当前位置:网站首页>[recommendation system paper reading] recommendation simulation user feedback based on Reinforcement Learning
[recommendation system paper reading] recommendation simulation user feedback based on Reinforcement Learning
2022-07-08 01:59:00 【Wwwilling】
Article
- author :Xiangyu Zhao, Long Xia, Lixin Zou, Dawei Yin, Jiliang Tang
- Literature title : Recommendation based on reinforcement learning simulates user feedback
- Document time :2019
- Links to Literature :https://arxiv.org/abs/1906.11462
Abstract
- With reinforcement learning (RL) What's new , People's confidence in the future RL Great interest has been generated for recommendation systems . However , Direct training and evaluation of new based on RL Our recommendation algorithm needs to collect users' real-time feedback in the real system , It takes time and effort , And may have a negative impact on the user experience . therefore , It needs a user simulator that can simulate real user behavior , We can pre train and evaluate new recommended algorithms . Simulating the behavior of users in dynamic systems faces great challenges :
- (i) Underline the complex distribution of items , also
- (ii) The history of each user is limited .
In this paper , We have developed a generation based countermeasure network (GAN) User simulator for . say concretely , The generator captures the underline distribution of user history logs , Generate real logs , It can be considered as an extension of the real log ; And the discriminator can not only distinguish between true and false logs , It can also predict user behavior . Experimental results based on real-world e-commerce data demonstrate the effectiveness of the proposed simulator .
background
- With the recent intensive learning (RL) Great development of , People are paying more and more attention to RL Apply to recommendations . be based on RL Our recommendation system regards the recommendation process as users and recommendation agents (RA) Sequential interaction between . They are designed to automatically learn the best recommendation strategy ( Strategy ), Maximize the cumulative rewards of users without any specific instructions . Recommendation system based on reinforcement learning can realize two key advantages :
- (i) Recommendation agents can constantly learn their recommendation strategies according to the real-time feedback of users in the interaction process of user agents ; and
- (ii) The goal of the optimal strategy is to maximize the long-term return of users ( For example, the total revenue of recommendation sessions ).
- However , Simulate user behavior in a dynamic recommendation environment ( feedback ) It's very challenging . There are millions of items in the actual recommendation system . therefore , In the history log , The underline of the recommended item sequence is widely distributed and extremely complex . In order to learn a powerful simulator , It usually requires large-scale historical logs as training data from each user . Although a large number of historical logs can usually be used , But the data available to each user is quite limited .
- To address these two challenges , We propose a simulator (RecSimu), For generating countermeasure networks based on (GAN) Recommendations based on reinforcement learning .
Main contributions
- We introduce a principle method to capture the underline distribution of the recommended item sequence in the historical log , And generate a real project sequence ;
- We propose a user behavior simulator RecSimu, It can be used to simulate the environment for pre training and evaluation based on RL The recommendation system of ; and
- We conduct experiments based on real-world data , To demonstrate the effectiveness of the proposed simulator and verify the effectiveness of its components .
Problem description
- Follow chart 2 A common setting shown , We first formally define recommendations based on reinforcement learning , Then based on this setting, we propose the problem we aim to solve . under these circumstances , We regard the recommendation task as a recommendation system ( agent ) And the user ( Environmental Science E) Sequential interaction between , And use Markov decision process (MDP) Model it . It consists of a series of States 、 Actions and rewards . Usually ,MDP There are four elements involved ( S , A , P , R ) (S,A,P,R) (S,A,P,R), Next we will introduce how to set them . Please note that , There are other settings , We will further investigate it as a future work .

