摘要:高斯Redis 搭建业务二级索引,低成本,高性能,实现性能与成本的双赢。
本文分享自华为云社区《华为云GaussDB(for Redis)揭秘第21期:使用高斯Redis实现二级索引》,作者:高斯Redis官方博客。
一、背景
提起索引,第一印象就是数据库的名词,但是,高斯Redis也可以实现二级索引!!!高斯Redis中的二级索引一般利用zset来实现。高斯Redis相比开源Redis有着更高的稳定性、以及成本优势,使用高斯Redis zset实现业务二级索引,可以获得性能与成本的双赢。
索引的本质就是利用有序结构来加速查询,因而通过Zset结构高斯Redis可以轻松实现数值类型以及字符类型索引。
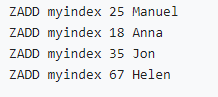
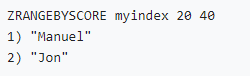
• 数值类型索引(zset按分数排序):
• 字符类型索引(分数相同时zset按字典序排序):

下面让我们切入两类经典业务场景,看看如何使用高斯Redis来构建稳定可靠的二级索引系统。
二、场景一:词典补全
当在浏览器中键入查询时,浏览器通常会按照可能性推荐相同前缀的搜索,这种场景可以用高斯Redis二级索引功能实现。
2.1 基本方案
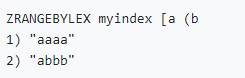
最简单的方法是将用户的每个查询添加到索引中。当需要进行用户输入补全推荐时,使用ZRANGEBYLEX执行范围查询即可。如果不希望返回太多条目,高斯Redis还支持使用LIMIT选项来减少结果数量。
• 将用户搜索banana添加进索引:
ZADD myindex 0 banana:1
• 假设用户在搜索表单中输入“bit”,并且我们想提供可能以“bit”开头的搜索关键字。
ZRANGEBYLEX myindex "[bit" "[bit\xff"
即使用ZRANGEBYLEX进行范围查询,查询的区间为用户现在输入的字符串,以及相同的字符串加上一个尾随字节255(\xff)。通过这种方式,我们可以获得以用户键入字符串为前缀的所有字符串。
2.2 与频率相关的词典补全
实际应用中通常希望按照出现频率自动排序补全词条,同时可以清除不再流行的词条,并自动适应未来的输入。我们依然可以使用高斯Redis的ZSet结构实现这一目标,只是在索引结构中,不仅需要存储搜索词,还需要存储与之关联的频率。
• 将用户搜索banana添加进索引
• 判断banana是否存在
ZRANGEBYLEX myindex "[banana:" + LIMIT 0 1
• 假设banana不存在,添加banana:1,其中1是频率
ZADD myindex 0 banana:1
• 假设banana存在,需要递增频率
若ZRANGEBYLEX myindex "[banana:" + LIMIT 0 1 中返回的频率为1
1)删除旧条目:
ZREM myindex 0 banana:1
2)频率加一重新加入:
ZADD myindex 0 banana:2
请注意,由于可能存在并发更新,因此应通过Lua脚本发送上述三个命令,用Lua script自动获得旧计数并增加分数后重新添加条目。
• 假设用户在搜索表单中输入“banana”,并且我们想提供相似的搜索关键字。通过ZRANGEBYLEX获得结果后按频率排序。
ZRANGEBYLEX myindex "[banana:" + LIMIT 0 10 1) "banana:123" 2) "banaooo:1" 3) "banned user:49" 4) "banning:89"
• 使用流算法清除不常用输入。从返回的条目中随机选择一个条目,将其分数减1,然后将其与新分数重新添加。但是,如果新分数为0,我们需从列表中删除该条目。
• 若随机挑选的条目频率是1,如banaooo:1
ZREM myindex 0 banaooo:1
• 若随机挑选的条目频率大于1,如banana:123
ZREM myindex 0 banana:123 ZADD myindex 0 banana:122
从长远来看,该索引会包含热门搜索,如果热门搜索随时间变化,它还会自动适应。
三、场景二:多维索引
除了单一维度上的查询,高斯Redis同样支持在多维数据中的检索。例如,检索所有年龄在50至55岁之间,同时薪水在70000至85000之间的人。实现多维二级索引的关键是通过编码将二维的数据转化为一维数据,再基于高斯Redis zset存储。
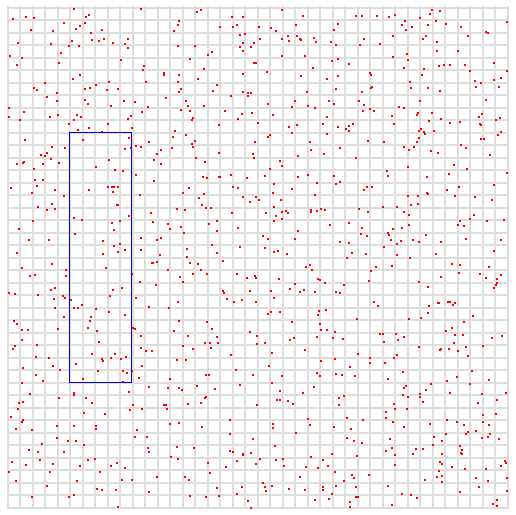
从可视化视角表示二维索引。下图空间中有一些点,它们代表我们的数据样本,其中x和y是两个变量,其最大值均为400。图片中的蓝色框代表我们的查询。我们希望查询x介于50和100之间,y介于100和300之间的所有点。
