当前位置:网站首页>[target tracking] |atom
[target tracking] |atom
2022-07-08 01:47:00 【rrr2】
Article title :《ATOM: Accurate Tracking by Overlap Maximization》
Article address :https://arxiv.org/pdf/1811.07628.pdf
github Address :https://github.com/visionml/pytracking
CVPR2019 oral
problem
People focus on developing powerful classifiers , However, the accurate target state estimation is seriously ignored (target state estimation)( That is, the regression problem of bounding box ).
In the actual , Many classifiers use simple multi-scale search methods ( for example SiamFC) To estimate the bounding box of the target .

chart 1. Compare our method with the most advanced tracker . Based on correlation filter UPDT[3] Lack of explicit target state estimation components , It is Perform brute force multiscale search . therefore , it Do not deal with aspect ratio changes , This may cause the trace to fail ( The second line ).DaSiamRPN[42] The bounding box regression strategy is used to estimate the target state , But out of plane rotate 、 deformation Under such circumstances, there are still difficulties . Our method uses overlapping prediction Networks , Successfully addressed these challenges , And provide accurate bounding box prediction
We believe that this method is essentially limited , Because target estimation is a very complicated thing , Need high-level information about the goal (high-level knowledge).
Tracking tasks can be broken down into categories (classification) Task and an estimate (estimation ) Mission . For the former , By dividing the image area into foreground and background , So as to robustly provide rough positioning of the target .
The latter is to estimate the target state , It is usually represented by a bounding box .
Online learning is to obtain the classifier weight in the first frame . Capture the characteristics of a specific target .
In this paper, we do
(1) Prediction of bounding box
In this paper , We balance the performance gap between target classification and target estimation , We introduced a novel tracking architecture , It consists of two parts: target estimation and target classification .
Received recent IoU-Net Inspired by the , We train a target estimation component , To predict “ The goal is ” and “ Estimated bounding box ” Between IoU. Because of the original IoU-Net Is a specific category (class-specific Of ), So it is not very suitable for general target tracking , We propose a novel architecture to put target-specific Information into IoU In the prediction of . We used to introduce a modulation based (modulation-based) Network components , hold reference Image ( That is to say Templates ) Target appearance information Combine , In order to obtain target-specific Of IoU It is estimated that . This allows us to train the target estimation component off-line on large-scale data sets . In the process of tracking , By putting the predicted IoU overlap Maximize , To find the target bounding box .
(2) Online training classifier ( Online training with conjugate gradient )
In order to develop a seamless and transparent tracking method , We also revisit the problem of target classification , To avoid unnecessary complexity . Our target classification component is simple and powerful , from 2 22 A network header with full connection layer . Different from the target estimation module , The classification component is trained online , Provide strong robustness in disturbed scenes . To ensure real-time performance , We solved the problem of online optimization , The problem of gradient descent cannot be effectively . contrary , The strategy based on conjugate gradient is adopted , It also demonstrates how to implement it in a deep learning architecture . The tracking process is simple , It mainly includes classification 、 It is estimated that 、 Model update .
Related work
Based on correlation filtering (correlation-based) The tracker of has been widely used . But it has been impossible to accurately estimate the target ( Bounding box ). Even to find a single parameter scaling factor , It's also a huge challenge . Most methods adopt the strategy of brute force multi-scale detection , The computational burden is heavy . therefore , The default method is to use a separate classifier to do state estimation . But the target classifier is not sensitive to all aspects of the target state , For example, width and height . actually , The target state is invariant in some ways , You can consider Use this feature to improve the robustness of the model . We don't rely on classifiers , Instead, learn a special goal estimation component .
Tracking should separate classification from estimation , Because classification is mainly used to judge whether a location target exists , And not sensitive to the state of the target , The target state is simplified as 2D Position and the length and width of the target box , This is what the goal evaluation does , Therefore, dividing the tracking framework into two task modules helps to improve the overall performance .
be based on CF Our tracker is a good classifier , It will output a response graph , Determine the most likely location of the target according to the maximum response , But this method can not completely estimate the state of the target , Such as scale , So scale estimation usually uses additional classifiers .
The accurate estimation of the target requires a lot of prior information , Because target changes such as deformation are difficult to estimate by tracking image information alone .
So the author thinks SiameseRPN The success of depends mainly on a lot of offline training , however Siamese Most methods are limited by the performance of classification , Because this kind of method has no online training process , and CF There is a way , So there is no online training
As a result, it cannot deal with the interference in tracking well , Or similar goals , Model updating can only partially solve this problem .
For the accurate estimation of the target bounding box , It's a complex task , Advanced prior knowledge is required . The bounding box depends on Attitude and perspective of the target , This cannot be modeled as a simple image transformation ( For example, unified image scaling ). therefore , Learning online from scratch to accurately estimate goals is very challenging . There are some methods recently , Integrate prior knowledge through a lot of offline training . for example SiamRPN, And its extended algorithm , All show the ability of bounding box regression .
However, these twins (siamese) Tracking methods usually struggle with the problem of target classification . Unlike those based on Correlation (correlation-based) Methods , Tracking due to No online updates , Interference factors are not explicitly considered . Although some use simple template update technology , Improved a little , but It has not reached the level of a powerful online learning model . Therefore, the author proposes an online training classifier and an offline training evaluation network , Work together to solve the problem of target tracking , In fact, it is very similar to testing , It is a two-stage tracking framework .
Compared with the twin tracking method , We Online learning classification model , At the same time, a lot of off-line training is used to estimate the target .

