当前位置:网站首页>【深度学习】语义分割实验:Unet网络/MSRC2数据集
【深度学习】语义分割实验:Unet网络/MSRC2数据集
2022-07-07 13:01:00 【zstar-_】
本实验使用Unet网络对MSRC2数据集进行划分
源代码文件和MSRC2数据集获取方式见文末
1.数据划分
把图片数据从文件夹整理成csv文件,每一行代表其路径
class image2csv(object):
# 分割训练集 验证集 测试集
# 做成对应的txt
def __init__(self, data_root, image_dir, label_dir, slice_data, width_input, height_input):
self.data_root = data_root
self.image_dir = image_dir
self.label_dir = label_dir
self.slice_train = slice_data[0]
self.slice_val = slice_data[1]
self.width = width_input
self.height = height_input
def read_path(self):
images = []
labels = []
for i, im in enumerate(os.listdir(self.image_dir)):
label_name = im.split('.')[0] + '_GT' + '.bmp'
# 由于各图片大小不同,这里进行简单的筛选,只有长宽均大于200px才被选取
if os.path.exists(os.path.join(self.label_dir, label_name)):
size_w, size_h = Image.open(
os.path.join(self.image_dir, im)).size
size_lw, size_lh = Image.open(
os.path.join(self.label_dir, label_name)).size
if min(size_w, size_lw) > self.width and min(size_h, size_lh) > self.height:
images.append(os.path.join(self.image_dir, im))
labels.append(os.path.join(self.label_dir, label_name))
else:
continue
self.data_length = len(images) # 两个文件夹都有的图片的长度
data_path = {
'image': images,
'label': labels,
}
return data_path
def generate_csv(self):
data_path = self.read_path() # 存放了路径
data_path_pd = pd.DataFrame(data_path)
train_slice_point = int(self.slice_train*self.data_length) # 0.7*len
validation_slice_point = int(
(self.slice_train+self.slice_val)*self.data_length) # 0.8*len
train_csv = data_path_pd.iloc[:train_slice_point, :]
validation_csv = data_path_pd.iloc[train_slice_point:validation_slice_point, :]
test_csv = data_path_pd.iloc[validation_slice_point:, :]
train_csv.to_csv(os.path.join(
self.data_root, 'train.csv'), header=None, index=None)
validation_csv.to_csv(os.path.join(
self.data_root, 'val.csv'), header=None, index=None)
test_csv.to_csv(os.path.join(self.data_root, 'test.csv'),
header=False, index=False)
2.数据预处理
颜色与分类标签的转换
语义分割主要是构建一个颜色图(colormap),对每一类分割的对象分别给予不同的颜色标注。
def colormap(n):
cmap = np.zeros([n, 3]).astype(np.uint8)
for i in np.arange(n):
r, g, b = np.zeros(3)
for j in np.arange(8):
r = r + (1 << (7 - j)) * ((i & (1 << (3 * j))) >> (3 * j))
g = g + (1 << (7 - j)) * ((i & (1 << (3 * j + 1))) >> (3 * j + 1))
b = b + (1 << (7 - j)) * ((i & (1 << (3 * j + 2))) >> (3 * j + 2))
