当前位置:网站首页>Classification automatique des cellules de modules photovoltaïques par défaut dans les images de lecture électronique - notes de lecture de thèse
Classification automatique des cellules de modules photovoltaïques par défaut dans les images de lecture électronique - notes de lecture de thèse
2022-07-07 19:50:00 【Wyypersist】
Automatic classification of defective photovoltaic module cells inelectroluminescence images
.Classification automatique des cellules photovoltaïques défectueuses dans les images d'électroluminescence
//2022.7.2Matin8:57Commencer à lire les notes
Adresse de la thèse
Contribution à la thèse
La contribution des travaux du présent document comprend trois parties..Tout d'abord,,.Nous proposons un cadre efficace sur le plan des ressources,Utilisé pour la classification supervisée des cellules solaires défectueuses à l'aide de classificateurs de machines vectorielles de support et de caractéristiques fabriqués à la main,..Support Vector Machine classifier peut être utilisé dans une large gamme de matériel commercial, Y compris les tablettes et les drones équipés d'une seule carte de faible puissance . Les faibles exigences en matière de calcul font que EL L'évaluation sur le terrain des images devient possible , Analyse similaire à l'image infrarouge à basse résolution (DotencoEt al.,2016).Deuxièmement,, Nous proposons un cadre de classification supervisé utilisant des réseaux neuronaux convolutifs , Le cadre est un peu plus précis ,Mais il fautGPU Formation et classification efficaces .En particulier, Nous avons montré comment intégrer l'incertitude dans ces deux cadres ,Pour améliorer la précision de la classification.Troisièmement, Nous avons fourni à la communauté un ensemble de données annotées , Cet ensemble de données a été créé par EL Extrait de l'image 2624 Composition des cellules solaires alignées , Nous avons utilisé cet ensemble de données pour effectuer une évaluation approfondie et une comparaison des méthodes proposées .
Contenu de la thèse
1.Introduction
Les modules solaires sont généralement protégés par des cadres en aluminium et des stratifiés en verre , Pour éviter la pluie 、 Effets environnementaux tels que le vent et la neige .Et pourtant, Ces mesures de protection n'empêchent pas toujours les modules photovoltaïques de tomber pendant l'installation 、 Les branches tombent 、 Dommages mécaniques causés par la grêle ou les contraintes thermiques .En outre,Erreur de fabrication( Par exemple, défaut de soudage ou défaut de câblage ) Peut également causer des dommages aux modules photovoltaïques . Les défauts réduisent à leur tour l'efficacité énergétique des modules solaires .Donc,, Nécessité de surveiller l'état des modules solaires , Et remplacer ou réparer l'unit é défectueuse , Pour assurer une efficacité maximale des centrales solaires .
Même pour les experts formés , L'identification visuelle des unités défectueuses est également particulièrement difficile . En plus des fissures évidentes sur le verre , De nombreux défauts qui réduisent l'efficacité des modules photovoltaïques sont invisibles à l'oeil nu .Au contraire., Les défauts visibles ne réduisent pas nécessairement l'efficacité du module .
Pour déterminer avec précision l'efficacité du module , La sortie électrique du module doit être mesurée directement .Et pourtant, Ces mesures nécessitent une interaction manuelle avec une seule Unit é pour le diagnostic. , Ils ne peuvent donc pas s'étendre à de grandes centrales solaires avec des milliers de modules photovoltaïques .En outre, Ce type de mesure ne capture qu'un seul point dans le temps , Par conséquent, il peut ne pas être possible de révéler certains types de petites fissures ,Avec le temps,Ce sera un problème(Kajari SchröderEt al.,2012).
Infrarouge(IR) L'imagerie est non destructive 、 Solutions de rechange sans contact , Pour évaluer la qualité des modules solaires . .Les modules solaires endommagés peuvent être facilement identifiés par des cellules solaires partiellement ou complètement déconnectées du circuit .Donc,, L'énergie solaire n'est plus convertie en électricité , Pour chauffer les cellules solaires .Et puis, Le rayonnement infrarouge émis peut être imagé par une caméra infrarouge .Et pourtant, La résolution de la caméra infrarouge est relativement faible , Il est donc impossible de détecter de petits défauts qui n'ont pas encore affecté l'efficacité de conversion photoélectrique des modules solaires. , Comme les microfissures .
L'électroluminescence (EL)Imagerie(FuyukiEt al.,2005;FuyukiEtKitiyanan,2009) Est une autre technologie non destructive mature d'analyse des défaillances des modules photovoltaïques , Capacité d'imagerie des modules solaires à une résolution plus élevée .InELEn images, Les cellules défectueuses semblent plus foncées , Parce que la partie déconnectée ne rayonne pas . Pour obtenir une image électroluminescente , Appliquer du courant aux modules photovoltaïques ,Et donc1150 nm électroluminescence induite à la longueur d'onde de . L'émission peut passer par un dispositif couplé à la charge de silicium (CCD) Imagerie par capteur . Haute résolution d'image spatiale capable de détecter les microfissures (BreitensteinEt al.,2011),EL L'imagerie n'est pas non plus floue en raison de la propagation latérale de la chaleur .Et pourtant,EL L'examen visuel des images est non seulement long et coûteux , Et des experts formés sont nécessaires .Dans ce travail, Nous proposons une classification automatique EL La méthode du défaut dans l'image , Ce qui élimine cette contrainte .
En général, Les défauts des modules solaires peuvent être classés en deux catégories: (FuyukiEtKitiyanan,2009):(1) Défauts inhérents dus aux propriétés des matériaux tels que les limites des grains et les dislocations ,Et(2) Défauts externes dus au procédé , Comme les microfissures et les fractures ,Avec le temps, Ces défauts réduisent l'efficacité globale des composants .
Fig.1 Montre des exemples avec différents types de défauts ELImages.Fig.1(a)Et(b) Les défauts généraux du matériau dans le processus de production sont indiqués , Par exemple, pointeur interrompu , Sauf en cas de déformation élevée au point de soudure , Sinon, la durée de vie des panneaux solaires touchés ne sera pas nécessairement réduite (KöntgesEt al.,2014).En particulier:, La perte d'efficacité causée par l'interruption du pointeur est sa taille 、 Interaction complexe entre la position et le nombre d'interruptions (De RoseEt al.,2012;KöntgesEt al.,2014).Fig.1(c)à(e) Montre des microfissures 、 Dégradation de l'interconnexion des batteries , Et les batteries ayant des sections séparées ou dégradées électriquement qui sont connues pour réduire l'efficacité des modules . En particulier, la détection des micro - fissures nécessite une caméra à haute résolution spatiale .

Pour la détection des défauts pendant la surveillance , Différents objectifs peuvent être fixés . Mettre en évidence l'emplacement exact des défauts dans les modules solaires , La zone touchée peut être surveillée avec une grande précision .Et pourtant, Pour l'évaluation de la qualité de l'ensemble des modules photovoltaïques , L'emplacement exact des défauts dans les cellules solaires n'est pas important .Pour cette tâche, La probabilité globale d'indication d'un défaut cellulaire est plus importante . Cela permet d'identifier rapidement les zones défectueuses , Et peut compléter les prévisions de perte d'efficacité future dans les modules photovoltaïques .Dans ce travail, Nous proposons deux pipelines de classification pour résoudre automatiquement la deuxième tâche , C'est - à - dire déterminer la probabilité d'un défaut de chaque Unit é qui pourrait entraîner une perte d'efficacité. .
Les méthodes de classification étudiées dans cet article sont la machine vectorielle de soutien et le classificateur de réseau neuronal. .
Support Vector Machine(SVM) Selon les cellules solaires EL Formation aux caractéristiques extraites des images .
Réseau neuronal convolutif(CNN) Entrée directe des pixels d'image des cellules solaires et des étiquettes correspondantes .
La méthode SVM est particulièrement efficace dans la formation et le raisonnement . Cela permet d'utiliser la méthode sur un large éventail de matériel commercial , Comme une tablette ou un drone , Leur utilisation dépend de leurs scénarios d'application respectifs .Au contraire.,CNN La précision des prévisions est généralement plus élevée , Et la formation et le raisonnement prennent plus de temps ,Normalement, il fautGPU Fonctionnement dans des délais acceptables et courts .Et pourtant, En particulier pour les images aériennes , D'autres problèmes peuvent survenir ,Il faut y remédier..KangEtCha(2018) Plusieurs défis à relever avant d'appliquer notre approche en dehors de l'environnement de fabrication ont été soulignés. .
1.1 Contribution
La contribution des travaux du présent document comprend trois parties..Tout d'abord,,.Nous proposons un cadre efficace sur le plan des ressources,Utilisé pour la classification supervisée des cellules solaires défectueuses à l'aide de classificateurs de machines vectorielles de support et de caractéristiques fabriqués à la main,..Support Vector Machine classifier peut être utilisé dans une large gamme de matériel commercial, Y compris les tablettes et les drones équipés d'une seule carte de faible puissance . Les faibles exigences en matière de calcul font que EL L'évaluation sur le terrain des images devient possible , Analyse similaire à l'image infrarouge à basse résolution (DotencoEt al.,2016).Deuxièmement,, Nous proposons un cadre de classification supervisé utilisant des réseaux neuronaux convolutifs , Le cadre est un peu plus précis ,Mais il fautGPU Formation et classification efficaces .En particulier, Nous avons montré comment intégrer l'incertitude dans ces deux cadres ,Pour améliorer la précision de la classification.Troisièmement, Nous avons fourni à la communauté un ensemble de données annotées , Cet ensemble de données a été créé par EL Extrait de l'image 2624 Composition des cellules solaires alignées , Nous avons utilisé cet ensemble de données pour effectuer une évaluation approfondie et une comparaison des méthodes proposées .
Fig.2 Les résultats de l'évaluation des panneaux solaires à l'aide du réseau neuronal convolutif proposé sont présentés .EL Chaque cellule solaire de l'image est couverte par la possibilité d'un défaut dans l'unit é correspondante .

