table模块。
确定性结果
每个用户自定义的函数类都可以通过重写isDeterministic()方法声明它是否产生确定性结果。如果函数不是纯函数(如random()、date()或now()),则该方法必须返回false。
默认情况下,isDeterministic()返回true。
确定性结果解释:像random()等函数,由于在SQL中调用函数时,每行数据都会调用一次函数,如果isDeterministic()方法返回false,则每次调用这类函数,都会产生一个新的结果,
也就是说,函数内部逻辑必走一次;如果isDeterministic()方法返回true,该函数则会预先执行一次,然后集群运行SQL时会直接使用预先执行后的结果,而不是每行数据都调用一次这个函数。
如果函数将数据列作为参数,每行数据都会执行一次函数,因为数据列的值对函数来说是不确定的。上述讨论的是无数据行列参数的函数。
此外,isDeterministic()方法还可能影响运行时行为。函数可能会在两个不同的阶段被调用:
- 在规划期间(即预运行阶段):如果一个函数通过常量表达式调用,或者可以从给定的语句派生出常量表达式,则该函数将被预先执行求出结果值以减少常量表达式的运行次数,并且可能不再在集群上执行该函数。
除非使用isDeterministic()来禁用常量表达式的这种缩减特性。
例如,在规划时对ABS的调用如下:SELECT ABS(-1) FROM t和SELECT ABS(field) FROM t WHERE field = -1;而SELECT ABS(field) FROM t
则不是常量表达式。 - 在运行时(即集群执行):如果一个函数被非常量表达式调用或
isDeterministic()返回false。
运行时集成方法
有时候,用户自定义的函数可能需要在实际工作之前获取全局运行时信息或做一些设置/清理工作。
用户自定义函数提供了可以被重写的**open()和close()**方法,并提供了与DataStream API的RichFunction中的方法类似的方法。
**open()方法在求值方法之前调用一次,最后一次调用求值方法之后调用close()**方法。
**open()**方法提供了一个FunctionContext,它包含了有关用户定义函数执行的上下文的信息,例如度量组(MetricGroup)数据、分布式缓存文件或全局作业参数。
通过调用FunctionContext的相应方法可以获得以下信息:
| 方法 | 描述 |
|---|---|
| getMetricGroup() | 子任务的度量组信息 |
| getCachedFile(name) | 本地临时文件拷贝到分布式的缓存文件 |
| getJobParameter(name, defaultValue) | 对应key的全局作业参数值 |
| getExternalResourceInfos(resourceName) | 返回对应key的外部资源信息集合 |
取决于函数执行的上下文,并非所有上述方法都可用。例如,在减少常量表达式期间,添加指标是一个无需执行的操作。
下面的示例片段展示了如何在标量函数中使用FunctionContext来访问全局作业参数:
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.FunctionContext;
import org.apache.flink.table.functions.ScalarFunction;
public class HashCodeFunction extends ScalarFunction {
private int factor = 0;
@Override
public void open(FunctionContext context) {
// 访问全局参数“hashcode_factor”的值,如果参数不存在,则“12”为其默认值
factor = Integer.parseInt(context.getJobParameter("hashcode_factor", "12"));
}
public int eval(String s) {
return s.hashCode() * factor;
}
}
class UseFun {
public static void main(String[] args) {
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();
TableEnvironment env = TableEnvironment.create(settings);
// 添加作业参数
env.getConfig().addJobParameter("hashcode_factor", "31");
// 注册函数
env.createTemporarySystemFunction("hashCode", HashCodeFunction.class);
// 调用自定义函数
env.sqlQuery("SELECT myField, hashCode(myField) FROM MyTable");
}
}
标量函数
用户自定义的标量函数会将零、一个或多个标量值映射到一个新的标量值。
数据类型
部分中列出的任何数据类型都可以用作求值方法的参数或返回类型。
为了自定义一个标量函数,必须扩展org.apache. fleck .table.functions中的基类ScalarFunction,并实现一个或多个名为eval(...)的求值方法。
下面的示例演示如何定义自己的哈希码函数并在查询中调用它。
import org.apache.flink.table.annotation.InputGroup;
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.ScalarFunction;
import static org.apache.flink.table.api.Expressions.*;