cmap[i, :] = np.array([r, g, b])
return cmap
class label2image():
def __init__(self, num_classes=22):
self.colormap = colormap(256)[:num_classes].astype('uint8')
def __call__(self, label_pred, label_true):
pred = self.colormap[label_pred]
true = self.colormap[label_true]
return pred, true
class image2label():
def __init__(self, num_classes=22):
# 给每一类都来一种颜色
colormap = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0],
[0, 0, 128], [0, 128, 128], [128, 128, 128], [192, 0, 0],
[64, 128, 0], [192, 128, 0], [64, 0, 128], [192, 0, 128],
[64, 128, 128], [192, 128, 128], [0, 64, 0], [128, 64, 0],
[0, 192, 0], [128, 64, 128], [
0, 192, 128], [128, 192, 128],
[64, 64, 0], [192, 64, 0]]
self.colormap = colormap[:num_classes]
# 创建256^3 次方空数组,颜色的所有组合
cm2lb = np.zeros(256 ** 3)
for i, cm in enumerate(self.colormap):
cm2lb[(cm[0] * 256 + cm[1]) * 256 + cm[2]] = i # 符合这种组合的标记这一类
self.cm2lb = cm2lb
def __call__(self, image):
image = np.array(image, dtype=np.int64)
idx = (image[:, :, 0] * 256 + image[:, :, 1]) * 256 + image[:, :, 2]
label = np.array(self.cm2lb[idx], dtype=np.int64) # 根据颜色条找到这个label的标号
return label
图片裁剪
class RandomCrop(object):
""" 自定义实现图像与label随机裁剪相同的位置 """
def __init__(self, size):
self.size = size
@staticmethod
def get_params(img, output_size):
w, h = img.size
th, tw = output_size
if w == tw and h == th:
return 0, 0, h, w
i = random.randint(0, h - th)
j = random.randint(0, w - tw)
return i, j, th, tw
def __call__(self, img, label):
i, j, h, w = self.get_params(img, self.size)
return img.crop((j, i, j + w, i + h)), label.crop((j, i, j + w, i + h))
3.数据加载
class CustomDataset(Dataset):
def __init__(self, data_root_csv, input_width, input_height, test=False):
# 在子类进行初始化时,也想继承父类的__init__()就通过super()实现
super(CustomDataset, self).__init__()
self.data_root_csv = data_root_csv
self.data_all = pd.read_csv(self.data_root_csv)
self.image_list = list(self.data_all.iloc[:, 0])
self.label_list = list(self.data_all.iloc[:, 1])
self.width = input_width
self.height = input_height
def __len__(self):
return len(self.image_list)
def __getitem__(self, index):
img = Image.open(self.image_list[index]).convert('RGB')
label = Image.open(self.label_list[index]).convert('RGB')
img, label = self.train_transform(
img, label, crop_size=(self.width, self.height))
