当前位置:网站首页>Word2vec词向量
Word2vec词向量
2022-08-02 14:07:00 【lq_fly_pig】
前文也零散的写了些 关于神经网络模型的篇幅,如NNLM,本文着重讲解有关词向量的内容,从静态词向量到动态词向量等,其实相关的内容,网上也有很多,本人主要是为了做些记录和巩固下基础的知识点
一、词向量概述
前面篇幅中介绍了NNLM 神经网络语言模型的计算原理,NNLM生成的产物初始化的矩阵也可以作为词向量。基于NNLM(神经网络语言模型)预训练方法存在一个问题,主要是通过 t 时刻的单词预测t+1时刻的单词,只能通过历史信息预测未来时刻的信息,损失了 当前单词与"未来"单词之间的 共现信息
本篇介绍新的词向量预训练方法——Word2Vec,其中包括skip-gram模型和CBOW(Continuous Bags of Words)模型,这两种模型是2013年提出,严格上来讲不算是语言模型,因为其是基于词语与词语之间的共现信息实现词向量的学习。不再是基于整句(句子长度为n )中前 n-1个 单词预测第n个单词
1.1 CBOW模型
输入一句query,CBOW的中心思想是,根据上下文预测目标词汇,例如query为,...  ,
,  ,
, ,
, ,
, .... CBOW的任务就是根据 的上下文
.... CBOW的任务就是根据 的上下文  = { , ,, } 来预测 t 时刻的单词 , 由于窗口大小设置为5 所以 的上下文文本中包含4个单词。 从上文中NNLM的文章得到 NNLM训练词向量的思想是,按照query的顺序进行输入前 n-1 个 word 来预测第 n 个word ,但是
= { , ,, } 来预测 t 时刻的单词 , 由于窗口大小设置为5 所以 的上下文文本中包含4个单词。 从上文中NNLM的文章得到 NNLM训练词向量的思想是,按照query的顺序进行输入前 n-1 个 word 来预测第 n 个word ,但是
CBOW模型不考虑上下文的顺序,因此CBOW模型也算是一个词袋子模型,后续有人验证 按照顺序输入在某些特定的任务(词性标注、句法分析)等表现更好
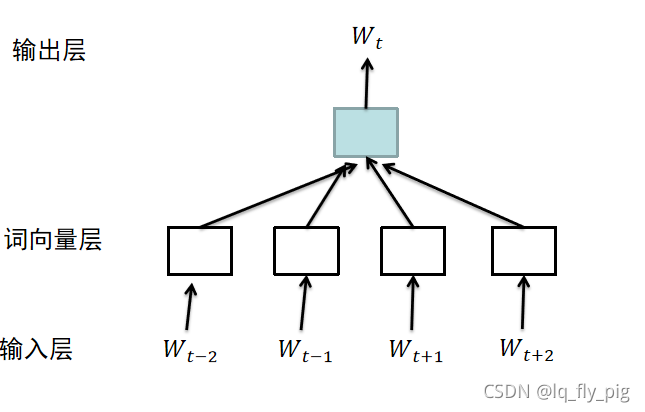
(1). 输入层,以大小为5的窗口,在目标词的左边和右边各选择2个词语,作为模型的输入,输入层是由4个维度为词表长度的 |V|的 one-hot表示
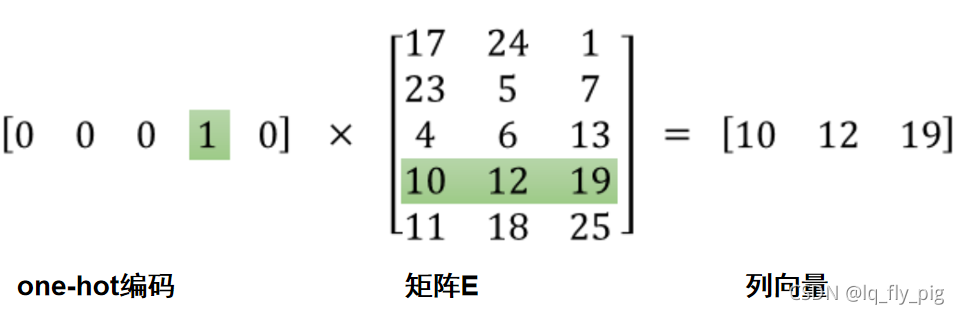
(2). 初始化一个矩阵 E,维度为{V,dim}, dim 表示词向量维度,一般(50-300)之间,V表示的是词表的长度。矩阵E类似于tensorflow中的 look_up操作。如下图所示:
(3).对上下文词向量取平均,就得到了  的上下文表示
的上下文表示 ,使用
,使用  表示单个word对应的列向量:
表示单个word对应的列向量:
 ,使用
,使用  表示单个word对应的列向量:
表示单个word对应的列向量: 
(4).输出层,对目标词汇进行预测,进行多分类预测,分类的类别大小为词汇的size 大小 |V|,损失函数为常见的 交叉熵损失函数
1.2 skip-gram模型
skip-gram 模型和CBOW模型反过来,使用当前词汇预测上下文词汇,使用词汇预测上下文信息,  ,
,  ,
, ,
, ,上下文中每一个词语当做独立的词汇进行预测,因此skip-gram模型是计算词与词之间的共现关系,
,上下文中每一个词语当做独立的词汇进行预测,因此skip-gram模型是计算词与词之间的共现关系,

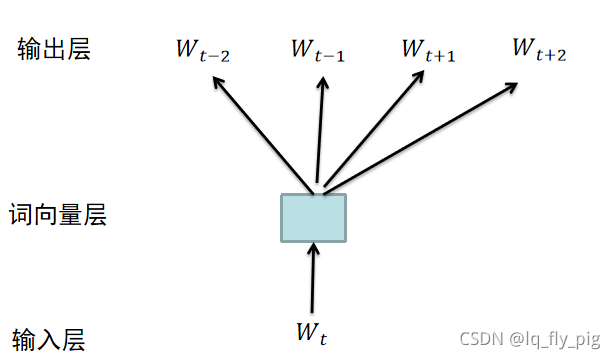
