1. Problem site
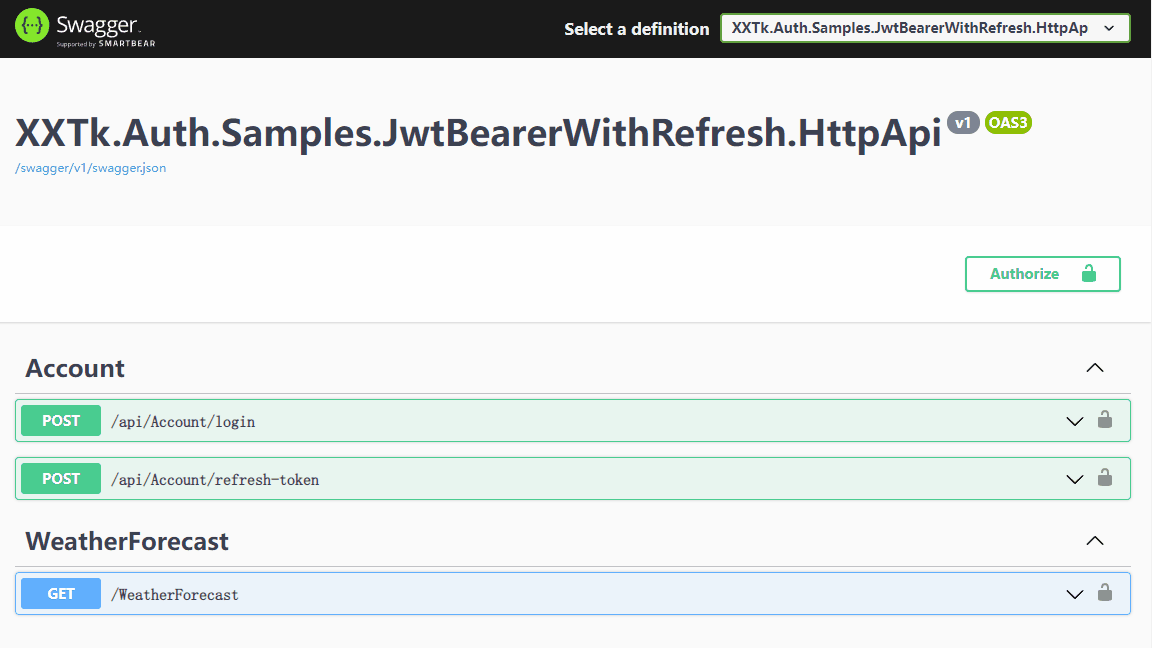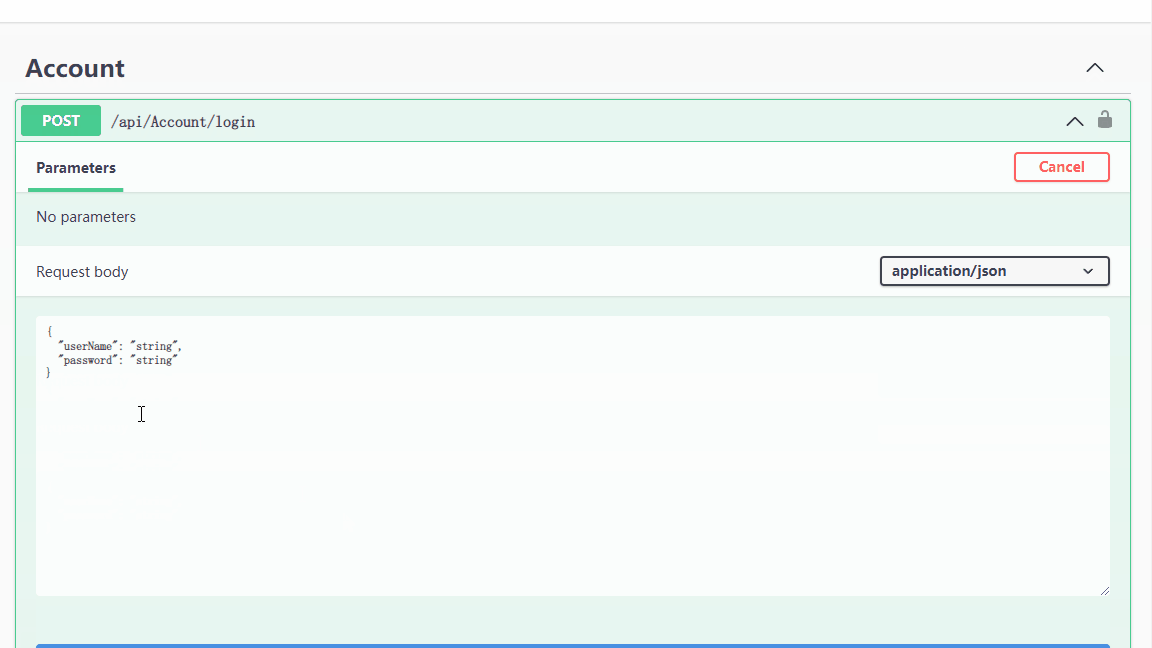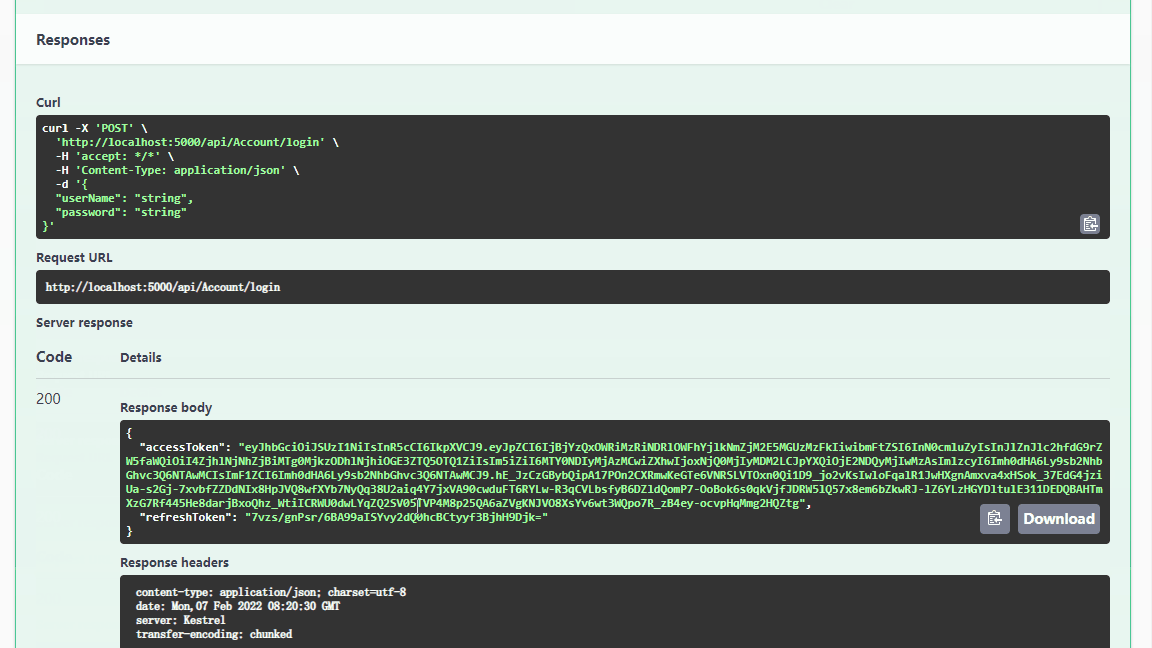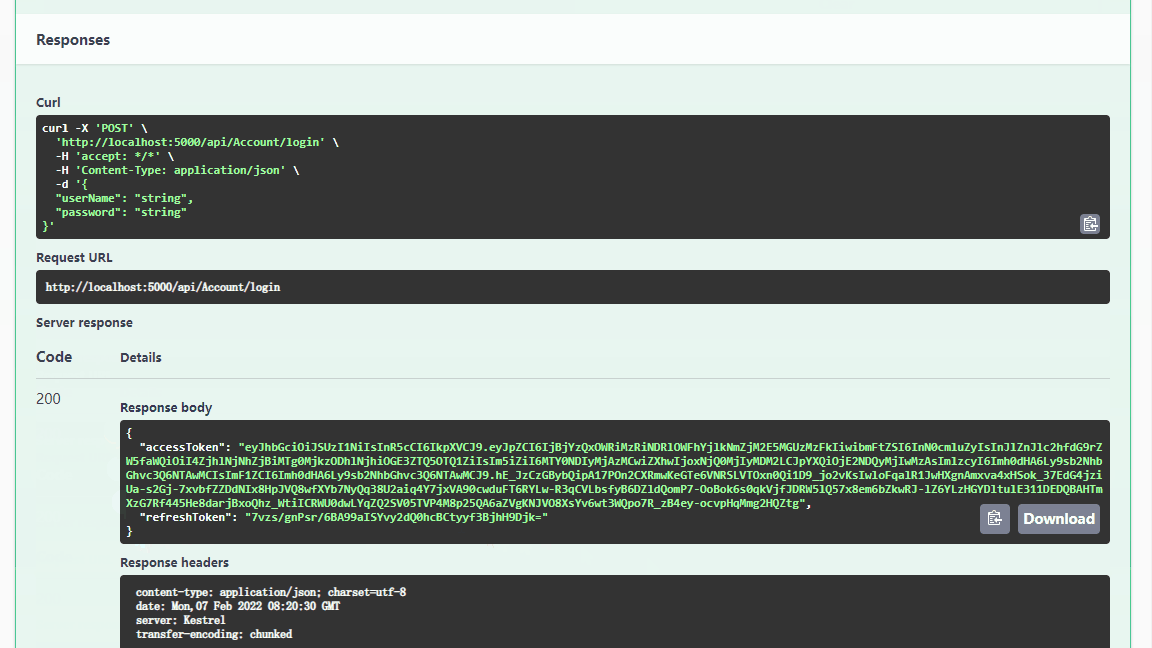
In recent days, , adopt IMP Monitoring discovery , Production container environment gc Very frequent - about 40s once , And are minor gc, Concrete gc The log is as follows :
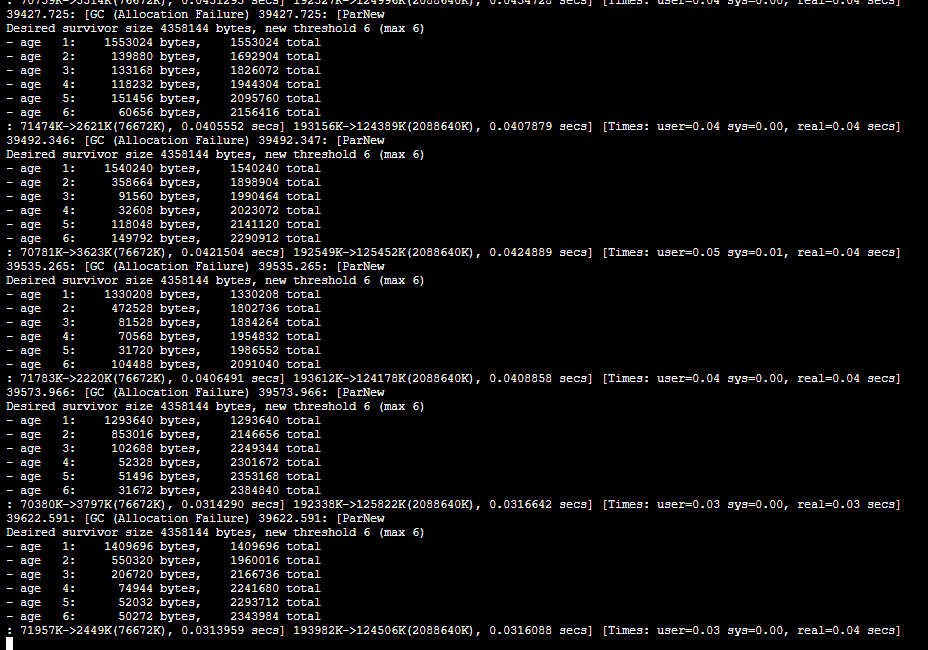
As can be seen from the picture above ,gc It happened in ParNew On the collector , The trigger reason is Allocation Failure. At present java The garbage collector configured by the process is CMS, The corresponding collector of the new generation is ParNew, The above figure fully shows that frequent minor gc, Every time minor gc The time is 30~40ms,minor gc There will be STW(Stop The Word), therefore , So often gc It is bound to have a negative impact on the application . that , So often minor gc How did it come about ?
2. Problem analysis
2.1 frequent minor gc The impact
From the front we can see , The application is used frequently minor gc, And minor gc Cause the application to pause (STW), that , How much impact does it have on Applications ?
One obvious point is , because minor gc It can lead to STW, So in minor gc occurs , It will prolong the response time of the application , If the response time of the application under normal state is 100ms, So it's triggering minor gc when , because STW Influence , The response time will change to 100+40=140ms.
in addition , From the whole point of view , We can apply the following formula to analyze minor gc Yes GC throughput ( In a nutshell , Throughput refers to the proportion of application thread time to the total program time . for example , throughput 99/100 signify 100 Seconds of program execution time. The application thread is running 99 second , And in this period of time GC The thread only runs 1 second ) Influence :
In the current situation , Suppose the time period is 4 minute , that , With 40s Trigger once gc Calculation ,gc The number of triggers is 4
60/40=6 Time , Every time gc The time is in the order of 40ms Calculation , Then the throughput is (1-(6
40)/(4
60
1000))*100%=99.9%, This means at least 0.1% In time , Apps are not available ( Of course, there is no perception at the user level ).