# assert(img.size == label.size)s
return img, label
def train_transform(self, image, label, crop_size=(256, 256)):
image, label = RandomCrop(crop_size)(
image, label) # 第一个括号是实例话对象,第二个是__call__方法
tfs = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([.485, .456, .406], [.229, .224, .225])
])
image = tfs(image)
label = image2label()(label)
label = torch.from_numpy(label).long()
return image, label
4.Unet 网络结构
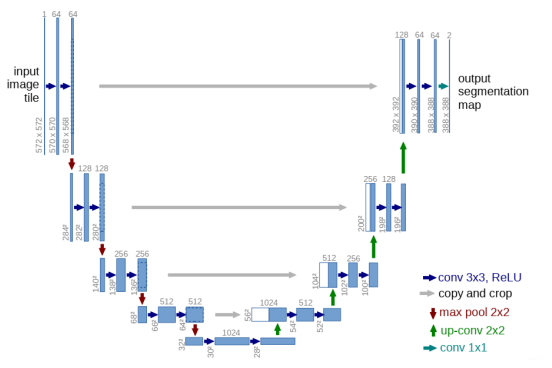
双卷积结构
class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
下采样
class Down(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
上采样
class Up(nn.Module):
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
if bilinear:
self.up = nn.Upsample(
scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(
in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
输出
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
整体结构
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
5.评估指标:MIoU
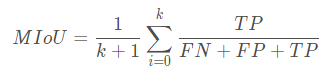
# 得到混淆矩阵
def _fast_hist(label_true, label_pred, n_class):
mask = (label_true >= 0) & (label_true < n_class)
hist = np.bincount(
n_class * label_true[mask].astype(int) +
label_pred[mask], minlength=n_class ** 2).reshape(n_class, n_class)
return hist
# 计算MIOU
def miou_score(label_trues, label_preds, n_class):
hist = np.zeros((n_class, n_class))
for lt, lp in zip(label_trues, label_preds):
hist += _fast_hist(lt.flatten(), lp.flatten(), n_class)
iou = np.diag(hist) / (hist.sum(axis=1) + hist.sum(axis=0) - np.diag(hist))
miou = np.nanmean(iou)
return miou
6.训练
GPU_ID = 0
INPUT_WIDTH = 200
INPUT_HEIGHT = 200
BATCH_SIZE = 2
NUM_CLASSES = 22
LEARNING_RATE = 1e-3
epoch = 300
net = UNet(3, NUM_CLASSES)
# -------------------- 生成csv ------------------
DATA_ROOT = './MSRC2/'
image = os.path.join(DATA_ROOT, 'Images')
label = os.path.join(DATA_ROOT, 'GroundTruth')
slice_data = [0.7, 0.1, 0.2] # 训练 验证 测试所占百分比
tocsv = image2csv(DATA_ROOT, image, label, slice_data,
INPUT_WIDTH, INPUT_HEIGHT)
tocsv.generate_csv()
# -------------------------------------------
model_path = './model_result/best_model_UNet.mdl'
train_csv_dir = 'MSRC2/train.csv'
val_csv_dir = 'MSRC2/val.csv'
train_data = CustomDataset(train_csv_dir, INPUT_WIDTH, INPUT_HEIGHT)
train_dataloader = DataLoader(
train_data, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
