当前位置:网站首页>相似文本聚类与调参
相似文本聚类与调参
2022-08-04 13:40:00 【小小明-代码实体】
作者: 小小明-代码实体
博客主页:https://blog.csdn.net/as604049322
欢迎点赞 收藏 留言 欢迎讨论!
之前我在《批量模糊匹配的三种方法》一文中讲述了如何匹配最相似文本的方法,其中使用Gensim进行批量模糊匹配,是使用了稀疏的词向量计算相似度,速度相对前面的方法极快。
去年我有使用sklearn做过文本聚类,今天我就给大家演示一下如何在一大堆文本中自动寻找出相似的文本进行聚类,主要思路有:
- 将每个文本进行分词
- 根据词频或TF-IDF生成词向量
- 使用DBSCAN聚类算法对词向量矩阵计算余弦相似度并连接聚类
之前使用Gensim计算出的词频向量无法直接作为sklearn库的输入,需要进行如下转换为专门的稀疏矩阵对象:
from scipy import sparse
data, rows, cols = [], [], []
for i, row in enumerate(data_corpus):
for e, c in row:
rows.append(i)
cols.append(e)
data.append(c)
data = sc.csr_matrix((data, (rows, cols)))
为了方便,今天词向量和聚类算法都使用sklearn库,不再使用Gensim库。
首先我们读取测试数据:
import pandas as pd
import numpy as np
import jieba
df = pd.read_csv("所有客户.csv", encoding="gbk")
中文分词
分词的好坏会直接影响后续词向量的表现,我们可以根据数据集的情况自定义词汇,例如我根据前20条数据的情况增加相应的药店品牌:
words = ["元岗", "铭心堂", "金健民", "祺和", "钜富", "杏园春", "天平民康"]
for word in words:
jieba.add_word(word)
如果我们需要分词的数据集存在停用词,可以使用如下代码将所有非中文字符(不含几个生僻字)删除:
df.user = df.user.str.replace("[^一-龟]+", "", regex=True)
然后执行分词并查看结果:
data_split_word = df.user.apply(jieba.lcut).apply(" ".join)
data_split_word.head(20)
0 [珠海, 广药, 康鸣, 医药, 有限公司]
1 [深圳市, 宝安区, 中心医院]
2 [中山, 火炬, 开发区, 伴康, 药店]
3 [中山市, 同方, 医药, 有限公司]
4 [广州市, 天河区, 元岗, 金健民, 医药, 店]
5 [广州市, 天河区, 元岗, 居健堂, 药房]
6 [广州市, 天河区, 元岗, 润佰, 药店]
7 [广州市, 天河区, 元岗, 协心, 药房]
8 [广州市, 天河区, 元岗, 心怡, 药店]
9 [广州市, 天河区, 元岗, 永亨堂, 药店]
10 [广州市, 天河区, 员村, 德晖, 中, 西药店]
11 [广州市, 天河区, 员村, 东兴, 堂昌, 乐园, 药店]
12 [广州市, 天河区, 员村, 合家欢, 大, 药房]
13 [广州市, 天河区, 员村, 慷乐, 医药, 商店]
14 [广州市, 天河区, 员村, 为民, 永康, 药店]
15 [广州市, 天河区, 珠江, 新城, 钜富, 药店]
