当前位置:网站首页>【论文阅读笔记】无监督行人重识别中的采样策略
【论文阅读笔记】无监督行人重识别中的采样策略
2022-08-04 05:24:00 【ifsun-】
参考论文《Rethinking Sampling Strategies for Unsupervised Person Re-identification》
一、问题背景
无监督行人重识别仍然具有挑战性,目前的大多数研究将重点放到了设计算法整体框架和损失函数上,但我们发现当这两个因素保持不变时,采用不同的采样策略,模型性能也不同。由此,采样策略也就成为了影响因素之一。
二、具体实现
1.基线模型
采用SpCL中提出的自主监督对比学习和伪标签生成结合的框架。
2.算法整体思路
对所提供的无标注行人图片数据集经过基于CNN的编码器进行特征提取(Resnet50在ImageNet上预训练的模型),然后将它们存储在存储库中。
在每次迭代时,对存储库中的特征经过伪标签生成器分配伪标签,然后对无标注图片+伪标签进行采样。
对于每个mini-batch中的每个样本,计算对比损失更新编码器,更新存储库。
3.采样策略对比
几个概念:
随机采样(最常用):恶化过拟合→模型训练崩溃
三元组采样(一般用于有监督,且与三元组损失配合使用):分组→提升统计稳定性→避免恶化过拟合→模型性能较好
聚类过程中的强类聚集紧密,数量多,结构稳定;弱类聚集松散,数量少,结构易被破坏。
被划分到一个类内的样本应该具有相似的结构,此时相似结构包括身份相似结构和一般相似结构(不良)。
如果一个类能够保证统计稳定性,就既能够保证类内的相似结构不被破坏,又能保证类间的差异。
(1)随机采样
具体做法:将数据集中所有样本随机打乱,然后把每个样本和对应的伪标签加到S(采样后返回的列表)中,进而划分mini-batch训练模型。
但这样相当于对样本随机采样,单个样本的随机性和本身的趋势就会影响到所在类的趋势,从而在聚类时弱类结构容易受到破坏,强类会吞噬弱类,使得一个类包含很多不同ID。这样,随着训练的进行,不良相似结构会不断积累,身份相似结构无法表达。最终使得伪标签质量很差,模型训练崩溃。
但在一般聚类过程中不可避免地会将某个样本分到其他类中(分错类),所以设置了纯粹度和浑浊度衡量一个类的质量。理想情况,希望纯粹度尽可能高,浑浊度尽可能低。