具体运算过程如下所示:
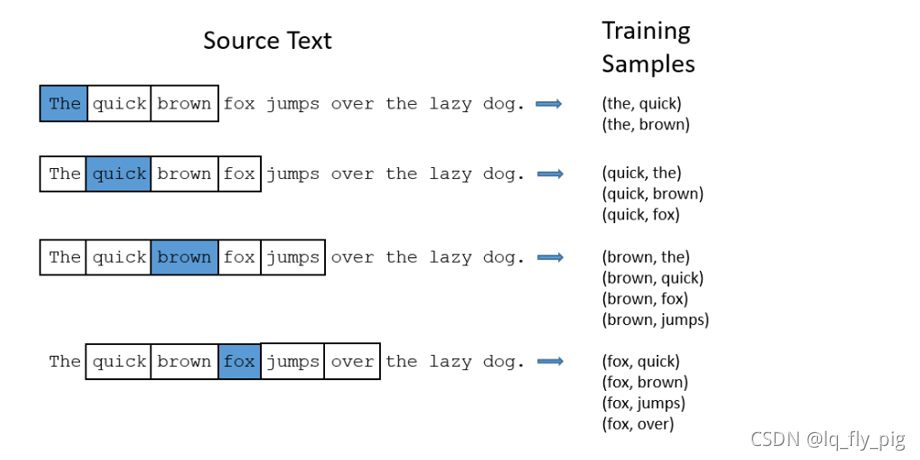
1.原始文本为“The quick brown fox jumps over the laze dog”,设置窗口大小为2;上图中蓝色的word 为目标词汇,右边的 Training Samples为构建的训练样本
2.从上文中发现一个问题,就是很多常见类似于"the" 这种词汇对于其上下文并不能带来很多有用的语义信息,因为几乎很多词汇中都会出现"the"这个单词,对于这种高频的词汇,原论文中使用的是通过抽样来删除该类单词;基本思想是,对于一开始训练的单词,每一个单词都有一定概率被删除,概率和单词出现的频率有关。
3.对于输出层也是类似于 NNLM的方式进行多分类预测,使用交叉熵进行损失迭代
二、负采样
2.1 CBOW和skip-gram模型的问题
我们从上文中的思路得到具体的流程如下:
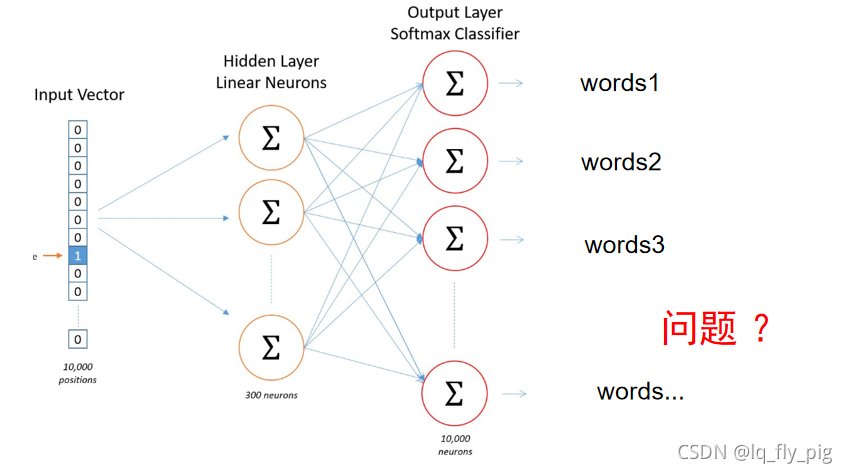
从章节一中,我们知道了 skip-gram和CBOW模型的输入层,词向量层,输出层,其中我们知道最终的预测是多分类,分类的类别数量和词汇的size相关,词汇表很大导致,训练过程中的矩阵很大,严重影响训练的效率
2.2 skip-gram模型的负采样训练
针对训练的效率问题,skip-gram 采用 负采样来加速训练,具体例子如下:

如:当前词汇是 quick,目标词汇是 brow,假设词汇表的大小是10000,在模型的输出层是10000分类,单词brow的score得分最高,其他的9999的分类的score较低。对于这些9999得分低的单词 我们称之为 "negative " word.
负采样的方法提供一种新的任务视角:给定当前词语和其上下文。最大化两者之间的共现概率,问题简化成一种二分类问题,也就是说 quick—> brown 的分类为1, quick—>dong 的分类为0
对于 "negative " word 的选择,一个单词被选作negative sample的概率跟它出现的频次有关,出现频次越高的单词越容易被选作negative words,原来论文中指的是使用"一元分布模型",一般的情况 "negative " word 选择(5-20)个
2.3 word2vec无法处理一词多义
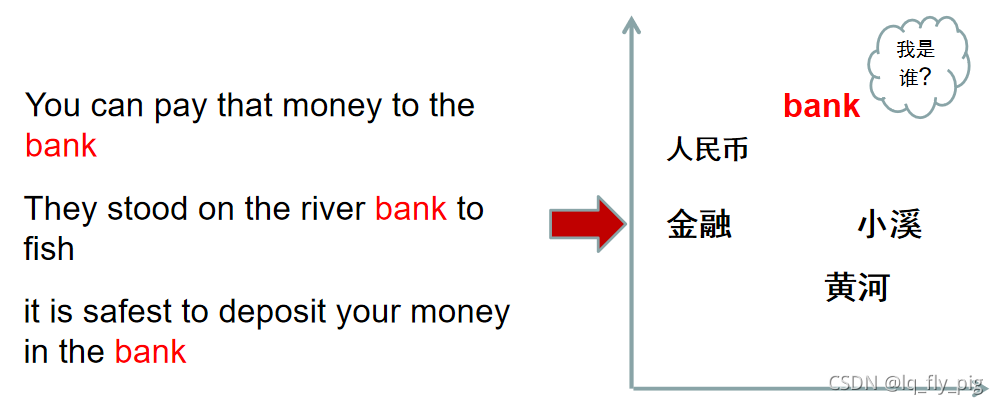
由上文得到 bank有银行的意思,也有河岸的意思,对于这种静态词向量无法表达其多义性
三、总结以及代码展示
3.1总结
1.CBOW 是通过上下文进行预测当前值
2. SKip-gram 是通过当前值来预测上下文
优点: (1).考虑到上下文,跟之前的Embedding 相比,效果更好
(2).相比较之前的Embedding 维度更少,速度更快
(3). 通用性较强,使用于各种NLP任务中
缺点:(1).词和向量是一对一的关系,无法处理多义词问题
(2).word2vec 是一种静态方式,无法处理特定任务做动态优化
3.2 代码展示
#code by 2021.8.1
# learning by https://github.com/graykode
import numpy as np
from numpy import random
import torch
import torch.nn as nn
import torch.optim as optim
import pdb
batch_size = 2 # mini-batch size
embedding_size = 2 # embedding size
