当前位置:网站首页>Code repetition of reinforcement learning based parameters adaptation method for particlewarn optimization
Code repetition of reinforcement learning based parameters adaptation method for particlewarn optimization
2022-06-29 01:06:00 【Huterox】
List of articles
Preface
I read this document a few days ago :
《Reinforcement learning based parameters adaption method for particleswarm optimization》
I found that some points are quite novel , So today, the code of the paper is reproduced as a whole . The whole process probably took 1 And a half days ( Code debugging , Experiments are not included )
(PS: If If you don't want to read the paper , Please check this blog : On reinforcement learning optimization particle swarm optimization paper interpretation
In this blog post, we will completely analyze the idea and workflow of this paper . And to be honest, I don't think it is difficult to reproduce this paper , Some of the points are quite novel , You can play , By the way, practice as an intensive learning project .
Copyright
It's a solemn reminder : The copyright of this article belongs to me , No one is allowed to copy , Carry , Use with my consent !
2022.6.27~2022.6.28
date :2022.6.27~2022.6.28
Project structure
The whole project structure is as follows :
There is no more explanation here , But what is worth mentioning is , I don't use matrix here , Because the purpose of the whole project is to use Python As an experiment , And then put Python Code conversion to Java On the code Flink Of , So at the beginning of the design, an object is used to store a particle , The advantage of this is to use one object instead of several large matrices , In other words, there is no need to maintain the matrix , And the written code is highly readable , And it happens to be used in the paper CLPSO The velocity update equation of the , So what he realized here , It is also difficult to directly use the matrix to realize the tracking between particles , And the tournament selection .
Oh , By the way, let's make an additional note that this paper was published in arxiv above , It's not something IEEE This top issue , So some places , His description is not rigorous , So the overall design of the code is based on the paper , But some details are different , Otherwise, the code will not run .
Then the project was also verified , I found that the effect was really great , To tell you the truth, if it wasn't for the addition of DDPG, I want to play with this neural network , I wouldn't even want to reproduce this thing , And it was written with skepticism at the beginning , But for now , It's still very powerful , I've trained a total of 300 Every round PSO Algorithmic run 1000 Time . That is to say, this place has run away 30 Ten thousand days later 100 A particle , That is to say 3000 ten thousand , The original words , In the morning, I can send this article to record , But then I changed a few bug Then I adjusted several parameters , Actually, I'm still training 3 Billion times of network , But I can't stand it , Finally, change to 0.3 Billion .
Tradition PSO( Here I don't show the optimized ( Originally, I optimized ) Because the result is the same as being hanged )
All running 1000 Time
Tradition :
I can only optimize to -58
DDPG Optimize :
And it is in 50 I came out many times :
How do we play this? ?!!!
Tell the truth , I never thought it would have this effect .
Of course, no more nonsense , Let's look directly at implementation .
Data structure definition
The words here , Based on the first go data structure , Here's a definition Bird It is specially used to store some information .
#coding=utf-8
# Here we use definitions Class The way to achieve PSO, Easy to adjust later
from ONEPSO.Config import *
import random
class Bird(object):
# This is from 1 At the beginning
ID = 1
# This is the population when it is divided into multiple groups ID. He is from 0 At the beginning
CID = 0
# Used to store the distance between the particles and the particles of each sub population
DIST = []
Iterate = 0
Y = None
X = None
# Record the optimal value of the individual , This is related to finding the global optimal value later
# Because the paper also uses CLPSO, So I need this crap
# But here we still need Pbest And Gbest
Follow = None
# This gadget is used to judge whether the current particle needs to change its followers
NoChange = 0
PbestY = None
PBestX = None
PBestV = None
GBestX = None
GBestY = None
GBestV = None
CBestY=None
CBestX=None
CBestV =None
V = None
def __init__(self,ID):
self.ID = ID
self.V = [random.random() *(V_max-V_min) + V_min for _ in range(DIM)]
self.X = [random.random() *(X_up-X_down) + X_down for _ in range(DIM)]
def __str__(self):
return "ID:"+str(self.ID)+" -Fintess:%.2e:"%(self.Y)+" -X"+str(self.X)+" -PBestFitness:%.2e"%(self.PbestY)+" -PBestX:"+str(self.PBestX)+\
"\n -GBestFitness:%.2e"%(self.GBestY)+" -GBestX:"+str(self.GBestX)
Basic particle swarm optimization implementation
The basic particle swarm optimization implementation here is actually the same as the original reality , It's just that I'm here to be universal , I add functions directly to it .
