当前位置:网站首页>Deep Learning 100 Examples - Convolutional Neural Network (CNN) for mnist handwritten digit recognition
Deep Learning 100 Examples - Convolutional Neural Network (CNN) for mnist handwritten digit recognition
2022-08-02 10:40:00 【Ding Jiaxiong】
活动地址:CSDN21天学习挑战赛
深度学习100例 —— 卷积神经网络(CNN)实现mnist手写数字识别
K老师用的tensorflow框架,啊这,Create a new virtual environment.
Python:3.7
编译器:jupyter notebook
深度学习框架:TensorFlow2.7.0


1. 前期准备工作
1.1 设置GPU
Here I finally chose to use itAutoDL的算力,I hate to run on my computer.
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU") # tf.config.list_physical_devices# Get a specific computing device type on the current host(如 GPU 或 CPU )的列表
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU") # Set the list of visible devices

1.2 导入数据
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
MNISTThe handwritten digits dataset is from the National Institute of Standards and Technology,is one of the well-known public datasets.The digital pictures in the dataset are made by 250个不同职业的人纯手写绘制.
MNISTIncluded in the handwritten digits dataset70000张图片,其中60000Zhang is the training data,10000Zhang is the test data,70000pictures are28*28

28 x 28 Convert pixels to vectors,得到长度为28 x 28 = 784 的向量,

1.3 数据归一化处理
作用:
- 使不同量纲的特征处于同一数值量级,减少方差大的特征的影响,使模型更准确.
- 加快学习算法的收敛速度.
归一化:把数变为(0 , 1)之间的小数;Scaling only follows the maximum value、最小值的差别有关.
# 将像素的值标准化至0到1的区间内.
train_images, test_images = train_images / 255.0, test_images / 255.0
train_images.shape,test_images.shape,train_labels.shape,test_labels.shape

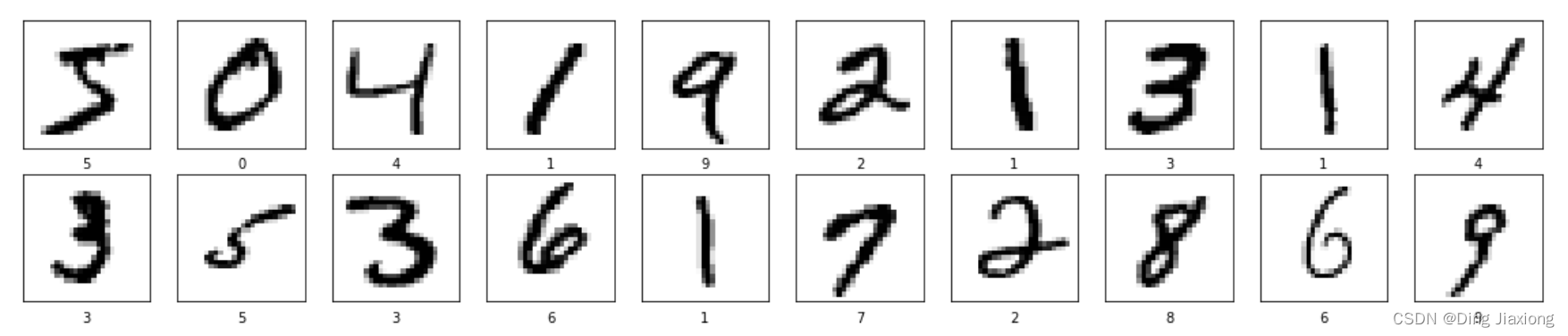
1.4 可视化图片
plt.figure(figsize=(20,10)) # 设置绘图窗口大小
for i in range(20):
plt.subplot(5,10,i+1) # 整个figure被分为5行10列,从左到右,从上到下编号为1,2,3...
plt.xticks([]) # 绘制x轴标签的方向
plt.yticks([]) # 绘制y轴标签的方向
plt.grid(False) # Turn off gridline display
plt.imshow(train_images[i], cmap=plt.cm.binary) # cmap=plt.cm.binary → 显示黑白图像,展示0-19的图像
plt.xlabel(train_labels[i]) # 设置xThe axis labels are the corresponding label values
plt.show()
1.5 调整图片格式
#调整数据到我们需要的格式
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
train_images.shape,test_images.shape,train_labels.shape,test_labels.shape
→ 数据维度转换,增加通道维度

2. 构建CNN网络模型
2.1 构建网络
model = models.Sequential(
[
layers.Conv2D(32 , (3 , 3) , activation = 'relu', input_shape = [28 , 28 , 1]), # 卷积层1,卷积核3 x 3
layers.MaxPooling2D((2, 2)), # 池化层1 , 2 x 2 采样
layers.Conv2D(64 , (3 , 3) , activation = 'relu'), # 卷积层2 , 卷积核3 x 3
layers.MaxPooling2D((2, 2)), # 池化层2, 2 x 2 采样
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(64 , activation = 'relu'), # 全连接层,特征进一步提取
layers.Dense(10) # 输出层,输出结果
]
)
model.summary()
网络结构

