当前位置:网站首页>Caching mechanism of leveldb
Caching mechanism of leveldb
2022-07-06 13:28:00 【shenmingik】
List of articles
The role of caching
leveldb To improve write performance , At the expense of some read performance . In the worst case, you may need to traverse each level Each file in . To alleviate read performance ,leveldb Cache mechanism is introduced , Of course , The version information includes each level The file meta information of can also improve the reading performance to a certain extent .
Basic components
The basic components of the whole cache module are divided into :ShardedLRUCache、LRUCache、HandleTable、LRUHandle.
- ShardedLRUCache: This is designed to reduce the overhead of frequent locking and unlocking , Adopt the idea of zoning , Divide different elements into different LRUCache in .
- LRUCache: This is divided into two parts : Hash table and bidirectional circular linked list , Structure for managing cached data
- HandleTable: Hashtable , Adopt the idea of open chain method to avoid hash Conflict , It stores specific elements
- LRUHandle: Represents the entity of the element ,<key,value> structure
The general relationship of the four is shown in the figure below :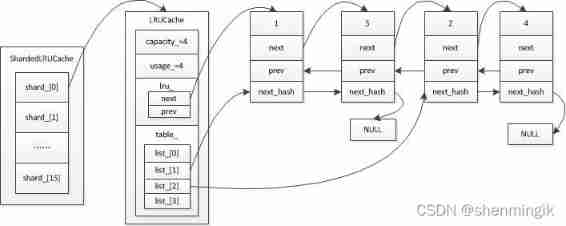
LRUCache
This structure is used to store <key,value> Structured data . It has many uses in design ,next_hash be used for hash surface ;prev,next It is used for two-way circular linked list . And it also uses and shared_ptr The same design , Only when this LRUCache The reference count is 0 Will really call the user's incoming deleter To release resources .
void* value; //<key,value>
// Medium value value , Access by pointer , It can be of any kind , This can be replaced by tem
void (*deleter)(
const Slice&,
void*
value); // Custom delete , Because the element may be applied in heap memory , Special release is required
LRUHandle* next_hash; // solve hash Collision , Point to next hash Elements of the same value
LRUHandle* next; // be used for list A two-way circular list
LRUHandle* prev; // be used for list A two-way circular list
size_t charge; // Memory footprint
size_t key_length; // key The length of
bool in_cache; // Is the element in LRU Cache in
uint32_t refs; // Reference count of element , It is mainly used for Remove function
uint32_t
hash; // Through the idea of offline computing , Calculate the of the element Hash value , Directly compare this when comparing Hash value , There is no time-consuming operation of string comparison
char key_data
[1]; // Key The beginning of , Multiple Key In the same memory space , use key_begin+key_length The way to position Key
HashHandle
This class will build a hash Table to store the actual LRUHandle, There are only three properties :
private:
uint32_t length_; // hash Long table
uint32_t elems_; // hash The number of table elements
