当前位置:网站首页>自己学习爬虫写的基础小函数
自己学习爬虫写的基础小函数
2022-08-04 05:26:00 【Drizzlejj】
1.带头和多个参数请求一个网页,因为很多网站都会检测请求头信息。
def Paramsrequest():
base_url = 'http://www.baidu.com/s?'
# 请求所需要携带的参数
data = {
'wd':'周',
'sex':'男',
'location':'中国'
}
# 转化为 unicode 编码
new_data = urllib.parse.urlencode(data)
# 拼接请求资源路径
url = base_url + new_data
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0'
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)2.post请求百度翻译,并返回结果
1.获取url
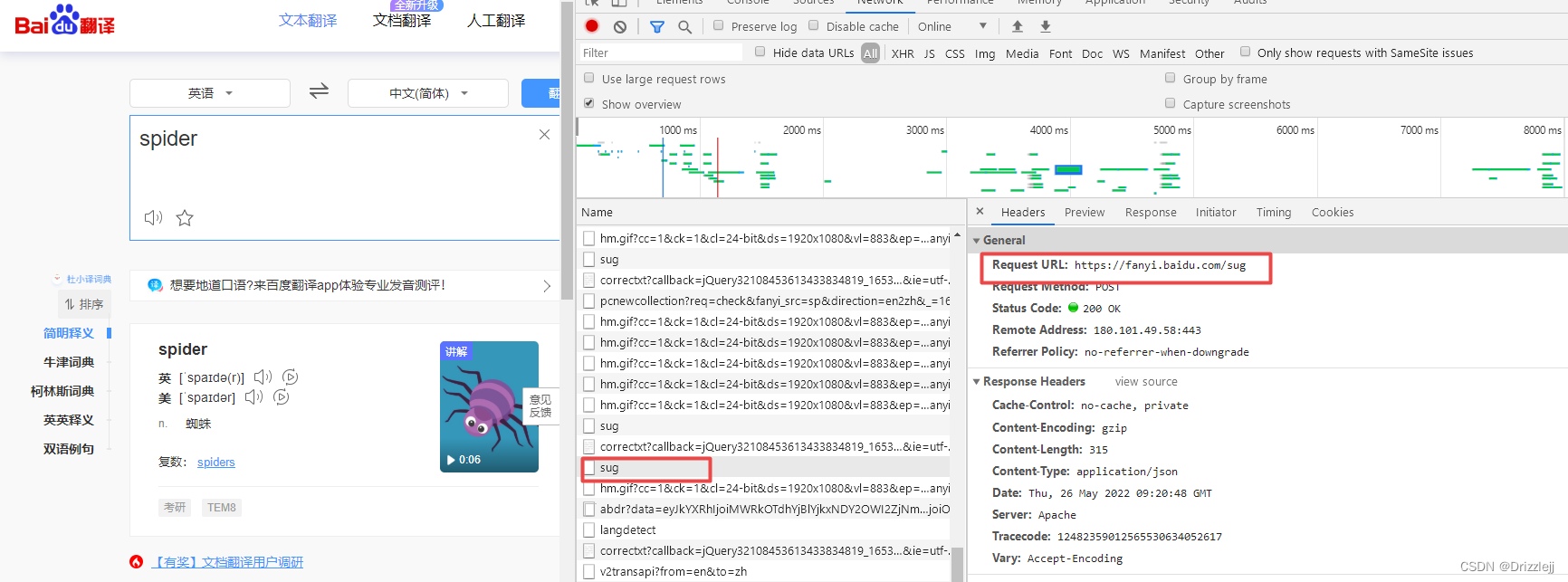
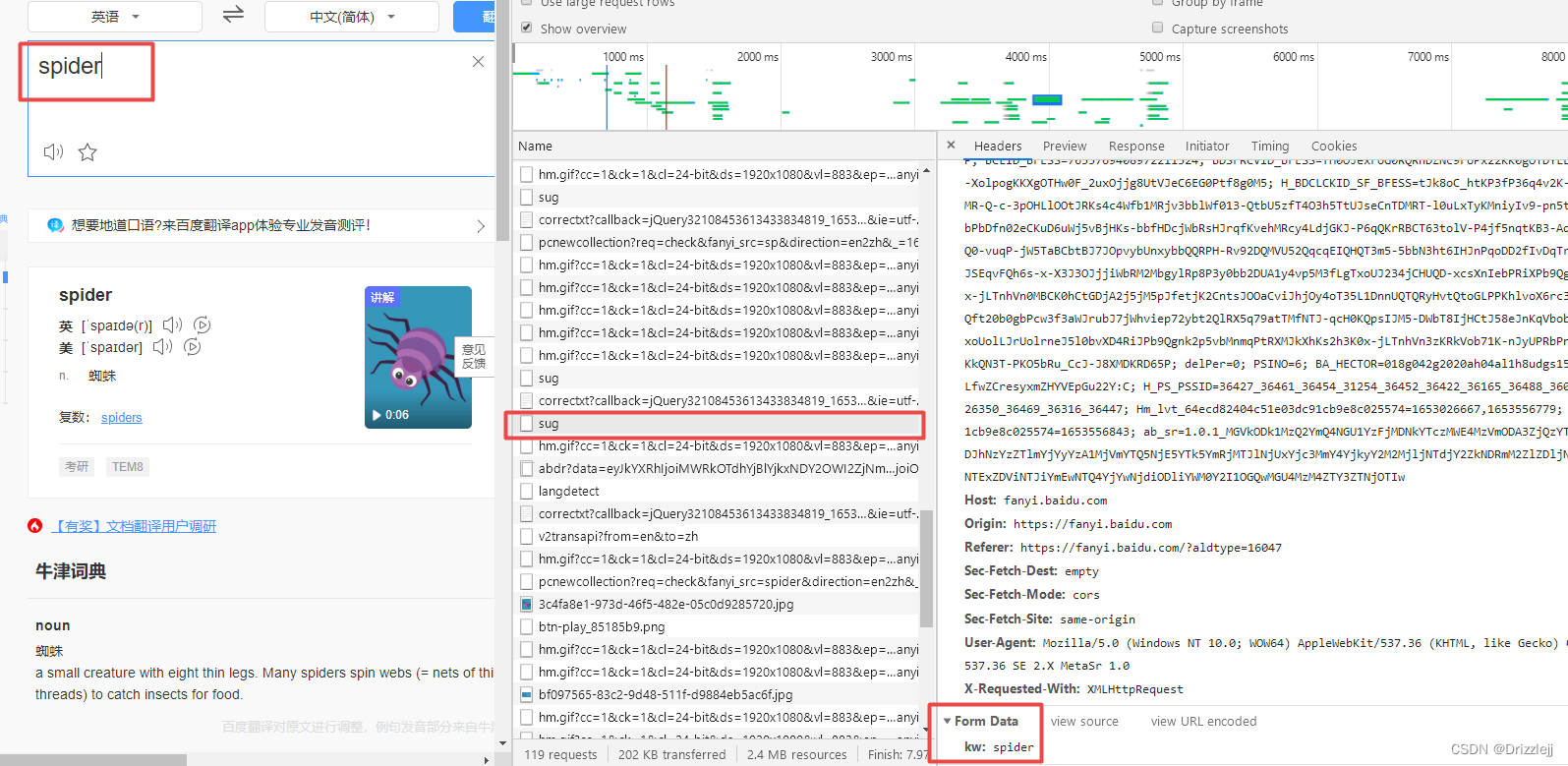
# post 请求百度翻译
import json
def PostBaiduFanyi():
url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0'
}
# F12 =》 Network =》 all 对应的接口 =》 Headers =》 Form Data 中可查看到携带的参数
data = {
'kw':'spider'
}
# post 请求的参数必须进行编码
new_data = urllib.parse.urlencode(data).encode('utf-8')
# post 请求的参数是不会拼接在 url 的后面,需要放在对象定制的参数中(不排除也有post请求的参数拼接在url链接)
request = urllib.request.Request(url=url,data=new_data, headers=headers)
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
# 字符串 =》 json 对象
obj = json.loads(content)
print(obj)反爬会检查 请求头内容,暴力方法全部复制 Request Headers
3.后去豆瓣前十页电影
import re
def GetDoubanOther():
def create_request(page):