3.1 数据编码
若插入数据点为x = 75和y = 200
1) 填充0(数据最大为400,故填充3位)
x = 075
y = 200
2) 交织数字,以x表示最左边的数字,以y表示最左边的数字,依此类推,以便创建一个编码
027050
若使用00和99替换最后两位,即027000 to 027099,map回x和y,即:
x = 70-79
y = 200-209
因此,针对x=70-79和y = 200-209的二维查询,可以通过编码map成027000 to 027099的一维查询,这可以通过高斯Redis的Zset结构轻松实现。
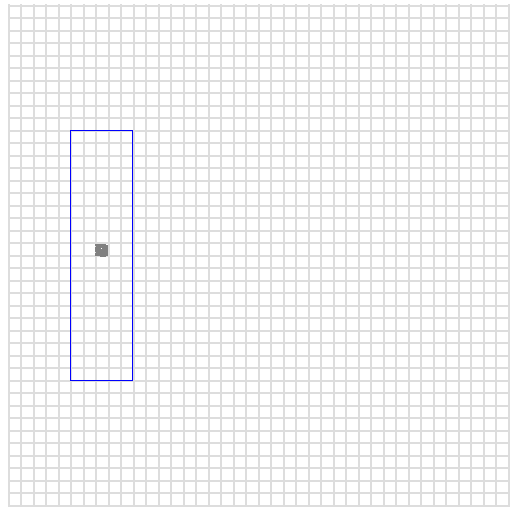
同理,我们可以针对后四/六/etc位数字进行相同操作,从而获得更大范围。
3) 使用二进制
为获得更细的粒度,可以将数据用二进制表示,这样在替换数字时,每次会得到比原来大二倍的搜索范围。假设我们每个变量仅需要9位(以表示最多400个值的数字),我们采用二进制形式的数字将是:
x = 75 -> 001001011
y = 200 -> 011001000
交织后,000111000011001010
让我们看看在交错表示中用0s ad 1s替换最后的2、4、6、8,...位时我们的范围是什么:

3.2 添加新元素
若插入数据点为x = 75和y = 200
x = 75和y = 200二进制交织编码后为000111000011001010,
ZADD myindex 0 000111000011001010
3.3 查询
查询:x介于50和100之间,y介于100和300之间的所有点
从索引中替换N位会给我们边长为2^(N/2)的搜索框。因此,我们要做的是检查搜索框较小的尺寸,并检查与该数字最接近的2的幂,并不断切分剩余空间,随后用ZRANGEBYLEX进行搜索。
下面是示例代码:
def spacequery(x0,y0,x1,y1,exp) bits=exp*2 x_start = x0/(2**exp) x_end = x1/(2**exp) y_start = y0/(2**exp) y_end = y1/(2**exp) (x_start..x_end).each{|x| (y_start..y_end).each{|y| x_range_start = x*(2**exp) x_range_end = x_range_start | ((2**exp)-1) y_range_start = y*(2**exp) y_range_end = y_range_start | ((2**exp)-1) puts "#{x},#{y} x from #{x_range_start} to #{x_range_end}, y from #{y_range_start} to #{y_range_end}" # Turn it into interleaved form for ZRANGEBYLEX query. # We assume we need 9 bits for each integer, so the final # interleaved representation will be 18 bits. xbin = x_range_start.to_s(2).rjust(9,'0') ybin = y_range_start.to_s(2).rjust(9,'0') s = xbin.split("").zip(ybin.split("")).flatten.compact.join("") # Now that we have the start of the range, calculate the end # by replacing the specified number of bits from 0 to 1. e = s[0..-(bits+1)]+("1"*bits) puts "ZRANGEBYLEX myindex [#{s} [#{e}" } } end spacequery(50,100,100,300,6)
四、总结
本文介绍了如何通过高斯Redis搭建二级索引,二级索引在电商、图(hexastore)、游戏等领域具有广泛的应用场景,高斯redis现网亦有很多类似应用。高斯Redis基于存算分离架构,依托分布式存储池确保数据强一致,可方便的支持二级索引功能,为企业客户提供稳定可靠、超高并发,且能够极速弹性扩容的核心数据存储服务。
附录
- 本文作者:华为云数据库GaussDB(for Redis)团队
- 杭州/西安/深圳简历投递:[email protected]
- 更多产品信息,欢迎访问官方博客:bbs.huaweicloud.com/blogs/248875