当前位置:网站首页>Es remote cluster configuration and cross cluster search
Es remote cluster configuration and cross cluster search
2022-07-03 05:58:00 【Ashley shot the sun】
ES Remote clusters can be configured in to realize cross cluster search , Greatly improved ES Horizontal scalability of clusters , Cross cluster search is also ES Knowledge points often tested in certification examination . This article briefly summarizes ES Configuration of remote cluster and cross cluster search as a reminder , Also hope to help students in need .
One . Configure remote cluster
In order to realize cross cluster search, you first need to configure the remote cluster in the current cluster , We can configure in the following three ways :
1. Profile Settings
First, you can ElasticSearch Of yml Set... In the configuration file ,ES A link with the remote cluster will be established at startup , The configuration is as follows :
cluster:
remote:
cluster_one:
seeds: 127.0.0.1:9300
transport.ping_schedule: 30s
cluster_two:
seeds: 127.0.0.1:9301
transport.compress: true
skip_unavailable: true
Configuration instructions
cluster_one: Custom cluster nameseeds: The node list of the cluster , You can configure multipletransport.ping_schedule: Set up to send ping Time interval between requests to detect connection statusskip_unavailable: Cross cluster search whether to skip unavailable clusters
2. ES The request is set
In addition to configuration files , You can also use ES Set the remote cluster by request , This is also a recommended way ,API as follows :
1. CURL request
curl -XPUT "http://localhost:9202/_cluster/settings" -H 'Content-Type: application/json' -d'
{
"persistent":{
"cluster":{
"remote":{
"cluster0":{
"seeds":["127.0.0.1:9300"],"transport.ping_schedule":"30s"},"cluster1":{
"seeds":["127.0.0.1:9301"],"transport.compress":true,"skip_unavailable":true},"cluster2":{
"seeds":["127.0.0.1:9302"]}}}}}
2. ES DSL command
PUT _cluster/settings
{
"persistent": {
"cluster": {
"remote": {
"cluster_one": {
"seeds": [
"127.0.0.1:9300"
],
"transport.ping_schedule": "60s"
},
"cluster_two": {
"mode": "sniff",
"seeds": [
"127.0.0.1:9301"
],
"transport.compress": false
},
"cluster_three": {
"mode": "proxy",
"proxy_address": "127.0.0.1:9302",
"transport.compress": true
}
}
}
}
}
3. Kibana Management add to
In addition to the above two ways , We can still do that Kibana Management interface Management -> Remote clusters To configure , The steps are as shown in the figure :
There are already two configurations in the above figure , I am adding a new cluster as follows :
Now three remote clusters are configured , Pictured

After configuration, you can use the following API Inquire about :
GET _remote/info
{
"cluster1" : {
"seeds" : [
"127.0.0.1:9301"
],
"connected" : true,
"num_nodes_connected" : 1,
"max_connections_per_cluster" : 3,
"initial_connect_timeout" : "30s",
"skip_unavailable" : true
},
"cluster0" : {
"seeds" : [
"127.0.0.1:9300"
],
"connected" : true,
"num_nodes_connected" : 1,
"max_connections_per_cluster" : 3,
"initial_connect_timeout" : "30s",
"skip_unavailable" : false
},
"cluster2" : {
"seeds" : [
"127.0.0.1:9301"
],
"connected" : true,
"num_nodes_connected" : 1,
"max_connections_per_cluster" : 3,
"initial_connect_timeout" : "30s",
"skip_unavailable" : true
}
}
4. Delete remote cluster
If a remote cluster is no longer needed , Can pass Kibana Interface or the following command to delete :
PUT _cluster/settings
{
"persistent": {
"cluster": {
"remote": {
"cluster_two": {
"seeds": null,
"skip_unavailable": null,
"transport": {
"compress": null
}
}
}
}
}
}
Two . Cross cluster search
After the remote cluster configuration is completed, cross cluster search can be carried out ,API It's simple , Is in the Search Specify the corresponding cluster and index in the request .
1. Search local clusters
Specify the index name directly, and the default search is local colony .
GET /twitter/_search
{
"query": {
"match": {
"user": "kimchy"
}
}
}
2. Search in a specified single cluster
For remote clusters, we need to adopt Cluster name : Index name The way of specifying .
# stay cluster_one Search in the remote cluster
GET /cluster_one:twitter/_search
{
"query": {
"match": {
"user": "kimchy"
}
}
}
3. Realize cross cluster search in multiple clusters
# stay local、clustr_one、cluster_two Search in three clusters
GET /twitter,cluster_one:twitter,cluster_two:twitter/_search
{
"query": {
"match": {
"user": "kimchy"
}
}
}
3、 ... and . ES Cross cluster search process
ES Cross cluster search modes mainly include Minimize network roundtrips and Don’t minimize network roundtrips Two ways . The main difference between the two is the number of requests sent when performing a search :
Minimize network roundtrips Pattern
Coordinating After the node receives the cross cluster request , A node will be selected in each cluster to be searched , Then send a search request , After receiving the search results, aggregate and return .
The process is as follows :
【1】 Receive client requests

