当前位置:网站首页>Idea远程提交spark任务到yarn集群
Idea远程提交spark任务到yarn集群
2022-07-06 00:23:00 【南风知我意丿】
文章目录
1.本地idea远程提交到yarn集群
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010.{
ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{
Seconds, StreamingContext}
import org.apache.spark.{
SparkConf}
import spark.wordcount.kafkaStreams
object RemoteSubmitApp {
def main(args: Array[String]) {
// 设置提交任务的用户
System.setProperty("HADOOP_USER_NAME", "root")
val conf = new SparkConf()
.setAppName("WordCount")
// 设置yarn-client模式提交
.setMaster("yarn")
// 设置resourcemanager的ip
.set("yarn.resourcemanager.hostname","master")
// 设置executor的个数
.set("spark.executor.instance","2")
// 设置executor的内存大小
.set("spark.executor.memory", "1024M")
// 设置提交任务的yarn队列
.set("spark.yarn.queue","spark")
// 设置driver的ip地址
.set("spark.driver.host","192.168.17.1")
// 设置jar包的路径,如果有其他的依赖包,可以在这里添加,逗号隔开
.setJars(List("D:\\develop_soft\\idea_workspace_2018\\sparkdemo\\target\\sparkdemo-1.0-SNAPSHOT.jar"
))
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val scc = new StreamingContext(conf, Seconds(1))
scc.sparkContext.setLogLevel("WARN")
//scc.checkpoint("/spark/checkpoint")
val topic = "jason_flink"
val topicSet = Set(topic)
val kafkaParams = Map[String, Object](
"auto.offset.reset" -> "latest",
"value.deserializer" -> classOf[StringDeserializer]
, "key.deserializer" -> classOf[StringDeserializer]
, "bootstrap.servers" -> "master:9092,storm1:9092,storm2:9092"
, "group.id" -> "jason_"
, "enable.auto.commit" -> (true: java.lang.Boolean)
)
kafkaStreams = KafkaUtils.createDirectStream[String, String](
scc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicSet, kafkaParams))
kafkaStreams.foreachRDD(rdd=> {
if (!rdd.isEmpty()) {
rdd.foreachPartition(fp=> {
fp.foreach(f=> {
println(f.value().toString)
})
})
}
})
scc.start()
scc.awaitTermination()
}
}
然后我们直接右键运行,看下打印的日志
19/08/16 23:17:24 INFO SparkContext: Running Spark version 2.2.0
19/08/16 23:17:25 INFO SparkContext: Submitted application: WordCount
19/08/16 23:17:25 INFO SecurityManager: Changing view acls to: JasonLee,root
19/08/16 23:17:25 INFO SecurityManager: Changing modify acls to: JasonLee,root
19/08/16 23:17:25 INFO SecurityManager: Changing view acls groups to:
19/08/16 23:17:25 INFO SecurityManager: Changing modify acls groups to:
19/08/16 23:17:25 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(JasonLee, root); groups with view permissions: Set(); users with modify permissions: Set(JasonLee, root); groups with modify permissions: Set()
19/08/16 23:17:26 INFO Utils: Successfully started service 'sparkDriver' on port 62534.
19/08/16 23:17:26 INFO SparkEnv: Registering MapOutputTracker
19/08/16 23:17:26 INFO SparkEnv: Registering BlockManagerMaster
19/08/16 23:17:26 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
19/08/16 23:17:26 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
19/08/16 23:17:26 INFO DiskBlockManager: Created local directory at C:\Users\jason\AppData\Local\Temp\blockmgr-6ec3ae57-661d-4974-8bc9-7357ab4a0c06
19/08/16 23:17:26 INFO MemoryStore: MemoryStore started with capacity 4.1 GB
19/08/16 23:17:26 INFO SparkEnv: Registering OutputCommitCoordinator
19/08/16 23:17:26 INFO log: Logging initialized @2170ms
19/08/16 23:17:26 INFO Server: jetty-9.3.z-SNAPSHOT
19/08/16 23:17:26 INFO Server: Started @2236ms
19/08/16 23:17:26 INFO AbstractConnector: Started [email protected]{
HTTP/1.1,[http/1.1]}{
0.0.0.0:4040}
19/08/16 23:17:26 INFO Utils: Successfully started service 'SparkUI' on port 4040.