val_data = CustomDataset(val_csv_dir, INPUT_WIDTH, INPUT_HEIGHT)
val_dataloader = DataLoader(
val_data, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
net = UNet(3, NUM_CLASSES)
use_gpu = torch.cuda.is_available()
# 构建网络
optimizer = optim.Adam(net.parameters(), lr=LEARNING_RATE, weight_decay=1e-4)
criterion = nn.CrossEntropyLoss()
if use_gpu:
torch.cuda.set_device(GPU_ID)
net.cuda()
criterion = criterion.cuda()
if os.path.exists(model_path):
net.load_state_dict(torch.load(model_path))
print('successful load weight!')
else:
print('not successful load weight')
# 训练验证
# def train():
best_score = 0.0
for e in range(epoch):
net.train()
train_loss = 0.0
label_true = torch.LongTensor()
label_pred = torch.LongTensor()
for i, (batchdata, batchlabel) in enumerate(train_dataloader):
if use_gpu:
batchdata, batchlabel = batchdata.cuda(), batchlabel.cuda()
output = net(batchdata)
output = F.log_softmax(output, dim=1)
loss = criterion(output, batchlabel)
pred = output.argmax(dim=1).squeeze().data.cpu()
real = batchlabel.data.cpu()
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.cpu().item() * batchlabel.size(0)
label_true = torch.cat((label_true, real), dim=0)
label_pred = torch.cat((label_pred, pred), dim=0)
train_loss /= len(train_data)
miou = miou_score(
label_true.numpy(), label_pred.numpy(), NUM_CLASSES)
print('\nepoch:{}, train_loss:{:.4f},miou:{:.4f}'.format(
e + 1, train_loss, miou))
net.eval()
val_loss = 0.0
val_label_true = torch.LongTensor()
val_label_pred = torch.LongTensor()
with torch.no_grad():
for i, (batchdata, batchlabel) in enumerate(val_dataloader):
if use_gpu:
batchdata, batchlabel = batchdata.cuda(), batchlabel.cuda()
output = net(batchdata)
output = F.log_softmax(output, dim=1)
loss = criterion(output, batchlabel)
pred = output.argmax(dim=1).data.cpu()
real = batchlabel.data.cpu()
val_loss += loss.cpu().item() * batchlabel.size(0)
val_label_true = torch.cat((val_label_true, real), dim=0)
val_label_pred = torch.cat((val_label_pred, pred), dim=0)
val_loss /= len(val_data)
val_miou = miou_score(val_label_true.numpy(),
val_label_pred.numpy(), NUM_CLASSES)
print('epoch:{}, val_loss:{:.4f}, miou:{:.4f}'.format(
e + 1, val_loss, val_miou))
# 通过验证集的val_miou来判断模型效果,保存最好的模型权重
score = val_miou
if score > best_score:
best_score = score
torch.save(net.state_dict(), model_path)