1.2 Généralités
Le reste du travail est organisé comme suit: .No2 La section passe en revue les travaux pertinents .No3 La section présente les deux méthodes de classification proposées. .En4Section, Nous avons évalué et comparé ces méthodes , Et discute des résultats . Ce travail a été effectué dans le cadre de la 5 Fin de la section .
2.Travaux connexes
AdoptionEL La détection visuelle des modules solaires par imagerie est un sujet de recherche actif .Et pourtant, La plupart des travaux connexes sont axés sur la détection de défauts internes ou externes spécifiques. , Plutôt que de prévoir les défauts qui pourraient éventuellement réduire l'efficacité énergétique des modules solaires .Cellules solairesEL La détection des anomalies de surface dans les images est liée à la surveillance de la santé structurelle. .Et pourtant,Il est important de noter que, Certains défauts des cellules solaires ne sont spécifiques qu'aux modules photovoltaïques ELImagerie.Par exemple, Les cellules solaires complètement déconnectées ne sont affichées que dans la zone d'image sombre (Similaire à la figure1(d)), Il n'existe donc pas d'équivalent comparable pour les défauts structurels .En outre, Irrégularités de surface dans les puces solaires ( Comme une interruption du doigt ) Facile à confondre avec les fissures de la batterie , Même s'ils n'affectent pas significativement la perte de puissance .
Dans le cadre de l'inspection visuelle des modules solaires ,TsaiEt al.(2012) Détection de modules photovoltaïques polycristallins à l'aide de la reconstruction d'images de Fourier EL Défauts dans l'image des cellules solaires . Le défaut externe de la cible est (Petit)Fissure、 .Fracture et doigts brisés . .La reconstruction d'image de Fourier élimine les défauts possibles en réglant les coefficients de haute fréquence associés aux artefacts de ligne et de barre à zéro . La représentation spectrale est ensuite convertie en domaine spatial . Le défaut peut alors être identifié comme une différence d'intensité entre l'image originale et l'image filtrée à haut débit . En raison de l'hypothèse de forme , Cette méthode est difficile à détecter pour les défauts de forme plus complexe .
TsaiEt al.(2013) Une méthode d'apprentissage supervisé est également introduite , Utilisé pour l'analyse indépendante des composants (ICA) Défaut de reconnaissance de l'image de base . Analyse indépendante des composantes (ICA), Recherche d'un ensemble d'images de base indépendantes à l'aide de sous - images de cellules solaires sans défaut .La méthode est utilisée dans300 Réalisé sur un ensemble relativement petit de données de formation de sous - images de cellules solaires 93.40% Haute précision de .Et pourtant, Les défauts matériels tels que les doigts brisés doivent être traités de la même manière que les fissures de la batterie. .Donc,, La stratégie ne s'applique qu'à la détection de chaque anomalie de la surface des cellules solaires , Ne s'applique pas à la prévision des pertes d'énergie futures .
AnwarEtAbdullah(2014) Un algorithme de détection des micro - fissures pour les cellules solaires polycristallines a été mis au point. . Ils utilisent un filtre de diffusion anisotrope , Et l'analyse de forme , Pour localiser les défauts dans les cellules solaires . Bien que cette méthode fonctionne bien pour détecter les microfissures , Mais il ne tient pas compte des autres types de défauts ,Par exemple, dansEL Les cellules complètement déconnectées qui apparaissent dans l'image comme complètement sombres .
TsengEt al.(2015) Une méthode de détection automatique de l'interruption des doigts dans les cellules solaires monocristallines est proposée. . La méthode utilise le regroupement binaire des caractéristiques de la région candidate pour détecter les défauts .Et pourtant, Les interruptions de doigts ne fournissent pas nécessairement des indices appropriés pour prédire les pertes de puissance futures. .
Le succès de l'apprentissage en profondeur a conduit à la substitution progressive des pipelines traditionnels de reconnaissance de motifs pour la détection optique. .Et pourtant,Pour autant qu'on sache, Pas encore proposé pour ELImageCNNArchitecture, Mais uniquement pour d'autres modes ou applications . Le plus étroitement lié est MehtaEt al.(2018Année)Travail, Ils ont proposé une sorte de RGB Les images prédisent la perte de puissance 、 Système de positionnement et de type saleté . Leur méthode ne nécessite pas de positionnement Manuel des étiquettes , C'est une opération sur l'image , Et utiliser la perte de puissance correspondante comme entrée .MasciEt al.(2012)On propose une approche de bout en boutmaxpooling CNN, Utilisé pour classer les défauts d'acier . Comparer la performance de son réseau avec plusieurs descripteurs de caractéristiques fabriqués à la main formés à l'aide de machines vectorielles de soutien . Bien que leurs ensembles de données ne contiennent que 2281Images d'entraînement et646Images de test,Mais...CNN L'architecture classifie les défauts d'acier avec au moins deux fois plus de précision que la machine vectorielle de soutien .Zhang et al.(2016) Une méthode de détection des fissures routières CNNArchitecture.Pour la formationCNN,Utilisé environ45000 Blocs d'image marqués manuellement .Ils ont montré,CNN Est beaucoup plus efficace que les caractéristiques faites à la main, puis à travers les machines vectorielles de soutien et boosting La combinaison de .. ChaEt al.(2017Année) Dans une large gamme d'images prises dans divers environnements et conditions d'éclairage , Utiliser des méthodes très similaires pour détecter les fissures de béton .KangEtCha(2018) Surveillance de la santé structurelle des images aériennes par apprentissage en profondeur .ChaEt al.(2018Année) Nous avons également étudié la méthode basée sur la rapidité R-CNN Localisation des défauts de la méthode de segmentation basée sur l'apprentissage moderne , Le cadre peut être exécuté en temps réel .LeeEt al.(2019) La segmentation sémantique est également utilisée pour détecter les fissures dans le béton. .
En médecine ,EstevaEt al.(2017) Classification des différents types de cancer de la peau à l'aide d'un réseau neuronal profond . Ils sont dans une situation où 129450 Image clinique et 2032 Un grand ensemble de données sur différentes maladies CNN Formation de bout en bout , Permet une grande précision .
3.Méthodes
Nous subdivisons chaque module en ses cellules solaires , Et analyser chaque batterie individuellement , Probabilité d'extrapolation finale des défauts . Cela décompose l'analyse en unités minimales significatives , .C'est - à - dire que les modules photovoltaïques sont conçus mécaniquement pour relier les cellules en série .En outre, La décomposition augmente considérablement le nombre d'échantillons de données disponibles pour la formation. . Pour la Division des cellules solaires , Nous avons utilisé des méthodes récemment mises au point (DeitschEt al.,2018), Cette méthode met chaque batterie dans un état normal , Pas de perspective et de distorsion de la lentille .
Sauf indication contraire, Dans le cas contraire, la méthode proposée s'applique à une résolution de ×300 La masse des cellules solaires pixels ELImages. Cette résolution d'image provient de l'original du module photovoltaïque EL Taille médiane de la zone d'image correspondant à une seule cellule solaire dans l'image . L'image de la cellule solaire est utilisée directement comme entrée de tuyau . La résolution d'image des cellules solaires sur le terrain s'écarte généralement de la résolution souhaitée , Des ajustements doivent donc être effectués en conséquence. .CNN Le schéma définit la résolution minimale de l'image , Cette résolution est généralement égale à CNN Le champ de réception de (Par exemple,OriginalVGG-19Utilisation du schéma×224 224). Si la résolution est inférieure à cette résolution minimale , L'image doit être agrandie . Pour une résolution plus élevée , Peut appliquer le réseau à travers les fenêtres , Puis Assemblez la sortie ( Les agrégats moyens ou maximaux sont généralement utilisés ). Nous avons adopté une autre approche ,Dans cette approche,,CNN L'architecture encode intrinsèquement ce processus . Pour les tuyaux de machines vectorielles de soutien , Les exigences en matière de résolution sont moins strictes . Étant donné que les caractéristiques locales sont invariantes à l'échelle , Classification la résolution d'image des cellules solaires n'a pas besoin d'être ajustée , Et peut varier d'une image à l'autre .
3.1. Classification à l'aide de machines vectorielles de soutien
Méthode générale de classification à l'aide de machines vectorielles de soutien (CortesEtVapnik,1995)Comme suit.Tout d'abord,, Extraction de descripteurs locaux à partir d'images de cellules photovoltaïques segmentées . Les caractéristiques sont généralement en évidence ( Aussi appelé clé ) Ou extrait dans une grille de pixels dense . Pour les classificateurs de formation et les prévisions subséquentes , La représentation globale doit être calculée à partir d'un ensemble de descripteurs locaux , Communément appelé codage .Enfin, Diviser les descripteurs globaux des cellules solaires en descripteurs de défaut et de fonction .Fig.3 Les tuyaux de tri sont affichés , Y compris le masquage 、Détection des points critiques、Description des caractéristiques、 Codage et classification . Nous décrivons ces étapes dans les sections suivantes. .

