当前位置:网站首页>scrapy 爬取当当图书名字图片
scrapy 爬取当当图书名字图片
2022-08-04 05:26:00 【Drizzlejj】
1。创建项目和创建爬虫参考上一篇博客。
2.dang.py
import scrapy
from scrapy_dangdang.items import ScrapyDangdangItem
class DangSpider(scrapy.Spider):
name = 'dang'
# 多页下载要注意 allowed_domains 范围,一般只写域名
allowed_domains = ['category.dangdang.com']
start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html']
base_url = 'http://category.dangdang.com/pg'
page = 1
def parse(self, response):
li_list = response.xpath('//ul[@id="component_59"]/li') # xpath 选择要爬取的内容路径
for li in li_list:
src = li.xpath('.//img/@data-original').extract_first()
# 懒加载反爬 第一张图片和其他图片的标签属性是不一样的,第一张图片是可以使用 src 的,其他图片的地址是 data-original
if src:
src = src
else:
src = li.xpath('.//img/@src').extract_first()
name = li.xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()
book = ScrapyDangdangItem(src=src,name=name,price=price)
yield book # 获取一个 book 就将 book 交给 pipelines ,yield 类似 return
# 每一页的爬取逻辑是一样的。只需要将执行页的请求再次调用 parse 方法
if self.page < 100:
self.page = self.page + 1
url = self.base_url +str(self.page) + '-cp01.01.02.00.00.00.html' # 每页的url链接拼接
# callback 要执行的函数
yield scrapy.Request(url=url,callback=self.parse)3. items 定义数据结构
items.py
import scrapy
class ScrapyDangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
src = scrapy.Field() # 图片
name = scrapy.Field() # 名字
price = scrapy.Field() # 价格4.管道 pipelines 下载数据
pipelines.py
import urllib.request
from itemadapter import ItemAdapter
# 如果想使用管道 ,必须在 settings 开启管道
class ScrapyDangdangPipeline:
# 在爬虫文件开始之前执行
def open_spider(self,spider):
self.fp = open('book.json','a',encoding='utf-8')
# item 就是yield 后面的 book 对象
def process_item(self, item, spider):
# write 方法必须是一个字符串
# 对文件打开关闭操作过于频繁,不推荐这样做
# with open('book.json','a',encoding='utf-8') as fp:
# fp.write(str(item))
self.fp.write(str(item) + ',')
return item
# 在爬虫文件执行完之后 执行
def cloxe_spider(self,spider):
self.fp.close()
# 再开一条管道下载
# 1)定义管道类,并在 settings 中增加 'scrapy_dangdang.pipelines.DangDangDownloadPipeline': 301,
class DangDangDownloadPipeline: # 定义管道类
def process_item(self,item,spider):
url = 'http:' + item.get('src') # 图片地址拼接
filename = r'C:\Users\Administrator\Desktop\books' + './' + item.get('name') + '.jpg'
urllib.request.urlretrieve(url=url,filename=filename) # 下载图片
return item5.爬取下载的部分数据保存在 json
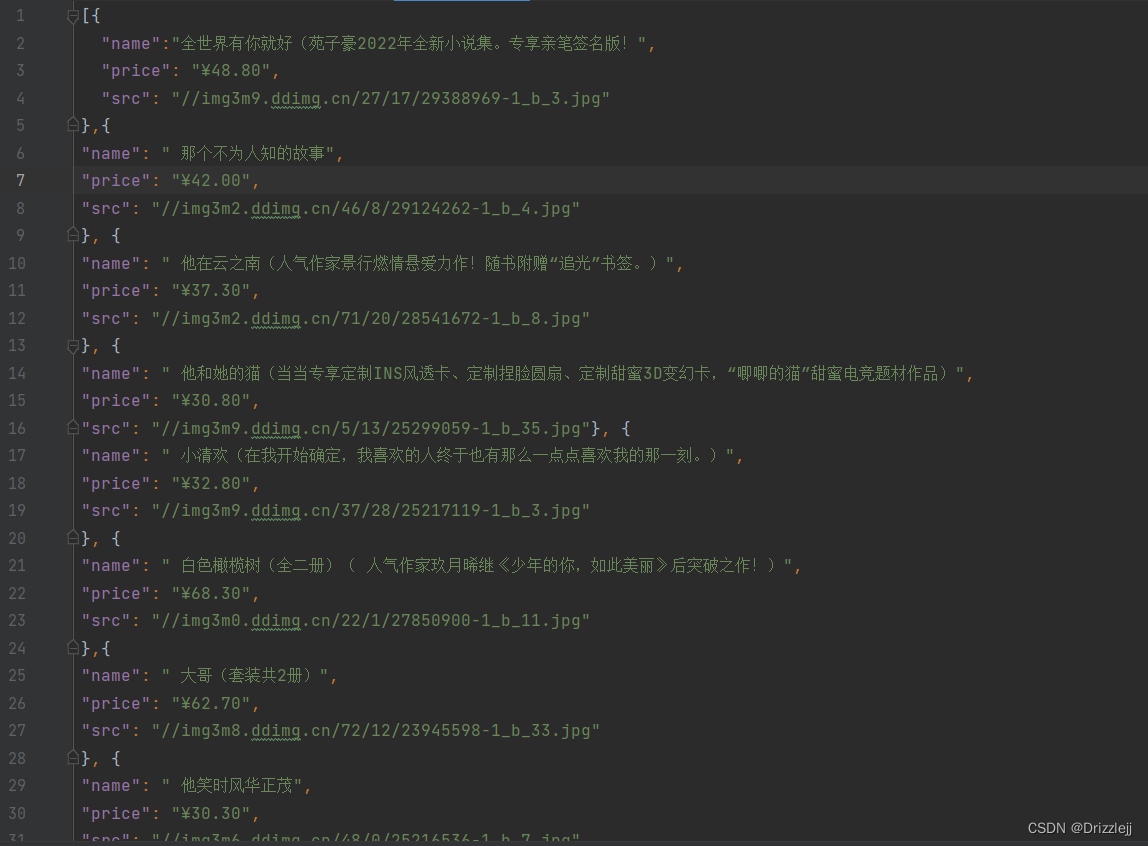
6.保存的图片

边栏推荐
猜你喜欢



随机推荐
Summary of MySQL database interview questions (2022 latest version)
关于C#的反射,你真的运用自如嘛?
解决JDBC在web工程中无法获取配置文件
word 公式编辑器 键入技巧 | 写数学作业必备速查表
如何低成本修bug?测试左移给你答案
强制结束进程
音视频相关基础知识与FFmpeg介绍
大龄程序员的心理建设
webrtc中视频采集实现分析(二) 视频帧的分发
基于C语言的学生信息管理系统_(更新版)_(附源码和安装包)_课程设计_**往事随風**的博客
MySQL日志篇,MySQL日志之binlog日志,binlog日志详解
npm安装依赖报错npm ERR! code ENOTFOUNDnpm ERR! syscall getaddrinfonpm ERR! errno ENOTFOUND
Unity DOTS学习教程汇总
再识关联容器
想低成本保障软件安全?5大安全任务值得考虑
【JS】js给对象动态添加、设置、删除属性名和属性值
C language -- operator details
【论文阅读笔记】无监督行人重识别中的采样策略
程序员也应了解的Unity粒子系统
Cannot read properties of null (reading ‘insertBefore‘)