public class HashFunction extends ScalarFunction {
// 允许输入任何类型数据,然后返回INT类型
public int eval(@DataTypeHint(inputGroup = InputGroup.ANY) Object o) {
return o.hashCode();
}
}
class UseFun {
public static void main(String[] args) {
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();
TableEnvironment env = TableEnvironment.create(settings);
// 在Table API中通过内联方式调用未注册的函数
env.from("MyTable").select(call(HashFunction.class, $("myField")));
// 注册函数
env.createTemporarySystemFunction("HashFunction", HashFunction.class);
// 在Table API中调用注册的函数
env.from("MyTable").select(call("HashFunction", $("myField")));
// 在SQL中调用注册的函数
env.sqlQuery("SELECT HashFunction(myField) FROM MyTable");
}
}
表函数
与用户自定义的标量函数类似,用户自定义的表函数(UDTF)接受零个、一个或多个标量值作为输入参数。但是,它可以返回任意数量的行(或结构化类型)作为输出,而不是单个值。
返回的记录可以由一个或多个字段组成。如果输出记录只包含一个字段,则可以省略结构化数据,并且可以发出一个标量值,该标量值将由运行时隐式包装到row中。
为了定义表函数,必须扩展org.apache.flink.table.functions中的基类TableFunction,并实现一个或多个名为eval(...)的求值方法。
与其他函数类似,使用反射自动提取输入和输出数据类型,包括用于确定输出数据类型的泛型参数T。与标量函数不同,求值方法本身不能有返回类型,
相反,表函数提供了一个collect(T)方法,可以在每个求值方法中调用该方法,以发出零条、一条或多条记录。
在Table API中,通过.joinLateral(…) 或 .leftOuterJoinLateral(…)使用表函数。
joinLateral操作符(cross)将外部表(操作符左侧的表)中的每一行与表函数(操作符右侧的表函数)产生的所有行连接起来。
leftOuterJoinLateral操作符将来自外部表(操作符左边的表)的每一行与表值函数(操作符右边的表值函数)产生的所有行连接起来,并保留表函数返回空表的外部行。
在SQL中,使用带有JOIN的LATERAL TABLE(<TableFunction>)或带有ON TRUE连接条件的LEFT JOIN。
下面的示例演示如何定义自己的split函数并在查询中调用它。
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.FunctionHint;
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;
import static org.apache.flink.table.api.Expressions.*;
@FunctionHint(output = @DataTypeHint("ROW<word STRING, length INT>"))
public class SplitFunction extends TableFunction<Row> {
public void eval(String str) {
for (String s : str.split(" ")) {
// 使用collect(...)方法发出row类型数据
collect(Row.of(s, s.length()));
}
}
}
class UseFun {
public static void main(String[] args) {
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();
TableEnvironment env = TableEnvironment.create(settings);
// 在Table API中通过内联方式调用未注册的函数
env
.from("MyTable")
.joinLateral(call(SplitFunction.class, $("myField")))
.select($("myField"), $("word"), $("length"));
env
.from("MyTable")
.leftOuterJoinLateral(call(SplitFunction.class, $("myField")))
.select($("myField"), $("word"), $("length"));
// 在Table API中重命名函数的属性名
env
.from("MyTable")
.leftOuterJoinLateral(call(SplitFunction.class, $("myField")).as("newWord", "newLength"))
.select($("myField"), $("newWord"), $("newLength"));
//注册函数
env.createTemporarySystemFunction("SplitFunction", SplitFunction.class);
// 在Table API中调用注册的函数
env
.from("MyTable")
.joinLateral(call("SplitFunction", $("myField")))