- The state space S S S: We will be in the state of s = { i 1 , . . . , i N } ∈ S s= \{ i_1,...,i_N \} \in S s={ i1,...,iN}∈S Defined as the user browsing N N N The sequence of items and the corresponding user feedback on each item . s s s The items in are sorted in chronological order .
- Action space A A A: From the perspective of recommendation system , action a ∈ A a \in A a∈A It is defined as recommending a set of items to users . No loss of generality , We assume that each time the recommendation system recommends a project to the user , But you can directly extend this setting to recommend more projects .
- Reward R R R: When the system according to the state s s s Take action a a a when , The user will browse the recommended project and provide her feedback on the project . In this paper , We assume that users can skip 、 Click and buy recommended products . Then the recommendation system will only be rewarded according to the type of feedback r ( s , a ) r(s, a) r(s,a).
- State transition probability P P P: State transition probability p ( s ′ ∣ s , a ) p(s'|s,a) p(s′∣s,a) Defined as performing actions a a a When the state changes from s s s Transferred to the s ′ s' s′ Probability . We assume that the state transition is deterministic : We are always from s s s Delete the first item i 1 i_1 i1 And in s s s Add action at the bottom of a a a, namely s ′ = { i 2 , . . . , i N , a } s' = \{ i_2,..., i_N , a \} s′={ i2,...,iN,a}.
- Use the above definitions and symbols , In this paper , Our goal is to build a simulator , Imitate users' feedback on recommended items based on user preferences learned from users' browsing history ( Behavior ), Pictured 2 Shown . let me put it another way , The simulator is designed to simulate the reward function r(s, a). More formally , The objectives of the simulator can be formally defined as follows : Given a state - The action is right ( s , a ) (s, a) (s,a), The goal is to find a reward function r ( s , a ) r(s, a) r(s,a), It can accurately imitate the behavior of users .
Simulator is recommended
- In this section , We will propose a simulator framework , The framework simulates users' feedback on recommended items based on their current preferences learned from browsing history ( Behavior ). As mentioned earlier , Building user simulators is challenging , because
- (1) The underline distribution of the item sequence in the user history log is complex ,
- (2) The historical data of each user is usually limited .
- Generative antagonistic network (GAN) And its variants can generate false but real images , This means their potential in modeling complex distributions . Besides , The generated image can be regarded as the enhancement of real-world images , To expand the data space . Driven by these advantages , We suggest building on GAN To capture the complex distribution of user browsing logs and generate real logs to enrich the training data set . be based on GAN Another challenge of the simulator is that the discriminator should not only be able to distinguish between real logs and generated logs , It should also be able to predict user feedback on recommended items . To meet these challenges , We propose a scheme as shown in the figure 3 The recommended simulator shown .

- The generator with supervision component is designed to learn data distribution and generate indistinguishable logs , A discriminator with a monitoring component can distinguish the truth at the same time / Generate logs and predict user feedback on recommended items . Next, we will introduce the architecture of generator and discriminator respectively , Then discuss the optimized objective function .
Generator architecture
- The goal of the generator is to learn data distribution , Then according to the user's browsing history ( state ) Generate indistinguishable logs ( action ), That is to imitate the recommendation strategy of the recommendation system that generates historical logs . chart 4 It shows that there is an encoder - decoder (Encoder-Decoder) Schema generator .

- Encoder The component aims to learn users' preferences according to the items they browse and users' feedback . The input is the state observed in the historical log s = { i 1 , . . . , i N } s= \{ i_1,...,i_N \} s={ i1,...,iN}, That is, what users browse N N N The sequence of items and the corresponding user feedback on each item . Output is a low dimensional representation of users' current preferences , be called p E p^E pE. Each project i n ∈ s i_n \in s in∈s There are two types of information involved :
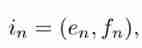
- among e n e_n en It is a low dimensional intensive project embedding of recommended projects (embedding), f n f_n fn It's a single heat vector (one-hot vector) Express , Indicates the user's feedback on the recommended items . The reason for choosing these two kinds of information is , We should not only learn the information of each item in the sequence , Also capture users' interest in each project ( feedback ). We use embedded layers (embedding layer) take f n f_n fn Convert to low dimensional dense vector : F n = t a n h ( W F f n + b F ) ∈ R ∣ f ∣ F_n = tanh(W_Ff_n+b_F) \in R^{|f|} Fn=tanh(WFfn+bF)∈R∣f∣. Please note that , We use “tanh” Activation function , because e n ∈ ( − 1 , + 1 ) e_n \in (−1, +1) en∈(−1,+1). then , We will e n e_n en and F n F_n Fn Connect , Get a low dimensional dense vector :