base_url = 'https://movie.douban.com/j/search_subjects?type=movie&tag=%E5%8A%A8%E4%BD%9C&sort=recommend&page_limit=20&'
data = {
'page_start':(page - 1) * 20
}
new_data = urllib.parse.urlencode(data) # data 编码
url = base_url + new_data # 拼接url
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0'
}
request = urllib.request.Request(url=url,headers=headers) # 定制请求参数
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page,content):
with open('douban' + str(page) + '.json','w',encoding='utf-8') as fp:
str_content = re.sub(r'\\', '', str(content)) # 将 content 转为字符串,并正则匹配删除转移 '\'
fp.write(str_content)
stat_page = int(input('起始页码:'))
end_page = int(input('结束页:'))
for page in range(stat_page,end_page+1):
request = create_request(page)
content = get_content(request)
down_load(page,content)
4.获取肯德基城市餐厅,看看你所在的城市肯德基的位置
def postkfcinfo():
def create_request(page):
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {
'cname': '成都',
'pid':'',
'pageIndex': page,
'pageSize': '10'
}
new_data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0'
}
request = urllib.request.Request(url=url,headers=headers,data=new_data) # 定制请求参数
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page,content):
with open('kfc' + str(page) +'.json','w',encoding='utf-8') as fp:
fp.write(content)
start_page = int(input('起始页码:'))
end_page = int(input('结束页码:'))
for page in range(start_page,end_page+1):
request = create_request(page)
content = get_content(request)
down_load(page,content)
5.使用自己的IP会被反爬给锁定,不让访问非常不安全,那么就去使用一个代理IP吧。handler 定制更高级的请求头(代理IP)
import random
def Handlergetbaidu():
url = 'http://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0'
}
request = urllib.request.Request(url=url,headers=headers)
# handler = urllib.request.HTTPHandler() # 1.获取 hander 对象
# 创建一个简易的代理池
proxies_poll = [
{'http':'60.211.218.78:53281'}, # 快代理去买一个IP
{'http': '60.211.218.78:53281'},
]
proxies = random.choice(proxies_poll) # 随机选择代理池中的一个IP
handler = urllib.request.ProxyHandler(proxies=proxies)
opener = urllib.request.build_opener(handler) # 2.获取 open 对象
response = opener.open(request) # 3.调用 open 方法
content = response.read().decode('utf-8')
print(content).
边栏推荐
猜你喜欢
![Deploy LVS-DR cluster [experimental]](/img/ad/84e05a6421d668b0b6ba6eeba0c730.jpg)
Deploy LVS-DR cluster [experimental]
8. Custom mapping resultMap
FLV格式详解
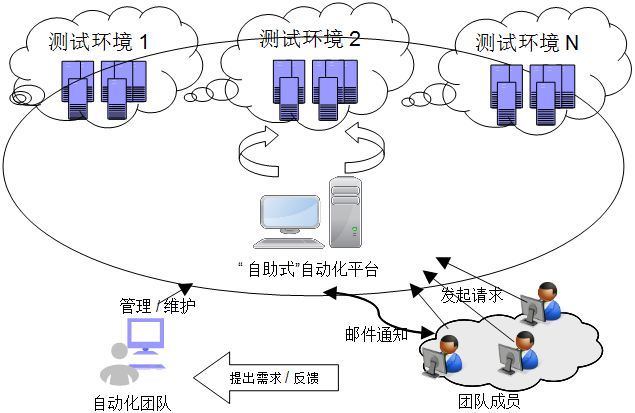
The cost of automated testing is high and the effect is poor, so what is the significance of automated testing?