.select($("myField"), $("word"), $("length"));
env
.from("MyTable")
.leftOuterJoinLateral(call("SplitFunction", $("myField")))
.select($("myField"), $("word"), $("length"));
// 在SQL中调用注册的函数
env.sqlQuery(
"SELECT myField, word, length " +
"FROM MyTable, LATERAL TABLE(SplitFunction(myField))");
env.sqlQuery(
"SELECT myField, word, length " +
"FROM MyTable " +
"LEFT JOIN LATERAL TABLE(SplitFunction(myField)) ON TRUE");
// 在SQL中重命名属性值
env.sqlQuery(
"SELECT myField, newWord, newLength " +
"FROM MyTable " +
"LEFT JOIN LATERAL TABLE(SplitFunction(myField)) AS T(newWord, newLength) ON TRUE");
}
}
如果想在Scala中实现函数,不要将表函数实现为Scala Object。Scala Object是单例的,会导致并发问题。
聚合函数
用户自定义的聚合函数(UDAGG)可以将多行标量值映射到一个新的标量值。
聚合函数会使用到累加器。累加器是一种中间数据结构,用于存储聚合值,直到计算出最终聚合结果。
对于每一组需要聚合的行,运行时将通过调用createAccumulator()方法创建一个空的累加器。随后,对每个输入行调用accumulate(...)方法来更新累加器。
处理完所有行后,调用getValue(...)方法来计算并返回最终结果。
下图演示了聚合过程:
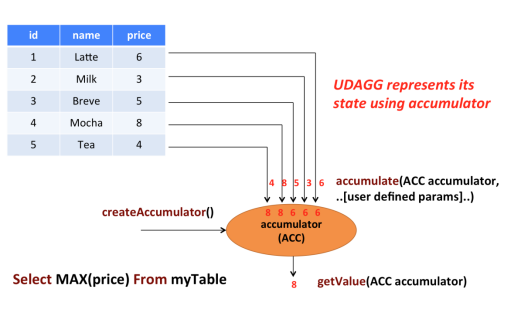
在本例中,我们假设有一个包含饮料数据的表。该表由三列(id、name、price)和5行数据组成。我们想找出表中所有饮料的最高价格,即执行max()聚合。我们需要计算这5行中的每一行。结果是一个标量数值。
为了定义聚合函数,必须扩展org.apache.flink.table.functions中的基类AggregateFunction,并实现一个或多个名为accumulate(...)的求值方法。accumulate方法必须public,而不是静态的。accumulate方法可以重载。
默认使用反射自动提取输入、累加器和输出数据类型,包括累加器泛型ACC和返回结果泛型T。输入参数来自一个或多个accumulate(...)方法。
下面的示例演示如何定义自己的聚合函数并在查询中调用它。
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.AggregateFunction;
import static org.apache.flink.table.api.Expressions.*;
// 自定义聚合函数的可变累加器
public class WeightedAvgAccumulator {
public long sum = 0;
public int count = 0;
}
// 第一个泛型表示聚合结果类型,也就是返回值类型,第二个泛型表示累加器类型
public class WeightedAvg extends AggregateFunction<Long, WeightedAvgAccumulator> {
/** * 创建并初始化累加器 * 累加器是计算中间结果的数据结构体,存储聚合数据值,直到计算最终聚合结果。 * * @return 具有初始化值的累加器 */
@Override
public WeightedAvgAccumulator createAccumulator() {
return new WeightedAvgAccumulator();
}
/** * 计算并返回最终结果 */
@Override
public Long getValue(WeightedAvgAccumulator acc) {
if (acc.count == 0) {
return null;
} else {
return acc.sum / acc.count;
}
}
/** * 处理输入参数值,并且更新提供的累加器实例。 * 这个方法可以被重载。 * 自定义聚合函数必须有至少一个accumulate()方法。 * * @param acc 包含当前聚合结果的累加器 * @param iValue 用户输入参数 * @param iWeight 用户输入参数 */
public void accumulate(WeightedAvgAccumulator acc, Long iValue, Integer iWeight) {
acc.sum += iValue * iWeight;
acc.count += iWeight;
}
/** * 从累加器实例撤回输入值。 * 当前设计假定该输入值是以前累加过的值。 * 该方法可以被重载。 * 在无界表上使用有界OVER聚合数据时,必须实现该方法。 * * @param acc 包含当前聚合结果的累加器 * @param iValue 用户输入参数 * @param iWeight 用户输入参数 */
public void retract(WeightedAvgAccumulator acc, Long iValue, Integer iWeight) {
acc.sum -= iValue * iWeight;
acc.count -= iWeight;
}