2.2 模型结构说明:

各层的作用:
- 输入层:Feed the data into the training network
- 卷积层:Extract features from images using convolution kernels
- 池化层:进行下采样,Represent image features with a higher level of abstraction
- Flatten层:将多维的输入一维化,Commonly used in the transition from convolutional layers to fully connected layers
- 全连接层:特征提取器
- 输出层:输出结果
3. 编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
compile()method is used to set training time,使用的优化器optimizer、损失函数loss、准确率评测标准metrics
SparseCategoricalCrossentropy → 交叉熵损失函数,当from_logits参数为True时,会使用softmax将预测y转换为概率.
4. 训练模型
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
epoch : 迭代次数,All samples will be trained loop10次
validation_data:指定验证数据.
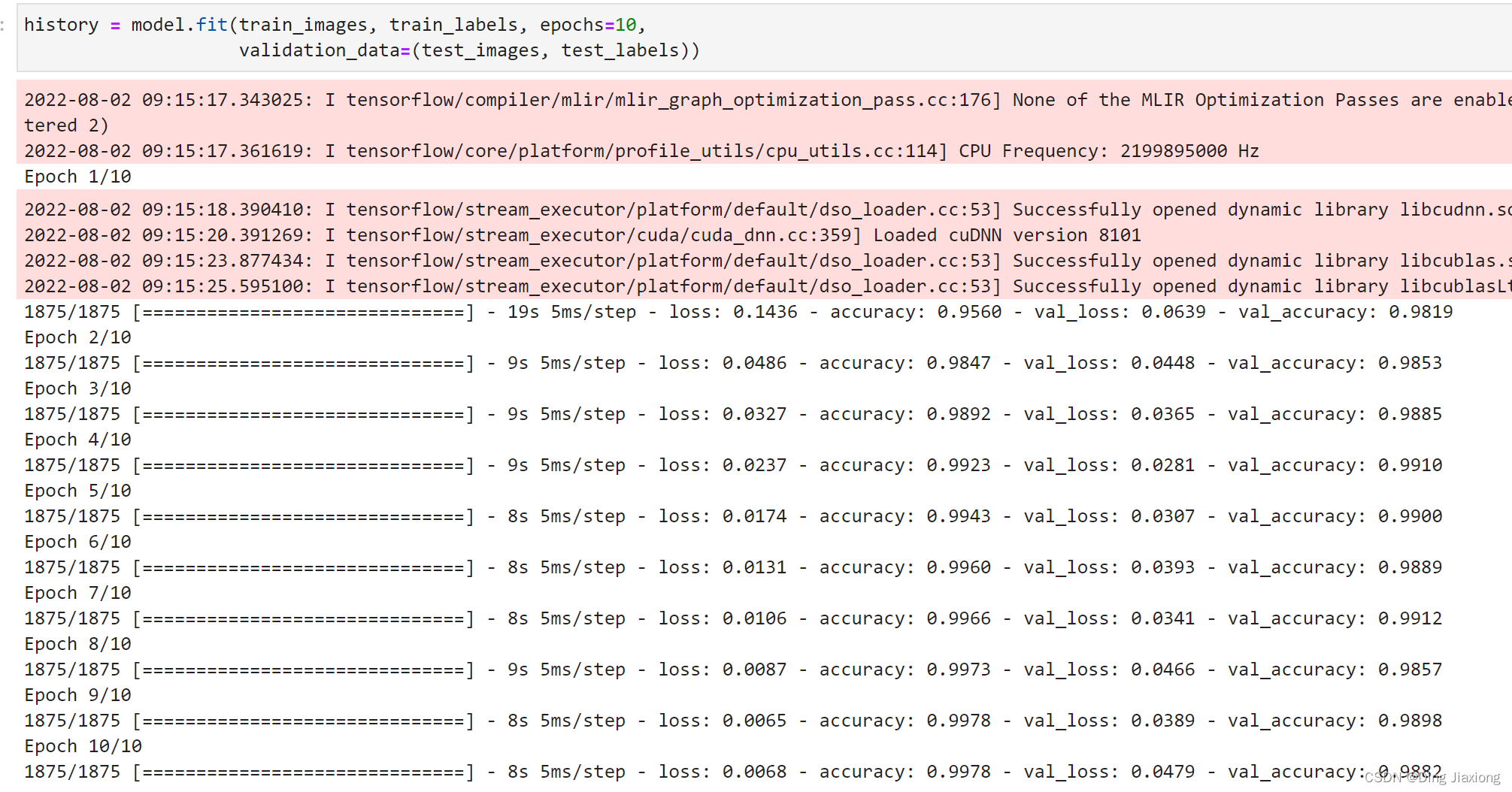
The accuracy of the compiled model settings,Here is the output accuracy
5. 预测
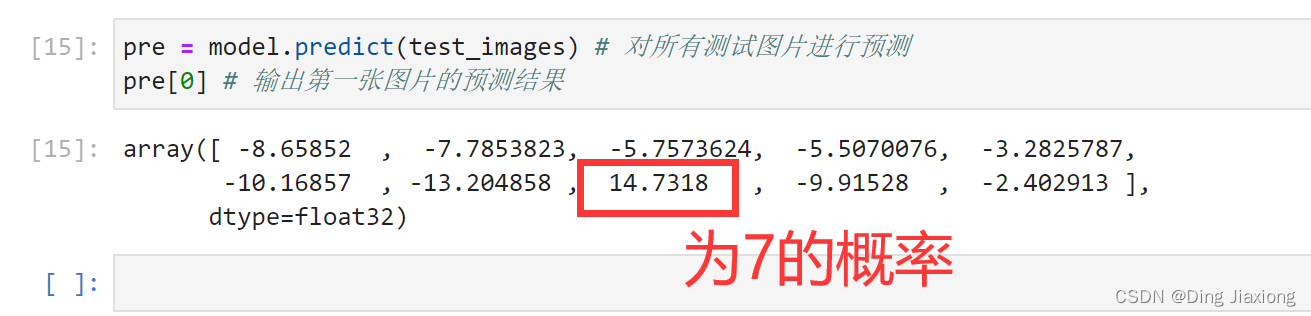
Take a look at the test set0号图片
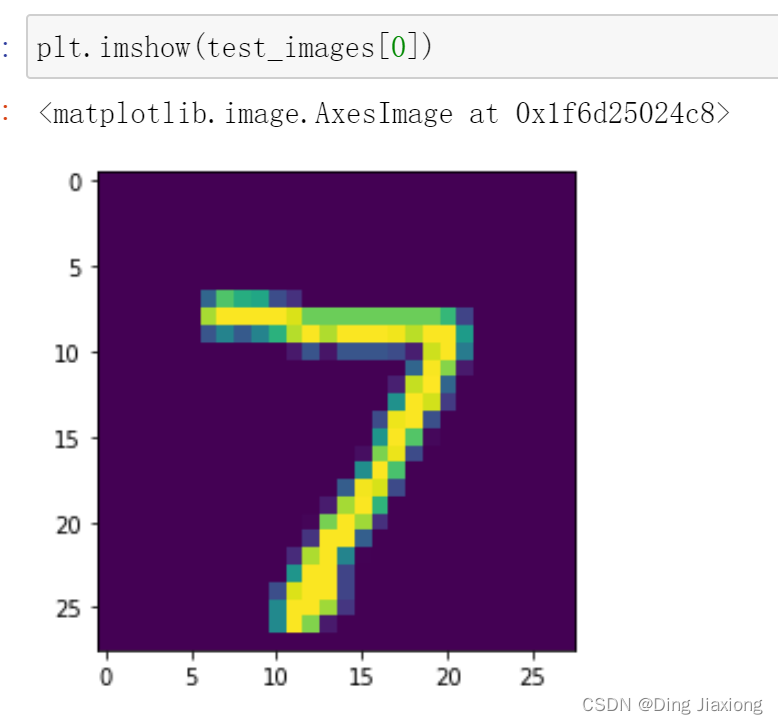
OK,是个7
使用训练好的模型进行预测:
边栏推荐
猜你喜欢
![ASP.NET Core 6框架揭秘实例演示[31]:路由"高阶"用法](/img/57/821576ac28abc8d1c0d65df6a72fa3.png)