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/jobs,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/jobs/json,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/jobs/job,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/jobs/job/json,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/stages,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/stages/json,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/stages/stage,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/stages/stage/json,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/stages/pool,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/stages/pool/json,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/storage,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/storage/json,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/storage/rdd,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/storage/rdd/json,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/environment,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/environment/json,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/executors,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/executors/json,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/executors/threadDump,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/executors/threadDump/json,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/static,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/api,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/jobs/job/kill,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/stages/stage/kill,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://192.168.17.1:4040
19/08/16 23:17:26 INFO SparkContext: Added JAR D:\develop_soft\idea_workspace_2018\sparkdemo\target\sparkdemo-1.0-SNAPSHOT.jar at spark://192.168.17.1:62534/jars/sparkdemo-1.0-SNAPSHOT.jar with timestamp 1565968646369
19/08/16 23:17:27 INFO RMProxy: Connecting to ResourceManager at master/192.168.17.142:8032
19/08/16 23:17:27 INFO Client: Requesting a new application from cluster with 2 NodeManagers
19/08/16 23:17:27 INFO Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)
19/08/16 23:17:27 INFO Client: Will allocate AM container, with 896 MB memory including 384 MB overhead
19/08/16 23:17:27 INFO Client: Setting up container launch context for our AM
19/08/16 23:17:27 INFO Client: Setting up the launch environment for our AM container
19/08/16 23:17:27 INFO Client: Preparing resources for our AM container
19/08/16 23:17:28 WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
19/08/16 23:17:31 INFO Client: Uploading resource file:/C:/Users/jason/AppData/Local/Temp/spark-7ed16f4e-0f99-44cf-8553-b4541337d0f0/__spark_libs__5037580728569655338.zip -> hdfs://master:9000/user/root/.sparkStaging/application_1565990507758_0020/__spark_libs__5037580728569655338.zip
19/08/16 23:17:34 INFO Client: Uploading resource file:/C:/Users/jason/AppData/Local/Temp/spark-7ed16f4e-0f99-44cf-8553-b4541337d0f0/__spark_conf__5359714098313821798.zip -> hdfs://master:9000/user/root/.sparkStaging/application_1565990507758_0020/__spark_conf__.zip
19/08/16 23:17:34 INFO SecurityManager: Changing view acls to: JasonLee,root
19/08/16 23:17:34 INFO SecurityManager: Changing modify acls to: JasonLee,root
19/08/16 23:17:34 INFO SecurityManager: Changing view acls groups to:
19/08/16 23:17:34 INFO SecurityManager: Changing modify acls groups to:
19/08/16 23:17:34 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(JasonLee, root); groups with view permissions: Set(); users with modify permissions: Set(JasonLee, root); groups with modify permissions: Set()
19/08/16 23:17:34 INFO Client: Submitting application application_1565990507758_0020 to ResourceManager
19/08/16 23:17:34 INFO YarnClientImpl: Submitted application application_1565990507758_0020
19/08/16 23:17:34 INFO SchedulerExtensionServices: Starting Yarn extension services with app application_1565990507758_0020 and attemptId None
19/08/16 23:17:35 INFO Client: Application report for application_1565990507758_0020 (state: ACCEPTED)
19/08/16 23:17:35 INFO Client:
client token: N/A
diagnostics: AM container is launched, waiting for AM container to Register with RM
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: spark
start time: 1565997454105
final status: UNDEFINED
tracking URL: http://master:8088/proxy/application_1565990507758_0020/
user: root
19/08/16 23:17:36 INFO Client: Application report for application_1565990507758_0020 (state: ACCEPTED)
19/08/16 23:17:37 INFO Client: Application report for application_1565990507758_0020 (state: ACCEPTED)
19/08/16 23:17:38 INFO Client: Application report for application_1565990507758_0020 (state: ACCEPTED)
19/08/16 23:17:39 INFO Client: Application report for application_1565990507758_0020 (state: ACCEPTED)
19/08/16 23:17:40 INFO YarnSchedulerBackend$YarnSchedulerEndpoint: ApplicationMaster registered as NettyRpcEndpointRef(spark-client://YarnAM)
19/08/16 23:17:40 INFO YarnClientSchedulerBackend: Add WebUI Filter. org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter, Map(PROXY_HOSTS -> master, PROXY_URI_BASES -> http://master:8088/proxy/application_1565990507758_0020), /proxy/application_1565990507758_0020
19/08/16 23:17:40 INFO JettyUtils: Adding filter: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
19/08/16 23:17:40 INFO Client: Application report for application_1565990507758_0020 (state: ACCEPTED)
19/08/16 23:17:41 INFO Client: Application report for application_1565990507758_0020 (state: RUNNING)
19/08/16 23:17:41 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 192.168.17.145
ApplicationMaster RPC port: 0
queue: spark
start time: 1565997454105
final status: UNDEFINED
tracking URL: http://master:8088/proxy/application_1565990507758_0020/
user: root
19/08/16 23:17:41 INFO YarnClientSchedulerBackend: Application application_1565990507758_0020 has started running.
19/08/16 23:17:41 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 62586.