/** * 将一组累加器实例聚合到一个累加器实例。 * 在无界会话窗口、滑动窗口进行分组聚合,以及在有界分区聚合时必须实现该方法。 * 除此之外,实现该方法对优化器是有帮助的。 * 比如,两阶段聚合优化要求所有聚合函数支持“merge”方法 * * @param acc 保存聚合结果的累加器。注意,它应该包含之前聚合的结果,因此,我们不能在聚合方法中替换或清理这个实例。 * @param it 一组将被合并的累加器对应的迭代器 */
public void merge(WeightedAvgAccumulator acc, Iterable<WeightedAvgAccumulator> it) {
for (WeightedAvgAccumulator a : it) {
acc.count += a.count;
acc.sum += a.sum;
}
}
/** * 重置累加器 */
public void resetAccumulator(WeightedAvgAccumulator acc) {
acc.count = 0;
acc.sum = 0L;
}
}
class useFun {
public static void main(String[] args) {
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();
TableEnvironment env = TableEnvironment.create(settings);
// 在Table API中调用未被注册的函数
env
.from("MyTable")
.groupBy($("myField"))
.select($("myField"), call(WeightedAvg.class, $("value"), $("weight")));
// 注册函数
env.createTemporarySystemFunction("WeightedAvg", WeightedAvg.class);
// 在Table API中调用注册的函数
env
.from("MyTable")
.groupBy($("myField"))
.select($("myField"), call("WeightedAvg", $("value"), $("weight")));
// 在SQL中调用注册的函数
env.sqlQuery(
"SELECT myField, WeightedAvg(`value`, weight) FROM MyTable GROUP BY myField"
);
}
}
WeightedAvg类的accumulate(...)方法接受三个输入参数。第一个是累加器,另外两个是用户自定义的输入。为了计算加权平均值,累加器需要存储已累积的所有数据的加权和计数。
在我们的示例中,我们定义了一个类WeightedAvgAccumulator作为累加器。累加器由Flink的checkpoint机制自动管理,并在出现错误时恢复,以确保恰好一次语义。
必选和可选方法
对于每个自定义AggregateFunction函数,以下方法是必须实现的:
- createAccumulator()
- accumulate(…)
- getValue(…)
此外,还有一些可选的方法可以实现。虽然其中一些方法只是为了让系统更有效地执行查询,但在某些情况下则必需实现的。
例如,如果在会话分组窗口(session group window)上调用聚合函数,则**merge(…)**方法是强制性的(当“连接”两个会话窗口的数据行时,需要连接两个会话窗口的累加器)。
AggregateFunction的以下方法实现取决于使用情境:
- retract(…):在OVER窗口上进行聚合时需要使用。
- merge(…):对于许多有界聚合、会话窗口和滑动窗口聚合都是必需的。此外,该方法也有助于查询优化。例如,两阶段聚合优化要求所有AggregateFunction支持merge方法。
两阶段聚合:类似于MR中的combiner,先在map端进行小的聚合,最后在reduce端再次聚合。
如果聚合函数只能在OVER窗口中使用,则可以通过返回FunctionRequirement来声明。在getRequirements()中返回FunctionRequirement.OVER_WINDOW_ONLY。
如果累加器需要存储大量的数据,则使用org.apache.flink.table.api.dataview.ListView和org.apache.flink.table.api.dataview.MapView
提供的高级特性,在无界数据场景中利用Flink的状态后端。有关这个高级特性的更多信息,请参阅相应类的文档。
由于有些方法是可选的,或者是可以重载,所以运行时是通过生成的代码来调用聚合函数方法的。这意味着基类并不总是提供具体方法实现需要覆盖的签名。然而,所有提到的方法都必须公开的,而且不是静态的,并且完全按照上面提到的方法的名字命名。
下面给出未在AggregateFunction中声明并由生成的代码调用的所有方法的详细文档。
accumulate(…):
/** * 处理输入参数值,并且更新提供的累加器实例。 * 这个方法可以被重载。 * 自定义聚合函数必须有至少一个accumulate()方法。 * * @param acc 包含当前聚合结果的累加器 * @param: [user defined inputs] 输入值(通常是新到达数据行字段) **/
public void accumulate(ACC accumulator,[user defined inputs])
retract(…):
/** * 从累加器实例撤回输入值。 * 当前设计假定该输入值是以前累加过的值。 * 该方法可以被重载。 * 在无界表上使用有界OVER聚合数据时,必须实现该方法。 * @param accumulator 包含当前聚合结果的累加器 * @param [user defined inputs] 输入值(通常是新到达数据行字段) */
public void retract(ACC accumulator,[user defined inputs])
merge(…):