【2】 Request cluster

【3】 Receive the query structure of each cluster
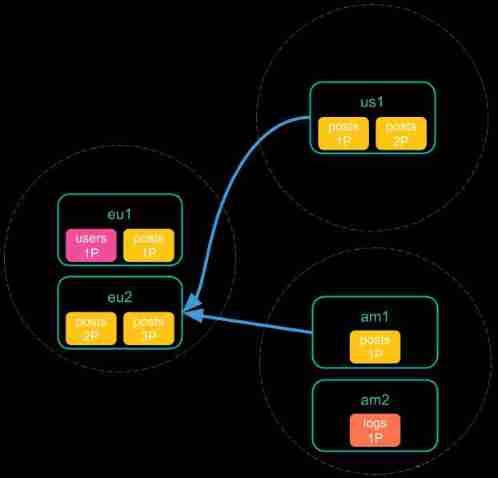
【4】 Return query results after aggregation

Don’t minimize network roundtrips
In this mode ,Coordinating After the node receives the cross cluster request , First, a message will be sent to each cluster Query fragmentation Request , Query the fragment information available for data query in each cluster , Then send a search request to each partition , Finally, aggregate the query results and return .
The specific process is as follows :
【1】 The client receives the request
【2】 Query each cluster partition
Receive fragment query results
【3】 Send query request to each partition

【4】 Receive the request results of each partition
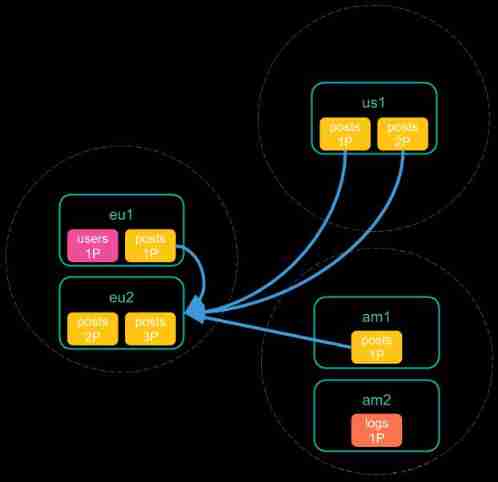
【5】 Aggregate the results and return
Lao tie saw this and gave a wave of praise 、 Comment on 、 How about paying attention to Sanlian
I am a AhriJ Zou classmate , Front and rear ends 、 Applet 、DevOps Are engaged in the explosion of stack engineers . The blog is constantly updated , If you think it's good , Welcome to the old tiesanlian , If it's not good, you're welcome to correct , learn from each other , Common progress .
边栏推荐
- 今天很多 CTO 都是被幹掉的,因為他沒有成就業務
- Analysis of Clickhouse mergetree principle
- [teacher Zhao Yuqiang] Alibaba cloud big data ACP certified Alibaba big data product system
- Qt读写Excel--QXlsx插入图表5
- 一起上水碩系列】Day 9
- Jetson AgX Orin platform porting ar0233 gw5200 max9295 camera driver
- [teacher Zhao Yuqiang] calculate aggregation using MapReduce in mongodb
- NG Textarea-auto-resize
- 期末复习(Day2)
- Detailed explanation of contextclassloader
猜你喜欢

今天很多 CTO 都是被幹掉的,因為他沒有成就業務

Sophomore dilemma (resumption)
Error 1045 (28000) occurs when Linux logs in MySQL: access denied for user 'root' @ 'localhost' (using password: yes)

Configure DTD of XML file
为什么网站打开速度慢?

2022.DAY592
Jedis source code analysis (II): jediscluster module source code analysis

一起上水碩系列】Day 9
![[Zhao Yuqiang] deploy kubernetes cluster with binary package](/img/cc/5509b62756dddc6e5d4facbc6a7c5f.jpg)
[Zhao Yuqiang] deploy kubernetes cluster with binary package

Disruptor learning notes: basic use, core concepts and principles
随机推荐
Synthetic keyword and NBAC mechanism
QT read write excel -- qxlsx insert chart 5
[teacher Zhao Yuqiang] use the catalog database of Oracle
chromedriver对应版本下载
2022.7.2 simulation match
Clickhouse learning notes (2): execution plan, table creation optimization, syntax optimization rules, query optimization, data consistency
[branch and cycle] | | super long detailed explanation + code analysis + a trick game
[teacher Zhao Yuqiang] index in mongodb (Part 1)
[teacher Zhao Yuqiang] RDB persistence of redis
Yum is too slow to bear? That's because you didn't do it
[set theory] relational closure (reflexive closure | symmetric closure | transitive closure)
redis 无法远程连接问题。
The programmer shell with a monthly salary of more than 10000 becomes a grammar skill for secondary school. Do you often use it!!!
Use telnet to check whether the port corresponding to the IP is open
[teacher Zhao Yuqiang] kubernetes' probe
期末复习(Day5)
多线程与高并发(7)——从ReentrantLock到AQS源码(两万字大章,一篇理解AQS)
Redhat7系统root用户密码破解
中职网络子网划分例题解析
2022.6.30DAY591