当前位置:网站首页>Clickhouse principle analysis and application practice "reading notes (8)
Clickhouse principle analysis and application practice "reading notes (8)
2022-07-08 01:56:00 【Aiky WOW】
Begin to learn 《ClickHouse Principle analysis and application practice 》, Write a blog and take reading notes .
The whole content of this article comes from the content of the book , Personal refining .

The first 10 Chapter :
The first 11 Chapter Management and operation and maintenance
11.1 User configuration
user.xml The default location of the configuration file is /etc/clickhouse-server Under the path .
Define user related configuration items , Including the setting of system parameters 、 User definition 、 Authority and circuit breaker mechanism .
【 The parameters of this part can be changed at the session level .】
11.1.1 user profile
The function is similar to user role , Multiple groups , Predefined in user.xml in .
<yandex>
<profiles><!-- To configure profile -->
<default> <!-- Custom name , Default character -->
<max_memory_usage>10000000000</max_memory_usage>
<use_uncompressed_cache>0</use_uncompressed_cache>
</default>
<test1> <!-- Custom name , Default character -->
<allow_experimental_live_view>1</allow_experimental_live_view>
<distributed_product_mode>allow</distributed_product_mode>
</test1>
</profiles>
……
Can be in CLI Switch directly to the desired profile:
SET profile = test1
The name is default Of profile Is the default configuration , There has to be , No report error .
profile Reference other in the definition profile Name can be inherited .
<normal_inherit> <!-- Only read Query authority -->
<profile>test1</profile>
<profile>test2</profile>
<distributed_product_mode>deny</distributed_product_mode>
</normal_inherit>The new parameter value will overwrite the original parameter value .
11.1.2 Configuration constraints
constraints Tags can set a set of constraints .
- Min: Minimum constraint , When setting the corresponding parameters , The value cannot be less than the threshold value .
- Max: Maximum constraint , When setting the corresponding parameters , The value cannot be greater than the threshold value .
- Readonly: Read only constraints , The parameter value cannot be modified .
<profiles><!-- To configure profiles -->
<default> <!-- Custom name , Default character -->
<max_memory_usage>10000000000</max_memory_usage>
<distributed_product_mode>allow</distributed_product_mode>
<constraints><!-- Configuration constraints -->
<max_memory_usage>
<min>5000000000</min>
<max>20000000000</max>
</max_memory_usage>
<distributed_product_mode>
<readonly/>
</distributed_product_mode>
</constraints>
</default>In the example, constraints are set for two sets of parameters .
At this time to use set An error will be reported when modifying the parameter value .
stay default Defined by default in constraints constraint , As the default global constraint , Automatically by other profile Inherit .
11.1.3 User defined
Define a new user , The following attributes must be included .
1.username
Specify login user name , Globally unique attribute .
2.password
The login password .
(1) Plaintext password
<password>123</password>
Password free login :
<password></password>
(2)SHA256 encryption
<password_sha256_hex>a665a45920422f9d417e4867efdc4fb8a04a1f3fff1fa07e998e86f7f7a27ae3</password_sha256_hex>
Yes, the password 123 encryption :
# echo -n 123 | openssl dgst -sha256
(stdin)= a665a45920422f9d417e4867efdc4fb8a04a1f3fff1fa07e998e86f7f7a27ae3
(3)double_sha1 encryption
<password_double_sha1_hex>23ae809ddacaf96af0fd78ed04b6a265e05aa257</password_double_sha1_hex>
Yes, the password 123 encryption :
# echo -n 123 | openssl dgst -sha1 -binary | openssl dgst -sha1
(stdin)= 23ae809ddacaf96af0fd78ed04b6a265e05aa257
3. networks
The network address allowed to log in , Client address used to restrict user login , The introduction of this aspect will be in 11.2 Section unfolding .
4.profile
Directly reference the corresponding name
<default>
<profile>default</profile>
</default>5.quota
A circuit breaker mechanism . Will be in 11.3 Section unfolding .
11.2 Rights management
11.2.1 Access right
1. Network access
Network access permission use networks Label settings , The client address used to restrict the login of a user .
After setting , The user will only be able to log in from the specified address .
(1)IP Address : Use it directly IP Address setting .
<ip>127.0.0.1</ip>
(2)host Host name : adopt host Host name setting .