3.1.1. Masquage
Nous supposons que les cellules solaires sont séparées des modules photovoltaïques ,Par exemple, En utilisant l'algorithme automatique que nous avons proposé dans nos premiers travaux (DeitschEt al.,2018).Et puis, Le masque binaire permet de séparer l'avant - plan et l'arrière - plan de chaque cellule . L'arrière - plan de l'unit é comprend une zone d'image qui n'appartient généralement pas à la plaquette de silicium , Par exemple, les limites entre les barres d'autobus et les cellules . Ce masque peut être utilisé pour limiter strictement l'extraction des caractéristiques à l'intérieur de l'unit é .Dans l'évaluation, Nous avons étudié l'utilité du masquage , Et a trouvé que l'impact était très faible , C'est - à - dire dans quelques caractéristiques / Seule une légère amélioration des performances dans la combinaison classificateur .
3.1.2. Extraction des caractéristiques
Pour former des machines vectorielles de soutien , Extraire d'abord le descripteur de caractéristique . L'emplacement de ces caractéristiques locales a été déterminé à l'aide de deux stratégies d'échantillonnage principales. :(1) Détection des points critiques et (2)Échantillonnage intensif. Ces stratégies sont illustrées à la figure 4Comme indiqué. Les deux stratégies produisent des ensembles de fonctions différents , Mieux adapté à certains types de puces solaires que d'autres stratégies . Échantillonnage intensif ignorer le contenu de l'image , Au lieu de cela, utilisez une configuration de point de fonction fixe .D'un autre côté, Le détecteur de clés dépend de la texture dans l'image , Le nombre de points clés est donc proportionnel au nombre d'éléments à haute fréquence , Comme les bords et les coins (Comme le montre la figure4(c)Et(d)Comme indiqué). Les détecteurs de clés fonctionnent généralement dans l'espace d'échelle , Permet la détection de caractéristiques à différents niveaux d'échelle et dans différentes directions .Fig.4(d)Montre.KAZE Points clés détectés .Ici, Chaque clé a une échelle différente ( Affiché par le rayon du cercle correspondant ), Il y a aussi des directions spécifiques , Par exemple, une ligne tracée du Centre à la limite du cercle . Les touches de l'échelle de capture et de la rotation ne changent pas la résolution de l'image et la rotation dans le plan , Cela les rend très robustes .

L'échantillonnage intensif est effectué en le comparant à ×n Une grille de piles superposée pour la subdivision ×300 Cellules photovoltaïques pixels . Le Centre de chaque cellule de grille indique l'emplacement du descripteur de fonction extrait par la suite. . Le nombre de positions des caractéristiques dépend uniquement de la taille de la grille . Si les ressources informatiques sont très limitées , Ou l'objectif est d'identifier uniquement les défauts dans les modules photovoltaïques à cristaux simples , L'échantillonnage intensif est utile .
Nous avons utilisé différentes combinaisons populaires de détecteurs de points clés et d'extracteurs de caractéristiques dans la littérature. ,Comme indiqué dans le tableau1Liste, Et il est résumé ci - dessous .

Plusieurs algorithmes combinent la détection des points clés et la caractérisation . .Le plus populaire de ces méthodes est peut - être la transformation des caractéristiques à l'échelle invariante (SIFT)(Lowe,1999), Il détecte et décrit les caractéristiques à plusieurs échelles .SIFTPour la rotation、Invariance de traduction et d'échelle, Et partiellement élastique aux différentes conditions d'éclairage .Caractéristiques robustes accélérées(SURF)(BayEt al.,2008)- Oui.SIFT Une variante plus rapide de , Comprend également un détecteur de points clés et un descripteur de caractéristiques locales .Et pourtant,SURF La partie détecteur de la transformation d'affine n'est pas invariante . Dans l'expérience initiale , Nous n'avons pas pu utiliser avec succès SIFTEtSURF Détecteur de points clés pour , Parce que les détecteurs de clés ne peuvent parfois pas détecter les caractéristiques dans des images de cellules monocristallines relativement uniformes , Donc nous n'utilisons que la partie descripteur .
KAZE(AlcantarillaEt al.,2012) Est un détecteur de caractéristiques à plusieurs échelles et un descripteur . Algorithme de détection des points clés avec SIFTTrès similaire,C'est juste...SIFT L'espace gaussien linéaire utilisé est remplacé par un filtre de diffusion non linéaire .Et pourtant, Pour la description des caractéristiques ,KAZEUtiliserSURFDescripteur.
Nous avons également étudié les essais adaptatifs et les essais généraux de segments d'accélération. (AGAST)(MairEt al.,2010) En tant que détecteur de clés dédié sans descripteur . Il est basé sur un classificateur forestier stochastique formé sur un ensemble de caractéristiques de coin , Ces caractéristiques sont connues sous le nom d'essais accélérés de segmentation (FAST)Caractéristiques(RostenEtDrummond,20052006).
Dans le descripteur privé , Histogramme pyramidal du texte visuel (PHOW)(BoschEt al.,2007)- Oui.SIFTExtension de, Il calcule intensivement sur une grille uniformément répartie SIFTDescripteur.Nous utilisonsVLFEAT Variante de mise en œuvre de (VedaldiEtFulkerson,2008).De même,,Histogramme du gradient directionnel(HOG)(DalalEtTriggs,2005) Est un descripteur de caractéristiques basé sur un gradient calculé intensivement sur un ensemble uniforme de blocs d'image .Enfin, Nous avons également utilisé des groupes de géométrie visuelle (VGG)Descripteur, Utiliser des méthodes d'optimisation efficaces pour la formation de bout en bout (SimonyanEt al.,2014).Dans notre mise en œuvre,Nous avons utilisé120 Dimension valeur réelle descripteur variable .
Nous avons omis le descripteur binaire de cette sélection . Bien que les descripteurs de caractéristiques binaires soient généralement très rapides à calculer , Mais ils ne sont généralement pas meilleurs que les descripteurs réels (HeinlyEt al.,2012).
3.1.3 Combinaison de détecteurs et d'extracteurs
Pour identifier le détecteur de caractéristiques le plus puissant \ Combinaison extracteur , Nous avons évalué toutes les combinaisons de détecteurs et d'extracteurs de caractéristiques ,À quelques exceptions près.
Dans la plupart des cas, Nous n'avons pas ajusté les paramètres du détecteur de clés , Ni ajuster les paramètres de l'extracteur de fonctionnalités ,Mais utiliserOPENCV(ITSEZ,2017)Depuis3.3.1 Par défaut depuis la version . Une exception notable est AGAST, Nous abaissons le seuil de détection à 5, Afin de détecter les points clés dans les modules photovoltaïques à cristaux simples .PourSIFTEtSURF, Un ajustement similaire n'a pas été couronné de succès , C'est pourquoi nous n'utilisons que leurs descripteurs .HOG Mailles nécessitant un chevauchement des zones d'image , Ceci n'est pas compatible avec le détecteur de clés .Au contraire.,On va300×300 Les images cellulaires des pixels sont échantillonnées à 256 X 256Pixels(Le plus proche2Puissance)Effectuer l'extraction des caractéristiques. En raison de contraintes spécifiques à la mise en œuvre ,OmisHOGBlindage. Compte tenu de ces exceptions , Nous avons évalué globalement 12 Combinaison de caractéristiques des espèces .
3.1.4 Codage
Les caractéristiques calculées sont codées dans un descripteur de caractéristiques global . Le but du codage est de former un seul descripteur global de longueur fixe à partir de plusieurs descripteurs locaux. . Le codage est généralement représenté par un histogramme qui extrait des statistiques du modèle de fond. .À cette fin,, Nous avons utilisé le vecteur descripteur d'agrégation locale (VLAD)(JégouEt al.,2012), Ceci fournit une représentation compacte et à la fine pointe de la technologie (PengEt al.,2015).VLAD Le codage est parfois utilisé pour la classification 、 Identifier et récupérer les caractéristiques basées sur l'apprentissage profond dans les tâches (GongEt al.,2014;NgEt al.,2015;PaulinEt al.,2016;ChristleinEt al.,2017).
VLAD Le dictionnaire est basé sur un sous - ensemble de descripteurs de caractéristiques aléatoires dans l'ensemble de formation k Créé par le regroupement des moyennes .Pour des raisons de performance,Nous utilisonsk-means Une variante rapide en petits lots de (Sculley,2010). Centroïde de Cluster µk Points d'ancrage correspondant au dictionnaire .Et puis, Agrégation des statistiques de premier ordre en tous les descripteurs extraits de l'image de la cellule solaire