/** * 将一组累加器实例聚合到一个累加器实例。 * 在无界会话窗口、滑动窗口进行分组聚合,以及在有界分区聚合时必须实现该方法。 * 除此之外,实现该方法对优化器是有帮助的。 * 比如,两阶段聚合优化要求所有聚合函数支持“merge”方法 * * @param accumulator 保存聚合结果的累加器。注意,它应该包含之前聚合的结果,因此,我们不能在聚合方法中替换或清理这个实例。 * @param iterable 一组将被合并的累加器对应的迭代器 */
public void merge(ACC accumulator,java.lang.Iterable<ACC> iterable)
表聚合函数
用户定义的表聚合函数(UDTAGG)可以将多行标量值映射为0、1或多行(或结构化类型)标量值。返回的记录可以由一个或多个字段组成。如果输出记录只包含一个字段,则可以省略结构化,并且发出一个标量值,该标量值将由运行时隐式包装到row中。
与聚合函数类似,表聚合的行为以累加器的概念为中心。累加器是中间数据结构,用于存储聚合值,直到计算出最终聚合结果。
对于每一组需要聚合的行,运行时将通过调用createAccumulator()创建一个空的累加器。随后,对每个输入行调用函数的accumulate(...)方法来更新累加器。
处理完所有行后,调用函数的emitValue(...)或emitUpdateWithRetract(...)方法来计算并返回最终结果。
下图演示了聚合过程:
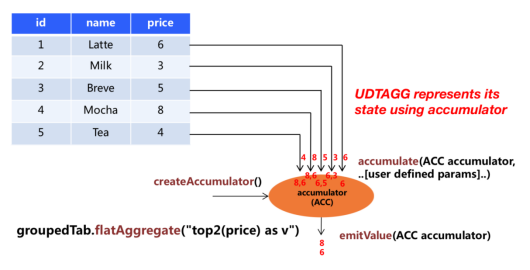
在本例中,我们假设一个包含饮料数据的表。该表由三列(id、name、price)和5行数据组成。我们想在表格中找出所有饮料最高的2个价格,即执行TOP2()表格汇总。我们需要计算这5行中的每一行。结果是一个包含前2个值的表。
为了定义表聚合函数,必须扩展org.apache.flink.table.functions中的基类TableAggregateFunction,并实现一个或多个名为accumulate(...)的求值方法。accumulate方法必须public,而且是非静态的。累加方法也可以通过实现多个名为accumulate的方法来重载。
默认情况下,使用反射自动提取输入、累加器和输出数据类型。这包括确定累加器泛型参数ACC和累加器结果泛型参数T。输入参数来自一个或多个accumulate(...)方法。
如果打算在Python中实现或调用函数,请参阅Python函数文档了解更多细节。
下面的示例演示如何定义自己的表聚合函数并在查询中调用它。
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.TableAggregateFunction;
import org.apache.flink.util.Collector;
import static org.apache.flink.table.api.Expressions.*;
// 自定义表聚合函数的可变累加器
public class Top2Accumulator {
public Integer first;
public Integer second;
}
// 函数包含用户输入值(INT),保存中间结果到Top2Accumulator对象,最后返回Tuple2<Integer, Integer>类型的结果,第一个表示结果值,第二个表示级别。
// 函数第一个泛型表示聚合结果类型,第二个泛型表示累加器类型
public class Top2 extends TableAggregateFunction<Tuple2<Integer, Integer>, Top2Accumulator> {
/** * 创建一个初始化的累加器 * * @return 初始化的累加器 */
@Override
public Top2Accumulator createAccumulator() {
Top2Accumulator acc = new Top2Accumulator();
acc.first = Integer.MIN_VALUE;
acc.second = Integer.MIN_VALUE;
return acc;
}
/** * 处理输入值,并且更新之前的累加器实例。这个方法可以被重载。表聚合函数要求至少一个accumulate()方法。 * * @param acc 包含当前聚合结果的累加器 * @param value 输入值(通常是用户输入的数据) */
public void accumulate(Top2Accumulator acc, Integer value) {
if (value > acc.first) {
acc.second = acc.first;
acc.first = value;
} else if (value > acc.second) {
acc.second = value;
}
}
/** * 合并一组累加器实例到一个累加器实例。这个方法必须在无界会话、滑动窗口分组聚合、有界分组聚合中实现。 * * @param acc 将要保存聚合结果的累加器。这个累加器可能包含之前聚合的结果,因此用户不能替换,或者是清理这个实例。 * @param it 将要被合并的一组累加器对应的迭代器 */
public void merge(Top2Accumulator acc, Iterable<Top2Accumulator> it) {
for (Top2Accumulator otherAcc : it) {
accumulate(acc, otherAcc.first);
accumulate(acc, otherAcc.second);
}
}
/** * 每次聚合结果应该被物化时调用。返回值可以是早期未完成的结果(当数据到达时定期发出),或者是最终的聚合结果。 * * @param acc 包含当前聚合结果的累加器。 * @param out 输出数据的收集器。 */
public void emitValue(Top2Accumulator acc, Collector<Tuple2<Integer, Integer>> out) {