<host>ch5.nauu.com</host>
(3) Regular matching : Match by expression host name
<host>^ch\d.nauu.com$</host>
give an example :
<user_normal>
<password></password>
<networks>
<ip>10.37.129.13</ip>
</networks>
<profile>default</profile>
<quota>default</quota>
</user_normal>
2. Database and dictionary access
adopt allow_databases and allow_dictionaries Label to set .
If there is no definition , Means no restriction .
After logging in , You will only see the databases and dictionaries for which access is open .
<user_normal>
……
<allow_databases>
<database>default</database>
<database>test_dictionaries</database>
</allow_databases>
<allow_dictionaries>
<dictionary>test_flat_dict</dictionary>
</allow_dictionaries>
</user_normal>
11.2.2 Query authority
The second layer of protection of the entire authority system .
Query permissions can be divided into the following four categories :
- Read permission : Include SELECT、EXISTS、SHOW and DESCRIBE Inquire about .
- Write permissions : Include INSERT and OPTIMIZE Inquire about .
- Set the permissions : Include SET Inquire about .
- DDL jurisdiction : Include CREATE、DROP、ALTER、RENAME、ATTACH、 DETACH and TRUNCATE Inquire about .
- Other permissions : Include KILL and USE Inquire about , Any user can execute these queries .
Configure label control through the following two items :
- readonly: Read permission 、 Write permission and set permission are controlled by this tag , It has three values .
- The value is 0 when , No restrictions ( The default value is ).
- The value is 1 when , Only have read access ( It can only be carried out SELECT、EXISTS、SHOW and DESCRIBE).
- The value is 2 when , Have read permission and set permission ( On the basis of read permission , increase 了 SET Inquire about ).
- allow_ddl:DDL Permissions are controlled by this tag , It has two values .
- The value is 0 when , Don't allow DDL Inquire about .
- The value is 1 when , allow DDL Inquire about ( The default value is ).
<profiles>
<normal> <!-- Only read Read permission -->
<readonly>1</readonly>
<allow_ddl>0</allow_ddl>
</normal>
<normal_1> <!-- Have the permission to read and set parameters -->
<readonly>2</readonly>
<allow_ddl>0</allow_ddl>
</normal_1>Assign the role to the user .
11.2.3 Data row level permissions
The third layer of protection in the authority system , Determines what data a user can see .
Data permission use databases Tag definition .
<databases>
<database_name><!-- Database name -->
<table_name><!-- The name of the table -->
<filter> id < 10</filter><!-- Data filtering conditions -->
</table_name>
</database_name>give an example :
<user_normal>
……
<databases>
<default><!-- Default database -->
<test_row_level><!— The name of the table -->
<filter>id < 10</filter>
</test_row_level>
<!— Support combination conditions
<test_query_all>
<filter>id <= 100 or repo >= 100</filter>
</test_query_all> -->
</default>
</databases>How to set data permissions ? Analyze its execution log :
Expression
Expression
Filter – Added filtering steps
MergeTreeThread
You can find , The above code is automatically attached to the ordinary query plan Filter Filtering steps .
After using this function ,PREWHERE Optimization will no longer take effect .
11.3 Circuit breakers
When the number of resources used reaches the threshold , Then the ongoing operation will be automatically interrupted .
Circuit breaker mechanisms can be divided into two categories .
1. Fuse according to the accumulated amount of time period
In this way , The consumption of system resources is accumulated and counted according to the time cycle .
This way through users.xml Internal quotas Tag to define resource quotas .
<quotas>
<default> <!-- Custom name -->
<interval>
<duration>3600</duration><!-- cycle time Company : second -->
<queries>0</queries>
<errors>0</errors>
<result_rows>0</result_rows>
<read_rows>0</read_rows>
<execution_time>0</execution_time>
</interval>
</default>
</quotas>- default: Represents a custom name , Globally unique .
- duration: Represents the cumulative time period , The unit is seconds .
- queries: Indicates the number of queries allowed to be executed in the cycle ,0 Means unrestricted .
- errors: Indicates the number of exceptions allowed in the cycle ,0 Means unrestricted .
- result_row: Indicates the number of result rows allowed to be returned by the query in the cycle ,0 Means unrestricted .