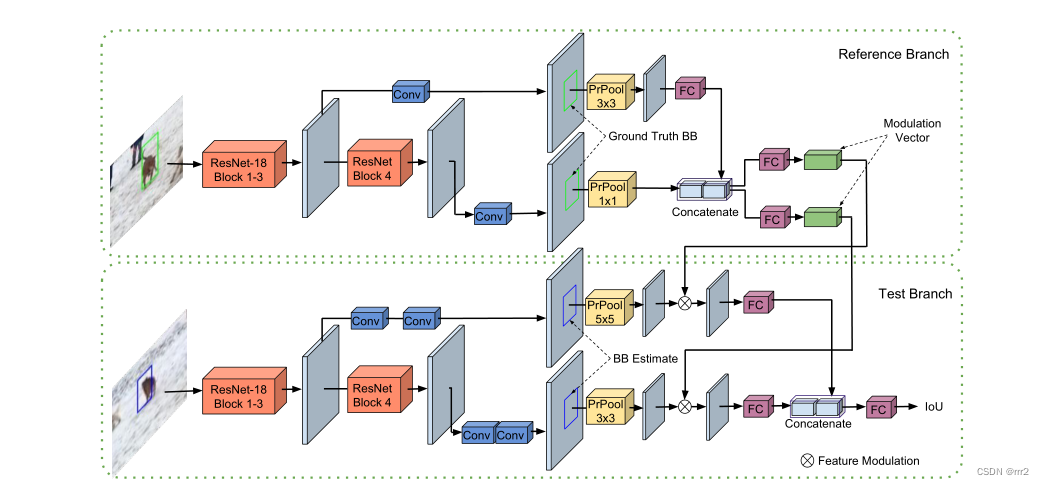
Target classification and target estimation Tasks share the same backbone network , This backbone is in ImageNet Pre trained ResNet-18, Then fine tune here .
Different from the detection task ,IoU Modules need to be trained for goals rather than categories , The author thinks that IoU The prediction module is a high-level semantic module , Therefore, it is unreasonable to use only the first frame of the video for training , So we need to train offline to get a person with strong generalization ability IoU Prediction module .
The difficulty lies in IoU How does the module make good use of the information of the reference frame of the given target , The author has made many attempts , Find out Siamese Its structure is good , So a similar network called modulation based network is used to Predict any target of a given reference frame Of IoU.
There are two parts , The upper half uses the reference frame to generate a modulation vector to modulate the network of the lower half test frame . The input characteristic networks of the two branches are consistent . The first half is the reference frame x 0 Reference target B 0 Characteristics of , Output a positive number D Modulation vector of dimension c,D Corresponding characteristic layers .
And in the test frame x when , The network part has changed , The proposed feature of the backbone network is followed by an additional convolution layer , Corresponding back pooling It's getting bigger , Then, each channel of the feature is weighted with the modulation vector , That is, the information of the reference frame is given , The modulated features are then sent to IoU Prediction module g, That is, output after three full connection layers IoU, Then the formula is right for a bb,B Of IoU namely I o U ( B ) = g ( c ( x 0 , B 0 ) ⋅ z ( x , B ) )
Training
The author used LaSOT and trackingNet Image pairs collected on the dataset , Also used. coco Data set for data amplification , Adopted and DaSiamese Similar approach
On the reference frame , Extracted around the target 5 Times the size of the square area as input , The test frame simulates the tracking scene by perturbing the position and scale of the image , Each picture pair generates 16 Candidates bb, This is from gt Plus Gaussian noise , And set bb and gt The smallest IoU by 0.1, Use image blur and color perturbation for data amplification ,IoU Finally normalized to -1 and 1 Between . The backbone network is not updated during training .
Classification of network
It consists of two convolution layers , It is mainly used for rough positioning, so there is no need for a deeper network , In fact, classification network is more like regression , Similar to the idea of deep regression tracking , A Gaussian centered on the target is regressed by convolution label, Write a function, that is

