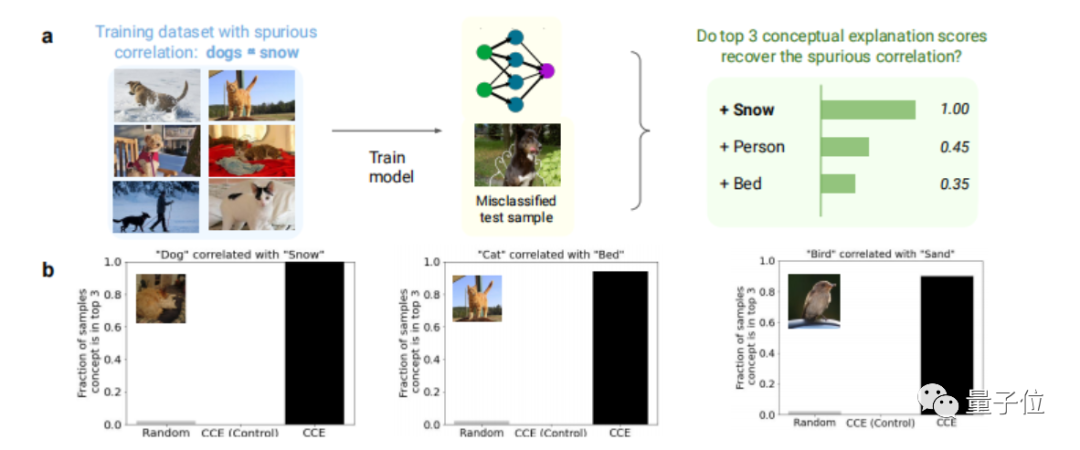
Overall overview
| example | describe |
|---|---|
[Pp]ython | matching “Python” or “python”. |
rub[ye] | matching “ruby” or “rube”. |
[abcdef] | Match any letter in bracket . |
[0-9] | Match any number . Be similar to [0123456789]. |
[a-z] | Match any lowercase letter . |
[A-Z] | Match any capital letters . |
[a-zA-Z0-9] | Match any letters and numbers . |
[^au] | except au All characters except letters . |
[^0-9] | Match characters other than numbers . |
| example | describe |
|---|---|
. | Matching elimination “\n” Any single character other than . To match includes ‘\n’ Any character inside , Please use something like ‘[.\n]’ The pattern of . |
? | Match a character zero times or once , Another function is the non greedy model |
+ | matching 1 Times or times |
* | matching 0 Times or times |
\b | Match a length of 0 The string of |
\d | Matches a numeric character . Equivalent to [0-9]. |
\D | Matches a non-numeric character . Equivalent to [^0-9]. |
\s | Matches any whitespace characters , Including Spaces 、 tabs 、 Page breaks and so on . Equivalent to [ \f\n\r\t\v]. |
\S | Matches any non-whitespace characters . Equivalent to [^ \f\n\r\t\v]. |
\w | Match any word character that includes an underline . Equivalent to ’[A-Za-z0-9_]’. |
\W | Match any non word character . Equivalent to ‘[^A-Za-z0-9_]‘. |
Character matching
Character set
Character set [] Allow matching a set Probably A single character that appears , We need to match multiple characters closely connected , No symbol separation is required .
Be careful : Only one character is matched in the character group , If you have determined the characters to match, you don't need to use character groups .
[Pp]ython
You can choose
python
Python
Section
Section - Allows us to match characters in a specified interval , Reduce the number of our writing .
- To match any number, you can use
[0-9]; - If you want to match all lowercase letters , It can be written.
[a-z]; - To match all capital letters, write
[A-Z]; - If you want to match from 5 To 8 The number of can be written as
[5-8].
Match special character
Sometimes the characters we want to match happen to have a specific meaning in regular expressions , At this time, we add \ Transference .
For example, we want to match characters -, But characters - Represents an interval in a character group , Then we can use escape character \ To paraphrase .
