当前位置:网站首页>【Attention】Dual Attention(DANet) & Fully Attention(FLA)
【Attention】Dual Attention(DANet) & Fully Attention(FLA)
2022-08-04 08:08:00 【m0_61899108】
空间注意力有助于保留细节信息,通道注意力有助于保留大物体的语义一致性。
有效使用两种注意力可以提升性能。
本文旨在记录一些常用的注意力,以及代码实现,包括两篇文章,DANet,FLA。
Dual Attention Network for Scene Segmentation,CVPR2019
论文地址:https://arxiv.org/abs/1809.02983
项目地址:GitHub - junfu1115/DANet: Dual Attention Network for Scene Segmentation (CVPR2019)
参考博客:DANet论文及代码阅读笔记_IronLavender的博客-CSDN博客_danet
DANet(双重注意力融合网络)_Nick Blog的博客-CSDN博客_danet
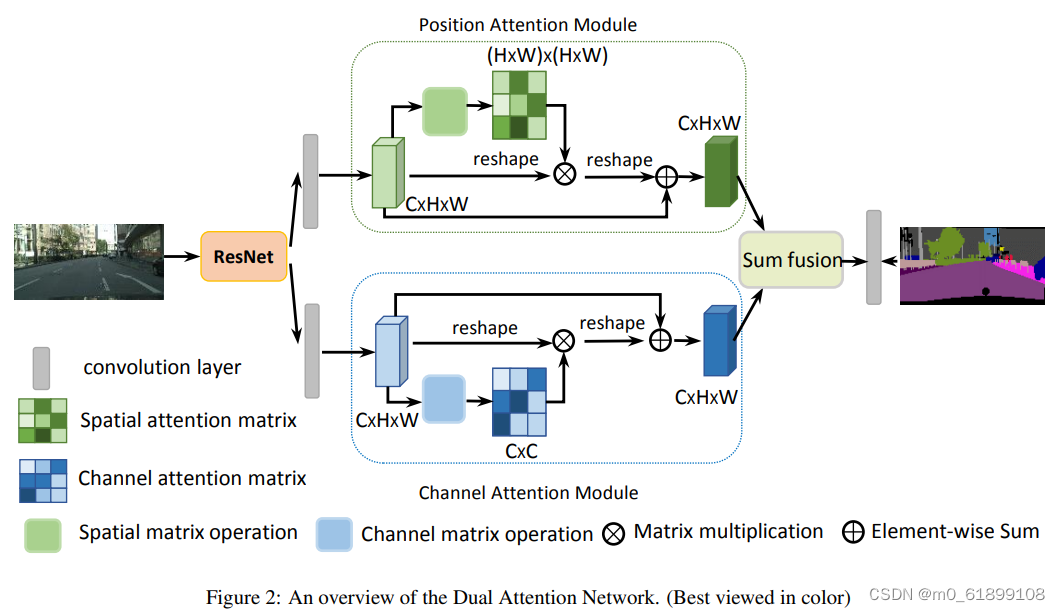
DANet,两条分支并联使用空间注意力和通道注意力,增强特征表示。
- position attention module使用自注意力机制捕获特征图在任意两个位置之间的空间依赖关系,通过加权求和对所有位置的特征进行聚合更新,权重是由对应两个位置的特征相似性决定的。
- Channel attention module使用自注意力机制来捕获任意两个通道图之间的通道依赖关系,并使用所有通道图的加权,和更新每个通道图。
- DANet对这两个注意力模块的输出进行融合,进一步增强了特征表示。
Architecture:(DANet)
PAM
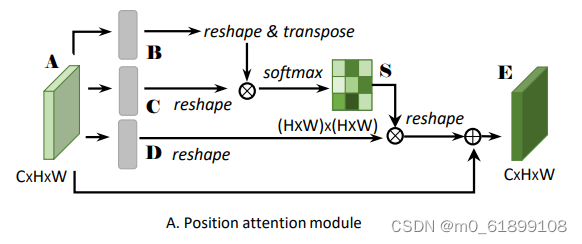
观察:传统FCNs生成的特征会导致对物体的错误分类。
解决:引入位置注意模块在局部特征上建立丰富的上下文关系,将更广泛的上下文信息编码为局部特征,进而增强他们的表示能力。
- 特征图A(C×H×W)首先分别通过3个卷积层得到3个特征图B,C,D,然后将B,C,D reshape为C×N,其中N=H×W。
- 之后将reshape后的B的转置(NxC)与reshape后的C(CxN)相乘,再通过softmax得到spatial attention map S(N×N)。
- 接着在reshape后的D(CxN)和S的转置(NxN)之间执行矩阵乘法,再乘以尺度系数α,再reshape为原来形状,最后与A相加得到最后的输出E。
- 其中α初始化为0,并逐渐的学习得到更大的权重。
CAM
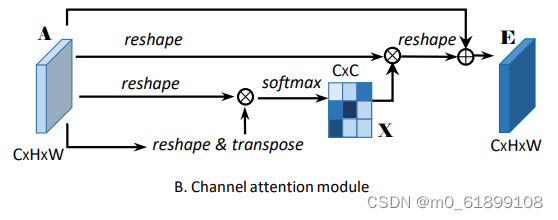
观察:每个high level特征的通道图都可以看作是一个特定于类的响应,通过挖掘通道图之间的相互依赖关系,可以突出相互依赖的特征图,提高特定语义的特征表示。