and CF The method is similar to writing the objective function, that is 
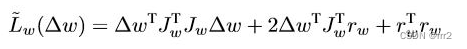

Online tracking
The evaluation network part estimates the location and scale of the target , First, find the maximum confidence point according to the confidence graph of the classification network , That is, the rough candidate target area , Combine the scale of the previous frame to generate the initial bb, Theoretically, only one bb That's all right. , But more is better , So after adding noise, it generates 9 individual ,10 individual bb All give IoUNet The prediction module utilizes target estimation Modules calculate their IoU The number , For each bb,5 Subgradient descent iteration maximizes IoU Get the best bb, Finally take 3 The highest IoU It's worth it bb As the final prediction result ,
The modulation vector is only calculated in the first frame , That is to say, the reference frame branch is only used in the first frame , Not in the back , The reference frame is the initialization frame .
ref
https://www.bilibili.com/video/BV1H54y167rG?vd_source=74166d3ce4e663703f01426526c56fd1
https://blog.csdn.net/laizi_laizi/article/details/109455080
边栏推荐
- Application of slip ring in direct drive motor rotor
- Working principle of stm32gpio port
- QT -- package the program -- don't install qt- you can run it directly
- 城市土地利用分布数据/城市功能区划分布数据/城市poi感兴趣点/植被类型分布
- 给刚入门或者准备转行网络工程师的朋友一些建议
- powerbuilder 中使用线程的方法
- Matlab method is good~
- C语言-Cmake-CMakeLists.txt教程
- About snake equation (2)
- break algorithm---刷题map
猜你喜欢
COMSOL----微阻梁模型的搭建---最终的温度分布和变形情况---材料的添加
Understanding of maximum likelihood estimation
Get familiar with XML parsing quickly

From starfish OS' continued deflationary consumption of SFO, the value of SFO in the long run

Application of slip ring in direct drive motor rotor
SQLite3 data storage location created by Android

C语言-Cmake-CMakeLists.txt教程

快手小程序担保支付php源码封装
静态路由配置全面详解,静态路由快速入门指南

The function of carbon brush slip ring in generator
随机推荐
Get familiar with XML parsing quickly
Tapdata 的 2.0 版 ,開源的 Live Data Platform 現已發布
ROS 问题(topic types do not match、topic datatype/md5sum not match、msg xxx have changed. rerun cmake)
Voice of users | winter goes and spring comes, waiting for flowers to bloom -- on gbase 8A learning comprehension
Capability contribution three solutions of gbase were selected into the "financial information innovation ecological laboratory - financial information innovation solutions (the first batch)"
nacos-微服务网关Gateway组件 +Swagger2接口生成
Euler Lagrange equation
PHP 计算个人所得税
项目经理有必要考NPDP吗?我告诉你答案
npm 内部拆分模块
第七章 行为级建模
Application of slip ring in direct drive motor rotor
C语言-Cmake-CMakeLists.txt教程
正则表达式
Call (import) in Jupiter notebook ipynb . Py file
qt-使用自带的应用框架建立--hello world--使用min GW 32bit
QML fonts use pixelsize to adapt to the interface
Version 2.0 of tapdata, the open source live data platform, has been released
碳刷滑环在发电机中的作用
What kind of MES system is a good system