2.2 GC Log analysis
Pick a paragraph GC The text of the log is as follows :
46834.030: [GC (Allocation Failure) 46834.031: [ParNew
Desired survivor size 4358144 bytes, new threshold 6 (max 6)
- age 1: 1200496 bytes, 1200496 total
- age 2: 673016 bytes, 1873512 total
- age 3: 145352 bytes, 2018864 total
- age 4: 180720 bytes, 2199584 total
- age 5: 153152 bytes, 2352736 total
- age 6: 170024 bytes, 2522760 total
: 71467K->4646K(76672K), 0.0318805 secs] 212747K->146025K(2088640K), 0.0320934 secs] [Times: user=0.03 sys=0.00, real=0.04 secs]
Briefly explain the above GC journal : first line GC The time point of occurrence is after the application starts 46834.030 second , Trigger GC The reason is that Allocation Failure, The collector is ParNew.
The second line Desired survivor size The value of is 4358144 bytes=4.156M( This value is survivor Area capacity * TargetSurvivorRatio/100,TargetSurvivorRatio The default value is 50), The maximum age of dynamic calculation new threshold yes 6.
The third to eighth lines are the information of all age groups , With age 2 For example ,673016 bytes In the new generation age=2 The amount of memory occupied by the object ,1873512 total Is the Cenozoic all less than or equal to 2 Age objects occupy memory (1200496+673016=1873512) Size .
The information in the ninth line is critical ,71467K->4646K(76672K) in ,71467K yes GC The previous memory area ( This is the new generation ) Use capacity ,4646K yes GC After that, the memory area use capacity ,76672K Is the total capacity of the memory area .212747K->146025K(2088640K) in ,212747K yes GC Memory size in the front heap ,146025K yes GC Memory size in the post heap ,2088640K Is the total size of the heap .[Times: user=0.03 sys=0.00, real=0.04 secs] We compare the relationship real=0.04 secs, On behalf of this GC The time actually spent , Please refer to the appendix for the specific meanings of these parameters 4.2 chapter .
Here we can see ,GC Capacity before 71467K=69.79M A very small , The total size of the Cenozoic is 76672K=74.875M Also exceptionally small . In the current case , We have not set the size of the Cenozoic , have access to jinfo Command to view the current java Progress :
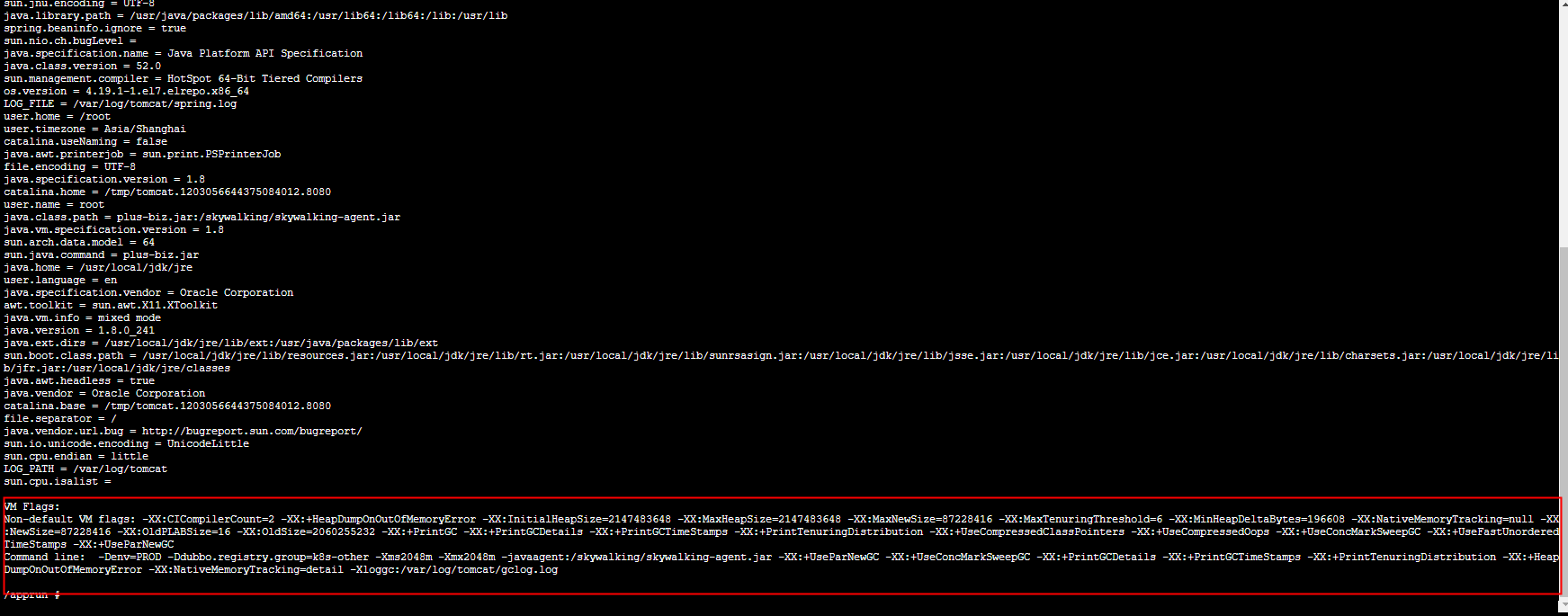
In the red frame Non-default VM flags Right and wrong vm Default parameters ( Overridden by command line options or vm Optimize policy settings ),Command line Is the command line parameter at startup , See from the start command , We didn't set up Xmn perhaps NewSize、MaxNewSize Parameters , The reason why it is not set is that we think there is no problem with the Cenozoic size calculated by using the default parameters ( This works well in a virtual machine environment ), Default Cenozoic size and NewRatio Parameters are related to , The meaning of this parameter is the ratio of the size of the old age to the size of the Cenozoic , We can also see the current jvm The value of this parameter in :

If calculated in this way , Then the size of the Cenozoic should be 2048M*(1/3)=682.7M, This sum GC The values displayed in the log are completely inconsistent . The specific calculation is explained in oracle Official documents of (
https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/sizing.html#heap_parameters
) As shown in :
The Young Generation
After total available memory, the second most influential factor affecting garbage collection performance is the proportion of the heap dedicated to the young generation. The bigger the young generation, the less often minor collections occur. However, for a bounded heap size, a larger young generation implies a smaller tenured generation, which will increase the frequency of major collections. The optimal choice depends on the lifetime distribution of the objects allocated by the application.By default, the young generation size is controlled by the parameter NewRatio. For example, setting -XX:NewRatio=3 means that the ratio between the young and tenured generation is 1:3. In other words, the combined size of the eden and survivor spaces will be one-fourth of the total heap size.The parameters NewSize and MaxNewSize bound the young generation size from below and above. Setting these to the same value fixes the young generation, just as setting -Xms and -Xmx to the same value fixes the total heap size. This is useful for tuning the young generation at a finer granularity than the integral multiples allowed by NewRatio.
