当前位置:网站首页>MySQL加锁案例分析
MySQL加锁案例分析
2022-08-01 16:22:00 【CaptHua】
1.锁的种类
InnoDB有三种行锁的算法
Record Lock
总是会去锁住索引记录, 如果表没有设置索引, 引擎会使用隐式的主键来进行锁定
Gap Lock 锁定一个范围, 不包含自身
Next-Key Lock: Gap Lock+Record Lock 范围+自身, 解决幻读问题,前开后闭
previous-key locking:前闭后开
2.加锁规则
前提:RR隔离级别,版本:版本:5.x 系列 <=5.7.24,8.x系统<=8.0.13
原则1:加锁的基本单位是 next-key lock。next-key lock 是前开后闭区间。
原则2:查找过程中访问到的对象才会加锁。
优化1:索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁。
优化2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock 退化为间隙锁。
一个bug:唯一索引上的范围查询会访问到不满足条件的第一个值(包含)为止。(8.0.25已经修复)
注意:
- 非唯一索引,需要向右遍历到第一个不符合条件的值才能停止
- 范围查找就往后继续找
- 执行 for update 时,系统会认为你接下来要更新数据,因此会顺便给主键索引上满足条件的行加上行锁
- 冲突的锁可以被不同事务在一个间隙上持有(conflicting locks can be held on a gap by different transactions)
- 读提交隔离级别的优化:在读提交隔离级别下有一个优化,即:语句执行过程中加上的行锁,在语句执行完成后,就要把“不满足条件的行”上的行锁直接释放了,不需要等到事务提交。也就是说,读提交隔离级别下,锁的范围更小,锁的时间更短,这也是不少业务都默认使用读提交隔离级别的原因。
3.案例
示例数据
CREATE TABLE `t`
(
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE = InnoDB;
insert into t
values (0, 0, 0),
(5, 5, 5),
(10, 10, 10),
(15, 15, 15),
(20, 20, 20),
(25, 25, 25);
案例一:等值查询间隙锁
t1 | t2 | t3 |
update t set d=d+1 where id=7; | ||
insert into t values (8,8,8); 阻塞 | ||
update t set d=d+1 where id=10; 成功 |

分析
t中没有id=7的记录,根据加锁的规则:
1. 根据 原则1,加锁单位是 next-key lock,session A 加锁范围就是 (5,10]
2. 同时根据优化 2,这是一个等值查询 (id=7),而 id=10 不满足查询条件,next-key lock 退化成间隙锁,因此最终加锁的范围是 (5,10)
所以事务2要往这个间隙里面插入 id=8 的记录会被锁住,但是事务3修改 id=10 这行是可以的
案例二:非唯一索引等值锁
t1 | t2 | t3 |
select id from t where c = 5 lock in share mode | ||
update t set d=d+1 where id=5 | ||