#coding=utf-8
# This is the most basic PSO Algorithm implementation , Used to test the rationality of the current algorithm architecture
# In addition, this gadget is also a tool class for optimization , The whole algorithm is to find the minimum value
import sys
import os
sys.path.append(os.path.abspath(os.path.dirname(os.getcwd())))
import math
from ONEPSO.RLPSOEmersion.TargetRL import Target
from ONEPSO.RLPSOEmersion.ConfigRL import *
from ONEPSO.RLPSOEmersion.BirdRL import Bird
import random
import time
class NewPsoRL(object):
# This is used to record the last round GBestY Of , Mainly for the sake of ENV use ( It does not affect the normal basis of this algorithm PSO Use )
GBestYLast = None
# This is used to record the global optimum , To record the stalled
GBestY = None
NoChangeFlag = False
Population = None
Iterate_num = 0
Random = random.random
target = Target()
W_RL = W
C1_RL = C1
C2_RL = C2
C3_RL = C3
# First instance an object , Avoid starting it again next time... It's slow
Math = math
Count_Div = 0
##################################
""" These three broken things are to input several parameters of the neural network Each of these three things unfolds 5 Dimensional """
F_iterate_num = None
F_diversity = None
F_no_increase = None
""" These are the auxiliary variables set to get the above three craps """
F_no_increase_time = 0
##################################
def __init__(self):
# For convenience , Let's start with 1 Start
self.Population = [Bird(ID) for ID in range(1,PopulationSize+1)]
def __GetDiversity(self,Population):
# First calculate the average
x_pa = [0 for _ in range(DIM)]
for bird in Population:
for i in range(DIM):
x_pa[i]+=bird.X[i]
for i in range(DIM):
x_pa[i]/=PopulationSize
# Now calculate Diversity
Diversity = 0.
for bird in Population:
sum = 0
for i in range(DIM):
sum+=abs(bird.X[i]-x_pa[i])
Diversity+=self.Math.sqrt(sum)
Diversity = Diversity/PopulationSize
return Diversity
def __SinX(self,params):
""" This is the one mentioned in the paper sin Method mapping This in the paper is from 0-4, That is to say 5 A parameter returns :param params: :return: """
res = []
for i in range(5):
tem_ = self.Math.sin(params*self.Math.pow(2,i))
res.append(tem_)
return res
def __cat(self,states,params):
for param in params:
states.append(param)
def GetStatus(self,Population):
""" In accordance with the requirements , Here we will implement the input of a state of the current particle swarm :return: """
self.F_iterate_num = self.Iterate_num / IterationsNumber
self.F_diversity = self.__GetDiversity(Population)
self.F_no_increase = (self.Iterate_num-self.F_no_increase_time)/IterationsNumber
# At this time, we pass through this sin Function to map
self.F_iterate_num = self.__SinX(self.F_iterate_num)
self.F_diversity = self.__SinX(self.F_diversity)
self.F_no_increase = self.__SinX(self.F_no_increase)
states = []
self.__cat(states,self.F_iterate_num);self.__cat(states,self.F_diversity);self.__cat(states,self.F_no_increase)
return states
def ChangeBird(self,bird,Population):
# This is mainly to implement the tournament method to update the particle tracking object
while True:
# The tracked particle cannot be the same as itself , It can't be the same as the last one
a,b = random.sample(range(PopulationSize),2)
a = Population[a];b=Population[b]
follow = a
if(a.PbestY>b.PbestY):
follow = b
if(follow.ID!=bird.ID):
if(bird.Follow):
if(bird.Follow.ID !=follow.ID):
bird.Follow = follow
return
else:
bird.Follow = follow
return
def __PCi(self,i,ps):
""" In the thesis PCi The operator of :return: """
pci = 0.05+0.45*((self.Math.exp(10*(i-1)/(ps-1)))/(self.Math.exp(10)-1))
return pci
def NewComputeV(self,bird,params):
""" :param bird: :param params: The incoming data format is :[[w,c1,c2,c3],[],[],[],[]] Here is 5 The group has a total of 100 A particle :return: Here, according to ID To call different parameters in the order of """
NewV = []
w, c1, c2, c3 = params[self.Count_Div]
if(bird.ID%ClusterSize==0):
if(self.Count_Div<ClusterNumber-1):
self.Count_Div+=1
for i in range(DIM):
v = bird.V[i]*w
if(self.Random()<self.__PCi((i+1),PopulationSize)):
pbestfi = bird.PBestX[i]
else:
pbestfi=bird.PBestX[i]
v=v+c1*self.Random()*(pbestfi-bird.X[i])+c2*self.Random()*(bird.GBestX[i]-bird.X[i])\
+c3*self.Random()*(bird.PBestX[i]-bird.X[i])
if(v>V_max):
v = V_max
elif(v<V_min):
v = V_min
NewV.append(v)
return NewV
def NewComputeX(self,bird:Bird,params):
NewX = []
NewV = self.NewComputeV(bird,params)
bird.V = NewV
for i in range(DIM):
x = bird.X[i]+NewV[i]
if(x>X_up):
x = X_up
elif(x<X_down):
x = X_down
NewX.append(x)
return NewX
def ComputeV(self,bird):