- read_rows: Indicates in the distributed query within the cycle , The number of data rows that the remote node is allowed to read ,0 Means unrestricted .
- execution_time: Indicates the query time allowed to be executed in the cycle , The unit is seconds ,0 Means unrestricted .
Add the quota to the user .<quota> name <quota>
2. Fuse according to the consumption of a single query
In this way , The consumption of system resources is calculated according to a single query , And the specific circuit breaker rules , It is composed of many different configuration items , These configuration items need to be defined in the user profile in . such as max_memory_usage.
【 There are too few parameters in this part of the parameter book , You can refer to the official website directly .Restrictions on Query Complexity | ClickHouse Docs】
11.4 The data backup
11.4.1 Export file backup
# adopt dump Export the data as a local file in the form of .
#clickhouse-client --query="SELECT * FROM test_backup" > /chbase/test_backup.tsv
# Import the backup data again
# cat /chbase/test_backup.tsv | clickhouse-client --query "INSERT INTO test_backup FORMAT TSV"
# You can also directly copy its entire directory file
# mkdir -p /chbase/backup/default/ & cp -r /chbase/data/default/test_backup /chbase/backup/default/11.4.2 Backup through snapshot table
Snapshot tables are essentially ordinary data tables , For example, create by day or week .
-- First, you need to create a data table with the same structure as the original table .
CREATE TABLE test_backup_0206 AS test_backup
-- The backup data
INSERT INTO TABLE test_backup_0206 SELECT * FROM test_backup
-- Considering the problem of disaster recovery , Put the above SQL Statement changes the form of remote query :
INSERT INTO TABLE test_backup_0206 SELECT * FROM remote('ch5.nauu.com:9000', 'default', 'test_backup', 'default')11.4.3 Backup by partition
ClickHouse Currently provided FREEZE And FETCH Two ways ,
1. Use FREEZE Backup
ALTER TABLE tb_name FREEZE PARTITION partition_exprAfter the partition is backed up , Will be uniformly saved to ClickHouse The root path /shadow/N subdirectory . among ,N Is a self increasing integer , It means the number of backups (FREEZE How many times ), The specific frequency is determined by shadow Under subdirectories increment.txt File record .
Partition backup is essentially a hard link operation on the original directory file , Therefore, it will not lead to additional storage space . The entire backup directory will be traced up to data The entire link of the root path :
/data/[database]/[table]/[partition_folder]Execute the following statement, for example , The data sheet partition_v2 Of 201908 Partition for backup :
ALTER TABLE partition_v2 FREEZE PARTITION 201908Get into shadow subdirectories , That is, you can see the partition directory you just backed up :
# pwd
/chbase/data/shadow/1/data/default/partition_v2
# ll
total 4
drwxr-x---. 2 clickhouse clickhouse 4096 Sep 1 00:22 201908_5_5_0Restore the backup partition , You need to use ATTACH Loading partitions . This means that if you want to restore data , First of all, we need to take the initiative to shadow Copy the partition file under the subdirectory to phase Should be in the data sheet detached Under the table of contents , And then use ATTACH Statement loading .
2. Use FETCH Backup
FETCH Only support ReplicatedMergeTree Series of table engines .
ALTER TABLE tb_name FETCH PARTITION partition_id FROM zk_path
How it works and ReplicatedMergeTree The principle of synchronizing data is similar .
Find the most suitable copy , Download the partition data and save it to the corresponding data table detached Under the table of contents .
And FREEZE equally , Restore the backup partition , It also needs the help of ATTACH Load partitions to achieve .
FREEZE and FETCH Although it can realize the backup of partition files , But they do not back up the metadata of the data table . So if you want to make a foolproof backup , You also need to back up the metadata of the data table , They are /data/metadata In the catalog [table].sql file . At present, these metadata need to be backed up separately by users in the form of replication .
11.5 Service monitoring
11.5.1 The system tables
There are mainly three system tables :metrics、events and asynchronous_metrics.
1.metrics
Used for statistics ClickHouse The service is running , High level profile currently being implemented , Including the total number of queries being executed 、 Total number of merging operations in progress, etc .
2.events
events Used for statistics ClickHouse The high-level cumulative profile that the service has executed during operation , Including the total number of queries 、 The total SELECT Query times, etc .
