当前位置:网站首页>Linear rectification function relu and its variants in deep learning activation function
Linear rectification function relu and its variants in deep learning activation function
2022-07-03 02:31:00 【Python's path to immortality】
Linear rectification function ReLU
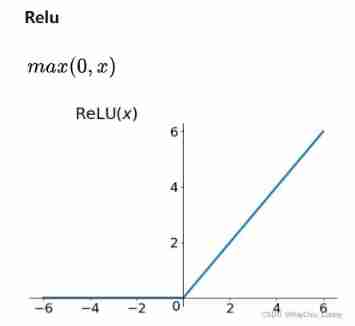
Linear rectification function (Rectified Linear Unit, ReLU), also called Modified linear element , It's a kind of Artificial neural network Activation functions commonly used in (activation function), Usually referred to as Slope function And its variants Nonlinear functions .
Mathematical expression :
f(x) = max(0, x)
Or write this :
![]()
In the above formula x Is the output value of neural network after linear transformation ,ReLU Convert the result of linear transformation into nonlinear value , This idea refers to the neural network mechanism in Biology , This mechanism is characterized by when the input is negative , Set all zeros , When the input is timing, it remains unchanged , This feature is called unilateral inhibition . In the hidden layer , This feature will bring certain sparsity to the output of the hidden layer . At the same time, because it is input as timing , The output remains the same , The gradient of 1:

- Advantages one : Simple calculation and high efficiency . Compared with other activation functions such as sigmoid、tanh, The derivative is easier to find , Back propagation is the process of constantly updating parameters , Because its derivative is not complex and its form is simple .
- Advantage two : The suppression gradient disappears . For deep networks , Other activation functions such as sigmoid、tanh Function back propagation , It's easy to see the gradient disappear ( stay sigmoid Near the saturation zone , Too slow to change , Derivative tends to 0, This can cause information loss .), This phenomenon is called saturation , So we can't complete the training of deep network .
and ReLU There will be no tendency to saturate ( This is only for the right end , The left derivative is zero , Once you fall in, the gradient will still disappear ), There won't be a very small gradient .
Advantage three : Ease of overfitting .Relu It's going to make the output of some of the neurons zero 0, This results in the sparsity of the network , Moreover, the interdependence of parameters is reduced , The problem of overfitting is alleviated
Shortcomings also exist relatively ,ReLU This unilateral inhibition mechanism is too rough and simple , In some cases, it may cause a neuron “ Death ”, That is, the elimination of the inhibition gradient emphasized in advantage 2 above is reflected at the right end , The left derivative is 0, Then in the process of back propagation , The corresponding gradient is always 0, As a result, effective updates cannot be made . To avoid that , There are several kinds of ReLU Variants of are also widely used .
Leaky ReLU

LeakyReLU differ ReLU Completely suppress when the input is negative , When the input is negative , A certain amount of information can be allowed to pass through , The specific method is when the input is negative , Output is ![]() , The mathematical expression is :
, The mathematical expression is :

among ![]() Is a super parameter greater than zero , Usually the value is 0.2、0.01. This can be avoided ReLU Neurons appear “ Death ” The phenomenon .LeakyReLU The gradient of is as follows :
Is a super parameter greater than zero , Usually the value is 0.2、0.01. This can be avoided ReLU Neurons appear “ Death ” The phenomenon .LeakyReLU The gradient of is as follows :

A great integrator ELU

The ideal activation function should satisfy two conditions :
- The distribution of the output is zero mean , Can speed up the training .
- The activation function is one-sided saturated , Can better converge .
LeakyReLU It is relatively close to meeting the 1 Conditions , Not satisfied with the 2 Conditions ; and ReLU Satisfy the 2 Conditions , Not satisfied with the 1 Conditions . The activation function satisfying both conditions is ELU(Exponential Linear Unit), The mathematical expression is :
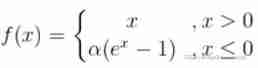
Input greater than 0 The gradient of the part is 1, Input less than 0 Part of the infinite approaches -α.
ELU Integrated sigmoid and ReLU, Soft saturation on the left , There is no saturation on the right , But the nonlinear optimization on the left also brings the disadvantage of losing computing speed .

Reference resources : Understand the activation function (Sigmoid/ReLU/LeakyReLU/PReLU/ELU) - You know
边栏推荐
- Cfdiv2 fixed point guessing- (interval answer two points)
- GBase 8c系统表-pg_constraint
- Awk from getting started to being buried (2) understand the built-in variables and the use of variables in awk
- Gbase 8C system table PG_ database
- Iptables layer 4 forwarding
- Codeforces Round #418 (Div. 2) D. An overnight dance in discotheque
- 人脸识别6- face_recognition_py-基于OpenCV使用Haar级联与dlib库进行人脸检测及实时跟踪
- GBase 8c系统表pg_database
- where 1=1 是什么意思
- JS的装箱和拆箱
猜你喜欢
4. Classes and objects
通达OA v12流程中心

Servlet中数据传到JSP页面使用el表达式${}无法显示问题

Detailed introduction to the usage of Nacos configuration center

Awk from introduction to earth (0) overview of awk

Flink CDC mongoDB 使用及Flink sql解析monggo中复杂嵌套JSON数据实现

easyPOI
4. 类和对象
The data in servlet is transferred to JSP page, and the problem cannot be displayed using El expression ${}
Summary of interview project technology stack
随机推荐
Y54. Chapter III kubernetes from introduction to mastery -- ingress (27)
Gbase 8C system table PG_ am
人脸识别6- face_recognition_py-基于OpenCV使用Haar级联与dlib库进行人脸检测及实时跟踪
Recommendation letter of "listing situation" -- courage is the most valuable
Detailed analysis of micro service component sentinel (hystrix)
Codeforces Round #418 (Div. 2) D. An overnight dance in discotheque
GBase 8c系统表-pg_am
GBase 8c系统表-pg_collation
COM and cn
GBase 8c系统表-pg_attribute
搭建私有云盘 cloudreve
UDP receive queue and multiple initialization test
Awk from getting started to getting into the ground (3) the built-in functions printf and print of awk realize formatted printing
[Hcia]No.15 Vlan间通信
Gbase 8C system table PG_ class
面试八股文整理版
GBase 8c 函数/存储过程参数(一)
GBase 8c系统表pg_database
Awk from introduction to earth (0) overview of awk
Word word word