682.7M contrast 74.875M There's a huge difference , It shows that the way we calculate the Cenozoic generation is wrong ( At least not completely accurate ). Observe carefully , We can also see that jinfo Viewed Non-default VM flags There is NewSize and MaxNewSize, The values of both are 87228416, The unit is byte, After conversion is 83.1875M, This is the sum of GC The values in the log are very close .
What is the actual value of each area in the pile , We also have a tool -jmap, It can be used jmap Check the actual situation in the heap :
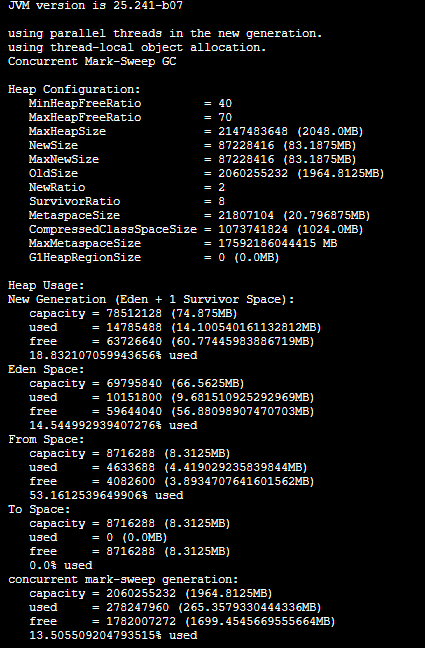
The results are clear ,NewSize=83.1875M, This sum jinfo The values you see are consistent , The new generation (New Generation) Its size is Eden District and a Suvivor The size of the area , On the startup command line , We didn't set up SurvivorRatio Value , So use the default value 8( About equal to ), It means Eden Area and Suvivor The proportion of districts is 8:1, So one Suvivor The size of the zone is NewSize Of 1/10, The actual value here is 8.3125, The size of the new generation is 66.5625=8.3125=74.875M, This sum GC The capacity of the Cenozoic in the log is consistent .
thus , What we can be sure of is , At present java The memory size of each region in the process heap and GC The values in the log are consistent , however , There is no solution NewSize=83.1875M The source of .
at present , There seems to be no other solution to the problem , We can only start with the source code . from github download openjdk Source code (
https://github.com/openjdk/jdk
), Switch to the branch corresponding to the version jdk8-b07, Global search MaxNewSize, From the search results, we locate this file /jdk/hotspot/src/share/vm/runtime/arguments.cpp, There is a way
void Arguments::set_cms_and_parnew_gc_flags()
Used to adjust CMS Collectors and ParNew Collector's GC Parameters , It's different from our current java The collectors used by the process are consistent .