3.asynchronous_metrics
asynchronous_metrics Used for statistics ClickHouse When the service is running , High level profile currently running asynchronously in the background , Include the currently allocated memory 、 Number of tasks in the execution queue .
11.5.2 Query log
At present, there are mainly 6 Types
1.query_log
Recorded ClickHouse All query records that have been executed in the service .
<query_log>
<database>system</database>
<table>query_log</table>
<partition_by>toYYYYMM(event_date)</partition_by>
<!— Refresh cycle -->
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_log>query_log After opening , That is, the records can be queried through the corresponding system table :
SELECT type,concat(substr(query,1,20),'...')query,read_rows,
query_duration_ms AS duration FROM system.query_log LIMIT 6
query_log The information recorded in the log is perfect , It covers query statements 、 execution time 、 The amount of data returned by the execution user and the execution user .
2.query_thread_log
Records the information of all threads executing queries .
<query_thread_log>
<database>system</database>
<table>query_thread_log</table>
<partition_by>toYYYYMM(event_date)</partition_by>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_thread_log>query_thread_log The logged information covers the thread name 、 Query statement 、 Execution time and memory usage .
3.part_log
Recorded MergeTree Partition operation log of series table engine .
<part_log>
<database>system</database>
<table>part_log</table>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</part_log>part_log The logged information covers the type of manipulation 、 The name of the table 、 Partition information and execution time .
4.text_log
Recorded ClickHouse A series of print logs generated during operation , Include INFO、DEBUG and Trace.
<text_log>
<database>system</database>
<table>text_log</table>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</text_log>
text_log The logged information covers the thread name 、 Log object 、 Log information and execution time .
5.metric_log
metric_log Logs are used to put system.metrics and system.events The data in comes together .
<metric_log>
<database>system</database>
<table>metric_log</table>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
<collect_interval_milliseconds>1000</collect_interval_milliseconds>
</metric_log>collect_interval_milliseconds Represents a collection metrics and events Time period of data .