- Please note that , All embedded layers (embedding layer) Share the same parameters W F W_F WF and b F b_F bF , This can reduce the number of parameters and have better generalization . We introduce a cycle unit with gating (GRU) Cyclic neural network based on (RNN) To capture the sequence pattern of items in the log . We choose GRU instead of Long Short-Term Memory (LSTM), because GRU Has fewer parameters , The architecture is simpler . We will RNN The final hidden state of is regarded as the output of the encoder component , That is, users' current preferences p E p^E pE The low dimension of .
- Decoder The goal of the component is to predict the items that will be recommended according to the current preferences of users . therefore , Input is the user's preference p E p^E pE, The output is the embedding of items that predict the next location in the log (item-embedding), be called G θ ( s ) G_{\theta}(s) Gθ(s). For the sake of simplification , We use several full connection layers as the decoder to p E p^E pE Convert directly to G θ ( s ) G_{\theta}(s) Gθ(s). Please note that , Using other methods to generate the next project is simple , For example, using softmax Layer calculates the correlation score of all items , And choose the item with the highest score as the next item . up to now , We have described Generator The architecture of , It aims to imitate the recommendation strategy of the existing recommendation system , And generate real logs to expand historical data . Besides , We added a monitoring component , To encourage the generator to generate projects that are close to real value projects , This will be in the 3 Section discusses . Next , We will discuss the architecture of the discriminator .
Discriminator Architecture
- The discriminator should not only distinguish the real historical log from the generated log , It is also necessary to predict the user's feedback category on the recommended items according to the user's browsing history . therefore , We regard this problem as having 2 × K 2 \times K 2×K Class classification problem , That is, the real feedback of the recommended items observed from the historical log is K K K class , The false feedback of the recommended items generated by the generator is K K K class .
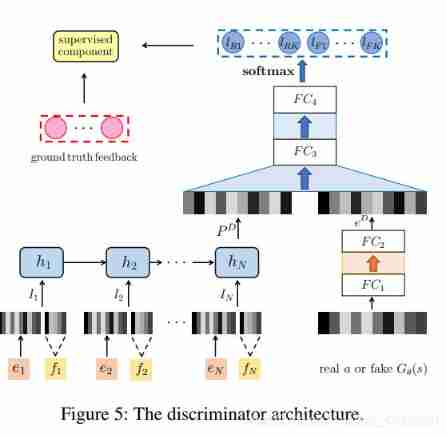
- chart 5 It explains the architecture of the discriminator . Similar to generator , We have introduced with GRU Of RNN To capture users' dynamic preferences . Please note that , Its architecture is similar to that in the generator RNN identical , But they have different parameters . RNN The input of is the state observed in the historical log s = { i 1 , . . . , i N } s= \{ i_1,...,i_N \} s={ i1,...,iN}, among i n = ( e n , f n ) i_n=(e_n,f_n) in=(en,fn), Output is a dense representation of users' current preferences (dense representation), abbreviation p D p^D pD . meanwhile , We will recommend the project ( really a a a Or false G θ ( s ) G_{\theta}(s) Gθ(s)) Project embedded (item-embedding) Feed into the full connection layer , Code the recommended item as a low dimensional representation , be called e D e^D eD. Then we connect p D p^D pD and e D e^D eD, And connect ( p D , e D ) (p^D,e^D) (pD,eD) Feed into the full connection layer , The goal is
(1) Judge the authenticity of recommended products , as well as
(2) Predict user feedback on these items . therefore , The final full connection layer outputs a 2 × K 2 \times K 2×K Dimensional logits vector , Represent the K K K Like real feedback and K K K Pseudo feedback :
- We include in the output layer K K K Pseudo feedback , Not just a fake class , Because fine-grained discrimination of false samples can increase the ability of the discriminator ( More details are in the following sections ). these logits Through a softmax Layer into class probability , The first j j j The corresponding probability of each class is :
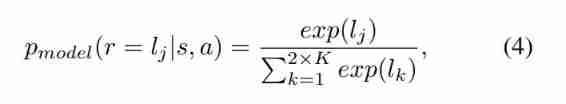
- among r r r Is the result of classification . The objective function is based on these class probabilities . Besides , A monitoring component is introduced to enhance users' feedback prediction , More details about this component will be found in 3 Section discusses .
Objective function
- In this section , We will introduce the objective function of the proposed simulator . The discriminator has two goals :
- (1) Distinguish between real-world historical logs and generated logs , as well as
- (2) According to the browsing history, predict the user's feedback category of recommended items .
- The first goal corresponds to an unsupervised problem , Like the standard GAN Distinguish between true and false images , And the second goal is a supervision problem , Minimize the category difference between users' real feedback and predictive feedback . therefore , The loss function of the discriminator L D L_D LD It's made up of two parts .
- For the unsupervised component that distinguishes between real-world historical logs and generated logs , We need to calculate the status - Probability of whether the action pair is true or false . From equation (4), We know the state observed from the historical log - The probability that action pairs are classified as real , be called D ϕ ( s , a ) D_{\phi}(s, a) Dϕ(s,a), yes K K K The sum of the probabilities of true feedback :
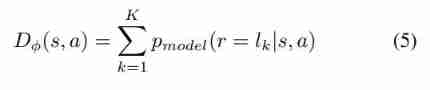
- And the generator produces G θ ( s ) G_{\theta}(s) Gθ(s) The false state of action - Probability of action pair , be called D ϕ ( s , G θ ( s ) ) D_{\phi}(s, G_{\theta}(s)) Dϕ(s,Gθ(s)), yes K K K The sum of the false feedback probabilities :