// emit the value and rank
if (acc.first != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.first, 1));
}
if (acc.second != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.second, 2));
}
}
}
class UseFun {
public static void main(String[] args) {
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();
TableEnvironment env = TableEnvironment.create(settings);
// 在Table API中通过内联方式调用未被注册的函数
env
.from("MyTable")
.groupBy($("myField"))
.flatAggregate(call(Top2.class, $("value")))
.select($("myField"), $("f0"), $("f1"));
// 在Table API中通过内联方式调用未被注册的函数,并且使用别名来更好的标识返回值二元组的属性
env
.from("MyTable")
.groupBy($("myField"))
.flatAggregate(call(Top2.class, $("value")).as("value", "rank"))
.select($("myField"), $("value"), $("rank"));
// 注册函数
env.createTemporarySystemFunction("Top2", Top2.class);
//在Table API中调用注册的函数
env
.from("MyTable")
.groupBy($("myField"))
.flatAggregate(call("Top2", $("value")).as("value", "rank"))
.select($("myField"), $("value"), $("rank"));
}
}
Top2类的accumulate(...)方法接受两个输入。第一个是累加器,第二个是用户定义的输入。
为了计算结果,累加器需要存储已累积的所有数据的2个最高值。累加器由Flink的checkpoint机制自动管理,并在出现错误时恢复,以确保精确一次的语义。结果值与排名索引作为结果一起发出。
必选和可选方法
对于每个自定义TableAggregateFunction,以下方法是必须的:
- createAccumulator()
- accumulate(…)
- emitValue(…) or emitUpdateWithRetract(…)
此外,还有一些可选的方法可以实现。其中一些方法可以让系统更有效地执行查询,但在某些情境下,有些方法是必需的。
例如,如果在会话分组窗口(session group window)上使用表聚合函数,则merge(...)方法是强制性的(当需要“连接”两个会话窗口的数据行时,需要连接两个会话窗口的累加器)。
TableAggregateFunction的以下方法取决于用例:
- retract(…):在OVER窗口上进行聚合时需要使用。
- merge(…):对于许多有界聚合、无界会话、滑动窗口聚合都是必需的。
- emitValue(…):对于有界、窗口聚合是必需的。
TableAggregateFunction的以下方法可以提高流作业的性能:
- emitUpdateWithRetract(…):用于发出在回撤模式下更新的值。
emitValue(...)方法总是通过累加器发出完整的数据。在无界流场景中可能会带来性能问题。
以Top N函数为例,每次emitValue(...)都会发出所有N个值。为了提高性能,可以实现emitUpdateWithRetract(...),在retract模式下增量输出数据。
换句话说,一旦有了更新,该方法可以在发送新的、更新的记录之前撤销旧记录。该方法将优先于emitValue(...)方法调用。
如果表聚合函数只能在OVER窗口中应用,则可以通过getRequirements()方法返回FunctionRequirement.OVER_WINDOW_ONLY来说明。
如果一个累加器需要存储大量的数据,可以使用org.apache.flink.table.api.dataview.ListView和org.apache.flink.table.api.dataview.MapView
提供的高级特性,在无界流数据场景中利用Flink的状态后端。有关这个高级特性的更多信息,请参阅相应类的文档。
由于有些方法是可选或可以重载的,因此flink会根据生成的代码来调用这些方法。基类并不总是提供所有需要实现的方法的签名。然而,所有提到的方法都必须是public,非静态的,并且完全按照上面提到的名字命名。
下面给出了未在TableAggregateFunction中声明并由生成的代码调用的所有方法的详细文档。
accumulate(…):
/** * 处理输入参数值,并且更新提供的累加器实例。 * 这个方法可以被重载。 * 自定义聚合函数必须有至少一个accumulate()方法。 * * @param acc 包含当前聚合结果的累加器 * @param: [user defined inputs] 输入值(通常是新到达数据行字段) **/
public void accumulate(ACC accumulator,[user defined inputs])
retract(…):
/** * 从累加器实例撤回输入值。 * 当前设计假定该输入值是以前累加过的值。 * 该方法可以被重载。 * 在无界表上使用有界OVER聚合数据时,必须实现该方法。 * @param accumulator 包含当前聚合结果的累加器 * @param [user defined inputs] 输入值(通常是新到达数据行字段) */
