当前位置:网站首页>Transformer中position encoding实践
Transformer中position encoding实践
2022-07-04 14:54:00 【初学者chris】
近年来,transformer由于其可以实现并行计算且可以解决长序列的依赖问题在nlp领域和cv领域大放异彩。
原理图如下所示: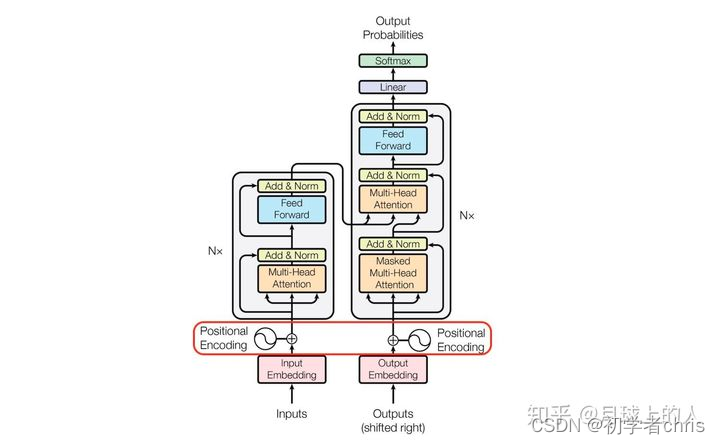
这里我们主要关注一个小部分,即position encoding部分,因为transformer取消了循环依赖,为了体现位置属性,所以给每个元素进行位置编码。
代码如下所示,至于为什么会这么写,可以参考作者原文,或者参考一下文章。https://zhuanlan.zhihu.com/p/338592312
代码如下:
class PositionalEncoding(torch.nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)#(max-len,1,d_model)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(1), :].squeeze(1)
#x = x + self.pe[:x.size(1), :]
return x
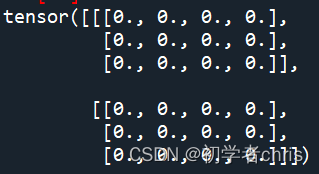
为了测试,我们定义两个输入矩阵,分别为全0、全1tensor。
d_model = 4
a=torch.zeros(2,3,4)
pos=PositionalEncoding(d_model)
b=pos(a)
c=torch.ones(2,3,4)
b1=pos(c)
很明显,输入矩阵为
输出为b,b1,如下所示:;
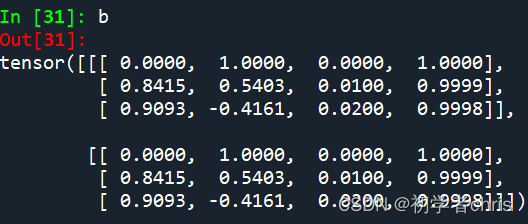
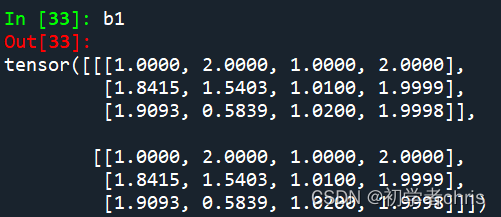
可以看出,都是在输入的基础之上,加上了固定值,而那些固定值就是编码得到的,与输入无关,与d_model有关,d_model可以理解为单词的embedding大小。
边栏推荐
- Vscode prompt Please install clang or check configuration 'clang executable‘
- Model fusion -- stacking principle and Implementation
- [North Asia data recovery] data recovery case of database data loss caused by HP DL380 server RAID disk failure
- Selenium browser (2)
- Some fields of the crawler that should be output in Chinese are output as none
- Recommend 10 excellent mongodb GUI tools
- . Net delay queue
- Qt---error: ‘QObject‘ is an ambiguous base of ‘MyView‘
- DC-2靶场搭建及渗透实战详细过程(DC靶场系列)
- Nine CIO trends and priorities in 2022
猜你喜欢
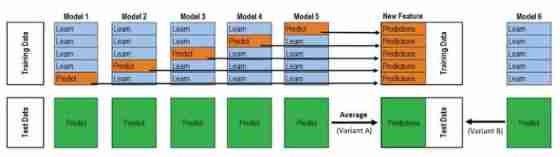
Model fusion -- stacking principle and Implementation
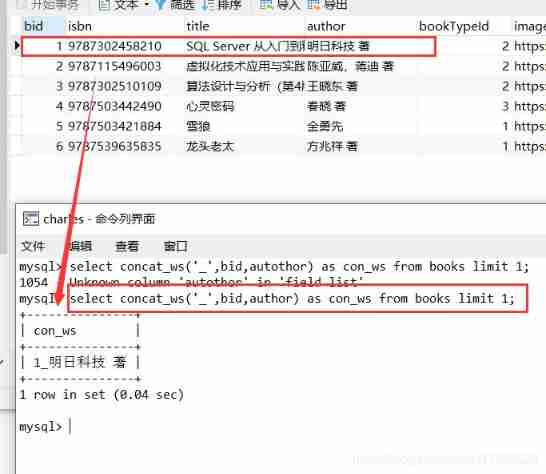
Penetration test --- database security: detailed explanation of SQL injection into database principle