# This method is used to calculate the velocity drop
# Now this calculation of the particle swarm V The algorithm needs to be changed , But it won't change much .
NewV=[]
for i in range(DIM):
v = bird.V[i]*self.W_RL + self.C1_RL*self.Random()*(bird.PBestX[i]-bird.X[i])\
+self.C2_RL*self.Random()*(bird.GBestX[i]-bird.X[i])
# Here, pay attention to judge whether it is beyond the scope
if(v>V_max):
v = V_max
elif(v<V_min):
v = V_min
NewV.append(v)
return NewV
def ComputeX(self,bird:Bird):
NewX = []
NewV = self.ComputeV(bird)
bird.V = NewV
for i in range(DIM):
x = bird.X[i]+NewV[i]
if(x>X_up):
x = X_up
elif(x<X_down):
x = X_down
NewX.append(x)
return NewX
def InitPopulation(self):
# Initial population
GBestX = [0. for _ in range(DIM)]
Flag = float("inf")
for bird in self.Population:
bird.PBestX = bird.X
bird.Y = self.target.SquareSum(bird.X)
bird.PbestY = bird.Y
if(bird.Y<=Flag):
GBestX = bird.X
Flag = bird.Y
# After the convenience, we get the globally optimal population
self.GBestY = Flag
for bird in self.Population:
bird.GBestX = GBestX
bird.GBestY = Flag
self.Iterate_num+=1
def InitPopulationRL(self):
# Initial population , It's just for ENV Called , Because there is one in this CLPSO Thought
GBestX = [0. for _ in range(DIM)]
Flag = float("inf")
for bird in self.Population:
bird.PBestX = bird.X
bird.Y = self.target.SquareSum(bird.X)
bird.PbestY = bird.Y
if(bird.Y<=Flag):
GBestX = bird.X
Flag = bird.Y
# After the convenience, we get the globally optimal population
self.GBestY = Flag
for bird in self.Population:
bird.GBestX = GBestX
bird.GBestY = Flag
# Now it's initialization , So this is no problem
self.GBestYLast = Flag
# Find a follower for each particle
self.ChangeBird(bird,self.Population)
def Running(self):
""" This method is used to run the basic version normally PSO Algorithm There is no need to delete these algorithms , At least we can make a comparison :return: """
for iterate in range(1,IterationsNumber+1):
w = LinearW(iterate)
# This is a good one GBestX In fact, it is always the best thing in the next round
GBestX = [0. for _ in range(DIM)]
Flag = float("inf")
for bird in self.Population:
# Change to linear weight
self.W_RL = w
x = self.ComputeX(bird)
y = self.target.SquareSum(x)
# Here we still need to be more detailed unconditionally , Otherwise, here C1 Is failure
# if(y<=bird.Y):
# bird.X = x
# bird.Y = y
bird.X = x
bird.Y = y
if(bird.Y<=bird.PbestY):
bird.PBestX=bird.X
bird.PbestY = bird.Y
# The best in an individual must contain the best that the whole world has experienced
if(bird.PbestY<=Flag):
GBestX = bird.PBestX
Flag = bird.PbestY
for bird in self.Population:
bird.GBestX = GBestX
bird.GBestY=Flag
if __name__ == '__main__':
start = time.time()
basePso = NewPsoRL()
basePso.InitPopulation()
basePso.Running()
end = time.time()
# for bird in basePso.Population:
# print(bird)
print(basePso.Population[0])
print(" It takes a long time :",end-start)
This class actually has two functions , One is the traditional particle swarm optimization algorithm , For each time, a traditional particle swarm optimization algorithm is encapsulated here , Then there are some methods of transformation based on the paper , Then this part of the call is called through other classes . This thing can be extracted , But there are also repetitions ( And basic particle swarm optimization ) So I didn't extract it separately .