19/08/16 23:17:41 INFO NettyBlockTransferService: Server created on 192.168.17.1:62586
19/08/16 23:17:41 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
19/08/16 23:17:41 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 192.168.17.1, 62586, None)
19/08/16 23:17:41 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.17.1:62586 with 4.1 GB RAM, BlockManagerId(driver, 192.168.17.1, 62586, None)
19/08/16 23:17:41 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 192.168.17.1, 62586, None)
19/08/16 23:17:41 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 192.168.17.1, 62586, None)
19/08/16 23:17:41 INFO ContextHandler: Started o.s.j.s.[email protected]{
/metrics/json,null,AVAILABLE,@Spark}
19/08/16 23:17:44 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (192.168.17.145:40622) with ID 1
19/08/16 23:17:44 INFO BlockManagerMasterEndpoint: Registering block manager storm1:44607 with 366.3 MB RAM, BlockManagerId(1, storm1, 44607, None)
19/08/16 23:17:48 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (192.168.17.147:58232) with ID 2
19/08/16 23:17:48 INFO YarnClientSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.8
19/08/16 23:17:48 INFO BlockManagerMasterEndpoint: Registering block manager storm2:34000 with 366.3 MB RAM, BlockManagerId(2, storm2, 34000, None)
19/08/16 23:17:49 WARN KafkaUtils: overriding enable.auto.commit to false for executor
19/08/16 23:17:49 WARN KafkaUtils: overriding auto.offset.reset to none for executor
19/08/16 23:17:49 WARN KafkaUtils: overriding executor group.id to spark-executor-jason_
19/08/16 23:17:49 WARN KafkaUtils: overriding receive.buffer.bytes to 65536 see KAFKA-3135
看到提交成功了,然后我们打开yarn的监控页面看下有没有job。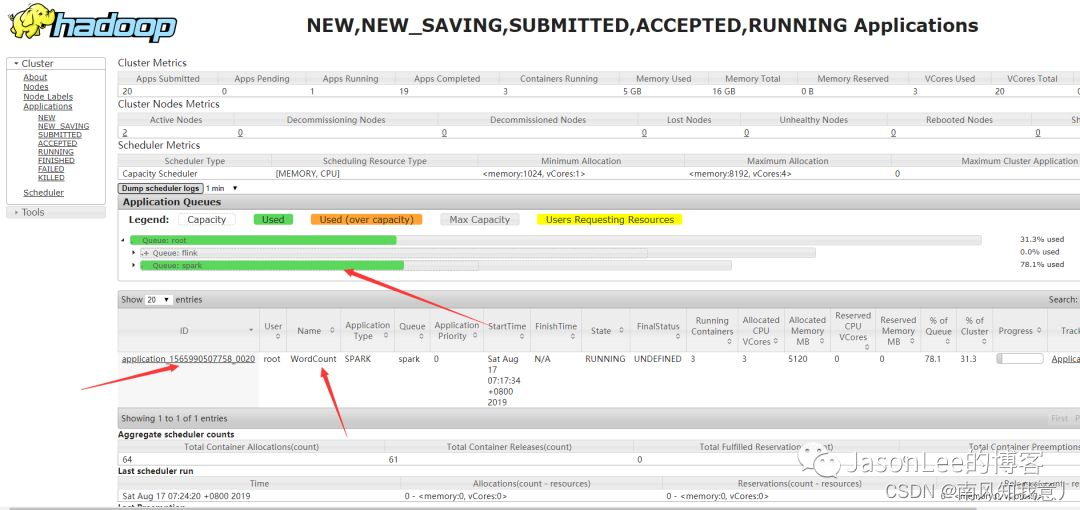