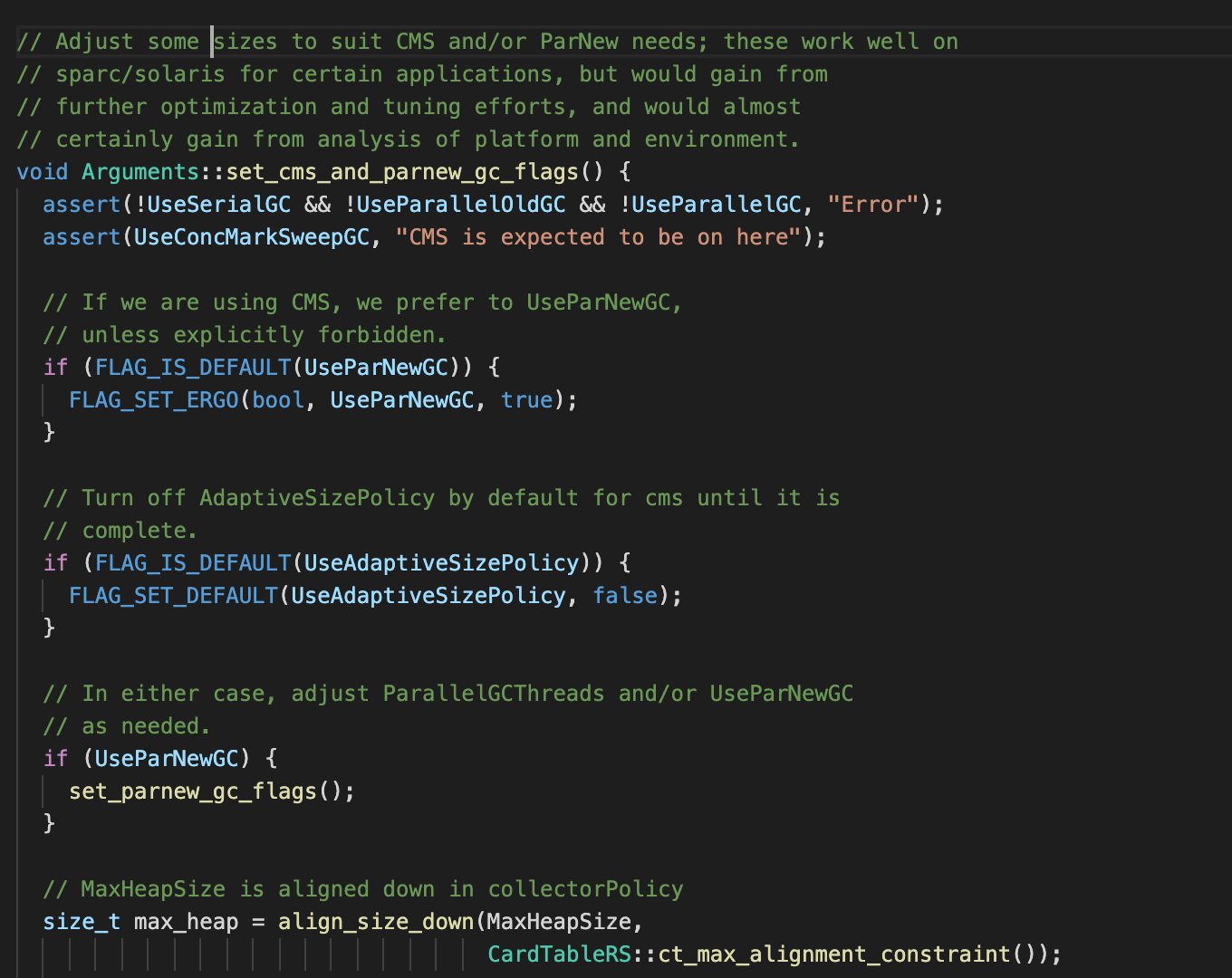
Here we directly extract a very critical paragraph :
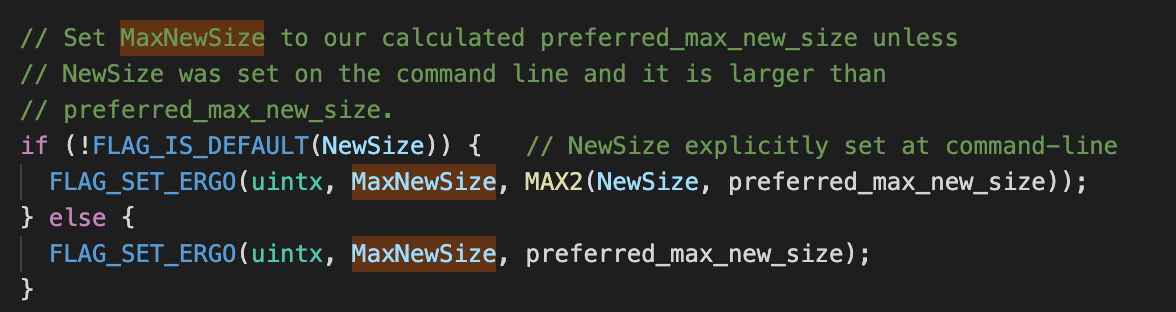
We can see it from here , If the command line is not explicitly set NewSize, that MaxNewSize The value of is
preferred_max_new_size
,
preferred_max_new_size
The value of is defined in :
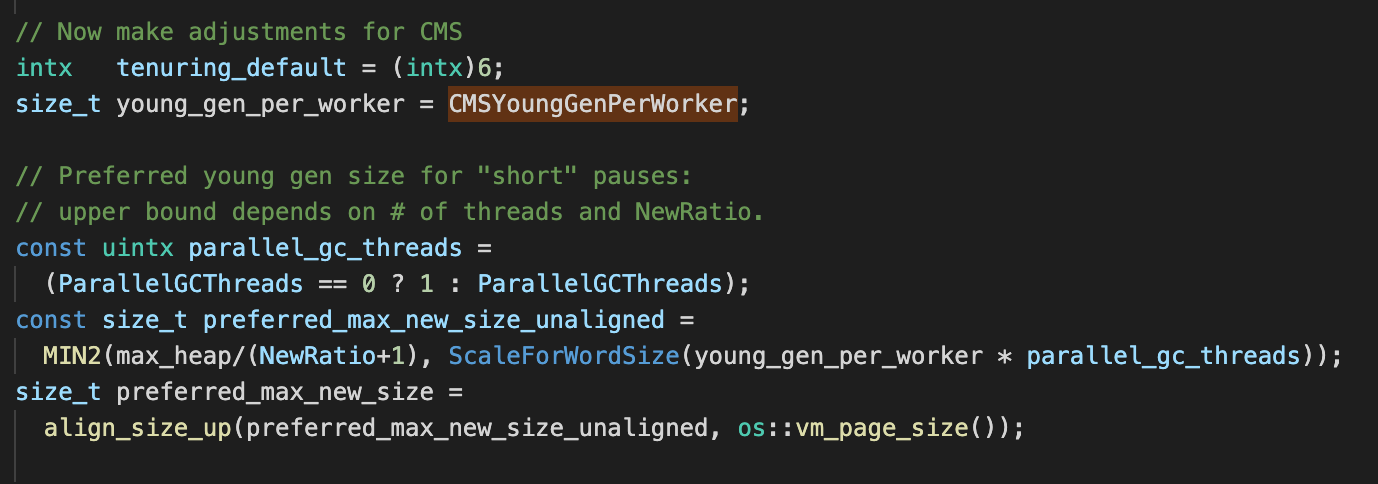
preferred_max_new_size
yes
preferred_max_new_size_unaligned
Byte alignment , and
preferred_max_new_size_unaligned
from max_heap/(NewRatio+1) and ScaleForWordSize(young_gen_per_worker * parallel_gc_threads) The small value in determines ,max_heap/(NewRatio+1) We calculated it before , The value is 682.7M.ScaleForWordSize The calculation result of the method is given by young_gen_per_worker and parallel_gc_threads decision , among parallel_gc_threads from
ParallelGCThreads
Parameter determination ,
ParallelGCThreads
It can be used jinfo Check it out. :

ParallelGCThreads
The value of is 1( This value is not explicitly set , Why 1 It will be explained later ),young_gen_per_worker The value is equal to the CMSyoungGenPerWorker, This value is in x86 On your machine is 64M:

Look again. ScaleForWordSize Method :

HeapWordSize stay 64 Bit machine for 8 byte , The result of the above calculation is about 83.20M, After the final alignment is 83.1875M, This is the final MaxNewSize Value , Of course, this is applicable to CMS+ParNew The collector . and NewSize The value of can also be through MaxNewSize The value of is finally determined :
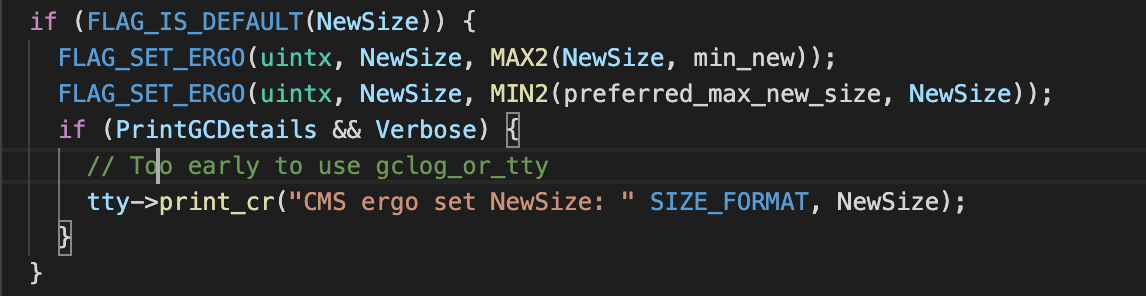
2.3
ParallelGCThreads
analysis
We mentioned above ,
preferred_max_new_size_unaligned
The value of is and
ParallelGCThreads
Relevant , Where did you get this value ? It can be through command line parameters
-XX:ParallelGCThreads=value
Direct designation , When the command line parameters are not specified , It will be based on CPU To calculate the number of cores .