La somme des résidus de . Les résidus sont basés sur l'ancre la plus proche dans le dictionnaire µkCalculéPour

Parmi eux:

Est une fonction indicateur de l'adhésion au cluster ,C'est - à - dire::

Ça veut direxOui NonµkVoisin le plus proche de.FinalVLADReprésentation

Correspond à l'ajout de tous les éléments restants (1)Série àKdDans le vecteur de dimension:

Pour faireVLAD Les descripteurs sont robustes , Plusieurs étapes de normalisation sont nécessaires . La normalisation de la puissance résout le problème que certains descripteurs locaux sont plus fréquents que d'autres .Ici.,Descripteur global

Chaque élément de :

Parmi eux, Nous avons choisi parmi la littérature

Comme valeur typique . Après normalisation de la puissance , Les vecteurs sont normalisés ,Faire- La norme est égale à 1.
De même,, Si au moins deux descripteurs apparaissent souvent ensemble , Il peut y avoir trop de co - occurrence .JégouEtOndřej(2012)Ça veut dire,Analyse des composantes principales(PCA) Le blanchiment élimine efficacement cette co - occurrence , Et élimine davantage la pertinence des données .
Pour améliorer le Codebook DLa probabiliték Robustesse des solutions sous - optimales potentielles pour les grappes moyennes , Nous avons calculé cinq sous - ensembles d'entraînement différents en utilisant différentes graines aléatoires VLADReprésentation.Et puis,AdoptionPCA(KessyEt al.,2016),C'est exact.VLAD Série codée
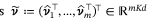
Effectuer la déscorrélation conjointe et le blanchiment . La représentation transformée est de nouveau normalisée ,Faire- La norme est égale à 1, Les résultats sont finalement transmis au classificateur SVM .
3.1.5. Support Vector Machine Training
Nous utilisons des noyaux de fonctions de base linéaires et radiales pour former des machines vectorielles de soutien .Pour les noyaux linéaires,Nous utilisonsLIBLINEAR(FanEt al.,2008), Il est optimisé pour les tâches de classification linéaire et les grands ensembles de données .Pour la non - linéaritéRBFNucléaire,Nous utilisonsLIBSVM(ChangEtLin,2011).
L'hyperparamètre support vector machine est évalué à l'aide d'une recherche en grille dans une validation croisée interne de cinq fois de l'ensemble de formation F1Points(van Rijsbergen,1979)Pour être sûr.Pour les machines vectorielles de soutien linéaires, Nous utilisons 2Sanctions.Paramètres de pénalitéC C'est un groupe de 10 De la puissance de ,C'est - à - dire:

.PourRBFSupport Vector Machine,Paramètres de pénalitéC Déterminé par un ensemble légèrement plus petit .Coefficient nucléaire L'espace de recherche pour est limité à ,Parmi euxS Indique le nombre d'échantillons d'entraînement .
3.2 Régression utilisant un réseau neuronal de convolution profonde
Nous avons envisagé plusieurs formations CNNStratégie. Compte tenu de la quantité limitée de données dont nous disposons , Obtenir les meilleurs résultats grâce à l'apprentissage de la migration .Nous avons utiliséVGG-19Architecture du réseau(SimonyanEtZisserman,2015),Utilisation initiale128Dix mille images et1000 Les classes sont IMAGENETEnsemble de données(DengEt al.,2009)Formation.Et puis, Nous avons utilisé nos ensembles de données pour optimiser le réseau .
Nous utilisons le pool moyen global (GAP)RemplacerVGG-19 Deux couches entièrement connectées (LinEt al.,2013),Et utiliser séparément4096Et2048 Les neurones remplacent deux couches complètement connectées (Voir fig.5). La couche de dégagement est utilisée pour VGG-19 Tenseur d'entrée réseau (×224 224 3) Résolution avec nos échantillons d'images de cellules solaires (×300 3)Compatible avec, Pour éviter un prélèvement supplémentaire de l'échantillon . La couche de sortie est composée d'un seul neurone , Probabilité de défaut de la cellule de sortie . En minimisant l'erreur carrée moyenne (MSE)Paire de fonctions de perteCNNOptimiser.Donc,, Nous avons essentiellement formé des réseaux de régression en profondeur , Le réseau nous permet d'utiliser seulement deux catégories de probabilité de défaut ( Fonctionnalité et défectuosité )Pour prévoir(Continu) Probabilité de défaut . En arrondissant la probabilité continue prévue au voisin le plus proche des quatre classes originales ,Nous pouvons directementCNN La décision est comparée à l'étiquette originale de vérité au sol , Sans binarisation .

