当前位置:网站首页>pytorch DataLoader实现miniBatch(未完成)
pytorch DataLoader实现miniBatch(未完成)
2022-07-03 05:45:00 【code bean】
书接上回《pytorch 搭建神经网络最简版》上次并未用到miniBatch,一次性将全部的数据输入进行训练。
这次通过DataLoader实现miniBatch
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv')
train_loader = DataLoader(dataset=dataset,
batch_size=749,
shuffle=False,
num_workers=1)
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
self.activate = torch.nn.ReLU()
# __call__() 中会调用这个函数!
def forward(self, x):
# x = self.activate(self.linear1(x))
# x = self.activate(self.linear2(x))
# x = self.activate(self.linear3(x))
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
# model为可调用的! 实现了 __call__()
model = Model()
# 指定损失函数
# criterion = torch.nn.MSELoss(size_average=Flase) # True
# criterion = torch.nn.MSELoss(reduction='sum') # sum:求和 mean:求平均
criterion = torch.nn.BCELoss(reduction='mean') # 二分类交叉熵损失函数
# -- 指定优化器(其实就是有关梯度下降的算法,负责),这里将优化器和model进行了关联
# optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # 这个用这个很准啊,其他得根本不行啊
# optimizer = torch.optim.Rprop(model.parameters(), lr=0.01)
# for epoch in range(5000):
# y_pred = model(x_data) # 直接把整个测试数据都放入了
# loss = criterion(y_pred, y_data)
# print(epoch, loss.item())
# optimizer.zero_grad() # 会自动找到所有的w和b进行清零!优化器的作用 (为啥这个放到loss.backward()后面清零就不行了呢?)
# loss.backward()
# optimizer.step() # 会自动找到所有的w和b进行更新,优化器的作用!
#
if __name__ == '__main__':
for epoch in range(1000):
for i, data in enumerate(train_loader, 0):
# 1. Prepare data
inputs, labels = data
# 2. Forward
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
# 3. Backward
optimizer.zero_grad()
loss.backward()
# 4. Update
optimizer.step()
# 测试
xy = np.loadtxt('diabetes_test.csv', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1])
y_data = torch.from_numpy(xy[:, -1])
x_test = torch.Tensor(x_data)
y_test = model(x_test) # 预测
print('y_pred = ', y_test.data)
# 对比预测结果和真实结果
for index, i in enumerate(y_test.data.numpy()):
if i[0] > 0.5:
print(1, int(y_data[index].item()))
else:
print(0, int(y_data[index].item()))
截取关键代码:
train_loader = DataLoader(dataset=dataset,
batch_size=749,
shuffle=False,
num_workers=1)batch_size 每个批次训练的大小,如果总的数据条数是7490条,那么此时train_loader 中将会产生10个batch。shuffle是洗牌的意思,就是打乱数据的顺序后再数据放到10个batch里。
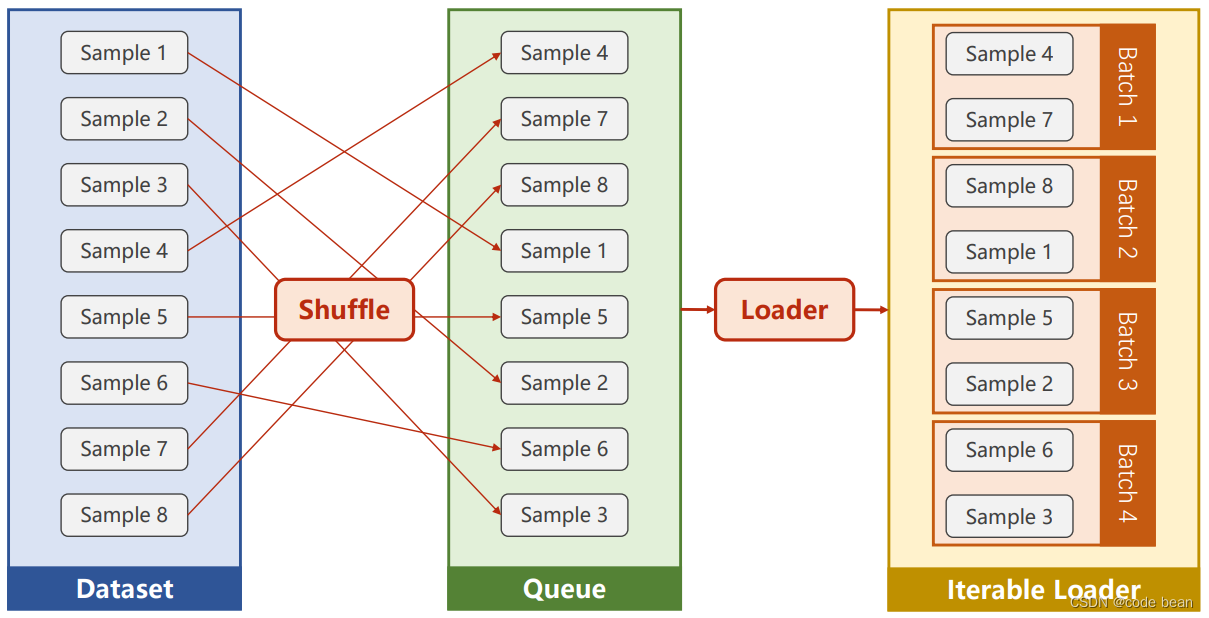
而此时我为啥,要将 batch_size设置成29,且设置为不洗牌。是因为我想和之前的过程进行对比。
因为此时数据集里只有749数据,那么就只会产生一个batch,一个batch内是不打乱顺序的全部数据。这样就和之前的训练过程是一样的。
这样做是因为我发现,使用了DataLoader之后训练的过程变得异常的慢,改成上述配置后,我以为速度会一样,但其实慢了10不止!
更蛋疼的是,如果 batch_size改小一点,loss直接没法收敛了,循环测试多了还报错:
return _winapi.DuplicateHandle( PermissionError: [WinError 5] 拒绝访问
这DataLoader还咋用啊?哪位大神指点一下?
边栏推荐
- @Import annotation: four ways to import configuration classes & source code analysis
- Why should we rewrite hashcode when we rewrite the equals method?
- [teacher Zhao Yuqiang] MySQL flashback
- 【一起上水硕系列】Day 7 内容+Day8
- 2022.6.30DAY591
- 獲取並監控遠程服務器日志
- Get and monitor remote server logs
- NG Textarea-auto-resize
- MySQL startup error: several solutions to the server quit without updating PID file
- 【无标题】
猜你喜欢