看到有一个spark程序在运行,然后我们点进去,看下具体的运行情况: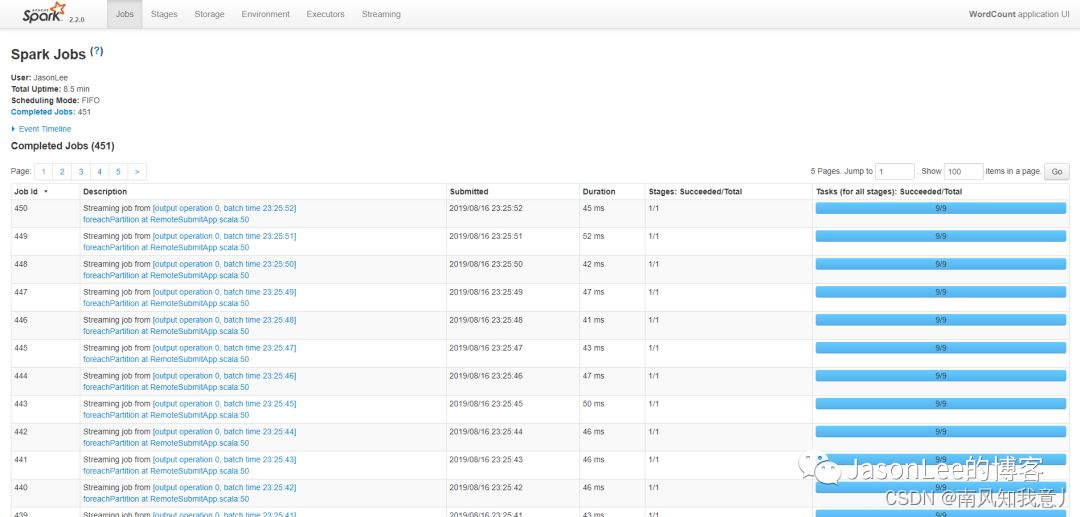
选择一下job,看下executor打印的日志
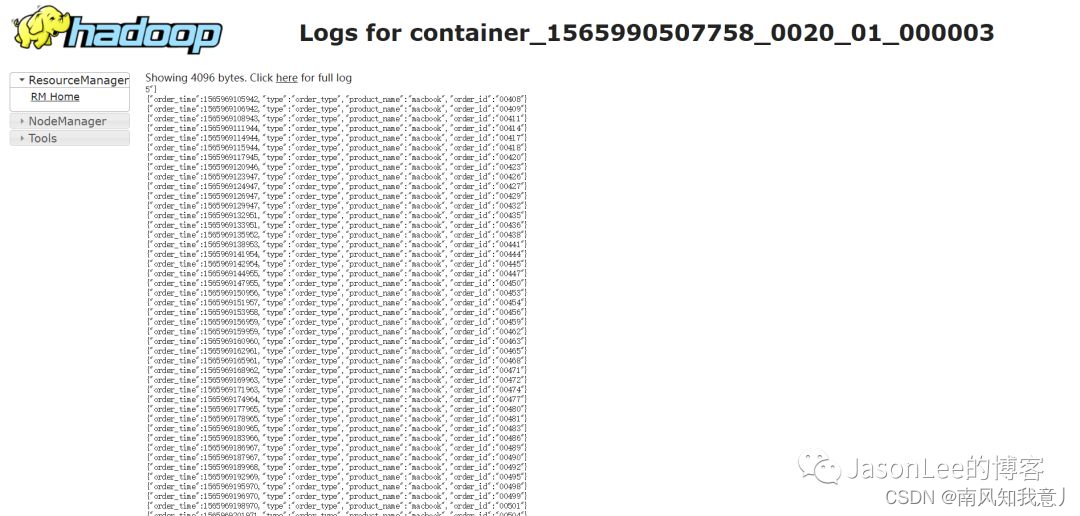
写到kafka的数据,没什么问题,停止的时候,只需要在idea里面点击停止程序就可以了,这样测试起来就会方便很多.
2.运行过程中可能会遇到的问题
2.1首先需要把yarn-site.xml,core-site.xml,hdfs-site.xml放到resource下面,因为程序运行的时候需要这些环境
2.2权限问题
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=JasonLee, access=WRITE, inode="/user":root:supergroup:drwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:342)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:251)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:189)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1744)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1728)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1687)
at org.apache.hadoop.hdfs.server.namenode.FSDirMkdirOp.mkdirs(FSDirMkdirOp.java:60)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:2980)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:1096)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:652)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:503)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:989)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:868)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:814)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1886)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2603)
这个是因为在本地提交的所以用户名是JasonLee,它没有访问hdfs的权限,最简单的解决方法就是在代码里面设置用户是root。
System.setProperty("HADOOP_USER_NAME", "root")
2.3缺失环境变量
Exception in thread "main" java.lang.IllegalStateException: Library directory 'D:\develop_soft\idea_workspace_2018\sparkdemo\assembly\target\scala-2.11\jars' does not exist; make sure Spark is built.