《看见新力量》第四期免费下载!走进十五位科技创业者的精彩故事
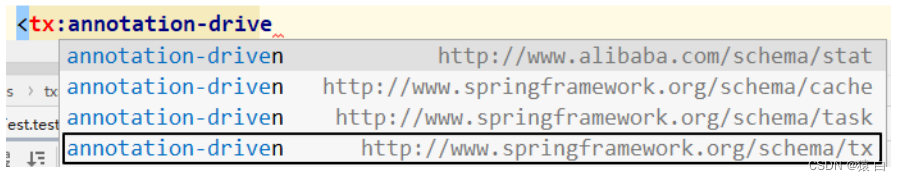
4.3 Annotation-based declarative transactions and XML-based declarative transactions
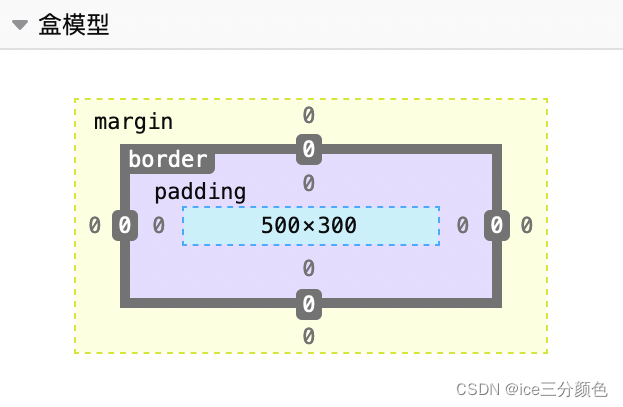
Web Basics and Exercises for C1 Certification - My Study Notes
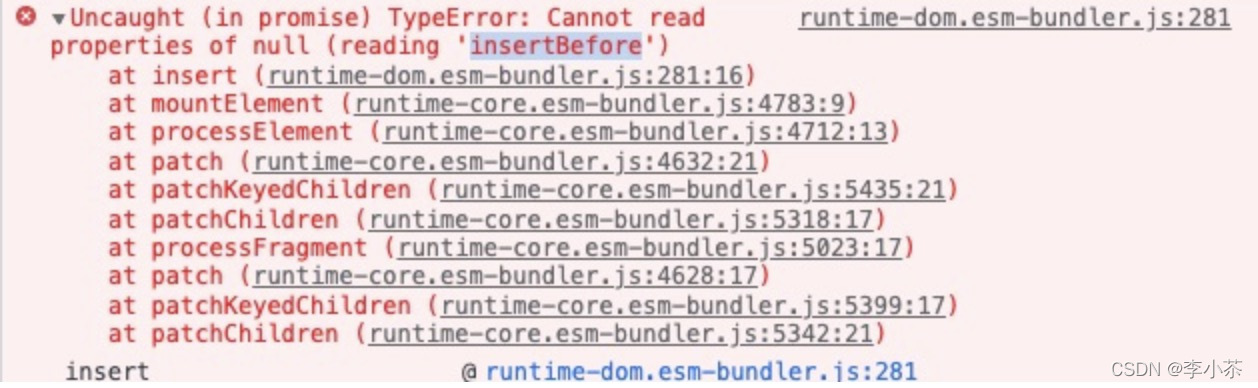
Cannot read properties of null (reading ‘insertBefore‘)

嵌入式系统驱动初级【4】——字符设备驱动基础下_并发控制
解决安装nbextensions后使用Jupyter Notebook时出现template_paths相关错误的问题
随机推荐
8大软件供应链攻击事件概述
MySQL数据库面试题总结(2022最新版)
ORACLE LINUX 6.5 安装重启后Kernel panic - not syncing : Fatal exception
Summary of MySQL database interview questions (2022 latest version)
注意!软件供应链安全挑战持续升级
力扣:343. 整数拆分
7.16 Day22---MYSQL(Dao模式封装JDBC)
Grain Mall - Basics (Project Introduction & Project Construction)
4.2 Declarative Transaction Concept
MediaCodec支持的类型
OpenRefine中的正则表达式
C语言 -- 操作符详解
4.3 Annotation-based declarative transactions and XML-based declarative transactions
webrtc中视频采集实现分析(一) 采集及图像处理接口封装
CentOS7 - yum install mysql
在被面试官说了无数次后,终于潜下心来整理了一下JVM的类加载器
CentOS7 —— yum安装mysql
文献管理工具 | Zotero
关于let var 和const的区别以及使用
力扣:63. 不同路径 II