##随机选取 训练数据 从skip_gram中选取
def random_batch():
random_inputs = []
random_labels = []
random_index = np.random.choice(range(len(skip_gram)),batch_size,replace=False) ## 选取 len(skip_gram) 范围内 batch_size长度的数组
for i in random_index:
random_inputs.append(np.eye(voc_size)[skip_gram[i][0]]) ## skip_gram[i][0] 表示的是获取 中心词 target
### np.eye(voc_size) 表示的是 生成one-hot的向量 大小是 voc_size * voc_size ,word2vec的数据输入是one-hot的形式
random_labels.append(skip_gram[i][1])
return random_inputs, random_labels
class word2vec(nn.Module):
def __init__(self) -> None:
super().__init__()
self.W = nn.Linear(voc_size,embedding_size,bias=False) ## word-embedding的 初始化
self.WT = nn.Linear(embedding_size,voc_size,bias=False) ## fc 输出
def forward(self,X):
### X [batch_size , voc_size] one-hot 编码
hidden_layers = self.W(X)
out_layers = self.WT(hidden_layers)
return out_layers
if __name__ == '__main__':
### 训练数据
sentences = ["apple banana fruit", "banana orange fruit", "orange banana fruit",
"dog cat animal", "cat monkey animal", "monkey dog animal"]
word_sequence = " ".join(sentences).split()
word_list = " ".join(sentences).split()
word_list = list(set(word_list)) ###所有的字典大小,去重统计
word_dict = {w:i for i, w in enumerate(word_list)}
voc_size = len(word_dict)
### create skip_gram data and window size = 1 , skip_window = 1, num_skips = 2
## skip_window的参数,它代表着我们从当前input word的一侧(左边或右边)选取词的数量
# 另一个参数 num_skips ,表示从 window中选取多少个不同的 词 作为训练数据
skip_gram = []
for i in range(1,len(word_sequence) -1):
target = word_dict[word_sequence[i]] ## 当前的 word
context = [word_dict[word_sequence[i-1]],word_dict[word_sequence[i+1]]] ##获取前后的 words