Amélioration des données pour générer des données supplémentaires 、 Échantillons d'entraînement légèrement perturbés .Et pourtant, Amélioration de la variabilité modérée , Parce que les cellules segmentées ne changent que de quelques pixels le long de l'axe de traduction , Seulement quelques degrés le long de l'axe de rotation . Échantillons d'entraînement jusqu'à la résolution originale 2%Zoom. La plage de rotation est limitée à ±°3. La traduction est limitée à la taille de la cellule ±2%. Nous utilisons également des retournements aléatoires le long des axes verticaux et horizontaux . Parce que les barres d'autobus peuvent être disposées verticalement et horizontalement , Nous incluons également une rotation précise 90°Échantillons d'entraînement pour. L'échantillon rotatif est augmenté de la même manière que ci - dessus .
Nous avons peaufiné les données IMAGENETModèle,Pour faireCNN S'adapter aux nouvelles tâches ,Similaire àGirshickEt al.(2014).Et pourtant, Nous le faisons en deux étapes .Tout d'abord,, .Nous ne formons que des couches entièrement connectées avec des poids d'initialisation aléatoires , Tout en maintenant le poids du bloc de convolution fixe .Ici,Nous utilisonsADAMOptimizer(KingmaEtBa,2014),Taux d'apprentissage10^-3, Taux d'atténuation exponentiel =0.91Et=0.9992, Valeur de régularisation =10^-8.Dans la deuxième étape, Nous affinons le poids de toutes les couches .À ce stade,Nous utilisons un gradient aléatoire pour descendre(SGD)Optimizer,Taux d'apprentissage5·104,L'impulsion est0.9.Nous avons observé, Comparé à une seule étape de raffinement , Peaufiner en plusieurs étapes en augmentant ensuite le nombre de superparamètres CNN Améliore légèrement la capacité de généralisation du modèle de résultat .
Dans ces deux phases ,On est dans deuxNVIDIA GeForce GTX 1080Vers le Haut16 Traitement en petits lots d'échantillons 1968 Version améliorée des échantillons de formation , Et courir jusqu'à 100- Oui.epochLe processus d'entraînement. Ça fait 196800Original1968 Variante améliorée de l'échantillon d'entraînement ,Pour optimiser le réseau. Pour réaliser un réseau de régression en profondeur , Nous utilisons KERASVersion2.0(CholletEt al.,2015)EtTENSORFLOWVersion1.4(AbadiEt al.,2015).
4.Évaluation
Pour l'évaluation quantitative, Nous commençons par évaluer les différents descripteurs de caractéristiques extraits intensivement sur la grille .Et puis, Nous comparons la configuration optimale avec les descripteurs de caractéristiques extraits aux points clés détectés automatiquement , Pour déterminer les changements de performance optimaux des pipelines classifiés par SVM .Enfin, Nous comparons ce dernier à la profondeur proposée CNNComparer,Et visualiserCNN Cartographie des caractéristiques internes de .
4.1 Ensemble de données
Nous proposons une résolution élevée à partir de modules photovoltaïques monocristallins et polycristallins EL Ensemble commun de données sur les cellules solaires extraites de l'image 1(Buerhop-LutzEt al.,2018).L'ensemble de données est défini par2624 Composition des images des cellules solaires ,Résolution:×300Pixels,A l'origine44 Extrait de différents modules photovoltaïques ,Parmi eux18 Les composants sont du type monocristal ,26 Sont de type polycristallin .
Les images des modules photovoltaïques utilisés pour extraire des échantillons individuels de cellules solaires ont été prises dans un environnement de fabrication . Cette condition contrôlée peut contrôler la qualité du panneau d'imagerie dans une certaine mesure , Et permet de minimiser l'impact négatif sur la qualité de l'image , Par exemple, surexposition . Parce que le rayonnement de fond peut dominer ELRayonnement, Des conditions de contrôle sont donc nécessaires . Considérant que les modules photovoltaïques n'émettent que de la lumière lorsqu'ils sont recueillis dans une chambre noire , Cela assure un éclairage uniforme de l'image . Ceci est contraire à l'acquisition d'images dans la surveillance structurelle générale de la santé. , Ce dernier introduit un degré de liberté supplémentaire , Les images peuvent être affectées par des ombres ou des projecteurs (ChaEt al.,2017Année).Et pourtant, Un problème important dans l'imagerie par électroluminescence est , Parce que la lentille est mal focalisée , Image électroluminescente floue ( C'est - à - dire hors de mise au point ), Parfois difficile à réaliser .Donc,, Nous nous assurons que ces images sont incluses dans l'ensemble de données proposé (Par exemple,Voir fig.1).A
Les cellules solaires présentent des défauts intrinsèques et extrinsèques communs aux modules solaires monocristallins et polycristallins .En particulier, L'ensemble de données comprend les micro - fissures et les batteries avec des pièces détachées et détériorées électriquement. 、Batterie de court - circuit、 Défauts d'interconnexion et de soudage en circuit ouvert .Tout le monde sait, Ces défauts de batterie peuvent affecter l'efficacité des modules solaires 、 Impact négatif sur la fiabilité et la durabilité . La perte de puissance due à ces défauts est généralement négligeable , Par conséquent, l'interruption du doigt n'est pas incluse .
Mesure de l'atténuation de la puissance non disponible ground-truth.Au contraire., Les cellules extraites sont présentées à la familiarité dans un ordre aléatoire EL Expert reconnu dans les détails complexes des différents défauts d'une image .KöntgesEt al.(2014) Les critères de ces défaillances sont résumés. . Dans la classification des défauts , Les experts sont particulièrement préoccupés par les pertes de puissance connues qui dépassent la puissance initiale 3%Défauts. L'expert répond à la question (2) Si la fonction cellulaire est normale ou défectueuse ?(2) Avez - vous confiance dans votre évaluation ? L'évaluation des cellules fonctionnelles et défectueuses par des évaluateurs confiants est utilisée directement comme étiquette. . L'évaluation non confiante des cellules fonctionnelles et défectueuses a été marquée comme défectueuse . Pour refléter l'incertitude du notateur , Attribuer une pondération plus faible à ces évaluations , C'est - à - dire que le poids de l'évaluation non fiable des cellules fonctionnelles est 33%, Le poids de l'évaluation non confiante des cellules défectueuses est 67%.Tableau2En résumé, À gauche se trouve l'évaluation de l'évaluateur , À droite se trouvent les étiquettes de classification et les poids pertinents. .Tableau3Montre.ground-truth Distribution des étiquettes des cellules solaires , Séparé par type de module photovoltaïque source .


Nous utilisons25% Des cellules marquées (656Cellules)Effectuer des tests,Le reste75%(1968Cellules)Formation. Échantillonnage stratifié pour la segmentation aléatoire des échantillons , Conserver la distribution de l'échantillon dans différentes catégories de l'ensemble d'entraînement et de l'ensemble d'essai . Pour équilibrer davantage l'ensemble d'entraînement ,Nous utilisonsKingEtZeng(2001) Classe de poids heuristique inverse de :

Parmi euxS Est le nombre total d'échantillons de formation ,njEst une fonction(=j 0) Ou défectueux (=j 1)Nombre d'échantillons.
4.2 Échantillonnage intensif
Dans cette expérience,, Nous avons évalué les données utilisées pour subdiviser les individus ×300 Différentes tailles de mailles pour les images de cellules pixels . Le nombre de points de grille par cellule est de 5×5À75 ×75 Changement entre les points . À chaque point de grille ,CalculSIFT、SURFEtVGGDescripteur. Les deux autres descripteurs PHOWEtHOG Omis dans cette expérience , Parce qu'ils ne permettent pas de spécifier arbitrairement l'emplacement du calcul du descripteur .Attention!,In75×75 Sur la grille des points , La distance entre les deux points de grille n'est que 4Pixels, Il en résulte un chevauchement important entre les descripteurs adjacents. .Donc,, L'amélioration de la résolution du maillage n'améliore pas sensiblement les résultats de la classification .
Le but de cette expérience est de trouver la meilleure combinaison de la taille de la grille et du classificateur . Nous avons formé des machines vectorielles de soutien linéaires et radiales . Pour chaque classificateur , Nous avons également examiné deux options supplémentaires , C'est - à - dire ajouter le poids de l'échantillon w(Voir tableau2) Ou masquer la zone de fond (Voir par.3.1.1Section) Si le classificateur peut être amélioré .
UtiliserF1 Les scores mesurent le rendement ,F1 Les scores sont des moyennes harmoniques de précision et de rappel .Fig.6 Affiche chaque catégorie F1 Moyenne des scores F1Points.De gauche à droite, Ces scores sont SURFDescripteur(Fig.6(a))、SIFTDescripteur(Fig.6(b))EtVGGDescripteur(Fig.6(c)).Ici.,VGGDescripteurs utilisant Pondéré et masqué Machine vectorielle de support linéaire de taille ×65 65 Obtenir le score le plus élevé sur la grille pour .SIFT Est le deuxième descripteur le plus performant , En utilisant une machine vectorielle de support linéaire pondérée ×60 60 Meilleure performance sur la grille , Mais sans masque .SURFLe score le plus bas,Utiliser pondéréRBF Support Vector Machine in ×70-70 Pic à la grille , Mais sans masque .Les résultats montrent que, Plus il y a de points de grille ,Mieux c'est..SURF Croissance lente de la précision de classification , Le taux de saturation est d'environ 70%.SIFTEtVGG Bénéficier davantage d'un maillage plus dense .Dans la plupart des cas,Poidsw L'utilisation de , Parce que les classificateurs peuvent s'appuyer davantage sur un échantillon plus confiant d'étiqueteurs experts . Le masquage s'est également amélioré VGGCaractéristiquesF1Points.Et pourtant, Par rapport aux changements globaux de performance de la configuration ,Presque2%Très peu d'amélioration.Pour ainsi dire, Compte tenu de la haute densité des points caractéristiques et du degré de chevauchement entre les zones d'image évaluées par l'extracteur de caractéristiques , La structure cellulaire n'est pas importante pour distinguer les différents types de défauts cellulaires .

4.3. Échantillonnage intensif et détection des points critiques
Le but de cette expérience est de comparer les performances de classification des caractéristiques basées sur des grilles denses et des caractéristiques basées sur des points clés. .À cette fin,, Comparer la meilleure performance de chaque descripteur dans les expériences précédentes avec un classificateur basé sur la grille et une combinaison de détecteurs de clés et de descripteurs de caractéristiques .
Fig.7 Affiche les cellules monocristallines évaluées 、 Piles polycristallines et leurs combinaisons de détecteurs et d'extracteurs . La plupart des détecteurs / L'extracteur est combiné par une barre oblique avant (Détecteur/Descripteur)Désignation. Aucune entrée pour Slash avant ,C'est - à - dire:KAZE、HOGEtPHOW, Caractéristiques indiquant que le détecteur et le descripteur ont été inclus . Les trois méthodes les plus performantes sur les grilles denses sont représentées respectivement comme denses SIFT×60、DenseSURF×70Et denseVGG×65.Sauf indication contraire, Sinon, utilisez la pondération de l'échantillon 、 Formation des caractéristiques par des machines vectorielles de soutien linéaires et non masquées .