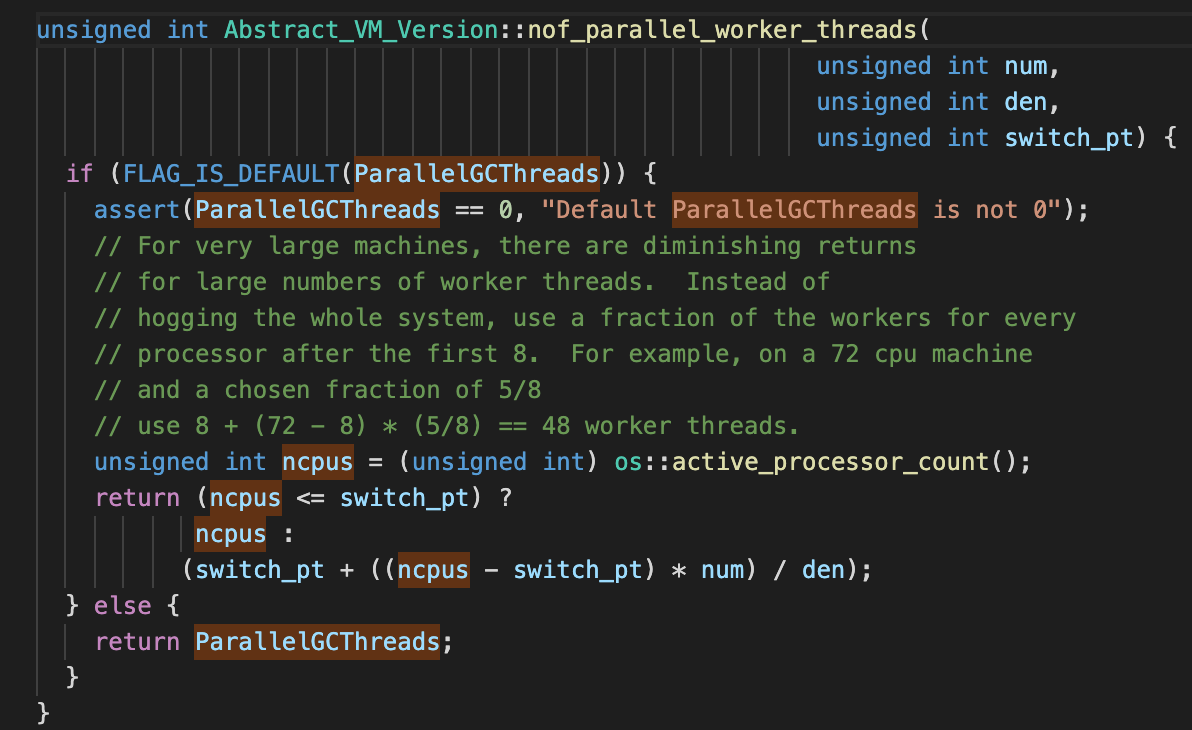
For most machines ,switch_pt The value of is 8, We can also see in the notes , When CPU The number of cores of is less than or equal to 8 when ,
ParallelGCThreads
The value of and CPU Auditing is equal , When CPU The number of cores of is greater than 8 when , The way of calculation is (8+(ncpus-8)*5/8). stay oracle It is also described in the official documents of :
On a machine with
N
hardware threads where
N
is greater than 8, the parallel collector uses a fixed fraction of
N
as the number of garbage collector threads. The fraction is approximately 5/8 for large values of
N
. At values of
N
below 8, the number used is
N
. On selected platforms, the fraction drops to 5/16. The specific number of garbage collector threads can be adjusted with a command-line option (which is described later). On a host with one processor, the parallel collector will likely not perform as well as the serial collector because of the overhead required for parallel execution (for example, synchronization). However, when running applications with medium-sized to large-sized heaps, it generally outperforms the serial collector by a modest amount on machines with two processors, and usually performs significantly better than the serial collector when more than two processors are available.
The official documents are more straightforward , When N Greater than 8 When the value of , The factor is close to 5/8. According to this algorithm , our
ParallelGCThreads
It can't be equal to 1 Of ( Production environment hardware CPU The number is not always 1), So what's the problem ?
At present, there is a very important scenario , We are in a container environment . Running on production java The version is jdk 8, and jdk 8 The first official version of was released in 2014 year 3 month ( Originally scheduled for 2013 year ).2013 year 3 month Docker founder Solomon Hykes stay PyCon The first public speech at the conference was introduced Docker This product ,2014 year 6 Of the month DockerCon At the conference Docker Officially released Docker 1.0 edition ,Docker The stability and reliability of have basically met the operation requirements of the production environment . You can see , Early java In the version ,docker Technology is not very popular , This also means early jvm Virtual machine in docker There are more or less problems running in the environment .
We can pass first cat /proc/cpuinfo Look at the host where the container is located CPU Check the number :
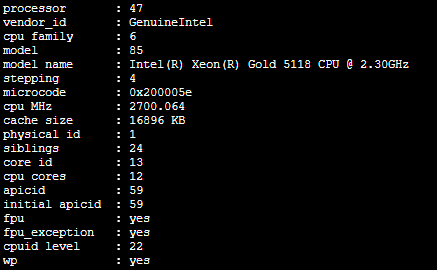
processor From 0 Start calculating , that CPU The core number is 48. According to the previous calculation , If jvm It's from the host computer CPU Check the number , that
ParallelGCThreads
The value should be 48*5/8=30 about , This is obviously inconsistent with our actual situation . As we mentioned earlier , because jdk 8 When it was released ,docker There is no mass epidemic , therefore docker The environment runs early java There will be some problems with the version , Actually, this is one of them . Run in a container java The program , The application may or may get the wrong CPU resources , This leads to errors in program judgment , Cause some unnecessary context switching .
Fortunately, , from Java SE 8u131 Start and in JDK 9 in ,JVM Yes Docker CPU Restrict transparent perception Docker. This means that if
-XX:ParalllelGCThreads
or
-XX:CICompilerCount
Not specified as a command line option , be JVM Will be applied Docker CPU limit As JVM What you see on the system CPU Number . then JVM Will adjust GC Threads and JIT Number of compiler threads , Just like it runs on bare metal systems ,CPU The quantity is set to Docker CPU limit.
