当前位置:网站首页>Lucene merge document order
Lucene merge document order
2022-07-03 07:30:00 【chuanyangwang】
org.apache.lucene.index.MergeState#buildDocMaps
Two cases
1. No, indexSort The situation of , Directly remove the deleted ID. And then according to reader Write in the order of DocMap in
2. Yes indexSort In the case of . according to [field][segmentOrd] Organize , And put it in a limited queue . Comparison method according to sorter Compare sizes in the order of ( It is similar to merging multiple ordered linked lists )
private DocMap[] buildDocMaps(List<CodecReader> readers, Sort indexSort) throws IOException {
if (indexSort == null) {
// no index sort ... we only must map around deletions, and rebase to the merged segment's
// docID space
return buildDeletionDocMaps(readers);
} else {
// do a merge sort of the incoming leaves:
long t0 = System.nanoTime();
DocMap[] result = MultiSorter.sort(indexSort, readers);
if (result == null) {
// already sorted so we can switch back to map around deletions
return buildDeletionDocMaps(readers);
} else {
needsIndexSort = true;
}
long t1 = System.nanoTime();
if (infoStream.isEnabled("SM")) {
infoStream.message(
"SM",
String.format(
Locale.ROOT, "%.2f msec to build merge sorted DocMaps", (t1 - t0) / 1000000.0));
}
return result;
}
} /**
* Does a merge sort of the leaves of the incoming reader, returning {@link DocMap} to map each
* leaf's documents into the merged segment. The documents for each incoming leaf reader must
* already be sorted by the same sort! Returns null if the merge sort is not needed (segments are
* already in index sort order).
*/
static MergeState.DocMap[] sort(Sort sort, List<CodecReader> readers) throws IOException {
// TODO: optimize if only 1 reader is incoming, though that's a rare case
SortField[] fields = sort.getSort();
final IndexSorter.ComparableProvider[][] comparables =
new IndexSorter.ComparableProvider[fields.length][];
final int[] reverseMuls = new int[fields.length];
for (int i = 0; i < fields.length; i++) {
IndexSorter sorter = fields[i].getIndexSorter();
if (sorter == null) {
throw new IllegalArgumentException(
"Cannot use sort field " + fields[i] + " for index sorting");
}
comparables[i] = sorter.getComparableProviders(readers);
reverseMuls[i] = fields[i].getReverse() ? -1 : 1;
}
int leafCount = readers.size();
PriorityQueue<LeafAndDocID> queue =
new PriorityQueue<LeafAndDocID>(leafCount) {
@Override
public boolean lessThan(LeafAndDocID a, LeafAndDocID b) {
for (int i = 0; i < comparables.length; i++) {
int cmp = Long.compare(a.valuesAsComparableLongs[i], b.valuesAsComparableLongs[i]);
if (cmp != 0) {
return reverseMuls[i] * cmp < 0;
}
}
// tie-break by docID natural order:
if (a.readerIndex != b.readerIndex) {
return a.readerIndex < b.readerIndex;
} else {
return a.docID < b.docID;
}
}
};
PackedLongValues.Builder[] builders = new PackedLongValues.Builder[leafCount];
for (int i = 0; i < leafCount; i++) {
CodecReader reader = readers.get(i);
LeafAndDocID leaf =
new LeafAndDocID(i, reader.getLiveDocs(), reader.maxDoc(), comparables.length);
for (int j = 0; j < comparables.length; j++) {
leaf.valuesAsComparableLongs[j] = comparables[j][i].getAsComparableLong(leaf.docID);
}
queue.add(leaf);
builders[i] = PackedLongValues.monotonicBuilder(PackedInts.COMPACT);
}
// merge sort:
int mappedDocID = 0;
int lastReaderIndex = 0;
boolean isSorted = true;
while (queue.size() != 0) {
LeafAndDocID top = queue.top();
if (lastReaderIndex > top.readerIndex) {
// merge sort is needed
isSorted = false;
}
lastReaderIndex = top.readerIndex;
builders[top.readerIndex].add(mappedDocID);
if (top.liveDocs == null || top.liveDocs.get(top.docID)) {
mappedDocID++;
}
top.docID++;
if (top.docID < top.maxDoc) {
for (int j = 0; j < comparables.length; j++) {
top.valuesAsComparableLongs[j] =
comparables[j][top.readerIndex].getAsComparableLong(top.docID);
}
queue.updateTop();
} else {
queue.pop();
}
}
if (isSorted) {
return null;
}
MergeState.DocMap[] docMaps = new MergeState.DocMap[leafCount];
for (int i = 0; i < leafCount; i++) {
final PackedLongValues remapped = builders[i].build();
final Bits liveDocs = readers.get(i).getLiveDocs();
docMaps[i] =
new MergeState.DocMap() {
@Override
public int get(int docID) {
if (liveDocs == null || liveDocs.get(docID)) {
return (int) remapped.get(docID);
} else {
return -1;
}
}
};
}
return docMaps;
}边栏推荐
- IPv4 address
- Deep learning parameter initialization (I) Xavier initialization with code
- An overview of IfM Engage
- docker建立mysql:5.7版本指定路径挂载不上。
- [cmake] cmake link SQLite Library
- Vertx restful style web router
- Pat grade a real problem 1166
- Leetcode 198: house raiding
- SQL create temporary table
- Wireshark software usage
猜你喜欢