16 [广州市, 天河区, 珠江, 新城, 祺和, 药店]
17 [广州市, 天河区, 珠江, 新城, 杏园春, 药店]
18 [广州市, 天河, 沙河, 云芝, 中药店]
19 [广州市, 天河, 天平民康, 药店]
Name: user, dtype: object
当前前20条数据勉强算是分词达标。
当然明显药房和药店这些词的含义相同,如果我需要进一步减少影响,完全可以批量将其替换为一致的词汇。
创建词频向量
然后我们需要使用sklearn建立词频向量:
from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer()
title_vec = count.fit_transform(data_split_word)
注意:如果我们需要使用TF-IDF模型当某个词在多个文本中出现时降低其权重,直接将
CountVectorizer修改为TfidfVectorizer即可。
title_vec是个稀疏矩阵:<43487x24882 sparse matrix of type '<class 'numpy.int64'>' with 224221 stored elements in Compressed Sparse Row format>
可以看看稀疏矩阵的结果:
print(title_vec[:2])
(0, 17283) 1
(0, 10626) 1
(0, 11177) 1
(0, 5944) 1
(0, 13505) 1
(1, 16416) 1
(1, 9475) 1
(1, 2833) 1
SciPy 稀疏矩阵:https://www.runoob.com/scipy/scipy-sparse-matrix.html
DBSCAN原理简介
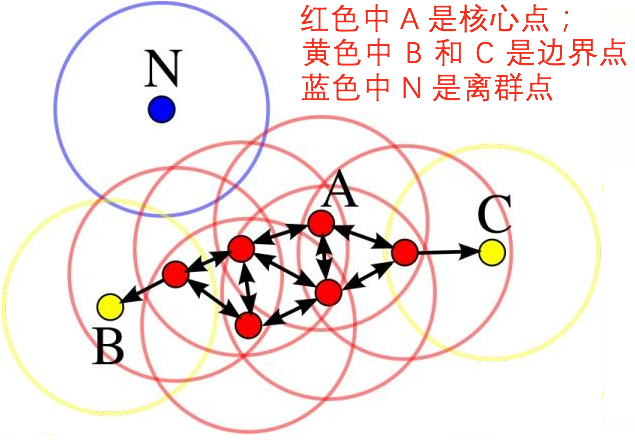
DBSCAN的核心参数是eps和min_samples,eps表示上图圆的半径,如果两个词向量的距离小于eps就会被连接在一起,而一个点能否成为中心点取决于圆内的点是否超过min_samples。
如何计算两个词向量之间的距离呢?sklearn内置了各种公式。
各类距离公式可查阅:https://xiao-xiaoming.github.io/DataMiningGuide/#/chapter-2
下面编写一个方法用于测试各种公式计算距离:
from sklearn.metrics import pairwise_distances
def calc_distance(i, j, metric="l1"):
x, y = title_vec[i].toarray(), title_vec[j].toarray()
print(i, j, data_split_word[i], "|", data_split_word[j],
pairwise_distances(x, y, metric=metric)[0][0])
先测试曼哈顿距离:
for i, j in combinations(range(3, 11), 2):
calc_distance(i, j)
3 4 中山市 同方 医药 有限公司 | 广州市 天河区 元岗 金健民 医药 店 7.0
3 5 中山市 同方 医药 有限公司 | 广州市 天河区 元岗 居健堂 药房 9.0
3 6 中山市 同方 医药 有限公司 | 广州市 天河区 元岗 润佰 药店 9.0
3 7 中山市 同方 医药 有限公司 | 广州市 天河区 元岗 协心 药房 9.0