而随机采样的纯粹度很低,浑浊度很高,从而产生恶化过拟合,导致模型训练崩溃。
(2)三元组采样(PK采样)
具体做法:从原始图片中随机选出P个ID,每个ID随机选K张图片作为一个mini-batch训练模型。
这K张图片是来自同一类的就能够削弱单个样本的随机性和趋势,从而保证整个组合的趋势。
当K合适时,三元组采样的纯粹度很高,浑浊度很低,保证了类的统计稳定性,模型效果更好。
缺点:
①一般与三元组损失配合使用,但我们的基线框架采用对比损失,不符合我们的目标;
②如果一个类中样本数量较少,则每次采样会对这些样本重复采样,从而增大他们的权重,导致样本不平衡;
③K的取值不同,模型性能不同,当K越大时,K会大于类中原有的样本数量,进而发生重复采样,样本不平衡,相当于增加了单个样本的随机性,使模型性能不佳。
(3)分组采样
具体做法:

对于聚类集合下每个聚类内的所有样本进行随机打乱,然后每N个划分为一组加到S中,同时最终不足N个的也作为一组加到S中。
对S中所有组进行随机打乱。
将所有离群点进行随机打乱,加到S中。
按照batch size划分mini-batch,对所有mini-batch进行随机打乱,最终返回。
联想IICS中的采样:
首先保证每个ID下至少有K张图片,若不足K张,则从原有图片中重复采样直至到达K张。然后对它们进行随机打乱,每K张划分为一组加到S中,最终不足K张的被丢弃。
按照batch size划分mini batch。
与IICS比较,IICS
①没有进行过多的随机打乱操作;
②对某些图片重复采样,可能会导致样本不平衡;
③划分组时,对不足K张的会丢弃。
分组采样代码:
class GroupSampler(Sampler):
def __init__(self, dataset_labels, group_n=1, batch_size=None):
label2data_idx = defaultdict(list) # 伪标签标注后的数据集中每个ID下的图片序号
for i, (_, label, _) in enumerate(dataset_labels):
label2data_idx[label].append(i)
label2data = defaultdict(list) # 区分离群点集合和聚类集合