Various postures of CS without online line

Summary of Arduino serial functions related to print read

691. Cube IV
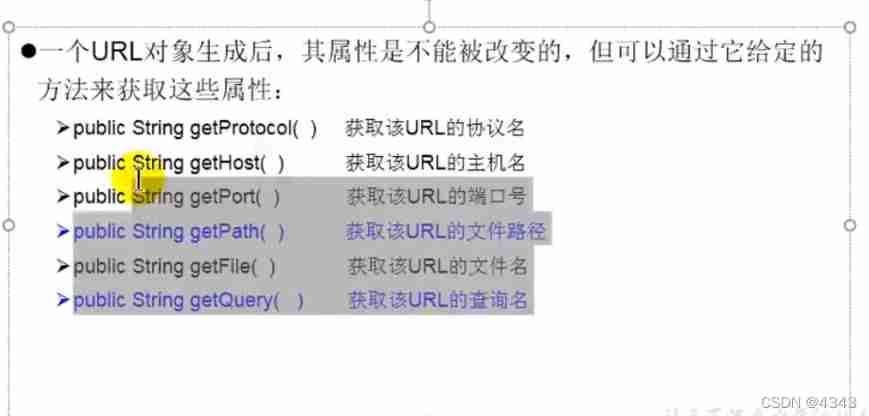
URL programming
1. E-commerce tool cefsharp autojs MySQL Alibaba cloud react C RPA automated script, open source log

Leetcode 198: 打家劫舍
![[solved] sqlexception: invalid value for getint() - 'Tian Peng‘](/img/bf/f6310304d58d964b3d09a9d011ddb5.png)
[solved] sqlexception: invalid value for getint() - 'Tian Peng‘

你开发数据API最快多长时间?我1分钟就足够了

VMWare网络模式-桥接,Host-Only,NAT网络
Topic | synchronous asynchronous
随机推荐
Wireshark software usage
c语言指针的概念
Jeecg data button permission settings
C code production YUV420 planar format file
II. D3.js draw a simple figure -- circle
Interview questions about producers and consumers (important)
Store WordPress media content on 4everland to complete decentralized storage
PdfWriter. GetInstance throws system Nullreferenceexception [en] pdfwriter GetInstance throws System. NullRef
Beginners use Minio
I. D3.js hello world
图像识别与检测--笔记
Sent by mqtt client server of vertx
圖像識別與檢測--筆記
SharePoint modification usage analysis report is more than 30 days
Introduction of buffer flow
IO stream system and FileReader, filewriter
The difference between typescript let and VaR
Visit Google homepage to display this page, which cannot be displayed
Various postures of CS without online line
[solved] sqlexception: invalid value for getint() - 'Tian Peng‘