Currently we set cpu limit yes 1000m, When not explicitly configured
ParallelGCThreads
In this case, the parameter is 1, Thus, through a series of calculations mentioned above , bring jvm Of MaxNewSize and NewSize The value of is 83.1875M. After knowing this information , We tried to modify CPU limit Value , It is modified to be greater than 1000m Less than 2000m when ,
ParallelGCThreads
The value of is 2, Use jmap Viewing the various areas of the heap has also changed :
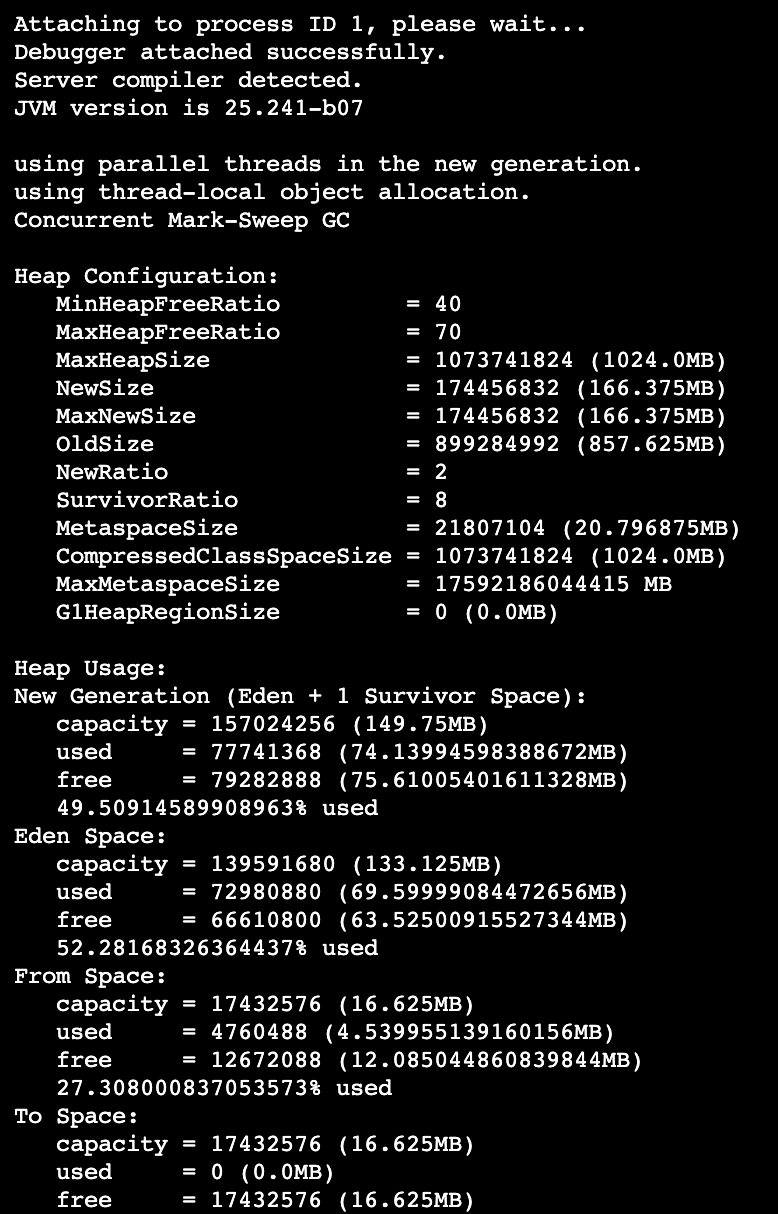
here ,NewSize and MaxSize The value of becomes 166.375M, Twice the original .
3. Problem solving
After a detailed analysis of the problem , We come to the conclusion that :minor gc The frequent reason is that the Cenozoic generation is too small , Too small because there is no explicit configuration MaxNewSize and NewSize Value , This triggers jvm A series of mechanisms , Finally, a value is calculated . That needs to be solved minor gc Frequent questions are simple , Set... On the command line -Xmn512M( It's equivalent to setting MaxNewSize and NewSize Value , Specific application and specific analysis ) that will do , in addition , our
ParallelGCThreads
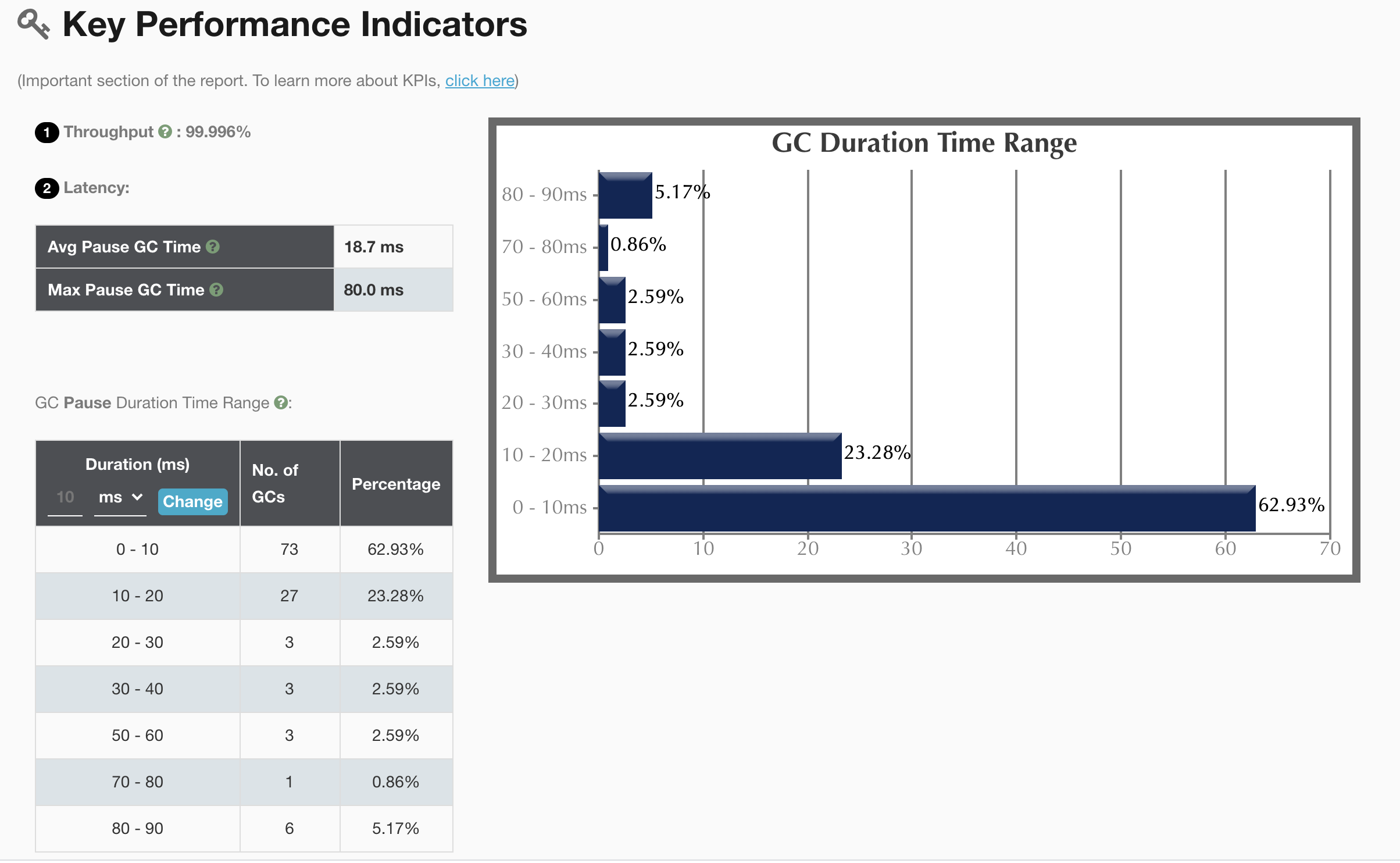
There are also problems , Add -XX:ParallelGCThreads=8 Configuration of , After configuration , We observed GC journal ,minor gc The time interval from the original 40s Promoted to 7 minute , Extracted nearly 13 Hour gc Log analysis is as follows :
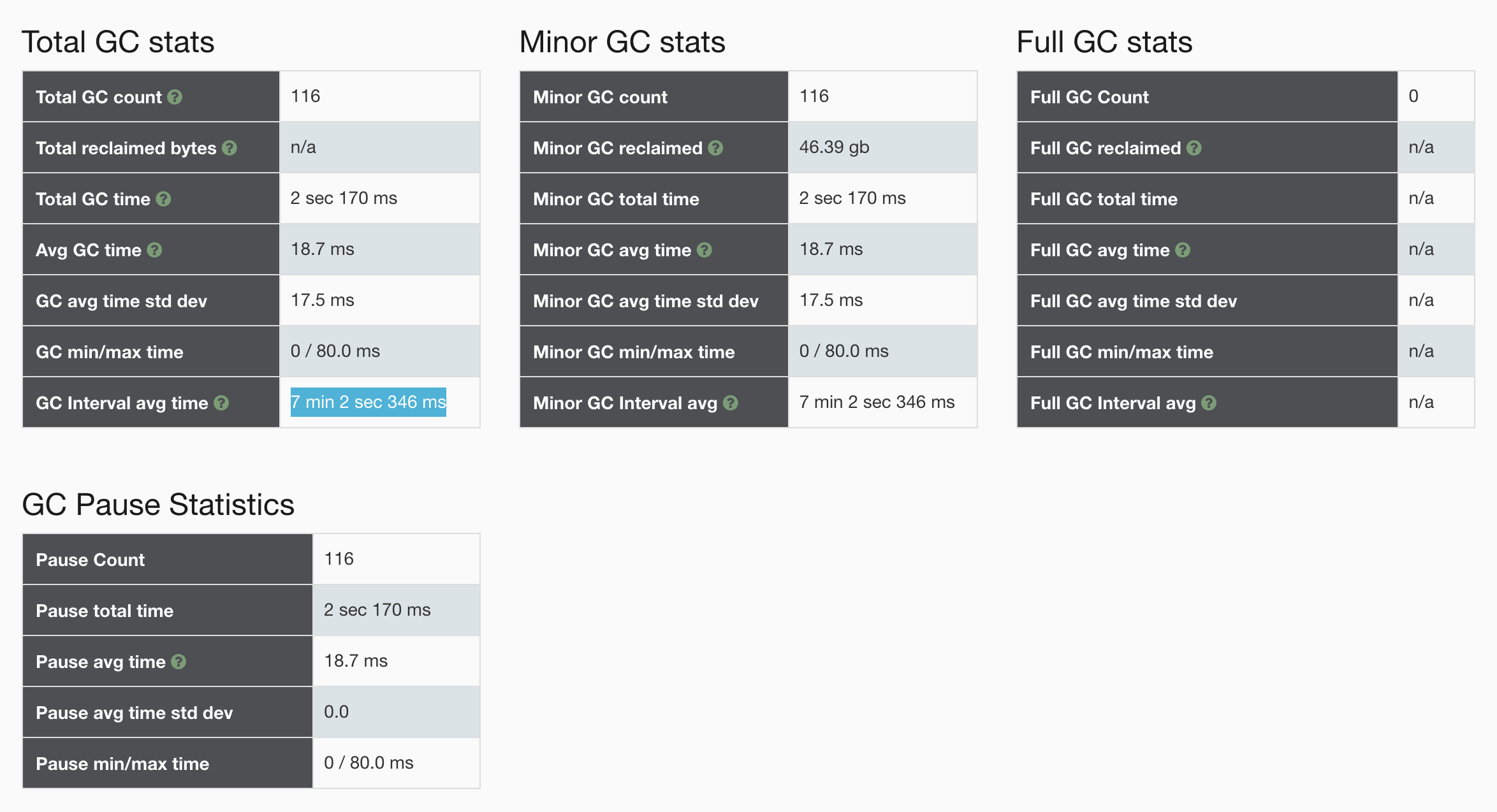
4. appendix
4.1 Dynamic object age determination
stay 《 In depth understanding of java virtual machine 》 There is a passage in the Third Edition :
In order to better adapt to the memory conditions of different programs ,HotSpot The immortality of virtual machine does not always require the age of the object to reach -XX:MaxTenuringThreshold To rise to the old age , If in Survivor The total size of all objects below or equal to a certain age in the space is greater than Survivor Half of the space , Those whose age is greater than or equal to that age can enter the old age directly , No need to wait -XX:MaxTenuringThreshold The age required in .
How to understand this passage ?