- that , Loss function L D L^D LD The unsupervised component of is defined as follows :
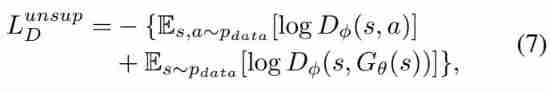
- among s s s and a a a From the historical log distribution of the first item p d a t a p_{data} pdata In the sample ; In the second item , Only s s s From the historical log distribution p d a t a p_{data} pdata In the sample , And action G θ ( s ) G_{\theta}(s) Gθ(s) By generator policy G θ G_{\theta} Gθ produce .
- The monitoring component is designed to predict the categories of user feedback , Express it as a supervision problem , To minimize the category difference between users' real feedback and predictive feedback ( That's cross entropy loss ). So it also has two items :
- The first is the distribution from real historical data p d a t a p_{data} pdata The real state of the sample in - Cross entropy loss of real state class and prediction class of action pairs ;
- The second item is the cross entropy loss of the real category and the predicted category of the false state action pair , The action is generated by the generator .
- therefore , Loss function L D L_D LD The monitoring component of is defined as follows :

- among λ Control the contribution of the second . The first is the standard cross entropy loss of the supervision problem . We introduce the equation (8) The reason for the second item is —— In order to solve the problem 1 Data limitation challenges mentioned in section , We will be in a false state - The action is regarded as the real state - Enhancement of action pair , Then fine-grained discrimination is made for the false state action pairs to increase the ability of the discriminator , This in turn forces the generator to output more indistinguishable actions . Discriminator L D L^D LD The global loss function of is defined as follows :
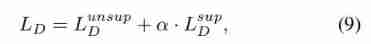
- Among them, the introduction of parameters α \alpha α To control the contribution of the oversight component .
- The goal of the generator is to output realistic recommendations that can deceive the discriminator G θ ( s ) G_{\theta}(s) Gθ(s) , It solves the problem of 1 The complex data distribution problem mentioned in section . To achieve this goal , We are the loss function of the generator L G L_G LG Two components are designed . The first component aims to maximize the equation (7) About China G θ G_{\theta} Gθ Of L D u n s u p {L_D}^{unsup} LDunsup. let me put it another way , The first component minimizes false States - Probability that action pairs are classified as false , So we have :

- among s s s From the real historical log distribution p d a t a p_{data} pdata In the sample , action G θ ( s ) G_{\theta}(s) Gθ(s) By generator policy G θ G_{\theta} Gθ produce . suffer GAN Monitor version (Luc et al.2016) Inspired by the , We introduced supervision loss L G s u p {L_G}^{sup} LGsup As L G L_G LG The second component of , That is, the ground live project a a a And build projects G θ ( s ) G_{\theta}(s) Gθ(s) Between l 2 l_2 l2 distance :

- among s s s and a a a It is distributed from the historical log p d a t a p_{data} pdata Sampling in . This supervised component encourages the generator to produce projects that are close to real projects . Discriminator L D L_D LD The overall loss function of is defined as
as follows :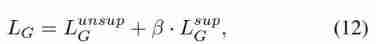
- among β Control the contribution of the second component .

- We introduce our simulator training algorithm in detail , Such as algorithm 1 Shown . At the beginning of the training phase , We use standard supervision methods to pre train the generator ( The first 3 That's ok ) Discriminator ( The first 5 That's ok ). After the pre training phase , Alternate training discriminator ( The first 7-11 That's ok ) And generators ( The first 12-15 That's ok ). To train the discriminator , state s s s And real action a a a Sample from the real history log , And fake action G θ ( s ) G_{\theta}(s) Gθ(s) It is generated by generator . For every d d d Keep balance in the step , We use the same number of real actions a a a Generate fake actions G θ ( s ) G_{\theta}(s) Gθ(s).
experiment
- In this section , We did a lot of experiments , To evaluate the effectiveness of the proposed simulator using real data sets from e-commerce websites . We mainly focus on two issues :
- (1) And the state-of-the-art baseline for predicting user behavior ( Discriminator ) comparison , How about the performance of the proposed simulator ; and
- (2) Compared with the representative Recommendation Algorithm , How does the generator perform . Let's first introduce the experimental setup . Then we seek the answers to the above two questions . Last , We study the influence of important parameters on the performance of the proposed framework .
Experimental setup
- We are 2018 year 7 Our method was evaluated on a data set from a real e-commerce company in August . We randomly collected 272,250 Recommended conversations , Each session is a series of projects - Feedback is right . Filter out occurrences less than 5 After the second project , be left over 1,355,255 A project . For each session , Before we use N N N Projects and corresponding feedback as the initial state , The first N + 1 N + 1 N+1 Items as the first action , Then we can follow paragraph 1 As defined in section MDP Collect a series of ( state , action , Reward ) Tuples . We collect the last from all the conversations ( state 、 action 、 Reward ) Tuples as test sets , At the same time, other tuples are used as the training set .
- In this paper , We use what users browse N = 20 N = 20 N=20 Items and the corresponding feedback of users on each item as status s s s. Users embed (item-embedding) e n e_n en The dimension of is ∣ E ∣ = 20 |E| = 20 ∣E∣=20, Action representation F n F_n Fn The dimension of is ∣ F ∣ = 10 |F| = 10 ∣F∣=10( f n f_n fn It's a two-dimensional one-hot vector : When the feedback is negative f n = [ 1 , 0 ] f_n = [1, 0] fn=[1,0], When the feedback is positive f n = [ 0 , 1 ] f_n = [0, 1] fn=[0,1]). discriminator The output of is a 4 ( K = 2 ) 4 (K = 2) 4(K=2) Dimensional logits vector , Every logit Represent the r e a l − p o s i t i v e real-positive real−positive, r e a l − n e g a t i v e real-negative real−negative, f a k e − p o s i t i v e fake-positive fake−positive and f a k e − n e g a t i v e fake-negative fake−negative:

- among r e a l real real Indicates that the recommended items are observed from the historical log ; f a k e fake fake Indicates that the recommended item is generated by the generator ; p o s i t i v e positive positive Indicates that the user clicks / Bought recommended products ; n e g a t i v e negative negative Indicates that the user skipped the recommended item . Please note that , Although we only simulated two types of user behavior ( Positive and negative ), But you can extend the simulator directly with more types of behavior . AdamOptimizer Apply to optimization ,Generator and Discriminator The learning rate of 0.001,batch-size by 500.RNN The hidden size of is 128. For the parameters of the proposed framework , Such as α \alpha α, β \beta β and $\gamma$, We chose them to pass cross validation . Accordingly , We also adjusted the parameters of the baseline to make a fair comparison . We will discuss more details about the parameter selection of the proposed simulator in the following sections .
- In the test phase , Given a state - The action is right , The simulator will predict the type of user feedback on the action ( Recommended projects ), Then compare the prediction with the real feedback observed from the historical log . For this classification task , We choose the common F 1 − s c o r e F1-score F1−score As a measure , It is a measure that combines precision and recall , That is, the harmonic average of accuracy and recall . Besides , We make use of p m o d e l ( r = l r p ∣ s , a ) p_{model}(r = l_{rp}|s, a) pmodel(r=lrp∣s,a)( That is, the probability of users providing positive feedback on real recommended items ) As a score , And use A U C AUC AUC(ROC The area under the curve ) Evaluate performance as a measure .
Overall performance comparison
- To answer the first question , We will propose the simulator ( Discriminator ) Compare with the following most advanced baseline methods :
- Random: This baseline Give each recommendation randomly item Allocate one score ∈ [0, 1], And use 0.5 As a threshold to item It is divided into positive and negative ; This score is also used to calculate AUC.
- LR: Logical regression ( Logistic Regression) Use logical functions by minimizing losses E 1 2 ( h θ ( x ) − y ) 2 E_{\frac{1}{2}}{(h_{\theta}(x) − y)}^2 E21(hθ(x)−y)2 To model binary dependent variables , among h θ ( x ) = 1 1 + e − w T x h_{\theta}(x) =\frac{1}{ {1+e^{-w^{T}x}}} hθ(x)=1+e−wTx1; We will i n = ( e n , f n ) i_n = (e_n, f_n) in=(en,fn) For the first time i i i Eigenvectors of items , If the feedback is positive , Then set the basic facts y = 1 y = 1 y=1, otherwise y = 0 y = 0 y=0.
- GRU: This baseline uses GRU Of RNN To predict the type of user feedback on recommended items . Input of each unit i n = ( e n , f n ) i_n = (e_n, f_n) in=(en,fn) in ,RNN The output of is a representation of user preferences , for instance u u u, Then we will u u u Connect with the embedding of recommended items , And use a s o f t m a x softmax softmax Layer to predict user feedback categories for this project .
- GAN: This baseline is based on generating countermeasure Networks (Goodfellow et al. 2014), The generator adopts the state - The action is right ( Browse history and recommended items ) And output the user's feedback on the project ( Reward ), The discriminator adopts ( state , action , Reward ) Tuples and distinguish between real tuples ( The reward is observed from the historical log ) And pseudo tuples . Please note that , We also use with GRU Of RNN To capture users' order preferences .
- GAN-s: This baseline is GAN Supervised version of (Luc et al. 2016), The setting is the same as the above GAN The baseline is similar , At the same time, a monitoring component is added to the output of the generator , Thus, the difference between real feedback and predictive feedback is minimized .
- The result is shown in Fig. 6 Shown . We made the following observations :