随机推荐
LayaBox---TypeScript---三斜线指令
MySQL模糊查询性能优化
Event object, do you know it well?
多大数量级会出现哈希碰撞
LayaBox---TypeScript---JSX
The R language uses the rollapply function in the zoo package to apply the specified function to the time series in a rolling manner and the window moves, and set the align parameter to specify that t
阿里CTO程立:阿里巴巴开源的历程、理念和实践
循环语句综合练习
Turning and anti-climbing attack and defense
38岁女儿不恋爱没有稳定工作老母亲愁哭
R语言ggplot2可视化:基于aes函数中的fill参数和shape参数自定义绘制分组折线图并添加数据点(散点)、使用theme函数的legend.position函数配置图例到图像右侧
LeetCode每日一练 —— 225. 用队列实现栈
【术语科普】关于集成工作台那些难懂的词儿,看这篇秒懂!
R语言时间序列数据算术运算:使用log函数将时间序列数据的数值对数化、使用diff函数计算对数化后的时间序列数据的逐次差分(计算价格的对数差分)
Event 对象,你很了解吗?
循环结构--while循环
The realization of the list
Geoffery Hinton: The Next Big Thing in Deep Learning
3 d laser slam: LeGO - LOAM - ground point extracting method and the analysis of the code
The R language uses the ggtexttable function of the ggpubr package to visualize the table data (draw the table directly or add the table data to the image), set the theme parameter to customize the fi