at org.apache.spark.launcher.CommandBuilderUtils.checkState(CommandBuilderUtils.java:248)
at org.apache.spark.launcher.CommandBuilderUtils.findJarsDir(CommandBuilderUtils.java:347)
at org.apache.spark.launcher.YarnCommandBuilderUtils$.findJarsDir(YarnCommandBuilderUtils.scala:38)
at org.apache.spark.deploy.yarn.Client.prepareLocalResources(Client.scala:526)
at org.apache.spark.deploy.yarn.Client.createContainerLaunchContext(Client.scala:814)
at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:169)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:56)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:173)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:509)
at org.apache.spark.streaming.StreamingContext$.createNewSparkContext(StreamingContext.scala:839)
at org.apache.spark.streaming.StreamingContext.<init>(StreamingContext.scala:85)
at spark.RemoteSubmitApp$.main(RemoteSubmitApp.scala:31)
at spark.RemoteSubmitApp.main(RemoteSubmitApp.scala)
这个报错是因为我们没有配置SPARK_HOME的环境变量,直接在idea里面的configurations里面的environment variables里面设置SPARK_HOME就可以了,如下图所示: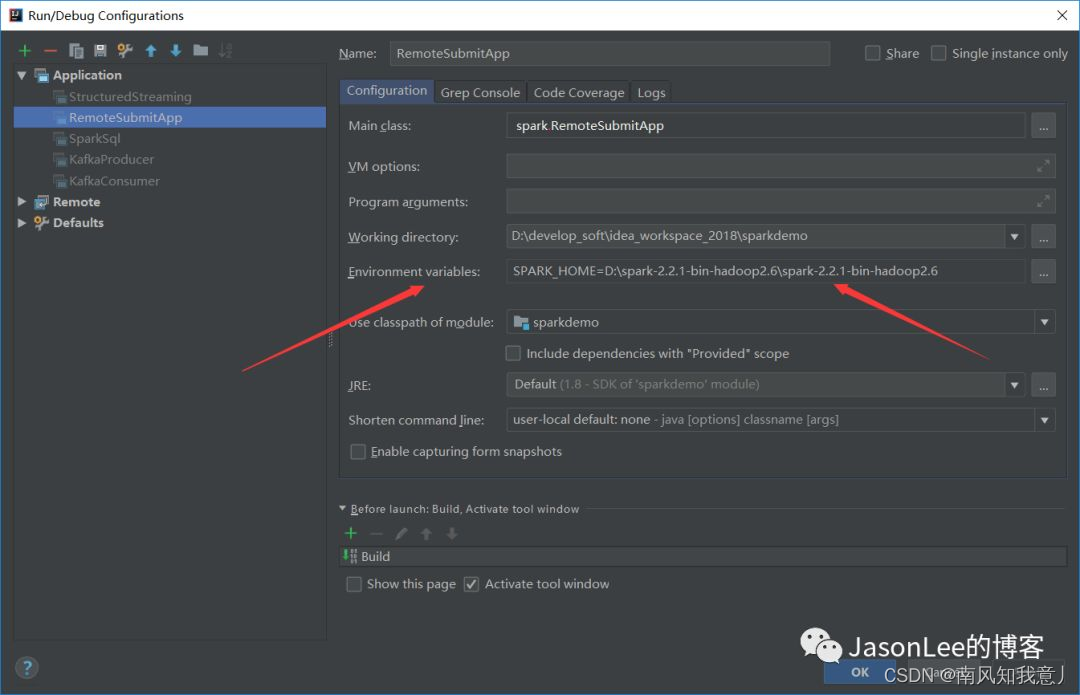
2.4 没有设置driver的ip
9/08/17 07:52:45 ERROR ApplicationMaster: Failed to connect to driver at 169.254.42.204:64010, retrying ...
19/08/17 07:52:48 ERROR ApplicationMaster: Failed to connect to driver at 169.254.42.204:64010, retrying ...
19/08/17 07:52:48 ERROR ApplicationMaster: Uncaught exception:
org.apache.spark.SparkException: Failed to connect to driver!
at org.apache.spark.deploy.yarn.ApplicationMaster.waitForSparkDriver(ApplicationMaster.scala:577)
at org.apache.spark.deploy.yarn.ApplicationMaster.runExecutorLauncher(ApplicationMaster.scala:433)
at org.apache.spark.deploy.yarn.ApplicationMaster.run(ApplicationMaster.scala:256)
at org.apache.spark.deploy.yarn.ApplicationMaster$$anonfun$main$1.apply$mcV$sp(ApplicationMaster.scala:764)
at org.apache.spark.deploy.SparkHadoopUtil$$anon$2.run(SparkHadoopUtil.scala:67)
at org.apache.spark.deploy.SparkHadoopUtil$$anon$2.run(SparkHadoopUtil.scala:66)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1692)
at org.apache.spark.deploy.SparkHadoopUtil.runAsSparkUser(SparkHadoopUtil.scala:66)
at org.apache.spark.deploy.yarn.ApplicationMaster$.main(ApplicationMaster.scala:762)
at org.apache.spark.deploy.yarn.ExecutorLauncher$.main(ApplicationMaster.scala:785)
at org.apache.spark.deploy.yarn.ExecutorLauncher.main(ApplicationMaster.scala)
这个报错是因为没有设置driver host,因为我们运行的是yarn-client模式,driver就是我们的本机,所以要设置本地的ip,不然找不到driver.