3 8 中山市 同方 医药 有限公司 | 广州市 天河区 元岗 心怡 药店 9.0
3 9 中山市 同方 医药 有限公司 | 广州市 天河区 元岗 永亨堂 药店 9.0
3 10 中山市 同方 医药 有限公司 | 广州市 天河区 员村 德晖 中 西药店 9.0
4 5 广州市 天河区 元岗 金健民 医药 店 | 广州市 天河区 元岗 居健堂 药房 4.0
4 6 广州市 天河区 元岗 金健民 医药 店 | 广州市 天河区 元岗 润佰 药店 4.0
4 7 广州市 天河区 元岗 金健民 医药 店 | 广州市 天河区 元岗 协心 药房 4.0
4 8 广州市 天河区 元岗 金健民 医药 店 | 广州市 天河区 元岗 心怡 药店 4.0
4 9 广州市 天河区 元岗 金健民 医药 店 | 广州市 天河区 元岗 永亨堂 药店 4.0
4 10 广州市 天河区 元岗 金健民 医药 店 | 广州市 天河区 员村 德晖 中 西药店 6.0
5 6 广州市 天河区 元岗 居健堂 药房 | 广州市 天河区 元岗 润佰 药店 4.0
5 7 广州市 天河区 元岗 居健堂 药房 | 广州市 天河区 元岗 协心 药房 2.0
5 8 广州市 天河区 元岗 居健堂 药房 | 广州市 天河区 元岗 心怡 药店 4.0
5 9 广州市 天河区 元岗 居健堂 药房 | 广州市 天河区 元岗 永亨堂 药店 4.0
5 10 广州市 天河区 元岗 居健堂 药房 | 广州市 天河区 员村 德晖 中 西药店 6.0
6 7 广州市 天河区 元岗 润佰 药店 | 广州市 天河区 元岗 协心 药房 4.0
6 8 广州市 天河区 元岗 润佰 药店 | 广州市 天河区 元岗 心怡 药店 2.0
6 9 广州市 天河区 元岗 润佰 药店 | 广州市 天河区 元岗 永亨堂 药店 2.0
6 10 广州市 天河区 元岗 润佰 药店 | 广州市 天河区 员村 德晖 中 西药店 6.0
7 8 广州市 天河区 元岗 协心 药房 | 广州市 天河区 元岗 心怡 药店 4.0
7 9 广州市 天河区 元岗 协心 药房 | 广州市 天河区 元岗 永亨堂 药店 4.0
7 10 广州市 天河区 元岗 协心 药房 | 广州市 天河区 员村 德晖 中 西药店 6.0
8 9 广州市 天河区 元岗 心怡 药店 | 广州市 天河区 元岗 永亨堂 药店 2.0
8 10 广州市 天河区 元岗 心怡 药店 | 广州市 天河区 员村 德晖 中 西药店 6.0
9 10 广州市 天河区 元岗 永亨堂 药店 | 广州市 天河区 员村 德晖 中 西药店 6.0
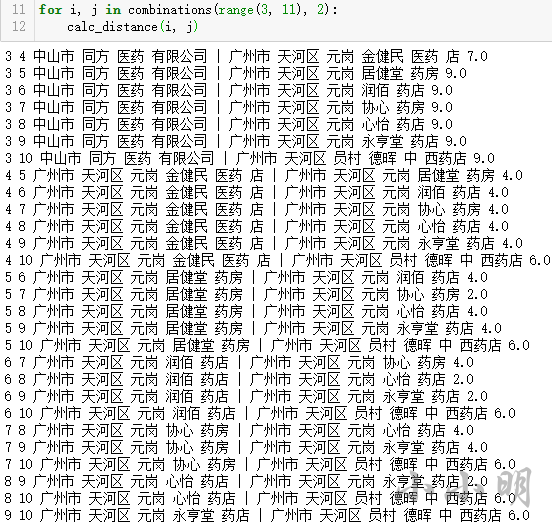
从目前的数据来看,可以认为曼哈顿距离在4以内的认为相似。
for i, j in combinations(range(3, 11), 2):
calc_distance(i, j, "l2")
而欧几里得距离下,可以认为距离在2以内的相似:
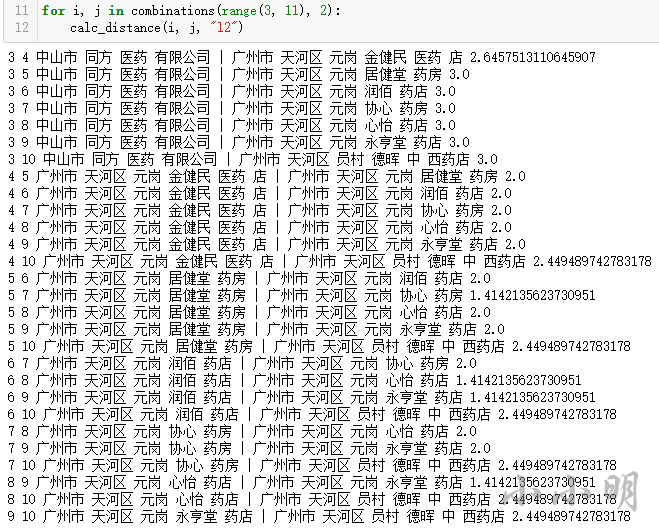
而余弦相似度距离下或许应该设置距离0.4以内认为相似:
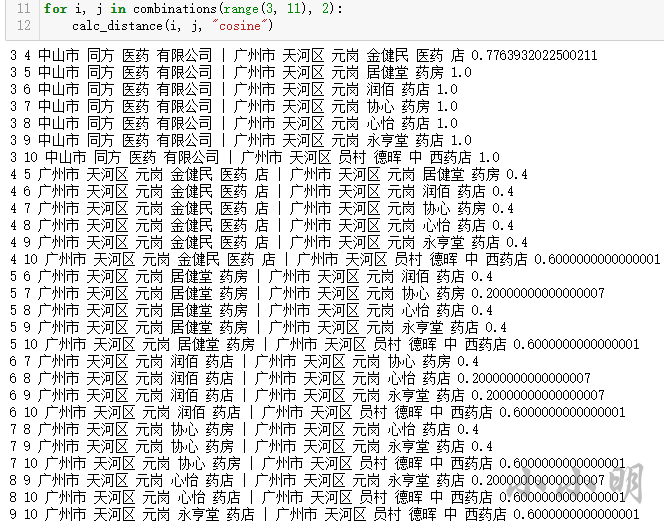
DBSCAN聚类
今天我们就使用余弦相似度进行聚类:
from sklearn.cluster import DBSCAN
model = DBSCAN(eps=0.4, min_samples=5, metric="cosine")
model.fit(title_vec)