for w in context:
skip_gram.append([target,w])
model = word2vec()
loss_fuc = nn.CrossEntropyLoss() ## 交叉熵 损失
optimizer = optim.Adam(model.parameters(), lr=0.001) ## 定义优化器
for epoch in range(50000):
input_batch, target_batch = random_batch()
input_batch = torch.Tensor(input_batch)
target_batch = torch.LongTensor(target_batch)
# pdb.set_trace()
## input_batch shape = [2,8] target_batch shape = [2]
optimizer.zero_grad() ## 优化器初始化 梯度值设置为0
output = model(input_batch) ## output : [batch_size, voc_size]
loss = loss_fuc(output,target_batch)
if(epoch + 1) % 1000 == 0:
print(' Epoch:','%04d'%(epoch + 1), 'loss = ','{:.6f}'.format(loss))
loss.backward() ## 反向传播
optimizer.step() ## 每一步更新参数
边栏推荐
- flutter中App签名
- MySQL知识总结 (五) 锁
- AAPT: error: duplicate value for resource ‘attr/xxx‘ with config ‘‘, file failed to compile.
- LLVM系列第十七章:控制流语句for
- 再见篇:App专项技术优化
- MySQL知识总结 (十一) MySql 日志,数据备份,数据恢复
- Cannot figure out how to save this field into database. You can consider adding a type converter for
- uni-app页面、组件视图数据无法刷新问题的解决办法
- 华为路由交换
- LLVM系列第八章:算术运算语句Arithmetic Statement
猜你喜欢


随机推荐
原码、补码、反码
LLVM系列第二十六章:理解LLVMContext
NDK报错问题分析方案(一)
The NDK portal: C
Redis持久化机制
C语言日记 6 基本输入/输出
二进制乘法运算
LLVM系列第二十五章:简单统计一下LLVM源码行数
C语言日记 4 变量
C语言待解决
App signature in flutter
Spark_Core
YOLOv7 uses cloud GPU to train its own dataset
一文带你快速掌握Kotlin核心技能
mysql常用函数
uniCloud 未能获取当前用户信息:30205 | 当前用户为匿名身份
浏览器报错数字代表的大概意思
LLVM系列第二十四章:用Xcode编译调试LLVM源码
AAPT: error: duplicate value for resource ‘attr/xxx‘ with config ‘‘, file failed to compile.
科创知识年度盛会,中国科创者大会8月6日首场开幕!