public void retract(ACC accumulator,[user defined inputs])
merge(…):
/** * 将一组累加器实例聚合到一个累加器实例。 * 在无界会话窗口、滑动窗口进行分组聚合,以及在有界分区聚合时必须实现该方法。 * 除此之外,实现该方法对优化器是有帮助的。 * 比如,两阶段聚合优化要求所有聚合函数支持“merge”方法 * * @param accumulator 保存聚合结果的累加器。注意,它应该包含之前聚合的结果,因此,我们不能在聚合方法中替换或清理这个实例。 * @param iterable 一组将被合并的累加器对应的迭代器 */
public void merge(ACC accumulator,java.lang.Iterable<ACC> iterable)
emitValue(…):
/** * 每次聚合结果应该被物化时调用。返回值可以是早期未完成的结果(当数据到达时定期发出),或者是最终的聚合结果。 * * param: accumulator 包含当前聚合结果的累加器。 * param: out 输出数据的收集器。 */
public void emitValue(ACC accumulator,org.apache.flink.util.Collector<T> out)
emitUpdateWithRetract(…):
/* * 每次聚合结果应该被物化时调用。返回值可以是早期未完成的结果(当数据到达时定期发出),或者是最终的聚合结果。 * 与emitValue()相比,emitUpdateWithRetract() 用来发出被更新的结果值。 * 这个方法在回撤模式(也叫做"update before" 和 "update after")下会立即输出数据。 * 一旦遇到一个更新,我们必须在发送新的更新数据之前撤回旧的记录。 * 如果在表聚合函数中同时实现了emitUpdateWithRetract()和emitValue(),则会优先使用emitUpdateWithRetract(), * 因为这个方法可以以增长的方式输出数据,比emitValue更有效。 * * param: accumulator 包含当前聚合结果的累加器。 * param: out 回撤收集器被用于输出数据。使用collect()方法输出增加的数据,使用retract()方法删除数据。 */
public void emitUpdateWithRetract(ACC accumulator,RetractableCollector<T> out)
Retraction案例
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.table.functions.TableAggregateFunction;
// 前两个属性表示最新的top2,后两个属性表示上一次top2
public class Top2WithRetractAccumulator {
public Integer first;
public Integer second;
public Integer oldFirst;
public Integer oldSecond;
}
public class Top2WithRetract extends TableAggregateFunction<Tuple2<Integer, Integer>, Top2WithRetractAccumulator> {
@Override
public Top2WithRetractAccumulator createAccumulator() {
Top2WithRetractAccumulator acc = new Top2WithRetractAccumulator();
acc.first = Integer.MIN_VALUE;
acc.second = Integer.MIN_VALUE;
acc.oldFirst = Integer.MIN_VALUE;
acc.oldSecond = Integer.MIN_VALUE;
return acc;
}
public void accumulate(Top2WithRetractAccumulator acc, Integer v) {
// 更新最新top2数据
if (v > acc.first) {
acc.second = acc.first;
acc.first = v;
} else if (v > acc.second) {
acc.second = v;
}
}
public void emitUpdateWithRetract(Top2WithRetractAccumulator acc, RetractableCollector<Tuple2<Integer, Integer>> out) {
if (!acc.first.equals(acc.oldFirst)) {
// 如果发现有更新数据,则先删除之前的旧值,然后发出新值
if (acc.oldFirst != Integer.MIN_VALUE) {
out.retract(Tuple2.of(acc.oldFirst, 1));
}
out.collect(Tuple2.of(acc.first, 1));
acc.oldFirst = acc.first;
}
if (!acc.second.equals(acc.oldSecond)) {
// 如果发现有更新数据,则先删除之前的旧值,然后发出新值
if (acc.oldSecond != Integer.MIN_VALUE) {
out.retract(Tuple2.of(acc.oldSecond, 2));
}
out.collect(Tuple2.of(acc.second, 2));
acc.oldSecond = acc.second;
}
}
实际案例