To configure
There is also a unified configuration center for control .
But there are still some things I haven't extracted from this configuration , I'm too lazy .
#coding=utf-8
# The setting of relevant parameters is completed through the configuration center
import sys
import os
sys.path.append(os.path.abspath(os.path.dirname(os.getcwd())))
C1=2.0
C2=2.0
C3=2.0
# If more than four rounds have not been updated , Then you need to choose another one follow For the current particle
M_follow = 4
W = 0.4
# Dimensions defined under a single objective
DIM =5
# function 1000 Time ( It can be understood as training 1 This particle swarm will run a thousand times )
IterationsNumber = 1000
X_down = -10.0
X_up = 10
V_min = -5.0
V_max = 5
# This is the description according to the paper , It is divided into 5 Group ,100 A particle is added after itself
ClusterSize = 20
ClusterNumber = 5
EPOCH = 20 # Training N round
PopulationSize = 100
def LinearW(iterate):
# Number of incoming iterations
Wmax = 0.9
Wmin = 0.4
w = Wmax-(iterate*((Wmax-Wmin)/IterationsNumber))
return w
Training to achieve
Then the next step is how to realize the training part of the thesis .
Because the thesis also says that you should pre train first , So you understand .
Definition of neural network
Here we want to realize this thing , We need to define two neural networks first .
class Actor(nn.Module):
""" Input three parameters to generate the action network """
def __init__(self,state):
super(Actor, self).__init__()
self.fc1 = nn.Linear(state,64)
self.fc1.weight.data.normal_(0, 0.1)
self.fc2 = nn.Linear(64,64)
self.fc2.weight.data.normal_(0, 0.1)
self.fc3 = nn.Linear(64,64)
self.fc3.weight.data.normal_(0,0.1)
# This is different from what the broken paper said , It should actually be 20 No 25
self.out = nn.Linear(64,20)
self.out.weight.data.normal_(0, 0.1)
def forward(self,x):
x = self.fc1(x)
x = F.leaky_relu(x)
x = self.fc2(x)
x = F.leaky_relu(x)
x = self.fc3(x)
x = F.leaky_relu(x)
x = self.out(x)
x = torch.tanh(x)
return x
class Critic(nn.Module):
""" This is Critic The Internet (DQN) """
def __init__(self,state_action):
super(Critic,self).__init__()
self.fc1 = nn.Linear(state_action,64)
self.fc1.weight.data.normal_(0,0.1)
self.fc2 = nn.Linear(64,64)
self.fc2.weight.data.normal_(0,0.1)
self.fc3 = nn.Linear(64,32)
self.fc3.weight.data.normal_(0,0.1)
self.fc4 = nn.Linear(32,32)
self.fc4.weight.data.normal_(0,0.1)
self.fc5 = nn.Linear(32,16)
self.fc5.weight.data.normal_(0,0.1)
self.out = nn.Linear(16,1)
self.out.weight.data.normal_(0,0.1)
def forward(self,x):
x = self.fc1(x)
x = F.leaky_relu(x)
x = self.fc2(x)
x = F.leaky_relu(x)
x = self.fc3(x)
x = F.leaky_relu(x)
x = self.fc4(x)
x = F.leaky_relu(x)
x = self.fc4(x)
x = F.leaky_relu(x)
x = self.fc5(x)
x = F.leaky_relu(x)
x = self.out(x)
return x
This is one of the papers , It's just actor It should be 20 Outputs , instead of 25.
Loss function
This loss function is actually the same as that DDPG The same as , Do not have what difference .

Preparation of environment
This environment is actually with PSO The algorithm is deeply bound , In fact, it is easy to write , Because according to the framework of reinforcement learning , You just need to achieve ,getRward() and reset() Method , Basically, these two methods are enough , One way to get the current situation , Reward for action , And the state of the next step ,reset It is directly initialized , Return to the current state .