for label, data_idx in label2data_idx.items():
if len(data_idx) > 1: # 每个伪标签下至少要有两张图片,聚类集合
label2data[label].extend(data_idx)
else: # 离群点
label2data[-1].extend(data_idx)
self.label2data_idx = label2data
self.dataset_labels = dataset_labels
self.group_n = group_n
self.batch_size = batch_size
def __len__(self):
return len(self.dataset_labels)
def __iter__(self):
data_idxes = [] # 一组一组
for label, data_idx in self.label2data_idx.items():
if label != -1: # 不是离群点,是聚类
data_idx = deepcopy(data_idx) # list
random.shuffle(data_idx) # 对该聚类下的所有图片打乱 1
data_idxes.extend([data_idx[i: i + self.group_n] for i in range(0, len(data_idx), self.group_n)])
# data_idxes.append(data_idx)
random.shuffle(data_idxes) # 2
ret = [] # 一堆图片序号
for data_idx in data_idxes: # 对于所有组中的每一组
ret.extend(data_idx)
data_idx = deepcopy(self.label2data_idx[-1])
random.shuffle(data_idx) # 3
ret.extend(data_idx)
if self.batch_size is not None:
batch_shuffle_ret = [] # 一堆图片序号
tmp = [ret[i: i + self.batch_size] for i in range(0, len(ret), self.batch_size)] # 一组一组
random.shuffle(tmp) # 4
for batch in tmp:
batch_shuffle_ret.extend(batch)
return iter(batch_shuffle_ret)
else:
return iter(ret)
def __str__(self):
return f"GroupSampler(num_instances={self.group_n}, batch_size={self.batch_size})"
def __repr__(self):
return self.__str__()边栏推荐
- day13--postman interface test
- MySQL数据库面试题总结(2022最新版)
- 【SemiDrive源码分析】【MailBox核间通信】47 - 分析RPMSG_IPCC_RPC 方式 单次传输的极限大小 及 极限带宽测试
- 力扣:96.不同的二叉搜索树
- day13--postman接口测试
- 2022年PMP考试延迟了,该喜该忧?
- Performance testing with Loadrunner
- 入坑软件测试的经验与建议
- 8大软件供应链攻击事件概述
- C Expert Programming Chapter 5 Thinking about Chaining 5.6 Take it easy --- see who's talking: take the Turning quiz
猜你喜欢
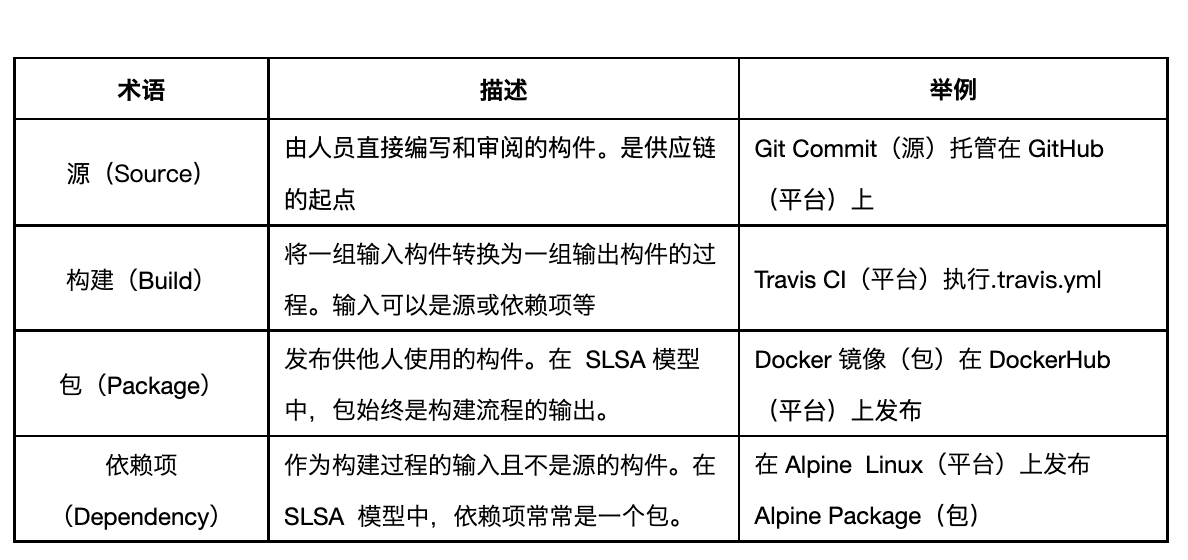
SLSA 框架与软件供应链安全防护
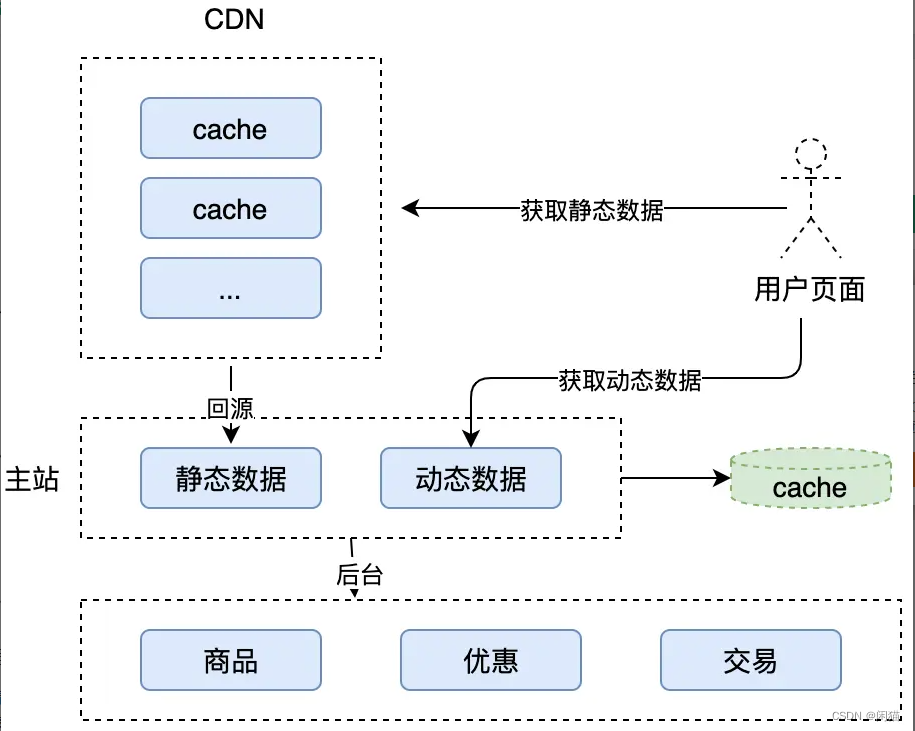
System design. How to design a spike system (full version transfer)
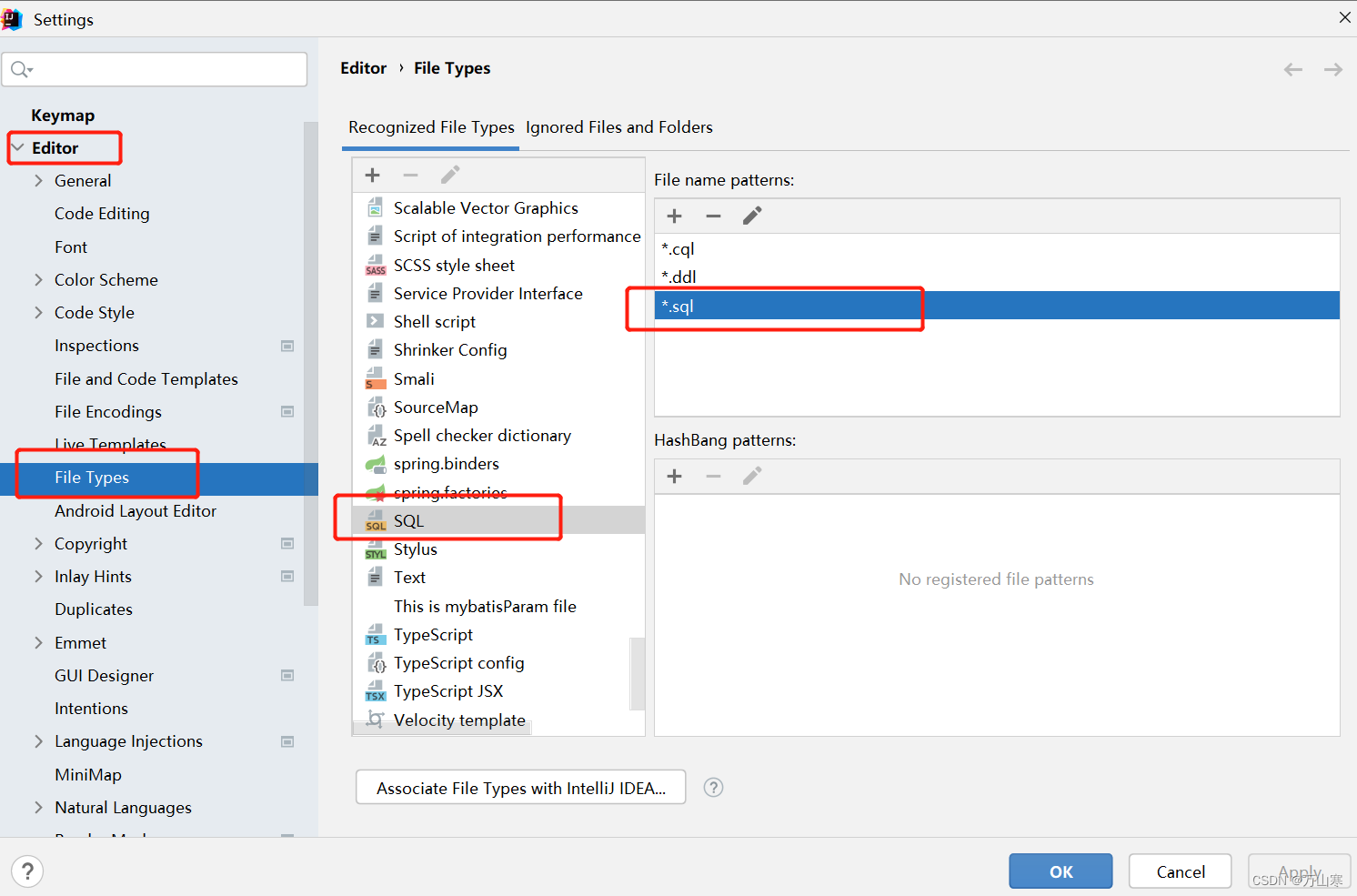
idea设置识别.sql文件类型以及其他文件类型

嵌入式系统驱动初级【4】——字符设备驱动基础下_并发控制