df['label'] = model.labels_
结果中标签-1未找到相似文本的节点,标签0往往表示大量的数据都被聚类到了这里面:
print("未被聚类:", df.query("label==-1").shape[0])
print("都被聚在一起:", df.query("label==0").shape[0])
print("正常的聚类:", df.query("label not in (-1,0)").shape[0])
print("产生类别数:", df.label.nunique()-2)
未被聚类: 5727
都被聚在一起: 35840
正常的聚类: 1920
产生类别数: 203
我们可以不断调整eps和metric得到更准确的结果。下面我们预览一下成功聚类的部分的聚类结果:
for label, df_split in df.query("label not in (-1,0)").groupby("label"):
print(label, df_split.user.to_list())
if label > 50:
break

整体而已,个人觉得结果还不错~
当然,这种文本聚类问题不可能100%结果完全准确,这需要大家根据数据集的情况,细化到每个步骤去调整,最好能够自定义距离计算公式(metric参数支持传入自动化函数)~
相关参考:
使用sklearn处理经纬度的三种距离计算与地图可视化
边栏推荐
猜你喜欢
Week 7 Latent Variable Models and Expectation Maximization
Arduino框架下I2S控制ADC采样以及PWM输出示例解析

视觉SLAM十四讲学习笔记 第7讲 视觉里程计

面试官:说一下NIO和BIO的区别

面试官:如何查看/etc目录下包含abc字符串的文件?

《社会企业开展应聘文职人员培训规范》团体标准在新华书店上架
用过Apifox这个API接口工具后,确实感觉postman有点鸡肋......
跨链桥已成行业最大安全隐患 为什么和怎么办
未来已来,只是尚未流行

新 Nsight Graph、Nsight Aftermath 版本中的性能提升和增强功能
随机推荐
HDU1580 输出先手能取的方案数
CReFF缓解长尾数据联邦学习(IJCAI 2022)
A discussion of integrated circuits
MPLS实验
nVisual secondary development - Chapter 2 nVisual API operation guide Swagger use
倒计时 3 天|一起看云原生 Meetup 的六大议题
内存定位利器-ASAN使用小结
【LeetCode】38、外观数列
博途200/1500PLC多段曲线控温FB(支持40段控温曲线、段曲线搜索、暂停、跳段等功能)
(记录)异步并发,多线程处理表的统计
七夕当然要学会SQL优化好早点下班去找对象
router---Programmatic navigation
Cows 树状数组
c#学习_第二弹
leetcode 48. Rotate Image 旋转图像(Medium)
秋招攻略秘籍,吃透25个技术栈Offer拿到手软
postgre 支持 newsql 特性可行性有多大?
双目立体视觉笔记(三)三角测量、极线校正
【解决方案 三十一】Navicat数据库结构同步
Week 7 Latent Variable Models and Expectation Maximization