""" be based on PSO Algorithm design environment , Make it bigger here , Now? Is based on PSO, You can join later GA,EDA And so on """
from ONEPSO.RLPSOEmersion.PSORL import NewPsoRL
from ONEPSO.RLPSOEmersion.ConfigRL import *
class ENV(object):
def __init__(self):
self.PsoRL = NewPsoRL()
def GetReward(self,state,action,i=0):
""" Enter the current state and action Return a score This score is actually obtained through calculation , And the state is also like this :param state: This state Actually, it doesn't work here , It's just that it was designed like this :param action: Notice the action Is the parameter after translation It looks like this [[],[],[],[],[]] :return: Next status and current rewards """
# This is a good one GBestX In fact, it is always the best thing in the next round
GBestX = [0. for _ in range(DIM)]
Flag = float("inf")# This is used to record the global optimal solution
CurrentBest = float("inf")
for bird in self.PsoRL.Population:
x = self.PsoRL.NewComputeX(bird,action)
y = self.PsoRL.target.SquareSum(x)
bird.X = x
bird.Y = y
if (bird.Y < bird.PbestY):
bird.PBestX = bird.X
bird.PbestY = bird.Y
elif(bird.Y==bird.PbestY):
bird.NoChange+=1
if(bird.NoChange==M_follow):
self.PsoRL.ChangeBird(bird,self.PsoRL.Population)
bird.NoChange=0
# The best in an individual must contain the best that the whole world has experienced
# Here is the search for the global optimal solution of the current round
if (bird.PbestY < Flag):
GBestX = bird.PBestX
Flag = bird.PbestY
# Select the best solution of the current number ( overall situation )
if(bird.Y<CurrentBest):
CurrentBest = bird.Y
# This code is used to determine the downtime
if(self.PsoRL.GBestY==Flag and not self.PsoRL.NoChangeFlag):
self.PsoRL.F_no_increase_time = i
self.PsoRL.NoChangeFlag = True
elif(self.PsoRL.GBestY!=Flag and self.PsoRL.NoChangeFlag):
self.PsoRL.F_no_increase_time = i
self.PsoRL.NoChangeFlag = False
elif(self.PsoRL.GBestY!=Flag and not self.PsoRL.NoChangeFlag):
self.PsoRL.F_no_increase_time = i
self.PsoRL.GBestY = Flag
for bird in self.PsoRL.Population:
bird.GBestX = GBestX
bird.GBestY = Flag
# here Flag It stores the solution value of the current global optimal solution
self.PsoRL.Iterate_num += 1
if(self.PsoRL.GBestYLast<CurrentBest):
R = 1
else:
R = -1
self.PsoRL.GBestYLast = CurrentBest
next_state = self.PsoRL.GetStatus(self.PsoRL.Population)
return next_state, R
def reset(self):
""" Complete the initialization operation :return: """
self.PsoRL.InitPopulationRL()
return self.PsoRL.GetStatus(self.PsoRL.Population)
Acquisition of state
This is actually one of the key points of the environment .
So this is also based on the thesis , Get three parameters , The current number of iterations , Current dispersion , Is the longest length of the latest idling
This part is actually in the front PSORL Realized . Look inside Notes should be known .
And here? Except for the middle one, it's troublesome to deal with , The others are simple to handle .
def __GetDiversity(self,Population):
# First calculate the average
x_pa = [0 for _ in range(DIM)]
for bird in Population:
for i in range(DIM):
x_pa[i]+=bird.X[i]
for i in range(DIM):
x_pa[i]/=PopulationSize
# Now calculate Diversity
Diversity = 0.
for bird in Population:
sum = 0
for i in range(DIM):
sum+=abs(bird.X[i]-x_pa[i])
Diversity+=self.Math.sqrt(sum)
Diversity = Diversity/PopulationSize
return Diversity

As for the current number of iterations , I don't think I have to say that , incoming i What is it ( In fact, of course , I didn't design that parameter at first i( The meaning of the lockout was misunderstood at the beginning , After reading my blog carefully, I realized , Is the longest length of the latest idling ), myself PSORL There is a counter ).