What should ABAP do when it calls a third-party API and encounters garbled code?

Audio and video technology development weekly | 252
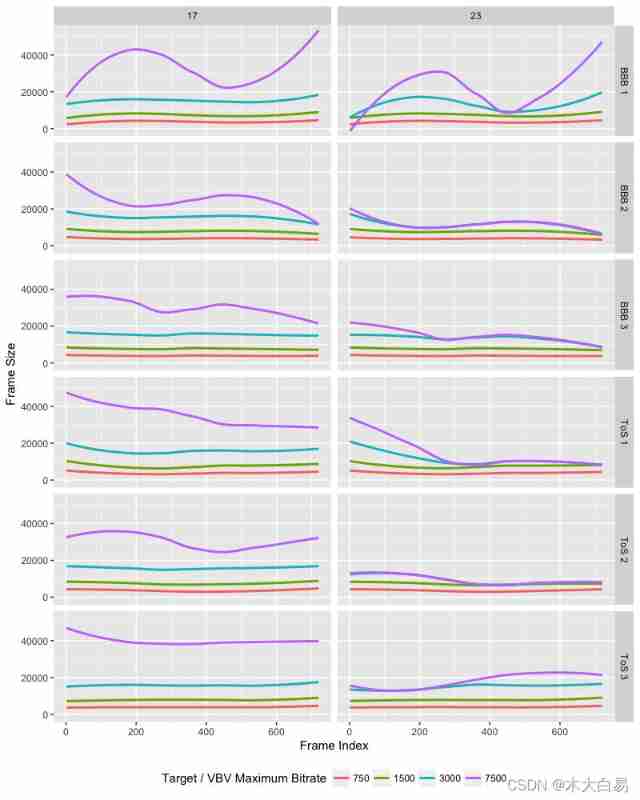
Understand the rate control mode rate control mode CBR, VBR, CRF (x264, x265, VPX)

DIY a low-cost multi-functional dot matrix clock!

程序员怎么才能提高代码编写速度?

Vscode prompt Please install clang or check configuration 'clang executable‘
Using celery in projects

I let the database lock the table! Almost fired!
随机推荐
~89 deformation translation
Research Report on market supply and demand and strategy of China's Sodium Tetraphenylborate (cas+143-66-8) industry
Functional interface, method reference, list collection sorting gadget implemented by lambda
Socks agent tools earthworm, ssoks
Accounting regulations and professional ethics [11]
Redis: SDS source code analysis
Anta is actually a technology company? These operations fool netizens
One question per day 540 A single element in an ordered array
[book club issue 13] coding format of video files
The content of the source code crawled by the crawler is inconsistent with that in the developer mode
函數式接口,方法引用,Lambda實現的List集合排序小工具
How can floating point numbers be compared with 0?
ECCV 2022放榜了:1629篇论文中选,录用率不到20%
Selenium element interaction
Unity script API - GameObject game object, object object
Vscode prompt Please install clang or check configuration 'clang executable‘
科普达人丨一文看懂阿里云的秘密武器“神龙架构”
How was MP3 born?
Model fusion -- stacking principle and Implementation
[hcie TAC] question 5 - 1