解决:建立一个通道注意力模块来显式地建模通道之间的依赖关系。
- 分别对A做reshape(CxN)和reshape与transpose(NxC)。
- 将得到的两个特征图相乘,再通过softmax得到channel attention map X(C×C)。
- 接着把X的转置(CxC)与reshape的A(CxN)做矩阵乘法,再乘以尺度系数β,再reshape为原来形状,最后与A相加得到最后的输出E。
- 其中β初始化为0,并逐渐的学习得到更大的权重。
代码
# https://github.com/junfu1115/DANet/blob/master/encoding/models/sseg/danet.py
# 调用方式:
# self.head = DANetHead(2048,nclass,norm_layer) # norm_layer默认 nn.BatchNorm2d
# features = self.head(x) # x 输入特征 [b,c,h,w]
class DANetHead(nn.Module):
def __init__(self, in_channels, out_channels, norm_layer):
super(DANetHead, self).__init__()
inter_channels = in_channels // 4
self.conv5a = nn.Sequential(nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels),
nn.ReLU())
self.conv5c = nn.Sequential(nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels),
nn.ReLU())
self.sa = PAM_Module(inter_channels)
self.sc = CAM_Module(inter_channels)
self.conv51 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels),
nn.ReLU())
self.conv52 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels),
nn.ReLU())
self.conv6 = nn.Sequential(nn.Dropout2d(0.1, False), nn.Conv2d(inter_channels, out_channels, 1))
self.conv7 = nn.Sequential(nn.Dropout2d(0.1, False), nn.Conv2d(inter_channels, out_channels, 1))
self.conv8 = nn.Sequential(nn.Dropout2d(0.1, False), nn.Conv2d(inter_channels, out_channels, 1))