insert into t values (7,7,7) 阻塞 |

分析
t1给索引 c 上 c=5 的这一行加上读锁
1.根据原则 1,加锁单位是 next-key lock,因此会给 (0,5] 加上 next-key lock
2.因为c不是唯一索引,所以需要向下遍历到第一个不符合条件的值才能停止。因此访问 c=5 这一条记录不能马上停下来,需要向右遍历,查到 c=10 才放弃。根据原则 2,访问到的都要加锁,因此要给 (5,10]加 next-key lock
3.根据优化 2:等值判断,向右遍历,最后一个值不满足 c=5 这个等值条件,因此退化成间隙锁 (5,10)。
4.根据原则 2 ,只有访问到的对象才会加锁,这个查询使用覆盖索引,并不需要访问主键索引,所以主键索引上没有加任何锁,因此 t2的 update 语句可以执行完成
访问到的对象才会加锁,这个“对象”指的是列,不是 记录行。 加锁,是加在索引上的。 列上,有索引,就加在索引上; 列上,没有索引,就加在主键索引上
t3要插入一个 (7,7,7) 的记录,就会被 t1 的间隙锁 (5,10) 锁住
案例三:主键索引范围锁
t1 | t2 | t3 |
select * from t where id>=10 and id | ||
insert into t values (8,8,8); OK insert into t values (13,13,13) 阻塞 | ||
update t set d=d+1 where id=15 阻塞 |
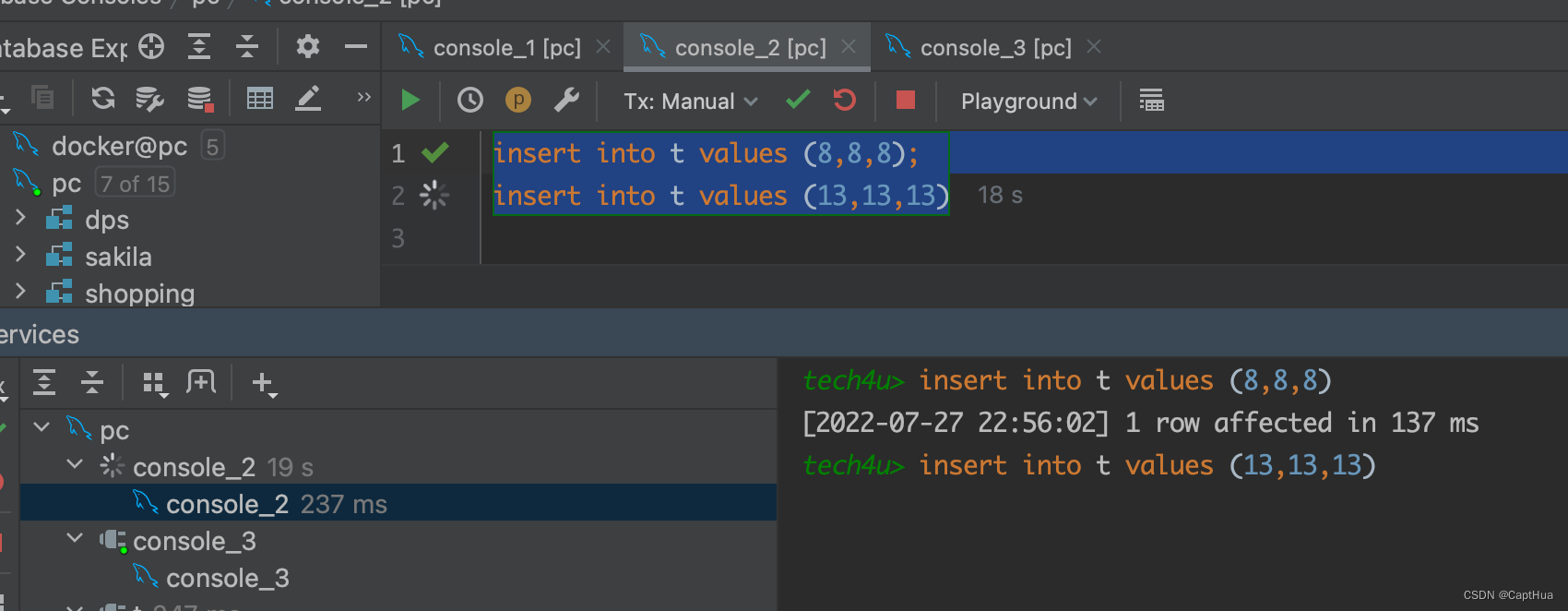
分析
1.开始执行的时候,要找到第一个 id=10 的行,因此本该是 next-key lock(5,10]。 根据优化 1, 主键 id(唯一索引) 上的等值条件,退化成行锁,只加了 id=10 这一行的行锁
2.范围查找就往后继续找,找到 id=15 这一行停下来,因此需要加 next-key lock(10,15]
所以,t1 锁的范围就是主键索引上,行锁 id=10 和 next-key lock(10,15]
案例四:非唯一索引范围锁
t1 | t2 | t3 |
select * from t where c>=10 and c | ||
insert into t values (8,8,8) 阻塞 | ||
update t set d=d+1 where c=15 阻塞 |
分析
在第一次用 c=10 定位记录的时候,索引 c 上加了 (5,10] 这个 next-key lock 后,由于索引 c 是非唯一索引,没有优化规则,也就是说不会蜕变为行锁,因此最终 t1 加的锁是 索引 c 上的 (5,10] 和 (10,15] 这两个 next-key lock
案例五:唯一索引范围锁 bug
t1 | t2 | t3 |
select * from t where id>10 and id | ||
update t set d=d+1 where id=20 阻塞 | ||
insert into t values (16,16,16) 阻塞 |
t1 是一个范围查询,按照原则 1 的话,应该是索引 id 上只加 (10,15]这个 next-key lock,并且因为 id 是唯一键,所以循环判断到 id=15 这一行就应该停止了,但是实现上,InnoDB 会往后扫描到第一个不满足条件的行为止,也就是 id=20。而且由于这是个范围扫描,因此索引 id 上的 (15,20]这个 next-key lock 也会被锁上