Match all characters -
[\-]
Take the opposite
Reverse sign ^ The negative symbol is only represented in the character group , Indicates that the character group is not taken ^ Words listed after .
such as [^123] Represents a match except 1,2,3 All characters except .
Shortcut matching
Match blanks
\s Represents a match Blank character , Including spaces 、tab、 Line break, etc
Match numbers and letters
\w It means to match any letter , Include case , Equate to [a-zA-Z].
\d Means to match any number , Equate to [0-9].
Word boundaries
Sometimes we just want to match a single word , At this time, we need to match word boundaries \b Symbol
For example, we have sentences i play on playground, If we use it directly play Pairs of words play Match , Will put words playground Medium play Also match in .
At this time , We need to use word boundaries , To match \bplay\b You can match a single play word .
The shortcut is reversed
You only need capital letters to reverse the shortcut .
such as \W、\D、\S、\bplay\B( It refers to extracting non word boundaries play) etc.
Start and end
In regular expressions Outside the character group ^ Specifies the beginning of a string ,$ Specifies the end of a string .
For example, here are two sentences
python is my favourite
this code in python
^python Means to extract with python Starting string .
python$ Means to extract with python a null-terminated string .
Any character
. Characters represent matches to any single character , it Can only appear outside the square bracket character group .
Optional characters
Sometimes , We may want to match different ways of writing a word , such as color and colour, perhaps honor And honour.
We can use it at this time ? The symbol specifies a character 、 Character groups or other basic units are optional , This means that the regular expression engine will expect this character to appear Zero or one .
such as honou?ru? Express u It's optional , It can appear or not , What can be matched is honor and honour .
If it is .? Represents any optional character , May or may not appear .
Match multiple characters
repeat
Add {N} Represents the number of times this character is repeated .
such as \d{4}, Express \d Repeat it four times , Equate to \d\d\d\d, Means to match a four digit number .
Repetition interval
Maybe sometimes , We don't know how many times to match the character group , For example, the ID card has 15 There are also 18 Bit .
Repeat the interval here and you can play , grammar :{M,N},M Is the lower bound and N It's the upper bound .
For example, we need to match three digits , Four and five digits , You can use it \d{3,5} To match .
\d{3,4} Can match 3 A number can also match 4 A digital , But when there is 4 A number , The priority match is 4 A digital , This is because regular expressions default to Greedy mode , That is, match as many characters as possible , And you want to use Non greedy model , We will be having Add... After the expression ? Number .
Open close interval
{1,} Indicates that the repetition of characters has no boundary , It means matching one or countless .
+ Equate to {1,}
* Equate to {0,}
grouping
Group extraction
In regular expressions, there is also a way to grouping The mechanism of , When using grouping , In addition to getting the whole match . You can also select each group in the match .
Grouping is simple , Use () that will do .
For example, I have to extract <div>hello</div> Medium hello , We can use <div>(.*?)</div>
Or conditions
While using grouping, you can also use perhaps (or) Conditions .
For example, to extract the suffix of all picture files , You can add a | Symbol .
such as (.jpg|.gif|.png)
Non capture grouping
occasionally , We don't need to capture the content of a group , But I want to use the characteristics of grouping .
At this time, you can use the non capture group (?: expression ), thus Do not capture data , You can also use the function of grouping .
such as 0731-75855, We just extract 75855, It can be used (?:\d{4})-(\d{5})
Group backtracking
Backtracking reference of group , Use \N The reference number is N The grouping .
For example, we have <div>hello</div>, We can use <(\w+)>(hello)</\1>, Inside \1 It stands for , The value in the first grouping in the expression .
Greedy mode and non greedy mode
Greedy mode : Regular expressions tend to match the maximum length , Always match as many characters as possible .
Non greedy model : Regular expressions tend to match the shortest length , Always match as few characters as possible .
For example, there is a string abcdefabc
Here are regular expressions a.*c
The matching result in greedy mode is :abcdefabc
In the non greedy mode, the matching result is :abc
In regular expressions , By default, greedy mode , If we want to use non greedy mode, we need to add a after the quantifier ?, such as a.*?c