def forward(self, x):
feat1 = self.conv5a(x)
sa_feat = self.sa(feat1)
sa_conv = self.conv51(sa_feat)
sa_output = self.conv6(sa_conv)
feat2 = self.conv5c(x)
sc_feat = self.sc(feat2)
sc_conv = self.conv52(sc_feat)
sc_output = self.conv7(sc_conv)
feat_sum = sa_conv+sc_conv
sasc_output = self.conv8(feat_sum)
output = [sasc_output]
output.append(sa_output)
output.append(sc_output)
return tuple(output)
Fully Attentional Network for Semantic Segmentation,AAAI2022
论文地址:https://arxiv.org/abs/2112.04108
项目地址:https://github.com/Ilareina/FullyAttentional
参考博客:【语义分割】Fully Attentional Network for Semantic Segmentation_呆呆的猫的博客-CSDN博客
精读Fully Attentional Network for Semantic Segmentation_格里芬阀门工的博客-CSDN博客
出发点&动机:以往的注意力机制,要么只关注同一空间不同通道的信息,要么只关注不同空间同一通道的信息,这会导致模型容易忽略小的对象,并错误分割较大的对象。本文提出了一种新的注意力机制,综合考虑两方面的信息。
具体来说,non-local (NL)的方法起到了很好了捕捉 long-range 信息的作用,大致可分为 Channel non-local 和 Spatial non-local 两种变种。但是他们却同时有一个问题——attention missing。
- 以 channel attention 为例:channel attention 能够找到每个通道和其他通道的关联,在计算的过程中,spatial 特征被整合了起来,缺失了不同位置之间的联系。
- 以 spatial attention 为例:spatial attention 能够找到每个位置之间的关系,但所有channel 的特征也都被整合了起来,缺失了不同 channel 之间的联系。
attention missing 问题会削弱三维上下文信息的存储,这两种 attention 方法都有各自的弊端。
论文也经过实验得出:
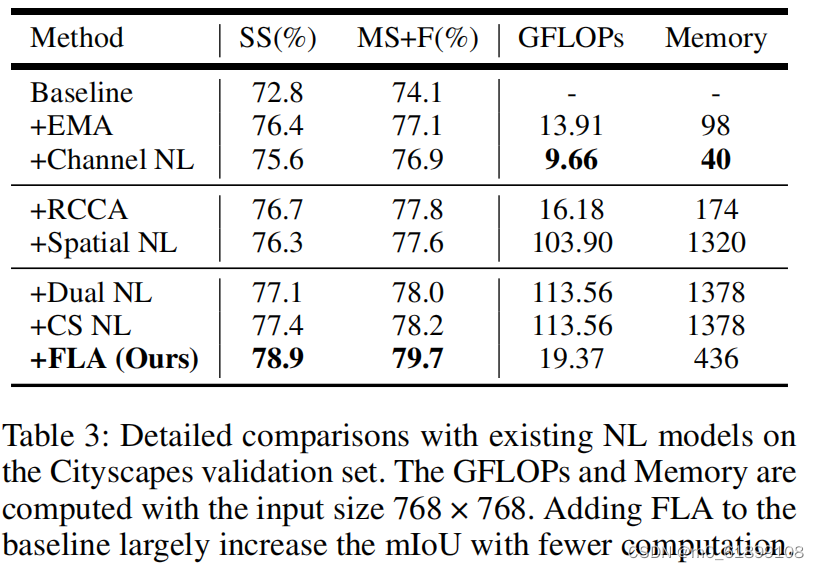
- channel NL 在大目标上表现好,spatial NL在小目标或细长目标表现较好。