metric_log After opening , That is, the records can be queried through the corresponding system table .
11.6 Summary of this chapter
This paper introduces the method of defining users and setting permissions .
This paper introduces how to protect through the circuit breaker mechanism ClickHouse System resources will not be overused .
The monitoring items of daily operation are introduced .
边栏推荐
- 滑环使用如何固定
- The foreach map in JS cannot jump out of the loop problem and whether foreach will modify the original array
- Optimization of ecological | Lake Warehouse Integration: gbase 8A MPP + xeos
- 图解网络:揭开TCP四次挥手背后的原理,结合男女朋友分手的例子,通俗易懂
- In depth analysis of ArrayList source code, from the most basic capacity expansion principle, to the magic iterator and fast fail mechanism, you have everything you want!!!
- Codeforces Round #649 (Div. 2)——A. XXXXX
- How to make enterprise recruitment QR code?
- 神经网络与深度学习-5- 感知机-PyTorch
- pb9.0 insert ole control 错误的修复工具
- Version 2.0 of tapdata, the open source live data platform, has been released
猜你喜欢
Neural network and deep learning-5-perceptron-pytorch
SQLite3 data storage location created by Android

Give some suggestions to friends who are just getting started or preparing to change careers as network engineers

From starfish OS' continued deflationary consumption of SFO, the value of SFO in the long run
#797div3 A---C

Application of slip ring in direct drive motor rotor
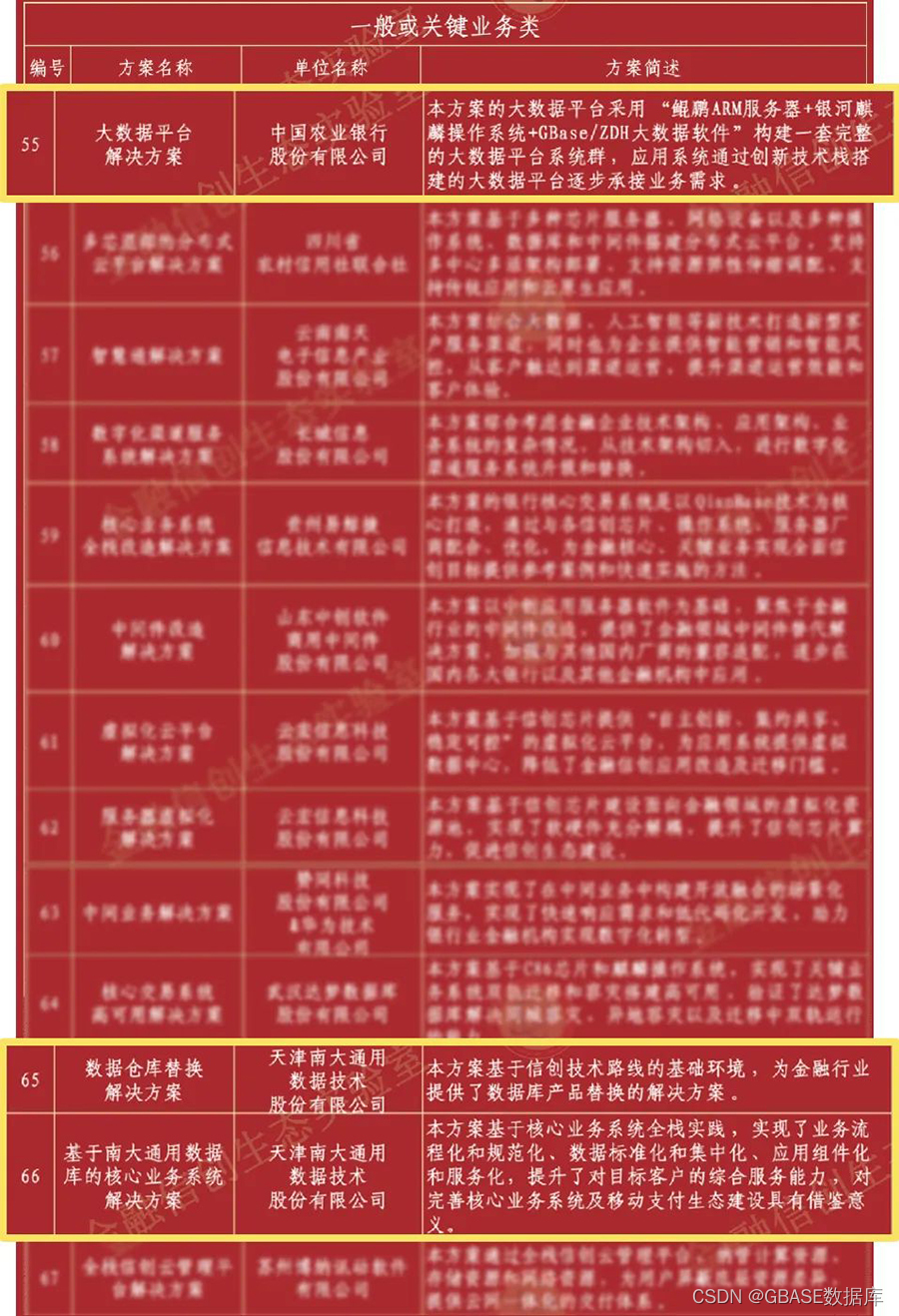
Capability contribution three solutions of gbase were selected into the "financial information innovation ecological laboratory - financial information innovation solutions (the first batch)"
ClickHouse原理解析与应用实践》读书笔记(8)

Keras深度学习实战——基于Inception v3实现性别分类

ANSI / nema- mw- 1000-2020 magnetic iron wire standard Latest original
随机推荐
uniapp一键复制功能效果demo(整理)
Redux usage
Can you write the software test questions?
如何制作企业招聘二维码?
Codeforces Round #649 (Div. 2)——A. XXXXX
Redismission source code analysis
CV2 read video - and save image or video
Codeforces Round #633 (Div. 2) B. Sorted Adjacent Differences
Tapdata 的 2.0 版 ,开源的 Live Data Platform 现已发布
Chapter 7 behavior level modeling
common commands
发现值守设备被攻击后分析思路
MySQL查询为什么没走索引?这篇文章带你全面解析
Codeforces Round #643 (Div. 2)——B. Young Explorers
Vim 字符串替换
Why did MySQL query not go to the index? This article will give you a comprehensive analysis
Is it necessary for project managers to take NPDP? I'll tell you the answer
Redisson distributed lock unlocking exception
How to make the conductive slip ring signal better
Dataworks duty table