求质数的方法
Linux登录MySQL出现ERROR 1045 (28000): Access denied for user ‘root‘@‘localhost‘ (using password: YES)

Brief introduction of realsense d435i imaging principle

DEX net 2.0 for crawl detection
![[set theory] relational closure (reflexive closure | symmetric closure | transitive closure)](/img/c8/2995c503e9dabae4e2cc704449e04f.jpg)
[set theory] relational closure (reflexive closure | symmetric closure | transitive closure)

今天很多 CTO 都是被干掉的,因为他没有成就业务

Capacity expansion mechanism of map

Export the altaro event log to a text file
![Ensemble, série shuishu] jour 9](/img/39/c1ba1bac82b0ed110f36423263ffd0.png)
Ensemble, série shuishu] jour 9

Kubernetes resource object introduction and common commands (V) - (configmap)
随机推荐
[untitled]
Shanghai daoning, together with American /n software, will provide you with more powerful Internet enterprise communication and security component services
DEX net 2.0 for crawl detection
mysql启动报错:The server quit without updating PID file几种解决办法
Why is the website slow to open?
Apt update and apt upgrade commands - what is the difference?
牛客网 JS 分隔符
How to install and configure altaro VM backup for VMware vSphere
Azure file synchronization of altaro: the end of traditional file servers?
[Shangshui Shuo series together] day 10
Ext4 vs XFS -- which file system should you use
Life is a process of continuous learning
CAD插件的安装和自动加载dll、arx
配置xml文件的dtd
2022.DAY592
Final review (Day6)
[function explanation (Part 1)] | | knowledge sorting + code analysis + graphic interpretation
Redhat7 system root user password cracking
期末复习(DAY7)
[teacher Zhao Yuqiang] index in mongodb (Part 1)