![[Evaluation model] Topsis method (pros and cons distance method)](/img/e7/c24241faced567f3e93f6ff3f20074.png)
[Evaluation model] Topsis method (pros and cons distance method)
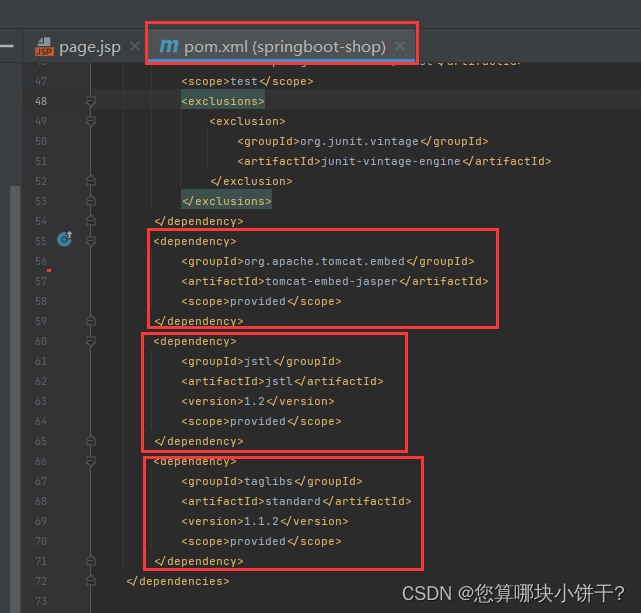
8.03 Day34---BaseMapper查询语句用法
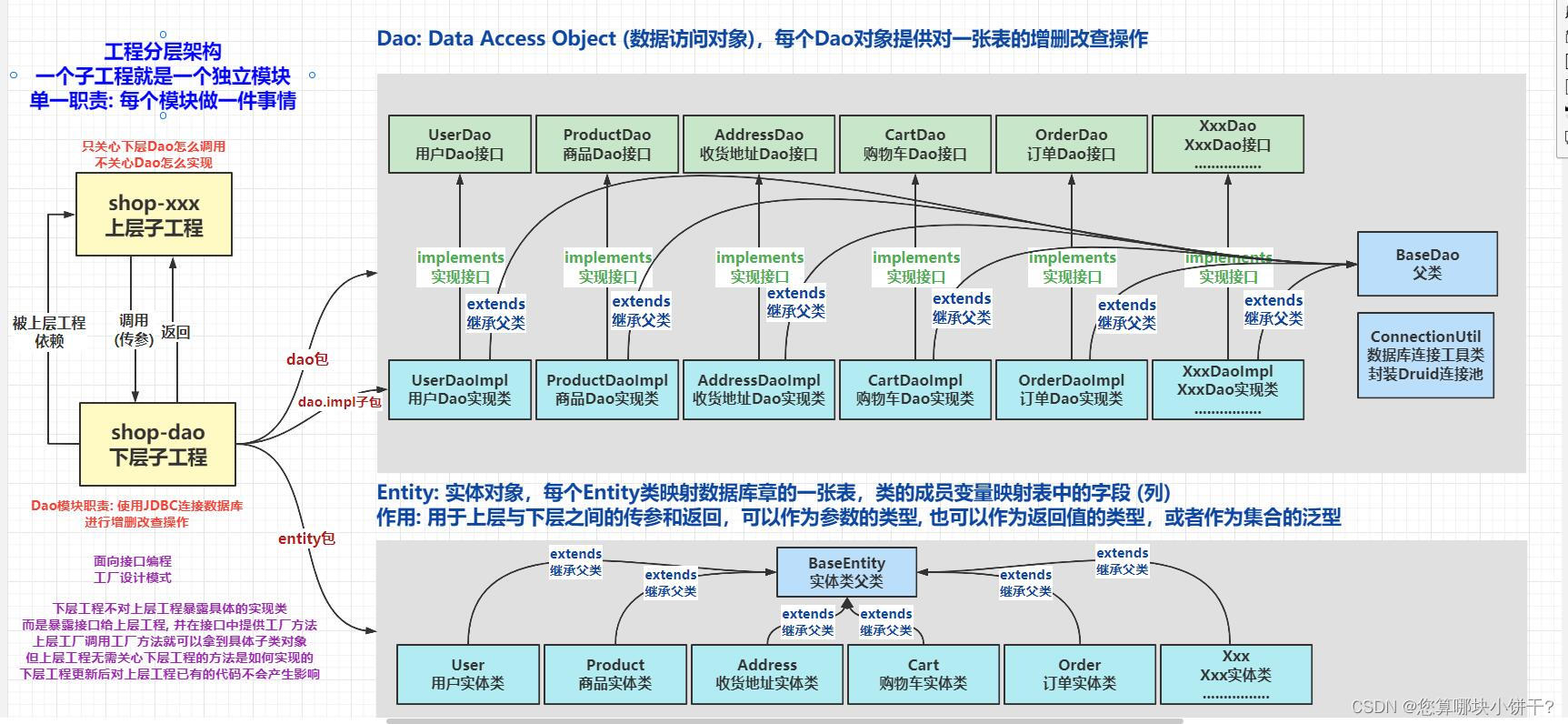
7.16 Day22---MYSQL(Dao模式封装JDBC)
心余力绌:企业面临的软件供应链安全困境
【评价类模型】Topsis法(优劣解距离法)

OpenSSF 安全计划:SBOM 将驱动软件供应链安全
随机推荐
离线采集怎么看sql执行计划
如何将 DevSecOps 引入企业?
C1认证之web基础知识及习题——我的学习笔记
CentOS7 - yum install mysql
一个对象引用的思考
C专家编程 第5章 对链接的思考 5.1 函数库、链接和载入
你以为border-radius只是圆角吗?【各种角度】
canal实现mysql数据同步
4.3 Annotation-based declarative transactions and XML-based declarative transactions
What are the steps for how to develop a mall system APP?
How to view sql execution plan offline collection
渗透测试(PenTest)基础指南
MySql数据恢复方法个人总结
Programming hodgepodge (4)
Cannot read properties of null (reading ‘insertBefore‘)
商城App开发都有哪些功能呢
redis中常见的面试题
What are the functions of mall App development?
商城系统APP如何开发 都有哪些步骤
7.13 Day20----MYSQL