- 简单堆叠两个注意力(并联,DANet(Dual NL) 或 串联,channel-spatial NL(CS NL)),能一定程度上提升整体性能。但相较而言,Dual NL在大尺寸目标上性能有所下降,CS NL在细长目标上IoU较差。
- 简单的复合attention结构,只能通过channel和spatial attention中的某一方来获得性能提升,所以,attention missing问题损害了特征的表示能力。
- 于是,论文提出了一个新的 non-local 模块——Fully Attention block(FLA)来在所有维度上进行有效的 attention 特征保留。

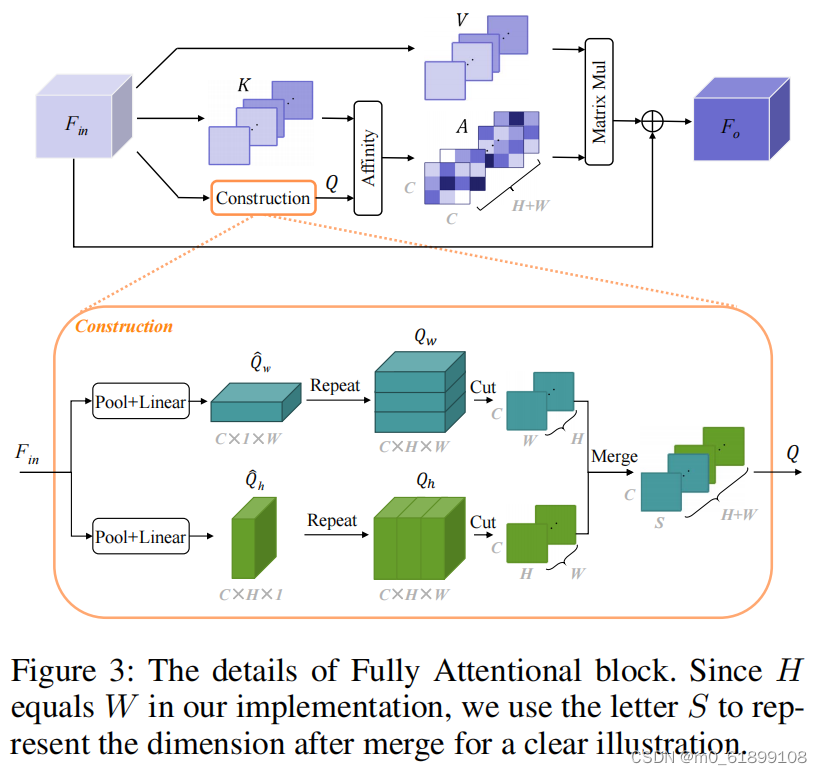
全文的基本思路在于:
在计算 channel attention map 时,使用全局上下文特征来保存空间响应特征,这能够使得在一个单一的 attention 中实现充分的注意并具有高的计算效率,图 1c 为整体结构。
- 首先,让每个空间位置来捕捉全局上下文的特征响应
- 之后,使用 self-attention 机制来捕捉两个 channel 之间和相应空间位置的全注意力相似度
- 最后,使用全注意力相似度来对 channel map 进行 re-weight。
① channel NL 的过程如图1a所示,生成的 attention map 为 C × C 大小,也就是每个通道和其他所有通道的注意力权重。
② spatial NL 的过程如图1b所示,生成的 attention map 为 H W × H W大小,也就是每个点和其他所有像素点的注意力权重。
③ FLA 的过程如图 1c 所示,生成的 attention map 为 ( C × C ) ( H + W ),其中 C × C 还是通道注意力权重,(H+W) 是每行(共H行)和每列(共W列)的注意力权重。
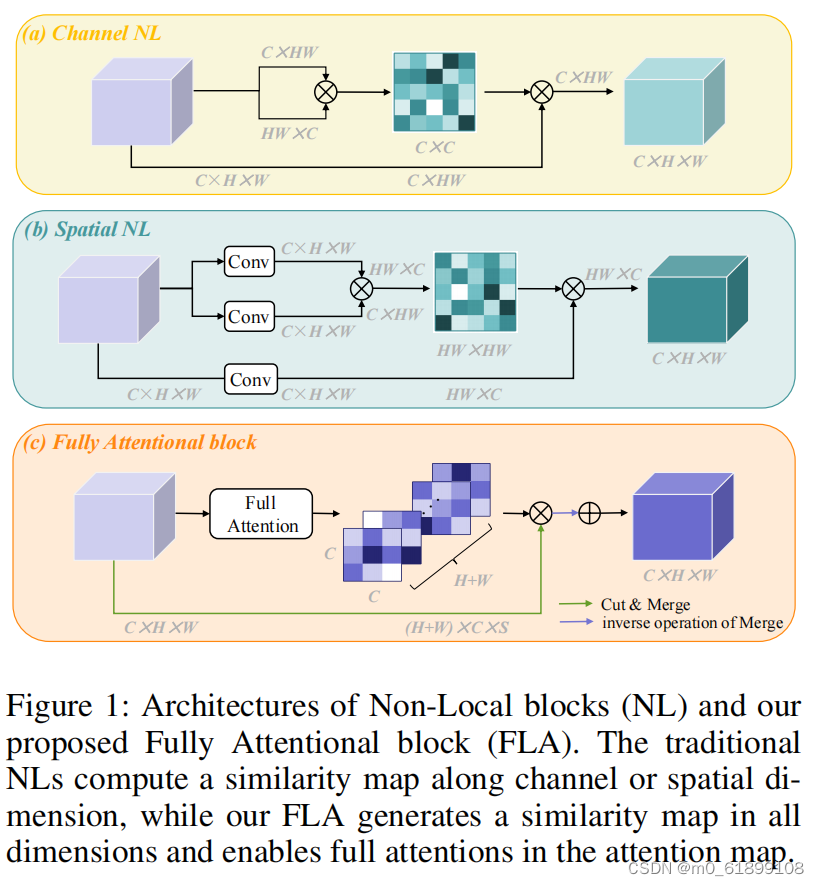
Architecture:Fully Attentional Block(FLA)



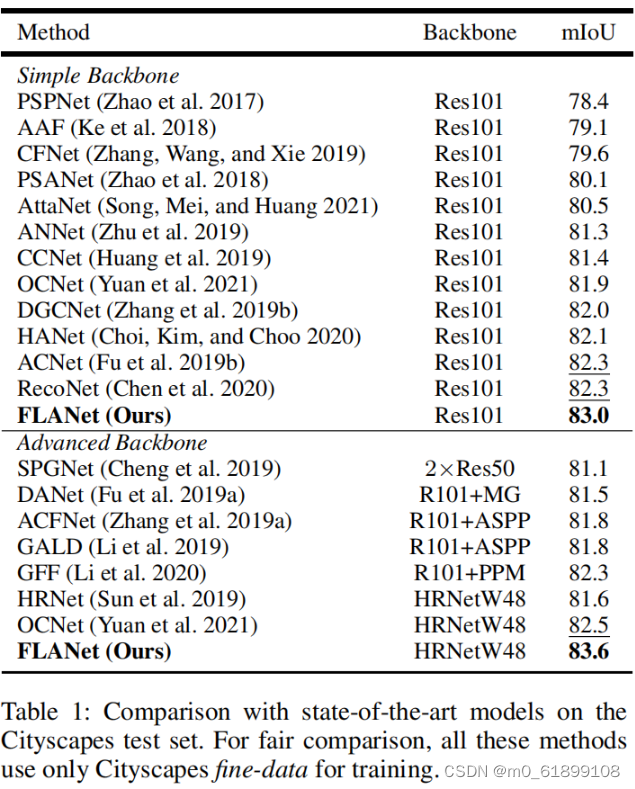
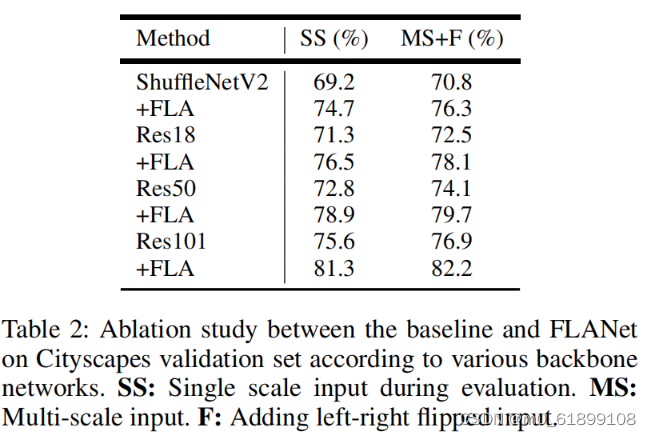
部分实验结果
代码
# https://github.com/Ilareina/FullyAttentional/blob/main/model.py
# 调用
# self.fully = FullyAttentionalBlock(512)
# full_feats = self.fully(x) # x,输入特征 [b,c,h,w]
class FullyAttentionalBlock(nn.Module):
def __init__(self, plane, norm_layer=SyncBatchNorm):
super(FullyAttentionalBlock, self).__init__()
self.conv1 = nn.Linear(plane, plane)
self.conv2 = nn.Linear(plane, plane)