- LR Performance ratio of GRU Bad , because LR Time series in user browsing history are ignored , and GRU It can capture the time pattern in the project sequence and the user's feedback on each project . The result shows that , When learning users' dynamic preferences , It is important to capture the sequential pattern of users' browsing history .
- GAN-s Better performance than GRU and GAN, because GAN-s Not only benefit from GAN frame ( Unsupervised components ) The advantages of , And benefit from the advantages of monitoring components , Directly minimize the cross entropy between real feedback and predictive feedback .
- RecSimu be better than GAN-s, Because the generator imitates the recommended strategy of generating historical logs , The generated log can be regarded as an extension of the real log , Solved the challenge of data limitations ; The discriminator can distinguish between real logs and generated logs ( Unsupervised components ), At the same time, predict users' feedback on recommended items ( Monitor components ). let me put it another way ,RecSimu Both unsupervised and supervised components are utilized . RecSimu The contribution of model components will be studied in the following sections .
- To make a long story short , The proposed framework is superior to the most advanced baseline , This verifies its effectiveness in simulating users' behavior in recommendation tasks .
Generator efficiency
- The generator we proposed is designed according to the browsing history of users ( state ) Generate indistinguishable logs ( action ). let me put it another way , It mimics the recommendation strategy of the recommendation system that generates historical logs . To answer the second question , We have trained several representative recommendation algorithms based on the historical log used in this paper , And compare the performance difference with historical log . To evaluate the performance of the recommended algorithm , We choose MAP and NDCG As an indicator . We will compare the proposed generator with the generator of the following representative recommended methods :
- FM: Factorization Machines (Rendle 2010) Combined with the SVM And the advantages of decomposition model . Compared with matrix decomposition , You can use dimension parameters to model high-order interactions .
- W&D: The baseline is an extensive and in-depth model , It is used for joint training of linear model with embedded feedforward neural network and feature transformation of general recommendation system .
- GRU4Rec:GRU4Rec Use a GRU The unit's RNN According to the click / Subscription history forecast users will next click / Order what .
- Results such as table 1 Shown . Compared to the baseline , Can be observed RecSimu The generator of can achieve the most similar performance to the historical log . This result verifies that the competition between generator and discriminator can enhance the ability of generator to capture complex project distribution in historical log , Exceed the supervised Recommendation Algorithm .