7.测试
GPU_ID = 0
INPUT_WIDTH = 200
INPUT_HEIGHT = 200
BATCH_SIZE = 2
NUM_CLASSES = 22
LEARNING_RATE = 1e-3
model_path = './model_result/best_model_UNet.mdl'
torch.cuda.set_device(0)
net = UNet(3, NUM_CLASSES)
# 加载网络进行测试
test_csv_dir = './MSRC2/train.csv'
testset = CustomDataset(test_csv_dir, INPUT_WIDTH, INPUT_HEIGHT)
test_dataloader = DataLoader(testset, batch_size=15, shuffle=False)
net.load_state_dict(torch.load(model_path, map_location='cuda:0'))
test_label_true = torch.LongTensor()
test_label_pred = torch.LongTensor()
# 这里只提取一个batch来测试,即15张图片
for (val_image, val_label) in test_dataloader:
net.cuda()
out = net(val_image.cuda())
pred = out.argmax(dim=1).squeeze().data.cpu().numpy()
label = val_label.data.numpy()
output = F.log_softmax(out, dim=1)
pred = output.argmax(dim=1).data.cpu()
real = val_label.data.cpu()
test_label_true = torch.cat((test_label_true, real), dim=0)
test_label_pred = torch.cat((test_label_pred, pred), dim=0)
test_miou = miou_score(test_label_true.numpy(),
test_label_pred.numpy(), NUM_CLASSES)
print("测试集上的miou为:" + str(test_miou))
val_pred, val_label = label2image(NUM_CLASSES)(pred, label)
for i in range(15):
val_imag = val_image[i]
val_pre = val_pred[i]
val_labe = val_label[i]
# 反归一化
mean = [.485, .456, .406]
std = [.229, .224, .225]
x = val_imag
for j in range(3):
x[j] = x[j].mul(std[j])+mean[j]
img = x.mul(255).byte()
img = img.numpy().transpose((1, 2, 0)) # 原图
fig, ax = plt.subplots(1, 3, figsize=(30, 30))
ax[0].imshow(img)
ax[1].imshow(val_labe)
ax[2].imshow(val_pre)
plt.show()
plt.savefig('./pic_results/pic_UNet_{}.png'.format(i))
break
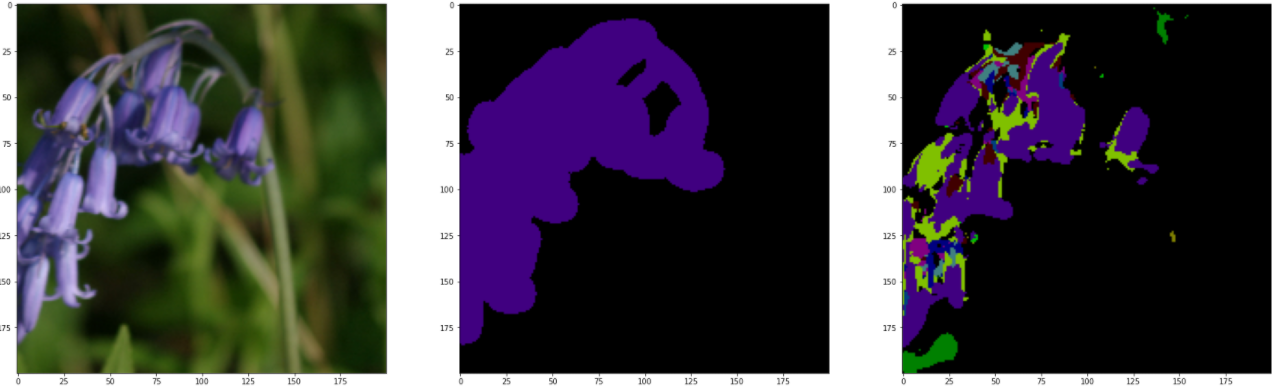
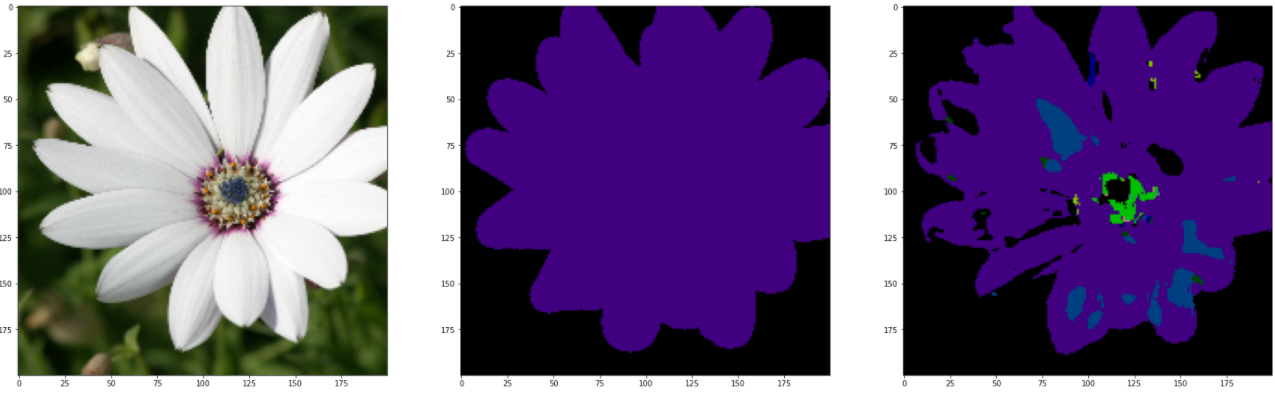
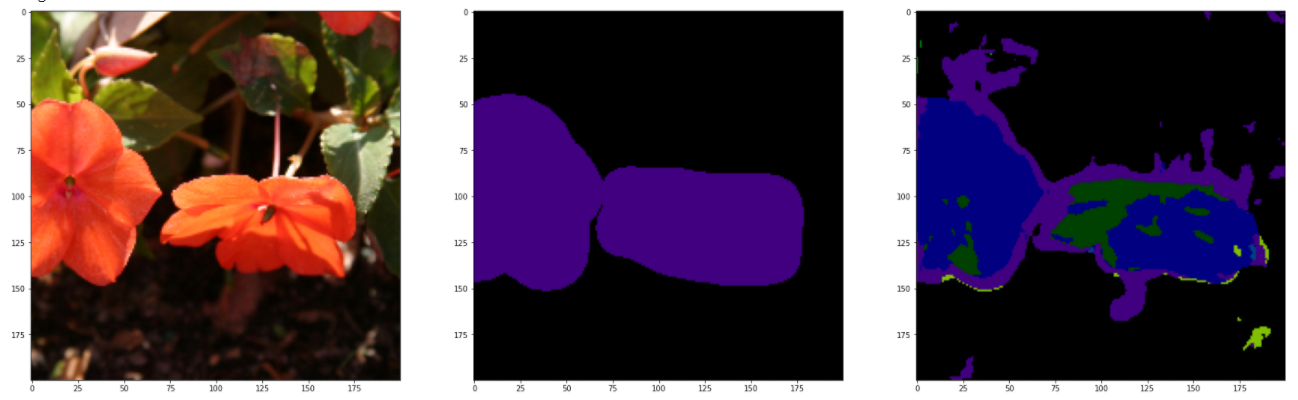
理论上,应该用测试集进行测试,但测试的结果惨不忍观。可能是由于训练次数不足导致,在上面这段代码中,直接导入训练集进行查看,下面是和GroundTruth进行对比参照图。
完整源码
实验源码+MSRC2数据集
https://pan.baidu.com/s/1WSgs1fVVfKL4poBFjhaBfA?pwd=8888
边栏推荐
- CTFshow,信息搜集:web12
- Ctfshow, information collection: web2
- IDA pro逆向工具寻找socket server的IP和port
- Ctfshow, information collection: web7
- 什么是数据泄露
- MicTR01 Tester 振弦采集模塊開發套件使用說明
- Niuke real problem programming - Day9
- 智汀不用Home Assistant让小米智能家居接入HomeKit
- [today in history] July 7: release of C; Chrome OS came out; "Legend of swordsman" issued
- 【OBS】RTMPSockBuf_Fill, remote host closed connection.