LRUHandle** list_; // hash surface , Each table item is a bidirectional circular array
We can see ,LevelDB Use a secondary pointer to represent one by one Hash surface , This is what I think is more innovative . Let's first look at the diagram it shows :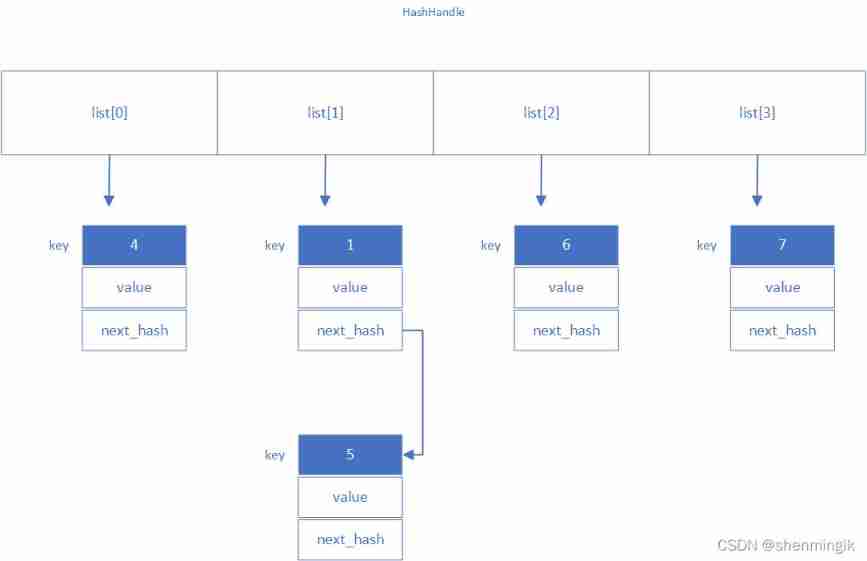
notes :
LevelDB in hash The default number of buckets is 4 individual
Insert elements
stay hash The first thing to do when inserting elements into a table is to know where this value should be placed hash Inside the bucket , This process corresponds to the function FindPointer:
/** * @brief find key The bidirectional circular linked list that should be inserted * * @param key key value * @param hash key Of hash value * @return LRUHandle** Suitable for insertion key The location of */
LRUHandle** FindPointer(const Slice& key, uint32_t hash) {
// length-1 It's equivalent to hash For mold taking hash operation
LRUHandle** ptr = &list_[hash & (length_ - 1)];
// Because there is hash The question of conflict , So we don't necessarily want to get the pointer here , It needs constant comparison
while (*ptr != nullptr && ((*ptr)->hash != hash || key != (*ptr)->key())) {
ptr = &(*ptr)->next_hash;
}
return ptr;
}
After finding the position where the element should be inserted, you can directly insert the element by using the head insertion method . Suppose we are going to insert key by 10, Now our length by 4, that 011 & 1010 = 10, We can insert it into the second bucket with the head insertion method :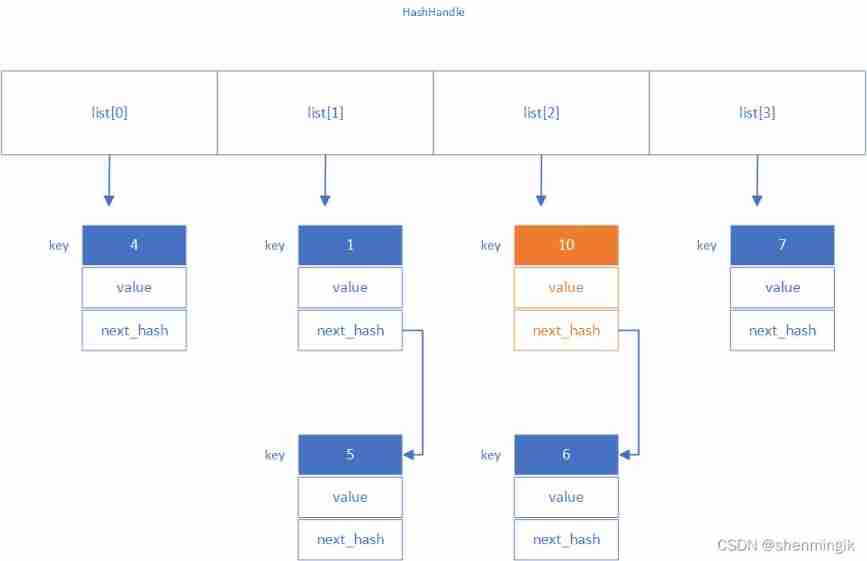
And insert , We will inevitably encounter the situation of insufficient space , At this time, we will expand the capacity .LevelDB The expansion rule of is Whole hash The number of elements in the table > Number of barrels , So the above table is a little irregular , Ha ha ha ha .
LevelDB Will implement the strategy of double capacity expansion , For example, our current 6 Elements are greater than 4 The number of barrels , Then next we will get 8 It's a bucket hash Watch . After that, the elements inside are rehash The process , Rebuild hash Table and delete the original hash surface .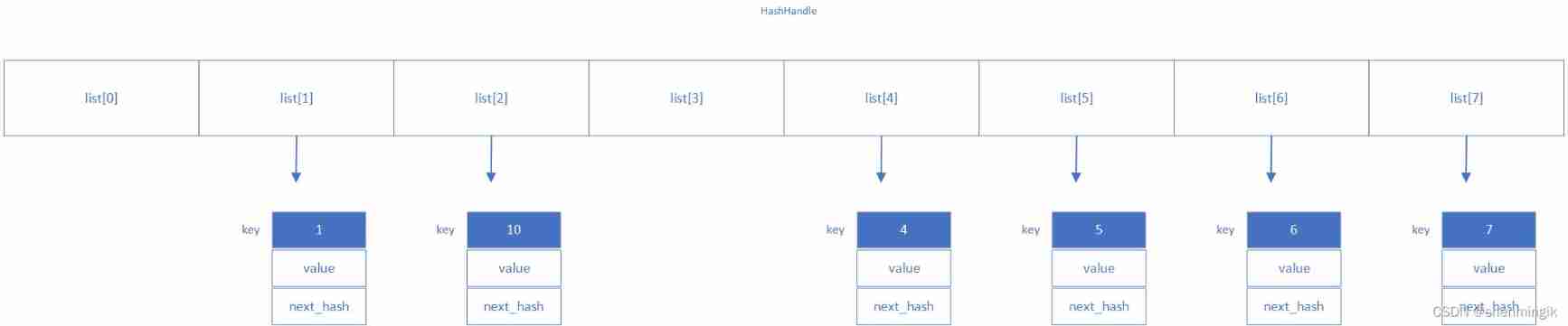
The code of the whole process is as follows :
/** * @brief Insert element in hash table * * @param h Pointer to the element to be inserted * @retval LRUHandle* The original element exists in hash The table returns a pointer to the original element * @retval nullptr There is no return */
LRUHandle* Insert(LRUHandle* h) {
LRUHandle** ptr = FindPointer(h->key(), h->hash);
LRUHandle* old = *ptr;
h->next_hash = (old == nullptr ? nullptr : old->next_hash);
*ptr = h;
if (old == nullptr) {
++elems_;
if (elems_ > length_) {
// Since each cache entry is fairly large, we aim for a small
// average linked list length (<= 1).