模拟hive函数collect_list
package cn.com.function.udaf;
import org.apache.flink.table.functions.AggregateFunction;
import java.util.ArrayList;
import java.util.List;
/** * 将字段所有值拼接到一起,保留重复值。<br> * 默认拼接符号为英文逗号。<br> * 必须将字段强转为字符串。<br> * 第一个泛型表示聚合结果类型,也就是返回值类型,第二个泛型表示累加器类型 * * @author ziqiang.wang * @date 2022/1/14 10:20 */
public class CollectList extends AggregateFunction<String, List<String>> {
/** * 最终结果拼接符号 */
private final String separator = ",";
/** * 创建并初始化累加器 * 累加器是计算中间结果的数据结构体,存储聚合数据值,直到计算最终聚合结果。 * * @return 具有初始化值的累加器 */
@Override
public List<String> createAccumulator() {
return new ArrayList<>();
}
/** * 计算并返回最终结果 */
@Override
public String getValue(List<String> accumulator) {
if (!accumulator.isEmpty()) {
StringBuilder builder = new StringBuilder();
accumulator.forEach(s -> builder.append(s).append(separator));
return builder.deleteCharAt(builder.length() - 1).toString();
} else {
return "";
}
}
/** * 处理输入参数值,并且更新提供的累加器实例。 * 这个方法可以被重载。 * 自定义聚合函数必须有至少一个accumulate()方法。 * * @param acc 包含当前聚合结果的累加器 * @param value 用户输入参数 */
public void accumulate(List<String> acc, String value) {
if (value != null) {
acc.add(value);
}
}
/** * 从累加器实例撤回输入值。 * 当前设计假定该输入值是以前累加过的值。 * 该方法可以被重载。 * 在无界表上使用有界OVER聚合数据时,必须实现该方法。 * * @param acc 包含当前聚合结果的累加器 * @param value 用户输入参数 */
public void retract(List<String> acc, String value) {
if (value != null) {
acc.remove(value);
}
}
/** * 将一组累加器实例聚合到一个累加器实例。 * 在无界会话窗口、滑动窗口进行分组聚合,以及在有界分区聚合时必须实现该方法。 * 除此之外,实现该方法对优化器是有帮助的。 * 比如,两阶段聚合优化要求所有聚合函数支持“merge”方法 * * @param acc 保存聚合结果的累加器。注意,它应该包含之前聚合的结果,因此,我们不能在聚合方法中替换或清理这个实例。 * @param it 一组将被合并的累加器对应的迭代器 */
public void merge(List<String> acc, Iterable<List<String>> it) {
for (List<String> list : it) {
acc.addAll(list);
}
}
/** * 重置累加器 */
public void resetAccumulator(List<String> acc) {
acc.clear();
}
}
边栏推荐
猜你喜欢
webrtc中的任务队列TaskQueue
Can 't connect to MySQL server on' localhost3306 '(10061) simple solutions
Swoole学习(二)
EntityComponentSystemSamples学习笔记

实际开发中左菜单自定义图标点击切换
【Matlab仿真】:一带电量为q的电荷以速度v运动,求运动电荷产生磁感应强度

MySQL database (basic)
Cannot read properties of null (reading 'insertBefore')
(Kettle) pdi-ce-8.2 连接MySQL8.x数据库时驱动问题之终极探讨及解决方法分析
实际开发中,如何实现复选框的全选和不选
随机推荐
lambda函数用法总结
攻防世界MISC———Dift
对象存储-分布式文件系统-MinIO-3:MinIo Client(mc)
BUUCTF——MISC(一)
【Matlab仿真】:一带电量为q的电荷以速度v运动,求运动电荷产生磁感应强度
Several ways to heavy
进程、线程、协程的区别和联系?
ISCC-2022
个人练习三剑客基础之模仿CSDN首页
Oracle备份脚本
PHP课堂笔记(一)
自动化运维工具Ansible(3)PlayBook
TensorRTx-YOLOv5工程解读(一)
LCP 17. Quick Calculation Robot
ORACLE LINUX 6.5 安装重启后Kernel panic - not syncing : Fatal exception
NFT市场以及如何打造一个NFT市场
通过&修改数组中的值
页面刷新没有执行watch?
进入古诗文网站个人中心,绕过登录
8.03 Day34---BaseMapper query statement usage