UtiliserROC Les courbes montrent les performances , La courbe montre la performance du classificateur binaire à différents taux de fausse alarme (Fawcett,2006).En outre, Le graphique montre l'avant 4CaractéristiquesAUCPoints,Plus hautAUC En gras .Dans ces trois cas,,KAZE \/VGG Meilleure combinaison que les autres caractéristiques ,Tous les modulesAUCPour88.51%,Et ensuite,KAZE \/SIFT,AUCPour87.22%. À titre exceptionnel ,JusteAUCEn termes, La deuxième meilleure combinaison de caractéristiques des cellules solaires polycristallines est PHOW. Les lignes pointillées grises représentent la base du classificateur aléatoire .En général, Meilleure performance avec des points clés que l'échantillonnage intensif .
4.4. Support Vector Machine and migration Learning Using Depth Regression Network
Fig.8AvecCNNClassificateur comparé à, Affiche la variante la plus forte de la machine vectorielle de soutien KAZE \/VGGPerformance.Fig.8(a)GaucheROC Courbe contenant les résultats des modules photovoltaïques à cristaux simples .Fig.8(b) Fournit la performance de classification des modules photovoltaïques polycristallins .Enfin, La performance globale de la classification des deux modèles est illustrée à droite 8(c)Comme indiqué.

Ce qui est remarquable, c'est que, Les performances de classification des modules photovoltaïques monocristallins par SVM et Ann sont très similaires .CNN La performance moyenne de SVM. Lorsque le taux de faux positifs est inférieur à 1%À gauche et à droite,CNN Obtenir un taux plus élevé de vrais positifs .Et pourtant,À environ1%À10% Dans la plage de faux positifs pour , Support vector machine fonctionne mieux .Ça veut direKAZE \/VGG La capacité de capturer des anomalies sur une surface uniforme est presque identique à l'entraînement direct sur les pixels d'image CNNExactement..
Pour les modules photovoltaïques polycristallins ,InAUCAspects,CNNPeut comparerSVM Prévoir plus précisément les défauts des cellules solaires presque 11%. En raison de la grande variété de textures dans les cellules solaires , C'est aussi un test beaucoup plus difficile. .
En général,CNNMieux queSVM.Et pourtant, La différence globale de performance entre les deux classificateurs n'est que de 6%Gauche et droite.Donc,, Le classificateur de machines vectorielles de soutien peut également être utilisé lorsque vous ne pouvez pas utiliser CNN Rapide avec du matériel dédié 、 Évaluation sur le terrain des modules photovoltaïques .
4.5. Performance du modèle pour chaque catégorie de défauts
Ici, Nous présentons un rapport détaillé sur le modèle proposé pour une seule catégorie de cellules solaires selon la matrice de confusion ( C'est - à - dire les défauts et les fonctions )Performance en termes de. La matrice de confusion bidimensionnelle stocke les proportions de cellules correctement identifiées ( Vrai faux et vrai positif ) Dans chaque catégorie sur sa Diagonale principale . Les diagonales secondaires fournissent des cellules solaires mal identifiées par rapport à d'autres catégories ( Faux négatif et faux positif )Proportion de.
Fig.9 Matrice de confusion montrant le modèle proposé . La matrice de confusion est donnée pour chaque type de puce solaire et sa combinaison . L'axe vertical de la matrice de confusion spécifie l'attente ( C'est - à - dire que le sol est réel )Étiquettes, L'axe horizontal indique l'étiquette prévue par le modèle correspondant .Ici,CNN Le seuil de prévision pour 50%, Pour produire deux types de fonctions (0%)Et défauts(100%)Cellules solaires.
À propos des modules photovoltaïques monocristallins ,Fig.9(a)Et(d) La matrice de confusion dans souligne que les deux modèles fournissent des résultats de classification comparables .Et pourtant,AvecCNNComparé à, La machine vectorielle de soutien linéaire peut identifier correctement plus de cellules défectueuses , Mais le prix est que les cellules fonctionnelles sont reconnues comme défectueuses (Faux négatif).À cette fin,, La machine vectorielle de support linéaire identifie les cellules solaires défectueuses comme étant intactes (Faux positifs) Des erreurs mineures peuvent également se produire .
Dans la figure9(b)Et(e) Dans le cas du polycristal donné ,CNN Dans chaque classe, il est évidemment supérieur à la machine vectorielle de soutien linéaire .Cela conduit également àCNN Meilleure performance globale dans les deux cas ,Comme le montre la figure9(c)Et(f)Comme indiqué.

Fig.9Notes: Matrice de confusion du modèle de classification proposé . .La matrice de confusion par rangée stocke la fréquence relative des instances dans la catégorie de probabilité de défaut attendue .D'un autre côté, Ces colonnes contiennent la fréquence relative des instances de prévision faites par le modèle de classification. .Idéalement, Seule la diagonale de la matrice de confusion contiendra un terme non nul , Cela correspond à une parfaite concordance entre les valeurs de vérité de base et les modèles de classification dans toutes les catégories .CNN En général, c'est plus important que KAZE/VGG Les machines vectorielles de soutien pour la formation aux caractéristiques produisent moins d'erreurs de prédiction .
4.6. Effet de la taille de l'ensemble de données de formation sur le rendement du modèle
Pour former les machines vectorielles de soutien linéaires et CNN, Un ensemble relativement petit et unique de données d'images de cellules solaires a été utilisé . Compte tenu de la production quotidienne typique de modules photovoltaïques 1500Composants,Contient environ90000Cellules solaires, On s'attend à ce que le modèle profite grandement des données supplémentaires sur la formation. . Pour vérifier si d'autres échantillons d'entraînement sont utilisés , Comment améliorer le modèle proposé , Nous avons évalué leur performance sur un sous - ensemble d'échantillons d'entraînement originaux. , Parce qu'aucun autre échantillon de formation n'est disponible .
Pour extrapoler les tendances du rendement , Nous avons évalué le modèle sur trois sous - ensembles de tailles différentes de l'échantillon d'entraînement original. .Nous avons utilisé25%、50%Et75% Échantillon d'entraînement original de . Afin d'éviter tout biais dans les indicateurs obtenus , Nous échantillonnons non seulement les sous - ensembles au hasard , Et pour chaque sous - ensemble, 50Sous - échantillonnage, Pour obtenir des échantillons pour le modèle de formation .En outre, Nous avons également utilisé un échantillonnage stratifié pour conserver la distribution des étiquettes dans l'ensemble d'échantillons d'entraînement original. .Pour évaluer le rendement, Nous utilisons l'échantillon d'essai original , Et fournit les résultats de trois indicateurs :F1Points、ROC AUCEt la précision.
Fig.10 Affiche la distribution des scores d'évaluation sur tous les échantillons de trois sous - ensembles d'échantillons de formation de tailles différentes utilisés pour former le modèle proposé . Tous les trois sous - ensembles 50 La répartition des points est résumée dans le diagramme de la boîte . Les résultats montrent clairement que le rendement du modèle proposé augmente approximativement logarithmiquement par rapport au nombre d'échantillons d'entraînement habituellement observés dans les tâches visuelles (SunEt al.,2017).

4.7. CNNAnalyse de l'espace caractéristique
Ici,Nous utilisonst-Intégration aléatoire de quartiers distribués(t-SNE)AnalyseCNNCaractéristiques de l'apprentissage(van der MaatenEtHinton,2008), C'est une technique d'apprentissage multiple pour réduire les dimensions . L'objectif est de vérifier les critères de séparation des différentes cellules solaires. .À cette fin,,Nous utilisonst-SNE Une variante de Barnes Cottage (van der Maaten,2014), Il est beaucoup plus rapide que la mise en œuvre standard . Pour calculer l'intégration ,On vatSNE Le paramètre de confusion est fixé à 35. Parce que notre ensemble de données d'essai est petit , Nous avons évité l'utilisation dans les étapes de prétraitement PCA Réduction initiale des dimensions des caractéristiques , Au lieu de cela, utilisez l'initialisation aléatoire intégrée .
Tous les656 Les résultats des images d'essai sont présentés comme suit: 11Comme indiqué. Chaque point correspond à 2048ViCNN Vecteur caractéristique de la dernière couche projetée en 2D . Les vecteurs caractéristiques de projection extraits des modules monocristallins et polycristallins sont codés respectivement en rouge et en bleu. . La probabilité de défaut est codée par saturation . La représentation bidimensionnelle préserve la structure des espaces de caractéristiques de haute dimension , Et montre que dans la plupart des cas, , Les probabilités de défaut similaires coexistent dans l'espace caractéristique .Ce qui rendCNN Classificateur capable de distinguer les cellules solaires défectueuses des cellules solaires fonctionnelles ELImages.