这里锁住 id=20 这一行的行为,其实是没有必要的。因为扫描到 id=15,就可以确定不用往后再找了。但实现上还是这么做了,因此这可以认为是个 bug
案例六:非唯一索引上存在"等值"的例子
向表中再插入一条记录
insert into t values (30,10,30);
此时索引c如下图所示

t1 | t2 | t3 |
delete from t where c=10 | ||
insert into t values (12,12,12) 阻塞 | ||
update t set d=d+1 where c=15 |
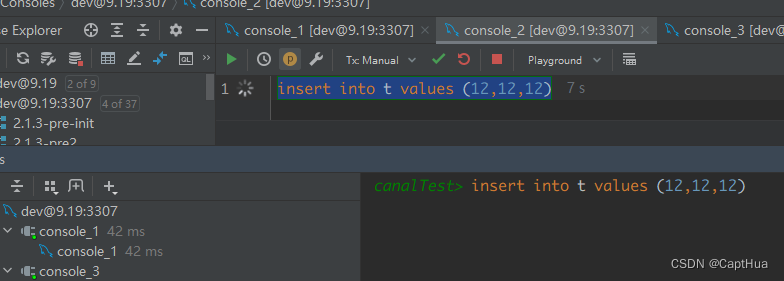
分析
1. t1在遍历的时候,先访问第一个 c=10 的记录。同样地,根据原则 1,这里加的是 (c=5,id=5) 到 (c=10,id=10) 这个 next-key lock
2. t1向右查找,直到碰到 (c=15,id=15) 这一行,循环才结束。根据优化 2,这是一个等值查询,向右查找到了不满足条件的行,所以会退化成 (c=10,id=10) 到 (c=15,id=15) 的间隙锁
因此,delete 语句在索引 c 上的加锁范围,就是下图中蓝色区域覆盖的部分

案例七:limit 语句加锁
t1 | t2 |
delete from t where c=10 limit 2 | |
insert into t values (12,12,13) OK |
分析
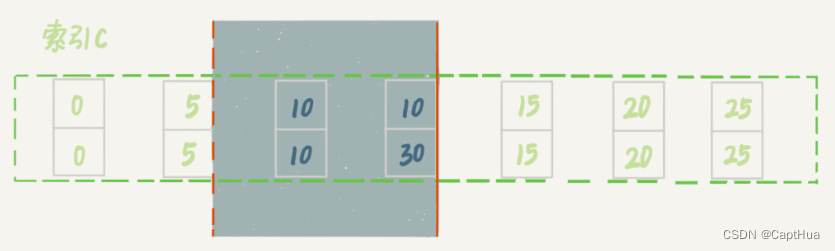
t1 的 delete 语句加了 limit 2。表 t 里 c=10 的记录有两条,因此加不加 limit 2,删除的效果都是一样的,但是加锁的效果却不同。可以看到,t2 的 insert 语句执行通过了,跟案例六的结果不同
delete 语句明确加了 limit 2 的限制,因此在遍历到 (c=10, id=30) 这一行之后,满足条件的语句已经有两条,循环就结束了
因此,索引 c 上的加锁范围就变成了从(c=5,id=5) 到(c=10,id=30) 这个前开后闭区间,(c=10,id=30)之后的这个间隙并没有在加锁范围里,因此 insert 语句插入 c=12 是可以执行成功的。如下图所示:
案例八:死锁
t1 | t2 |
select id from t where c=10 lock in share mode; | |
update t set d=d+1 where c=10 阻塞 | |
insert into t values (8,8,8); | |
[40001][1213] Deadlock found when trying to get lock; try restarting transaction |
分析
1. t1 启动事务后执行查询语句加 lock in share mode,在索引 c 上加了 next-key lock(5,10] 和间隙锁 (10,15);
2. t2 的 update 语句也要在索引 c 上加 next-key lock(5,10] ,进入锁等待。
先加(5, 10)的间隙锁,然后加10的行锁,锁住,还没有来得及加(10,15]的next-key lock呢,就被10的行锁给锁住了,所以这个时候t1如果插入(12,12,12)是不会被session B的间隙锁给锁住。