.set("spark.driver.host","192.168.17.1")
2.5保证自己的电脑和虚拟机在同一个网段内,而且要关闭自己电脑的防火墙,不然可能会出现连接不上的情况.
边栏推荐
- DEJA_ Vu3d - cesium feature set 055 - summary description of map service addresses of domestic and foreign manufacturers
- Permission problem: source bash_ profile permission denied
- [binary search tree] add, delete, modify and query function code implementation
- 7.5模拟赛总结
- Atcoder beginer contest 254 [VP record]
- Chapter 16 oauth2authorizationrequestredirectwebfilter source code analysis
- [online chat] the original wechat applet can also reply to Facebook homepage messages!
- FFMPEG关键结构体——AVFrame
- 权限问题:source .bash_profile permission denied
- Codeforces Round #804 (Div. 2)【比赛记录】
猜你喜欢
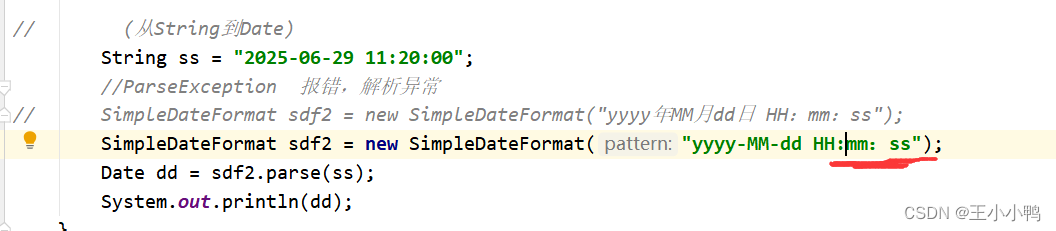
Problems and solutions of converting date into specified string in date class
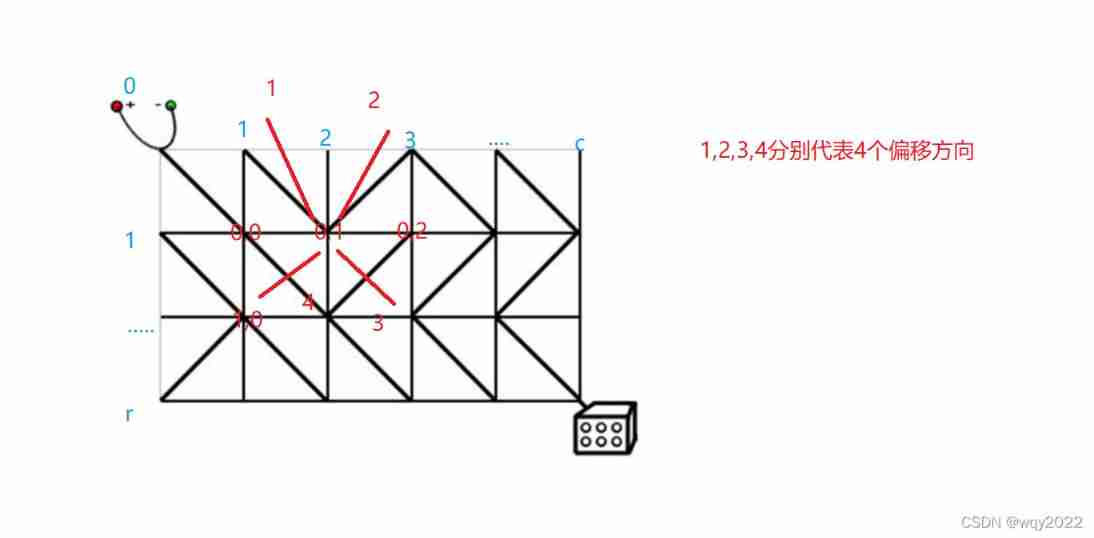
Search (DFS and BFS)

小程序技术优势与产业互联网相结合的分析
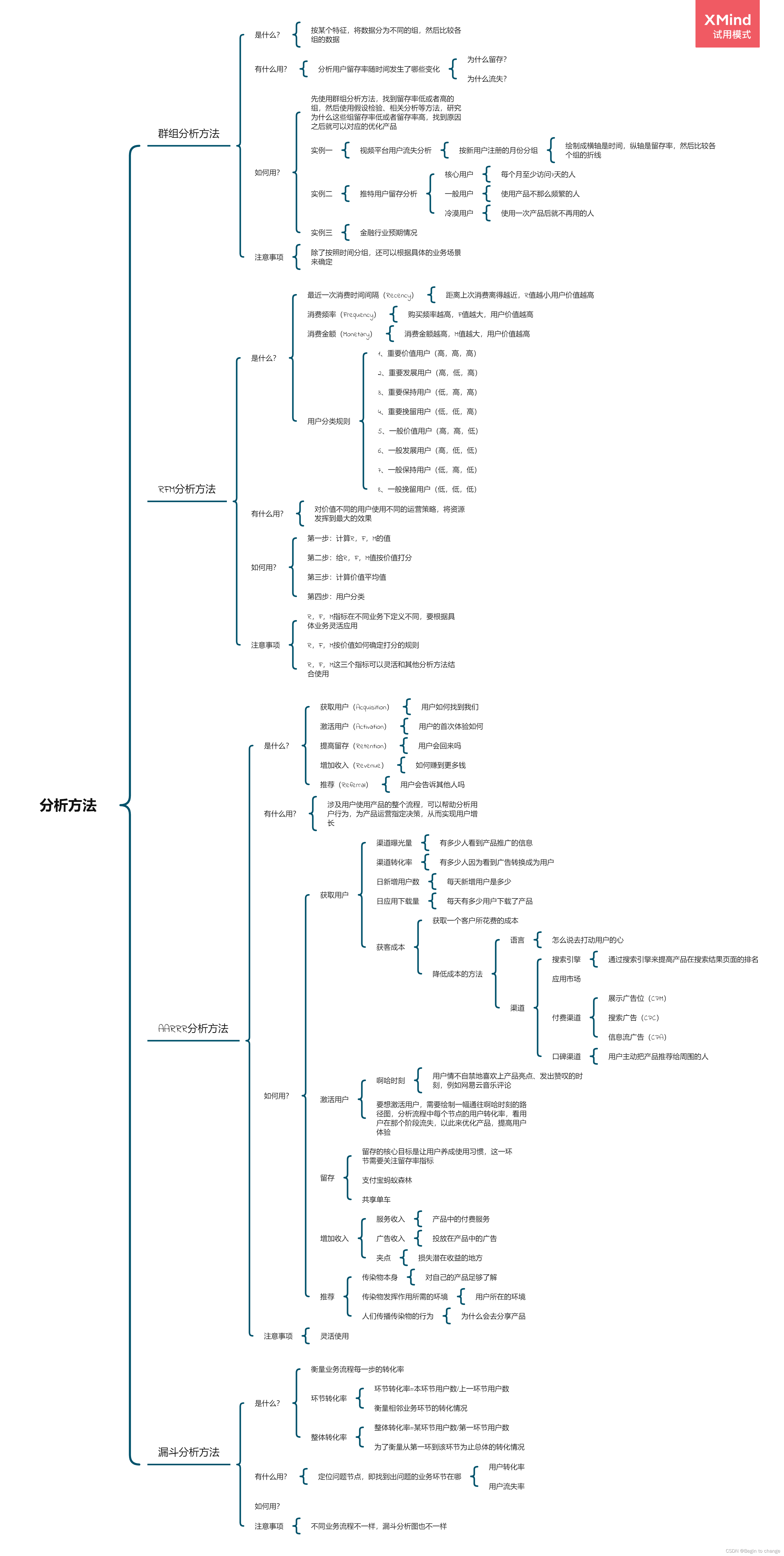