Preparation of awards
This is even simpler .
direct :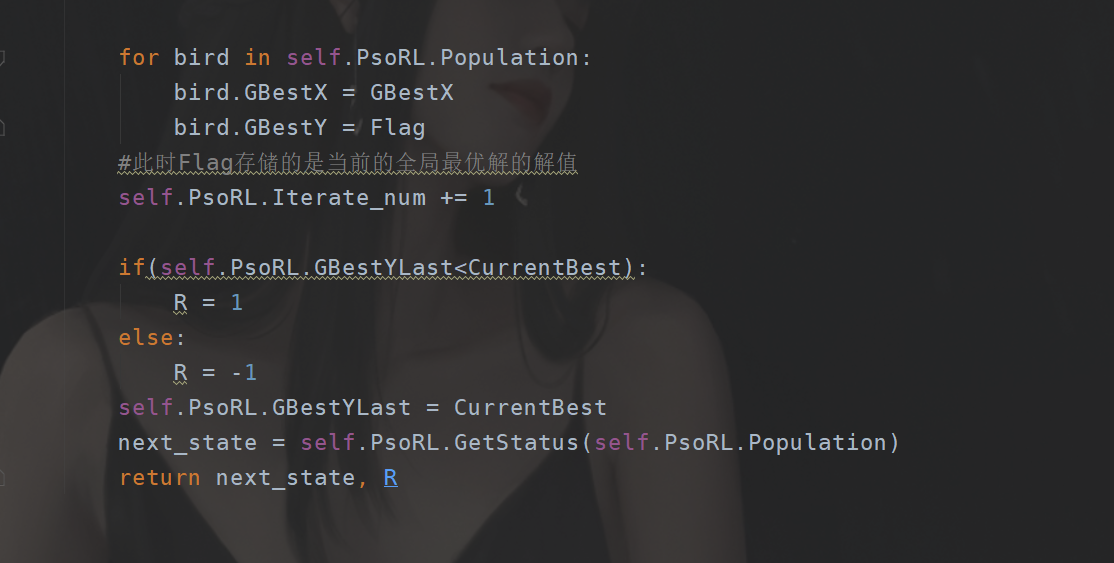
Objective function
Our particle swarm optimization needs this function to be optimized . The functions to be optimized here are also encapsulated in Target Inside .
#coding=utf-8
# This gadget is used to define functions that need to be optimized
import sys
import os
sys.path.append(os.path.abspath(os.path.dirname(os.getcwd())))
class Target(object):
def SquareSum(self,X):
res = 0
for x in X:
res+=x*x
return res
Training
It's time for training .
Now look into this thing .
It contains actor and critic Training for .
class DDPGNetWorkPSO(object):
""" Provide model training , Model preservation , Model loading function , Model call function """
def __init__(self,N_state,N_action):
""" :param state: This is the current PSO Dimension of state ( The length of putting those three parameters together ) :param state_action: This is the output action , In this case , It should be to convert w c1 c2 Otherwise, the environment is difficult to score ( Again here is the length ) """
self.N_Status = N_state
self.N_action = N_action
self.GAMMA = 0.9
self.ENV = ENV()
self.LR_actor = 0.0001
self.LR_critic = 0.0001
self.MEMORY_CAPACITY_CRITIC = 100 # The size of the memory is 100
self.TARGET_REPLACE_ITER = 10 # Set up here 10 One change at a time
self.BATCH_SIZE_CRITIC = 20 # One Batchsize Size is 20
self.Env = ENV()
self.actor = Actor(self.N_Status)
self.eval_net_critic, self.target_net_critic = Critic(self.N_Status+self.N_action), Critic(self.N_Status+self.N_action)
self.opt_actor = torch.optim.Adam(self.actor.parameters(), lr=self.LR_actor)
self.opt_critic = torch.optim.Adam(self.eval_net_critic.parameters(), lr=self.LR_critic)
self.LearnStepCount = 0
self.MemoryCount = 0 # Recorded several memories
""" from 0-statu Is the current and then reward, Then the next one """
self.Memory = np.zeros((self.MEMORY_CAPACITY_CRITIC, self.N_Status * 2 + self.N_action+1)) # Initialize memory
#(s, [a, r], s_) The best action corresponds to reward
self.loss_func_critic = nn.MSELoss() # The square difference is used here
def Remember(self, s, a, r, s_):
# This is our memory
transition = np.hstack((s, a.detach().numpy(), [r], s_))
index = self.MemoryCount % self.MEMORY_CAPACITY_CRITIC
self.Memory[index, :] = transition
self.MemoryCount += 1
def Train_Critic(self):
""" :s_a: This parameter is Status and Action Integrated parameters ,DQN There is a temporary cache table , It will not update until the cache is satisfied But our Actor The Internet is not ( After a round of particle training, it needs to be updated , Then store s a r s_next This is the training method , Responsible for completing the current Critic Network training :return: """
if self.LearnStepCount % self.TARGET_REPLACE_ITER == 0:
self.target_net_critic.load_state_dict(self.eval_net_critic.state_dict())
self.LearnStepCount += 1
# Select memory
SelectMemory = np.random.choice(self.MEMORY_CAPACITY_CRITIC, self.BATCH_SIZE_CRITIC)
selectM = self.Memory[SelectMemory, :]
S_s = torch.FloatTensor(selectM[:, :self.N_Status])
S_a = torch.LongTensor(selectM[:, self.N_Status:self.N_Status+self.N_action].astype(int))