3. 然后 t1 要再插入 (8,8,8) 这一行,被 session B 的间隙锁锁住。由于出现了死锁,InnoDB 让 session B 回滚
t2 中 “加 next-key lock(5,10] ” 操作,实际上分成了两步,先是加 (5,10) 的间隙锁,加锁成功;然后加 c=10 的行锁,这时候才被锁住的。
总结
在分析加锁规则的时候可以用 next-key lock 来分析。具体执行的时候,是要分成间隙锁和行锁两段来执行的
在删除数据的时候尽量加 limit。这样不仅可以控制删除数据的条数,让操作更安全,还可以减小加锁的范围
边栏推荐
- 会议OA项目(六)--- (待开会议、历史会议、所有会议)
- ODrive开发 #1 ODrive固件开发指南[通俗易懂]
- kubelet节点压力驱逐
- 兆骑科创科创赛事平台,创业赛事活动路演,线上直播路演
- ESP8266-Arduino编程实例-GA1A12S202对数刻度模拟光传感器
- Zhaoqi Science and Technology Innovation Platform attracts talents and attracts talents, and attracts high-level talents at home and abroad
- 70后夫妻给苹果华为做“雨衣”,三年进账7.91亿
- 计算机系统与网络安全技术——第一章——信息安全概述——1.1-网络安全定义——什么是信息?
- 5年测试,只会功能要求17K,功能测试都敢要求这么高薪资了?
- 直播app开发,是优化直播体验不得不关注的两大指标
猜你喜欢







随机推荐
22年镜头“卷”史,智能手机之战卷进死胡同
2022强网杯CTF---强网先锋 ASR wp
Zhaoqi Science and Technology Innovation Platform attracts talents and attracts talents, and attracts high-level talents at home and abroad
MySQL INTERVAL 关键字指南
【硬核拆解】50块2个的2022年夏季款智能节电器到底能不能省电?
03 gp 集群搭建
华盛顿大学、Allen AI 等联合 | RealTime QA: What's the Answer Right Now?(实时 QA:现在的答案是什么?)
04 flink 集群搭建
5年测试,只会功能要求17K,功能测试都敢要求这么高薪资了?
MUI as a mobile phone to return to the action bar
直播app开发,是优化直播体验不得不关注的两大指标
14年测试人最近的面试经历,值得借鉴√
暑气渐敛,8月让我们开源一夏!
中国驻西班牙使馆再次提醒留学人员注意暑期安全
【repo】SyntaxError: invalid syntax
The untiy Resources directory dynamically loads resources
等变图神经网络在药物研发中大放异彩
MySQL data processing of authorization 】 【
Zhaoqi Science and Technology Innovation Event Platform, Entrepreneurship Event Roadshow, Online Live Roadshow
Why should model.eval() be added to the pytorch test?