Data analysis thinking analysis methods and business knowledge - analysis methods (III)
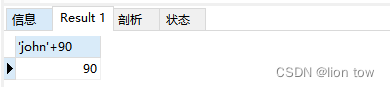
MySql——CRUD
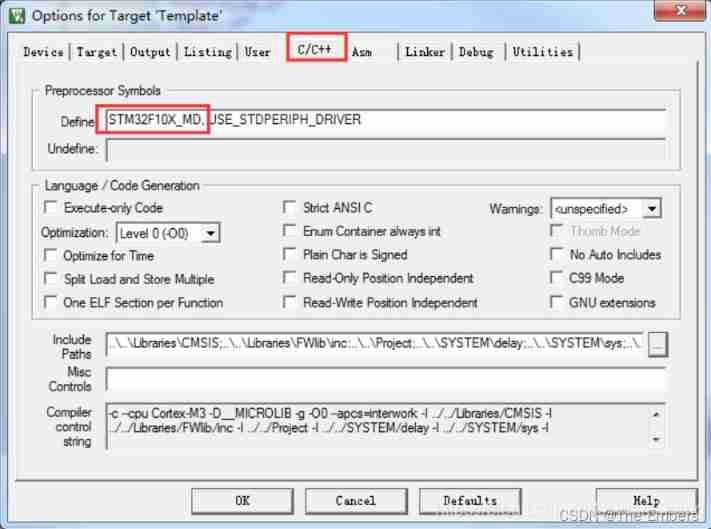
STM32 configuration after chip replacement and possible errors
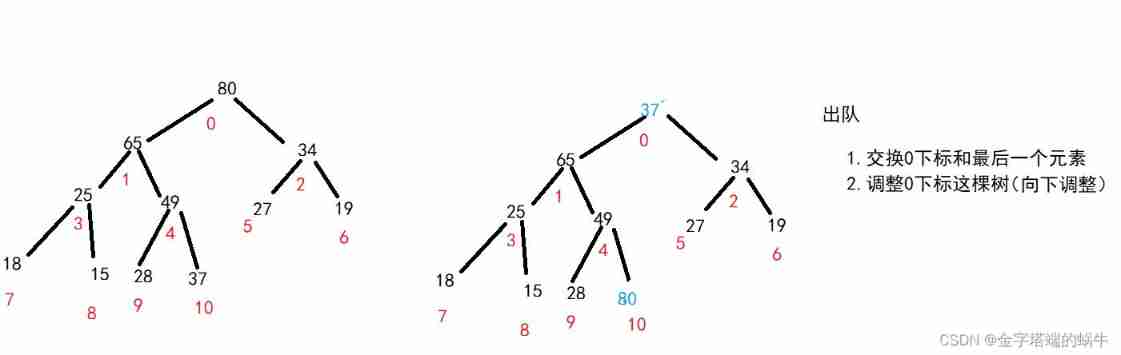
Priority queue (heap)

Location based mobile terminal network video exploration app system documents + foreign language translation and original text + guidance records (8 weeks) + PPT + review + project source code
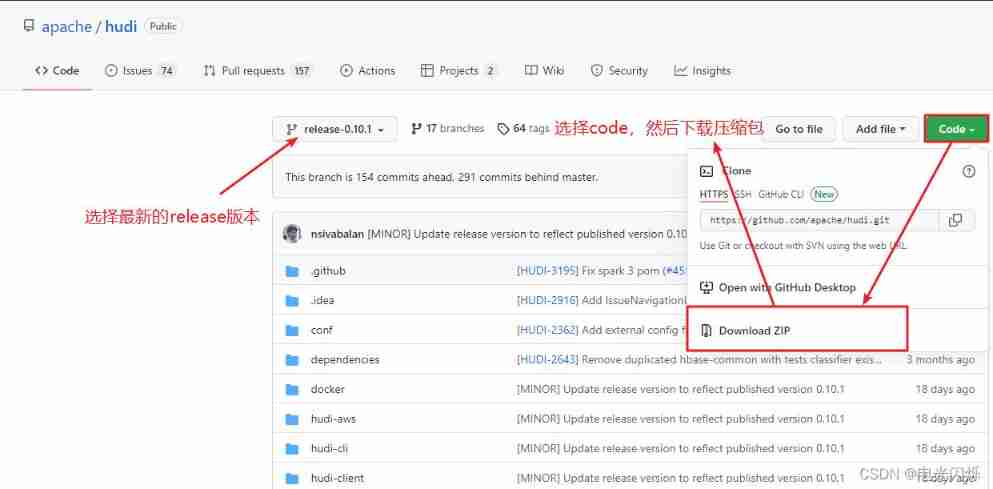
Hudi of data Lake (2): Hudi compilation
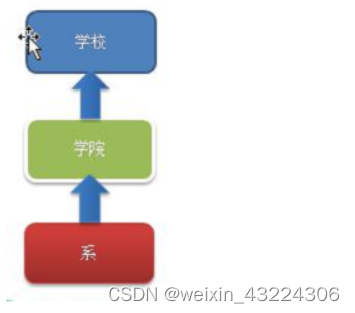
【DesignMode】组合模式(composite mode)
随机推荐
Browser local storage
[noi simulation] Anaid's tree (Mobius inversion, exponential generating function, Ehrlich sieve, virtual tree)
Problems and solutions of converting date into specified string in date class
Solve the problem of reading Chinese garbled code in sqlserver connection database
What is information security? What is included? What is the difference with network security?
7.5 装饰器
DEJA_VU3D - Cesium功能集 之 055-国内外各厂商地图服务地址汇总说明
Opencv classic 100 questions
Room cannot create an SQLite connection to verify the queries
MySQL存储引擎
MySql——CRUD
[EI conference sharing] the Third International Conference on intelligent manufacturing and automation frontier in 2022 (cfima 2022)
Global and Chinese market of water heater expansion tank 2022-2028: Research Report on technology, participants, trends, market size and share
Classic CTF topic about FTP protocol
Detailed explanation of APP functions of door-to-door appointment service
Notepad++ regular expression replacement string
[designmode] Decorator Pattern
【DesignMode】装饰者模式(Decorator pattern)
Global and Chinese markets for hinged watertight doors 2022-2028: Research Report on technology, participants, trends, market size and share
FFT 学习笔记(自认为详细)