S_r = torch.FloatTensor(selectM[:, self.N_Status+self.N_action:self.N_Status+self.N_action+1])
S_s_ = torch.FloatTensor(selectM[:, -self.N_Status:])
# This step got us a batch_size The best value of ( The best )
real_input = torch.cat([S_s,S_a],dim=1)
q_eval = self.eval_net_critic(real_input)
# q_eval = q_eval.gather(1,S_a)
# # Get the value of the corresponding action in non transposed order , But the paper here suggests that , The output value is 1, Not the size of the action
# This is the value corresponding to the next action
S_a_ = self.actor(S_s_)
# The dimension of the action output here is 20,
b = torch.normal(mean=torch.full((self.BATCH_SIZE_CRITIC, 20), 0.0), std=torch.full((self.BATCH_SIZE_CRITIC, 20), 0.5))
S_a_ = S_a_+ b
next_input = torch.cat([S_s_,S_a_],dim=1)
q_next = self.target_net_critic(next_input).detach()
# Update our Q The Internet
# shape (batch, 1)
q_target = S_r + self.GAMMA * q_next.max(1)[0].view(self.BATCH_SIZE_CRITIC, 1)
loss = self.loss_func_critic(q_eval, q_target)
self.opt_critic.zero_grad()
loss.backward()
self.opt_critic.step()
def TranslateAction(self,actions):
""" Now I'm going to put action Turn into 5 Group parameters , So we can give the particle swarm feedback :param actions: :return: [[],[],[],[],[]] """
length = 4
params = []
a = []
for i in range(1,len(actions)+1):
a.append(actions[i-1])
if(i%length==0):
w = a[0]*0.8 +0.1
scale = 1/(a[1]+a[2]+0.00001)*a[3]*8
c1 = scale*a[1]
c2 = scale*a[2]
c3 = scale*a[3]
temp = [w,c1,c2,c3]
params.append(temp)
a = []
return params
def SavaMould(self,net,path):
""" Save network , Enter a path , Automatically save two :return: """
torch.save(net.state_dict(), path)
def LoadMould(self,path_actor,path_critic):
""" This will return two loaded networks :return: """
self.actor.load_state_dict(torch.load(path_actor))
self.eval_net_critic.load_state_dict(torch.load(path_critic))
def LoadMouldActor(self,path_actor):
""" load Actor The Internet :return: """
self.actor.load_state_dict(torch.load(path_actor))
def LoadMouldCritic(self,path_critic):
""" load Critic The Internet :return: """
self.eval_net_critic.load_state_dict(torch.load(path_critic))
def TrainPSORL(self):
""" This part is used to complete our whole PSO Of the training code :return: """
state = self.Env.reset()
for epoch in range(1,EPOCH+1):
for i in range(1,IterationsNumber+1):
# It's done here Actor and Critic Training for
state_ = torch.tensor(state, dtype=torch.float)
out_actor = self.actor(state_)
out_actor = out_actor + torch.normal(mean=torch.full((1, 20), 0.0), std=torch.full((1, 20), 0.5))[0]
in_critic_ = torch.cat([state_,out_actor])
loss = -self.eval_net_critic(in_critic_)
self.opt_actor.zero_grad()
loss.backward()
self.opt_actor.step()
a = out_actor.tolist()
a = self.TranslateAction(a)
s_, r =self.Env.GetReward(state, a,i)
# Here are training updates Critic The Internet
self.Remember(state,out_actor,r,s_)
if (self.MemoryCount > self.MEMORY_CAPACITY_CRITIC):
self.Train_Critic()
state = s_
print(" Executing the ",epoch," The first of the rounds ",i," Time training !")
self.SavaMould(self.actor,"./module/actor.pth")
self.SavaMould(self.eval_net_critic,"./module/critic.pth")
print(" The model is saved !")