self.conv = nn.Sequential(nn.Conv2d(plane, plane, 3, stride=1, padding=1, bias=False),
norm_layer(plane),
nn.ReLU())
self.softmax = nn.Softmax(dim=-1)
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self, x):
batch_size, _, height, width = x.size()
feat_h = x.permute(0, 3, 1, 2).contiguous().view(batch_size * width, -1, height)
feat_w = x.permute(0, 2, 1, 3).contiguous().view(batch_size * height, -1, width)
encode_h = self.conv1(F.avg_pool2d(x, [1, width]).view(batch_size, -1, height).permute(0, 2, 1).contiguous())
encode_w = self.conv2(F.avg_pool2d(x, [height, 1]).view(batch_size, -1, width).permute(0, 2, 1).contiguous())
energy_h = torch.matmul(feat_h, encode_h.repeat(width, 1, 1))
energy_w = torch.matmul(feat_w, encode_w.repeat(height, 1, 1))
full_relation_h = self.softmax(energy_h) # [b*w, c, c]
full_relation_w = self.softmax(energy_w)
full_aug_h = torch.bmm(full_relation_h, feat_h).view(batch_size, width, -1, height).permute(0, 2, 3, 1)
full_aug_w = torch.bmm(full_relation_w, feat_w).view(batch_size, height, -1, width).permute(0, 2, 1, 3)
out = self.gamma * (full_aug_h + full_aug_w) + x
out = self.conv(out)
return out
边栏推荐
- Distributed Computing Experiment 4 Random Signal Analysis System
- Recommend several methods that can directly translate PDF English documents
- 力扣 剑指 Offer 04. 二维数组中的查找
- 占位,稍后补上
- redis stream 实现消息队列