Une observation importante est que , Ce type est absolument défectueux (100%) Les piles forment un seul amas mince (En bas à gauche), Y compris les batteries , Indépendamment du type de module photovoltaïque source .C'est le contraire., Cellules fonctionnelles (0%) Sont divisés en différents groupes , Cela dépend du type de module photovoltaïque de la source . Aspect général de la batterie ( C'est - à - dire le nombre de joints soudés 、Texture, etc.) Dans les amas monocristallins (À droite.) Il y a aussi plusieurs branches . Ces branches comprennent des échantillons groupés par nombre de joints soudés de barres d'autobus dans l'unit é. .Ici., Grâce à l'uniformité des plaquettes de silicium ( C'est - à - dire sans texture )Surface, Groupe d'unités polysiliciques fonctionnelles à rapport de branche (Coin supérieur droit) La séparation est plus prononcée dans .
Peut - être défectueux (33%) Et peut - être défectueux (67%) Le regroupement des cellules est mixte . Le degré élevé de confusion entre ces échantillons découle de la comparaison de la taille des deux autres types d'échantillons de confiance élevée dans notre ensemble de données , La taille de la catégorie correspondante est relativement petite (Voir tableau3).En outre, Les échantillons de ces deux catégories se trouvent à la limite entre les défauts et les non - défauts qui peuvent être clairement distingués , Peut stimuler des décisions floues .
4.8. Résultats qualitatifs
Fig.12 Fournit des résultats qualitatifs pour le choix des cellules solaires monocristallines et polycristallines , Et par le projet de CNN Déduire la probabilité de défaut correspondante . Pour faciliter la comparaison avec les étiquettes de vérité au sol , En arrondissant la probabilité à la catégorie la plus proche ,Oui.CNN La probabilité de défaut est quantifiée en quatre catégories correspondant à l'étiquette originale . Cette sélection contient des cellules solaires correctement classées et mal classées , Distance carrée minimale et maximale entre la probabilité prévue et l'étiquette de vérité au sol, respectivement .
Pour mettre en évidence une zone de différenciation spécifique à la classe dans l'image des cellules solaires , Le diagramme peut être activé en utilisant la classe (CAM)(ZhouEt al.,2016;SelvarajuEt al.,2017;ChattopadhayEt al.,2018).Et pourtant, En raison de sa résolution plus grossière ,CAM Ne s'applique pas directement à la segmentation précise des zones défectueuses .CAM Il y a encore des indices , Expliquer les raisons pour lesquelles les réseaux de convolution extrapolent des probabilités de défauts spécifiques .À cette fin,,Fig.12 Les cellules solaires de VGG-19 Le dernier bloc de convolution du réseau (×18 18 512)Extrait deCAM Couverture supplémentaire ,Et utiliserChattopadhayEt al.(2018) Pour zoomer sur la résolution originale 300 X 300 Des images de cellules solaires .

C'est drôle,Même siCNN Classification incorrecte des cellules solaires défectueuses comme fonctionnelles (Voir fig.12(b)La dernière colonne de),CAM Vous pouvez encore mettre en évidence les zones d'image présentant des défauts potentiels .Donc,,CAM Le processus d'évaluation entièrement automatisé peut être complété , Et fournir un soutien à la décision dans des situations complexes lors d'examens visuels . Un problème particulier qui ressort de l'inspection des cames est , L'interruption du doigt n'est pas toujours clairement discernable du défaut réel .Et pourtant, Ceci peut être formé en incluant l'échantillon correspondant CNNPour réaliser.

Dans la figure13Moyenne,Nous avons montréCNN Prévision de modules solaires polycristallins complets . L'étiquette en direct au sol est représentée dans le coin supérieur droit de chaque cellule solaire par un cercle d'ombre rouge .Encore une fois, Les cellules solaires sont CAMÉcraser, Et pondéré par les prévisions du réseau , Pour réduire la quantité de confusion visuelle .Par inspectionCAM,Peut être observéCNN Attention aux défauts particuliers des cellules solaires , Ces défauts sont plus difficiles à identifier que les défauts plus évidents dans la même batterie , Par exemple, composants de batterie dégénérés ou isolés électriquement ( Afficher comme zone sombre ).
4.9 Évaluation de l'exécution
Ici, Nous avons évalué chaque étape du pipeline SVM et CNN Temps consacré à la formation et aux tests . L'exécution est en cours Intel i7-3770K CPU Pour évaluer systématiquement ,CPUL'horloge est3.50GHz,La mémoire est32GB.Les résultats sont présentés dans la figure14Comme indiqué.

Comme prévu., Les deux modèles ont passé la plus grande partie de leur formation . Bien que les machines vectorielles de soutien à la formation 30Environ une minute..RaffinementCNN La vitesse est presque la même 10X,Besoin5Environ une heure.Mais,UtiliserCNN Est beaucoup plus rapide que le pipeline SVM , Dans le support de la machine vectorielle 8 Pas besoin de plus de 20Secondes.Et pourtant,Il est important de noter que, Support Vector Machine pipe Inference duration is at CPUMise en œuvre,Et plus viteCNN La durée du raisonnement est limitée à GPUAccès.En outre, Seule une partie de la tuyauterie Support Vector Machine effectue le traitement en parallèle .QuandCPU Très parallèle CNNQuand on raisonne, Le temps d'essai a considérablement augmenté à 12Plus d'une minute.Donc,,InCPUFormationCNNÇa devient difficile., Nous évitons donc de mesurer les temps d'exécution correspondants .
Compte tenu de la contribution relative des différentes étapes du pipeline SVM , L'extraction des caractéristiques prend le plus de temps , Deuxièmement, le codage local des caractéristiques et le regroupement (Voir fig.15). Les exigences minimales en matière de prétraitement des caractéristiques et d'optimisation des hyperparamètres sont .