After the training , You will see your weight file here 
RLPSO
Finally, it's time to call .

""" This part of the code is used to call the trained Actor The Internet Then form a real RLPSO Algorithm , The code here is actually the same as ENV The writing of is very similar to """
import torch
from ONEPSO.RLPSOEmersion.ConfigRL import *
from ONEPSO.RLPSOEmersion.ENV import ENV
from ONEPSO.RLPSOEmersion.DDPGNetwoekPSO import DDPGNetWorkPSO
class RLPSOGo(object):
env = ENV()
ddpg = DDPGNetWorkPSO(15,20)
def __init__(self,path_actor):
self.ddpg.LoadMouldActor(path_actor)
def __get_params(self,state):
""" :param state: Passed in by the current ENV(PSO) The state of return :return: """
state_ = torch.tensor(state, dtype=torch.float)
out_actor = self.ddpg.actor(state_)
out_actor = out_actor.tolist()
out_actor = self.ddpg.TranslateAction(out_actor)
return out_actor
def RUNINGRLPSO(self):
""" Here is RLPSO start-up , And environmental GETReward It's kind of similar :return: """
state = self.env.reset()
for i in range(1,IterationsNumber+1):
out_params = self.__get_params(state)
# In fact, these two s_,r,r It doesn't work here , I just want to run PSORL
s_,r = self.env.GetReward(state,out_params,i)
# This is the next round
state = s_
print(" The current number of iterations is :",i," The best adaptive value is %.2e"%self.env.PsoRL.GBestY)
if __name__ == '__main__':
rLPso = RLPSOGo("./module/actor.pth")
rLPso.RUNINGRLPSO()
summary
There is nothing like mathematics itself , Just understand , It's easy to do. . After all, it's easier to write code .
边栏推荐
- Two fresh students: one is practical and likes to work overtime, and the other is skilled. How to choose??
- Is it safe to open an account on great wisdom
- 使用.Net驱动Jetson Nano的OLED显示屏
- EasyCVR服务private.pem文件被清空,导致无法正常启动该如何处理?
- WPF 实现心电图曲线绘制
- 【SV 基础】queue 的一些用法
- Streaming media cluster application and configuration: how to deploy multiple easycvr on one server?
- 深度优先搜索实现抓牛问题
- Uvm:factory mechanism
- If you can play these four we media operation tools, the sideline income of 6000+ is very easy
猜你喜欢

What is redis
How to solve the problem of Caton screen when easycvr plays video?

What is the difference between the histology and western blotting 两种方法都是进行组织染色的

IT治理方面的七个错误,以及如何避免

接雨水系列问题

Esmm reading notes

Report on the convenient bee Lantern Festival: the first peak sales of pasta products this year; prefabricated wine dumplings became the winners

Easycvr service private What should I do if the PEM file is emptied and cannot be started normally?
![[eight part essay] MySQL](/img/8e/719149fb49f1850baf5bab343955bf.jpg)
[eight part essay] MySQL
Pytorch -- use and modification of existing network model
随机推荐
be based on. NETCORE development blog project starblog - (13) add friendship link function
[MCU club] design of classroom number detection based on MCU [physical design]
Notes on the infrastructure of large websites
Is l1-031 too fat (10 points)
Precautions for installation and use of rotary joint
Baidu online disk login verification prompt: unable to access this page, or the QR code display fails, the pop-up window shows: unable to access this page, ensure the web address....
Do280 allocating persistent storage
Bug risk level
【图像增强】基于matlab人工多重曝光融合AMEF图像去雾【含Matlab源码 1916期】
Browser cache library design summary (localstorage/indexeddb)
Xuetong denies that the theft of QQ number is related to it: it has been reported; IPhone 14 is ready for mass production: four models are launched simultaneously; Simple and elegant software has long
How to handle a SIGTERM - how to handle a SIGTERM
Is it safe and reliable for qiniu school to help open a securities account? How to drive
机器视觉系统的配件及工作过程
GUI Graphical user interface programming example - color selection box
Large-scale case applications to developing post-click conversion rate estimation with MTL
利用kubernetes资源锁完成自己的HA应用
[staff] accent mark, gradually stronger mark and gradually weaker mark
Is the fund reliable and safe
How to calculate the income tax of foreign-funded enterprises