Composition analysis
- To study how components in generators and discriminators contribute to performance , We define RecSimu To systematically eliminate the corresponding components of the simulator :
- RecSimu-1: This variant is a simplified version of the simulator , Except that the output of the discriminator is a 3 Dimension vector o u t p u t = [ l r p , l r n , l f ] output = [l_{rp}, l_{rn}, l_f ] output=[lrp,lrn,lf], Each of them logit Represent the r e a l − p o s i t i v e real-positive real−positive, r e a l − n e g a t i v e real-negative real−negative and f a k e fake fake, That is, it will not distinguish the generated positive and negative terms .
- RecSimu-2: In this variant , We evaluate oversight components L G s u p {L_G}^{sup} LGsup The contribution of , So we set β = 0 \beta = 0 β=0 To eliminate L G s u p {L_G}^{sup} LGsup Influence .
- RecSimu-3: This variant is to evaluate the effectiveness of the competition between the generator and the discriminator , therefore , We removed from the loss function L G u n s u p {L_G}^{unsup} LGunsup and L D u n s u p {L_D}^{unsup} LDunsup.
- The result is shown in Fig. 7 Shown . Can be observed :
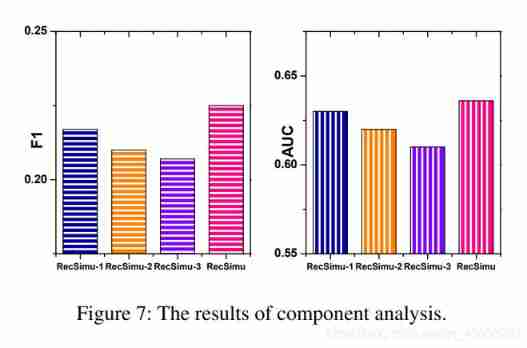
- RecSimu Better performance than RecSimu-1, This shows that distinguishing the generated positive and negative terms can improve performance . This also verifies that the data generated by the generator can be regarded as an enhancement of real-world data , This solves the data limitation challenge .
- RecSimu-2 Performance ratio of RecSimu Bad , This shows that the supervision component helps the generator generate more indistinguishable projects .
- RecSimu-3 First train a generator , Then use real data and generated data to train the discriminator ; and RecSimu Iterative update generator and discriminator . RecSimu be better than RecSimu-3, This shows that the competition between the generator and the discriminator can enhance the generator ( Capture complex data distribution ) Discriminator ( Classify true and false samples ) The ability of .
Parameter sensitivity analysis
- Our method has two key parameters , namely
- (1) N N N Control the length of the state , and
- (2) λ \lambda λ Control formula (8) The second contribution in , It divides the generated projects into positive or negative classes .
- In order to study the influence of these parameters , We studied the proposed framework RecSimu How to work under the change of a parameter , Fix other parameters at the same time . The result is shown in Fig. 8 Shown . We have the following observations :
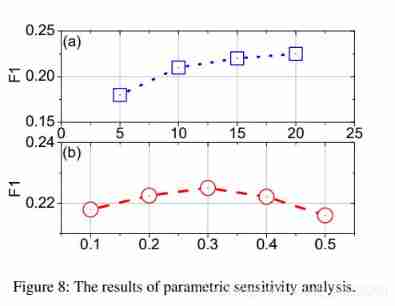
- chart 8 (a) It shows N N N Parameter sensitivity . We found that with N N N An increase in , Improved performance . say concretely , The performance is significantly improved first , Then it becomes relatively stable . This result shows that introducing a longer browsing history can improve performance .
- chart 8 (b) Shows λ \lambda λ Sensitivity . When λ = 0.3 \lambda= 0.3 λ=0.3 when , The performance of the simulator reaches its peak . let me put it another way , equation (8) The second item in does improve the performance of the simulator ; However , Performance depends mainly on the equation (8) First of all , It divides real projects into positive and negative categories .
Related work
- In this section , We briefly review the work related to our research . generally speaking , Related work can be divided into the following categories .
- The third kind related to this paper is the recommendation system based on reinforcement learning , It usually regards the recommendation task as a Markov decision process (MDP), The recommendation process is modeled as the sequential interaction between users and the recommendation system (Zhao et al. 2019b; Zhao et al. 2018a. Practical recommendation systems always have millions of projects ( Discrete action ) To recommend (Zhao et al. 2016;Guo et al. 2016). therefore , Most are based on RL Our model will become inefficient , Because they cannot handle such a large discrete action space . The depth deterministic strategy gradient is introduced (DDPG) Algorithm to alleviate based on reality RL The big action space problem in the recommendation system of (Dulac-Arnold wait forsomeone ,2015 year ). for fear of DDPG And improve recommended performance , stay (Chen et al. 2018a) The strategy gradient of tree structure is proposed in . Double clustering technology is also introduced to model the recommendation system as a grid world game , To reduce the state / Action space (Choi wait forsomeone ,2018 year ). In order to solve the unstable reward allocation problem in the dynamic recommendation environment , Proposed the approximate regret reward technology and double DQN, To obtain a reference baseline from a single customer sample (Chen et al. 2018c). Positive and negative feedback from users , That is to buy / Click and skip behavior , Consider together in a framework to promote recommendations , Because both types of feedback can represent part of user preferences (Zhao et al. 2018c). Introduced improvements in architecture and formula , In the unified RL Capture positive feedback and negative feedback in the framework . A page by page recommendation framework is proposed to jointly recommend a project page and display them in a two-dimensional page (Zhao et al. 2017; Zhao et al. 2018b). introduce CNN Technology to capture the item display mode and user feedback of each item in the page . For the whole chain recommendation (Zhao et al. 2019c) A reinforcement learning framework based on multi-agent model is proposed (DeepChain), The framework can train multiple recommendation agents in different scenarios through model-based optimization algorithm . For based on RL The recommendation system of (Zhao et al. 2019a) Based on the generation of confrontation network (GAN) User simulator of the framework RecSimu, The system models the behavior of real users according to their historical logs , And solved two challenges :(i) The distribution of recommended items in users' historical logs is very complex , also (ii) The tag training data from each user is limited . In the news push scene , Based on DQN To meet the challenges of traditional models , namely (1) Only for current rewards ( Such as click through rate ) Modeling ,(2) Don't consider clicking / Skip labels , as well as (3) Provide similar news to users (Zheng wait forsomeone ,2018 year ). (Wang et al. 2018) A reinforcement learning framework with interpretable recommendation is proposed , Can explain any recommended model , And the interpretation quality can be flexibly controlled according to the application scenario . (Chen et al. 2018b) by YouTube A strategy gradient based top-K Recommendation system , It combines learning log strategies with novel top-K Deviation strategy correction to solve the deviation in the recorded data . Other applications include seller impression distribution (Cai et al. 2018a)、 Fraud detection (Cai et al. 2018b) And user status representation (Liu et al. 2018).
- The second kind related to this article is behavioral cloning . One of the most effective ways is to learn from demonstrations (LfD), It estimates the implicit reward function from the expert's behavior state to the action mapping . The success of LfD Applications include autonomous helicopter maneuvers (Ross et al. 2013)、 Autopilot (Bojarski et al. 2016)、 play table tennis (Calinon et al. 2010)、 Object manipulation (Pastor et al. 2009) And making coffee (Sung、Jin and Saxena 2018 year ). for example , Ross et al . (Ross wait forsomeone ,2013 year ) A method of automatically piloting small helicopters at low altitude in natural forest environment has been developed . Bojaski et al . (Bojarski et al. 2016) Training CNN Map the original pixels of a single front camera directly to the steering command . Calinon wait forsomeone . (Calinon et al. 2010) A probabilistic method is proposed , Train a robust human motion model by imitating, for example, playing table tennis . Priest, etc . (Pastor et al. 2009) This paper presents a general method of learning robot motor skills from human demonstrations . Song et al . (Sung,Jin and Saxena 2018) According to the assumption that many household products share similar operating components , An operation planning method is proposed .
Conclusion
- In this paper , We propose a generation based countermeasure network (GAN) New user simulator of framework RecSimu, It models the behavior of real users according to their historical logs , And solved two challenges :
- (i) The distribution of recommended items in users' historical logs is very complex , as well as
- (ii) The tag training data from each user is limited .
- be based on GAN The user simulator of can naturally solve these two challenges , It can also be used to pre train and evaluate the new recommendation algorithm before it goes online . say concretely , The generator captures the underlined item distribution of the user history log , And generate indistinguishable false logs , As an extension of the real log ; The discriminator can predict the user's feedback on the recommended items according to the user's browsing log , This utilizes supervised and unsupervised learning techniques . In order to verify the effectiveness of the proposed user simulator , We have conducted extensive experiments based on real-world e-commerce data sets . It turns out that , The proposed user simulator can improve the performance of user behavior prediction in recommendation tasks , And has a significant margin over the representative baseline .
- There are several interesting research directions . First , In order to generalize , In this paper , We don't consider the dependency between continuous actions , let me put it another way , We split a recommendation session into several independent States - The action is right . Some recent imitation learning techniques , For example, reverse reinforcement learning and generative antagonistic imitation learning , Put a series of States - The action is regarded as a complete track , And the prior action may affect the posterior action . We will introduce this idea in a future work . secondly , Positive in user history ( Click on / Buy ) And negative ( skip ) Feedback is extremely unbalanced , This makes it more difficult to collect enough positive feedback data . In this paper , We use the traditional up sampling technique to generate more positive feedback training data . future , We will consider using GAN The framework automatically generates more positive feedback data . Last , There are many reasons why users skip projects , for example (1) Users really don't like this project ,(2) The user didn't look at the item carefully and skipped it by mistake ,(3) There is a better location near the project . These reasons make it more difficult to predict jumping behavior . therefore , We will introduce interpretable recommendation techniques to determine why users skip projects .
边栏推荐
猜你喜欢
Tapdata 的 2.0 版 ,开源的 Live Data Platform 现已发布
PB9.0 insert OLE control error repair tool
![[target tracking] |atom](/img/33/529b483a0a848e0e4263ba24462d5c.png)
[target tracking] |atom
pb9.0 insert ole control 错误的修复工具