above gc journal ( This is before the adjustment of the Cenozoic ) in , There is such a passage :
Desired survivor size 4358144 bytes, new threshold 6 (max 6)
- age 1: 1200496 bytes, 1200496 total
- age 2: 673016 bytes, 1873512 total
- age 3: 145352 bytes, 2018864 total
- age 4: 180720 bytes, 2199584 total
- age 5: 153152 bytes, 2352736 total
- age 6: 170024 bytes, 2522760 total
Desired survivor size The value of is 4358144 bytes=4.156M( This value is survivor Area capacity *TargetSurvivorRatio/100,TargetSurvivorRatio The default value is 50), at that time survivor The capacity of the zone is 8.3125M.max 6 It stands for -XX:MaxTenuringThreshold, This value is not set in the command line , The default value is used 6. With age 6 For example , Current age is less than or equal to 6 The size of the object is 2522760 bytes, Less than 4358144 bytes, So the calculated dynamic age is equal to XX:MaxTenuringThreshold Value 6. Well, if age 5 The total size of has been greater than 4358144 bytes 了 , be new threshold Would be 5, Older than or equal to age 5 All the objects will directly enter the elderly .
If the dynamic age is calculated new threshold Too small , As a result, a large number of objects enter the elderly generation too early , Consider adjusting SurvivorRatio Value , take Survivor Enlarge the space .
4.2 usr, sys, real meaning
user and sys It's processor time ,real It's clock time , The difference between them is that processor time represents the time-consuming count of threads occupying a core , And clock time is the count of time in the real world . If it is a single core and single thread scenario , The two can be considered equivalent , But in a multi-core scenario , How many processor cores are working in the same clock time , How many times the processor time will be consumed and recorded .
When tuning garbage collection , We mainly rely on real Optimize the program with time as the goal , Because the end user only cares about the time from sending the request to responding , That is, response speed , It doesn't care how many threads or processors the program uses to complete the task .
原网站版权声明
本文为[InfoQ]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/185/202207041504176959.html