- 智汇华云 | 华云软件定义网络 DCI介绍
- 【虚幻引擎UE】UE5基于Gltf加载插件实现gltf格式骨骼动画在线/本地导入和切换
- Distributed Computing Experiment 2 Thread Pool
- 关于常用状态码4XX提示错误
- Detailed explanation of TCP protocol
猜你喜欢
IDEA引入类报错:“The file size (2.59 MB) exceeds the configured limit (2.56MB)

一天学会JDBC04:ResultSet的用法
秒懂大模型 | 3步搞定AI写摘要
Yolov5更换主干网络之《旷视轻量化卷积神经网络ShuffleNetv2》

data:image/jpg; base64 format data is converted to image
一天学会JDBC06:PrepaerdStatemtnt

高等代数_证明_两个矩阵乘积为0,则两个矩阵的秩之和小于等于n
研究性学习专题 3_LL(1)语法分析设计原理与实现
华为设备配置VRRP与路由联动监视上行链路
ShuffleNet v2 network structure reproduction (Pytorch version)
随机推荐
沃尔玛、阿里国际该如何做测评自养号?
经典动态规划问题的递归实现方法——LeetCode39 组合总和
高等代数_证明_对称矩阵属于不同特征值的特征向量正交
智能健身动作识别:PP-TinyPose打造AI虚拟健身教练!
解决:Hbuilder工具点击发行打包,一直报尚未完成社区身份验证,请点击链接xxxxx,项目xxx发布H5失败的错误。
ShuffleNet v2 network structure reproduction (Pytorch version)
TCP协议详解
分布式计算实验4 随机信号分析系统
此时已莺飞草长,愿世间美好与你环环相扣
2022的七夕,奉上7个精美的表白代码,同时教大家改源码快速自用
Yolov5 replaces the backbone network of "Megvii Lightweight Convolutional Neural Network ShuffleNetv2"
秒懂大模型 | 3步搞定AI写摘要
Lightweight Backbone VGNetG Achieves "No Choice, All" Lightweight Backbone Network
金仓数据库KingbaseES客户端编程接口指南-JDBC(10. JDBC 读写分离最佳实践)
智汇华云 | 华云软件定义网络 DCI介绍
GBase 8c数据库集群中,怎么替换节点呢?比如设置A节点为gtm,换到B节点上。
C Language Lectures from Scratch Part 6: Structure
JMeter 常用的几种断言方法,你会几种呢?
【论文笔记】—低照度图像增强—Supervised—RetinexNet—2018-BMVC
【我想要老婆】