Dans les applications qui nécessitent non seulement une faible consommation de ressources, mais aussi un fonctionnement rapide ,Peut passerSIFTOuPHOWRemplacerVGG Descripteurs de caractéristiques pour réduire le temps total d'exécution du pipeline SVM . Ces deux descripteurs de caractéristiques sont maintenus avec VGG Descripteurs de performance de classification similaires , Extraire les caractéristiques de la période de raisonnement à partir de la période initiale 8 Les minutes sont réduites à 23Secondes et12Quelques secondes..
4.10. Discussion
Plusieurs conclusions peuvent être tirées des résultats de l'évaluation .Tout d'abord,, Si la répartition spatiale des clés est assez clairsemée , Le masquage peut être utile .Et pourtant,Dans la plupart des cas, Le masquage n'améliore pas la précision de la classification .Deuxièmement,, La pondération proportionnelle de l'échantillon en fonction de la confiance dans la probabilité de défaut dans l'unit é améliore en effet la capacité de généralisation du classificateur d'apprentissage .
Formation à l'utilisation de machines vectorielles de soutien linéaires KAZE/VGG Les caractéristiques sont les meilleures variantes de tuyauterie SVM ,Précision:82.44%,F1Le score est82.52%.CNN Encore plus précis. . Il distingue les cellules solaires fonctionnelles des cellules solaires défectueuses ,Précision:88.42%.CorrespondantF1Le score est88.39%.Adoptiont-SNEC'est exact.CNN La visualisation bidimensionnelle de la distribution des caractéristiques met l'accent sur l'apprentissage en réseau de la structure réelle de la tâche à accomplir .
L'une des limites de cette méthode est que chaque cellule solaire est inspectée indépendamment .En particulier, .Certains types d'anomalies de surface qui n'affectent pas l'efficacité du module peuvent se produire en mode répétitif entre les cellules . Une classification précise de ces effets à grande échelle exige que l'on tienne compte du contexte. , Cela dépend des travaux futurs .
Et la possibilité de prévoir des défauts , Mieux vaut prévoir un type particulier de défaut . Données sur la formation en dehors des quotas , Compte tenu des données supplémentaires sur la formation portant l'étiquette appropriée , Peut se produire sans changement majeur (Par exemple, En affinant la nouvelle catégorie de défauts ) En cas d'application de la méthode proposée dans le présent document .Et pourtant, Affiner le Réseau pour plusieurs catégories de défauts , Pour prédire le type de défaut plutôt que sa probabilité , Cela affecte généralement le choix de la fonction de perte , Cela affecte le nombre de neurones dans la dernière couche active . Le choix commun des fonctions de perte pour ce type de tâche est (Classification) Perte d'entropie croisée et softmaxActivation(GoodfelloEt al.,2016).
5.Résumé
Nous proposons un cadre général pour la formation des machines vectorielles de soutien et des réseaux neuronaux , Peut être utilisé pour identifier la haute résolution EL Défauts dans l'image des cellules solaires . La tuyauterie de traitement du classificateur SVM a été soigneusement conçue . Dans une série d'expériences , Le pipeline le plus performant a été identifié comme étant le KAZE/VGGCaractéristiques, L'échantillon tient compte du degré de confiance de la machine d'étiquetage. .CNN Le réseau est basé sur VGG-19 Le réseau de régression fine de , Formation à l'amélioration des images cellulaires , Le degré de confiance de l'étiquette est également pris en considération .
Sur un module solaire monocristallin , Les performances des deux classificateurs sont similaires ,PourCNN En moyenne, il n'y a qu'un petit avantage. .Et pourtant, Sur des cellules polycristallines plus hétérogènes ,CNN Le classificateur est plus SVM La précision du classificateur est d'environ 6%.Ça fait aussiCNN Meilleure précision moyenne dans toutes les cellules ,Pour88.42%,EtSVMPour82.44%. La haute précision rend les deux classificateurs adaptés à l'inspection visuelle . Si le scénario d'application le permet GPU Et plus de temps de traitement , Les calculs les plus coûteux sont préférés CNN.Sinon, Pour les applications nécessitant une faible utilisation des ressources , Support Vector Machine classifier est une alternative viable .
//Cet article n'est destiné qu'à un examen ultérieur,Il n'a pas besoin de.
边栏推荐
- R语言ggplot2可视化:使用ggpubr包的ggecdf函数可视化分组经验累积密度分布函数曲线、linetype参数指定不同分组曲线的线型
- Kirin Xin'an with heterogeneous integration cloud financial information and innovation solutions appeared at the 15th Hunan Financial Technology Exchange Conference
- Empowering smart power construction | Kirin Xin'an high availability cluster management system to ensure the continuity of users' key businesses
- R language ggplot2 visualization: use the ggstripchart function of ggpubr package to visualize the dot strip plot, set the position parameter, and configure the separation degree of different grouped
- 一锅乱炖,npm、yarn cnpm常用命令合集
- 指定opencv非标准安装的版本
- R语言fpc包的dbscan函数对数据进行密度聚类分析、查看所有样本的聚类标签、table函数计算聚类簇标签与实际标签构成的二维列联表
- Kirin Xin'an joins Ningxia commercial cipher Association
- 微信公众号OAuth2.0授权登录并显示用户信息
- R语言dplyr包select函数、group_by函数、filter函数和do函数获取dataframe中指定因子变量中指定水平中特定数值数据列的值第三大的值
猜你喜欢
Numpy——axis
Navicat连接2002 - Can‘t connect to local MySQL server through socket ‘/var/lib/mysql/mysql.sock‘解决

论文解读(ValidUtil)《Rethinking the Setting of Semi-supervised Learning on Graphs》
ASP. Net kindergarten chain management system source code
![Jerry's headphones with the same channel are not allowed to pair [article]](/img/7d/3dcd9c7df583944e1d765b67543eb1.png)
Jerry's headphones with the same channel are not allowed to pair [article]

Welcome to the markdown editor
PMP对工作有益吗?怎么选择靠谱平台让备考更省心省力!!!

Kirin Xin'an with heterogeneous integration cloud financial information and innovation solutions appeared at the 15th Hunan Financial Technology Exchange Conference
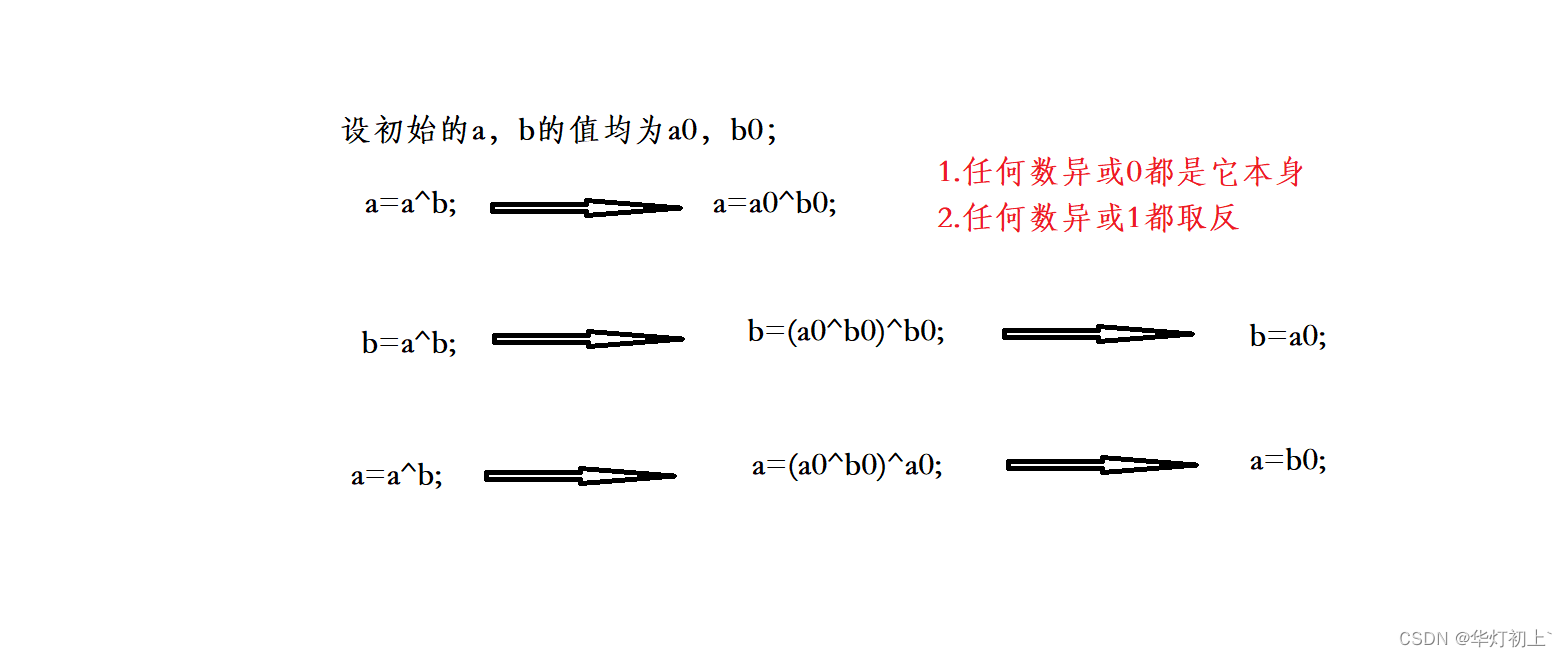
Introduction to bit operation
关于ssh登录时卡顿30s左右的问题调试处理
随机推荐
Command mode - unity
Responsibility chain model - unity
杰理之关于 TWS 声道配置【篇】
R语言使用ggplot2函数可视化需要构建泊松回归模型的计数目标变量的直方图分布并分析构建泊松回归模型的可行性
现在股票开户可以直接在网上开吗?安全吗。
模拟实现string类
浏览积分设置的目的
杰理之测试盒配置声道【篇】
R language ggplot2 visualization: use the ggviolin function of ggpubr package to visualize the violin diagram, set the palette parameter to customize the filling color of violin diagrams at different
Browse the purpose of point setting
Make this crmeb single merchant wechat mall system popular, so easy to use!
R language ggplot2 visualization: use the ggstripchart function of ggpubr package to visualize the dot strip plot, set the position parameter, and configure the separation degree of different grouped
最长公共前缀(leetcode题14)
歌单11111
Kirin Xin'an with heterogeneous integration cloud financial information and innovation solutions appeared at the 15th Hunan Financial Technology Exchange Conference
9 原子操作类之18罗汉增强
Navicat连接2002 - Can‘t connect to local MySQL server through socket ‘/var/lib/mysql/mysql.sock‘解决
LeetCode 535(C#)
R language ggplot2 visualization: use the ggecdf function of ggpubr package to visualize the grouping experience cumulative density distribution function curve, and the linetype parameter to specify t
R语言dplyr包mutate_at函数和min_rank函数计算dataframe中指定数据列的排序序号值、名次值、将最大值的rank值赋值为1