猜你喜欢

Novel Slot Detection: A Benchmark for Discovering Unknown Slot Types in the Dialogue System
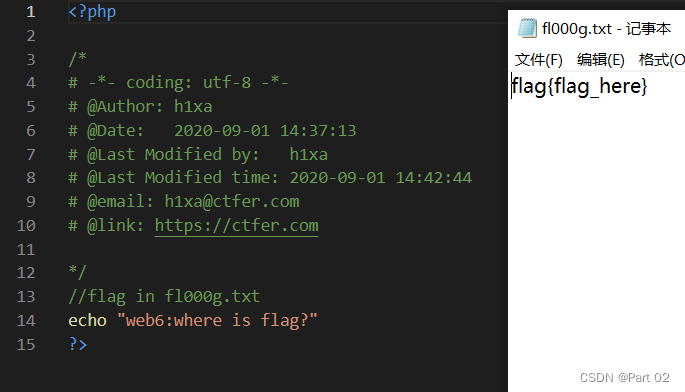
CTFshow,信息搜集:web6

Stm32cubemx, 68 sets of components, following 10 open source protocols

CPU与chiplet技术杂谈

What is cloud primordial? This time, I can finally understand!
Computer win7 system desktop icon is too large, how to turn it down

2022年5月互联网医疗领域月度观察
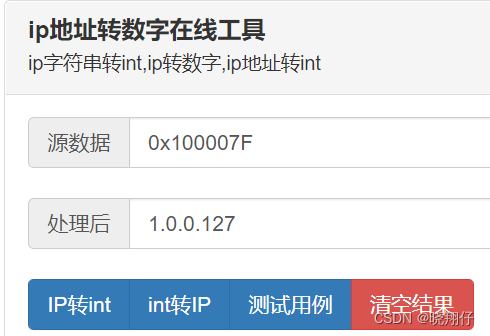
IDA pro逆向工具寻找socket server的IP和port
拜拜了,大厂!今天我就要去厂里
CTFshow,信息搜集:web13
随机推荐
拜拜了,大厂!今天我就要去厂里
Ctfshow, information collection: web13
Bill Gates posted his resume 48 years ago: "it's not as good-looking as yours."
Classification of regression tests
Discussion on CPU and chiplet Technology
CTFshow,信息搜集:web12
"July 2022" Wukong editor update record
什么是数据泄露
Find your own value
Ctfshow, information collection: web4
15、文本编辑工具VIM使用
Yyds dry goods inventory # solve the real problem of famous enterprises: cross line
Wechat applet - Advanced chapter component packaging - Implementation of icon component (I)
CTFshow,信息搜集:web6
MicTR01 Tester 振弦采集模塊開發套件使用說明
A laravel background management expansion package you can't miss - Voyager
Instructions d'utilisation de la trousse de développement du module d'acquisition d'accord du testeur mictr01
Data Lake (IX): Iceberg features and data types
Apache多个组件漏洞公开(CVE-2022-32533/CVE-2022-33980/CVE-2021-37839)
[server data recovery] a case of RAID data recovery of a brand StorageWorks server