Js中forEach map无法跳出循环问题以及forEach会不会修改原数组
The foreach map in JS cannot jump out of the loop problem and whether foreach will modify the original array
谈谈 SAP 系统的权限管控和事务记录功能的实现

How to make enterprise recruitment QR code?
nmap工具介绍及常用命令

给刚入门或者准备转行网络工程师的朋友一些建议
随机推荐
[SolidWorks] modify the drawing format
Why did MySQL query not go to the index? This article will give you a comprehensive analysis
Clickhouse principle analysis and application practice "reading notes (8)
The numerical value of the number of figures thought of by the real-time update of the ranking list
QT -- create QT program
Introduction to Microsoft ad super Foundation
Optimization of ecological | Lake Warehouse Integration: gbase 8A MPP + xeos
Remote Sensing投稿經驗分享
What kind of MES system is a good system
Redission源码解析
Flutter 3.0框架下的小程序运行
Can you write the software test questions?
为什么更新了 DNS 记录不生效?
The circuit is shown in the figure, r1=2k Ω, r2=2k Ω, r3=4k Ω, rf=4k Ω. Find the expression of the relationship between output and input.
ANSI / NEMA- MW- 1000-2020 磁铁线标准。. 最新原版
DataWorks值班表
PHP calculates personal income tax
云原生应用开发之 gRPC 入门
In depth analysis of ArrayList source code, from the most basic capacity expansion principle, to the magic iterator and fast fail mechanism, you have everything you want!!!
VIM use