// Capacity expansion
Resize();
}
}
return old;
}
LRUCache
LRUCache use LRU Cache structure for , Its main structure has two LRU List and Hash Table. Special attention should be paid to the two linked lists in its design lru and in_use, The same element is different and exists in the two linked lists at the same time .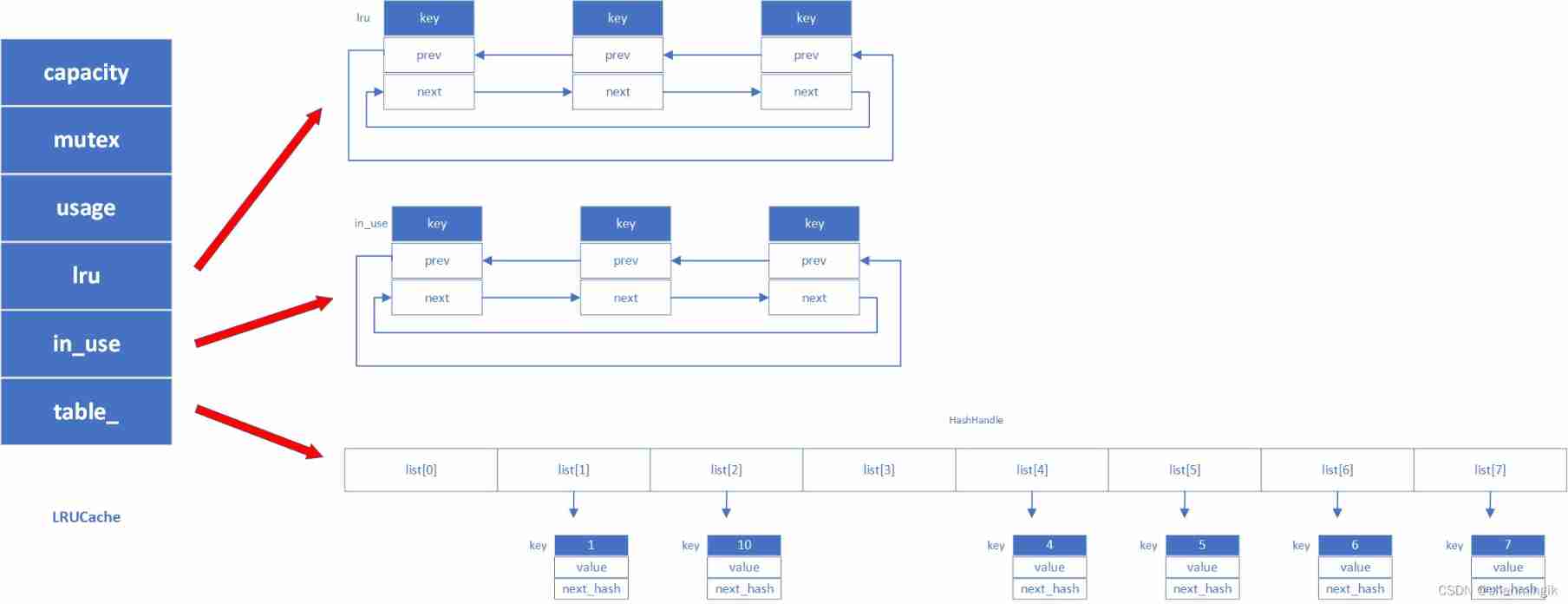
private:
size_t capacity_; // LRU Total cache capacity , Number of bytes
mutable port::Mutex mutex_; // lock
size_t usage_ GUARDED_BY(mutex_); // LRU The capacity used by the cache
LRUHandle lru_ GUARDED_BY(
mutex_); // LRU List, prev It points to relatively new data ,next Point to older data
// The data inside meets the conditions refs==1 && in_cache==true
LRUHandle in_use_
GUARDED_BY(mutex_); // in_use list, There are quilts client Data used
// The data meets the conditions refs >= 2 and in_cache==true
HandleTable table_ GUARDED_BY(mutex_); // HashHandle, Hashtable
Insert elements
For this cached insert element operation , First, it will be based on the data transmitted from the upper layer , apply LRUHandle The required memory space and build this element . meanwhile , Here we will initially set the reference count to 1, Because this data is transmitted to be used externally . after , Insert it into in_use Linked list and hash In the table , What we should pay attention to here is if hash There is this element before the table , Will pass the old elements FinishErase Delete , At the same time, add new elements to hash surface .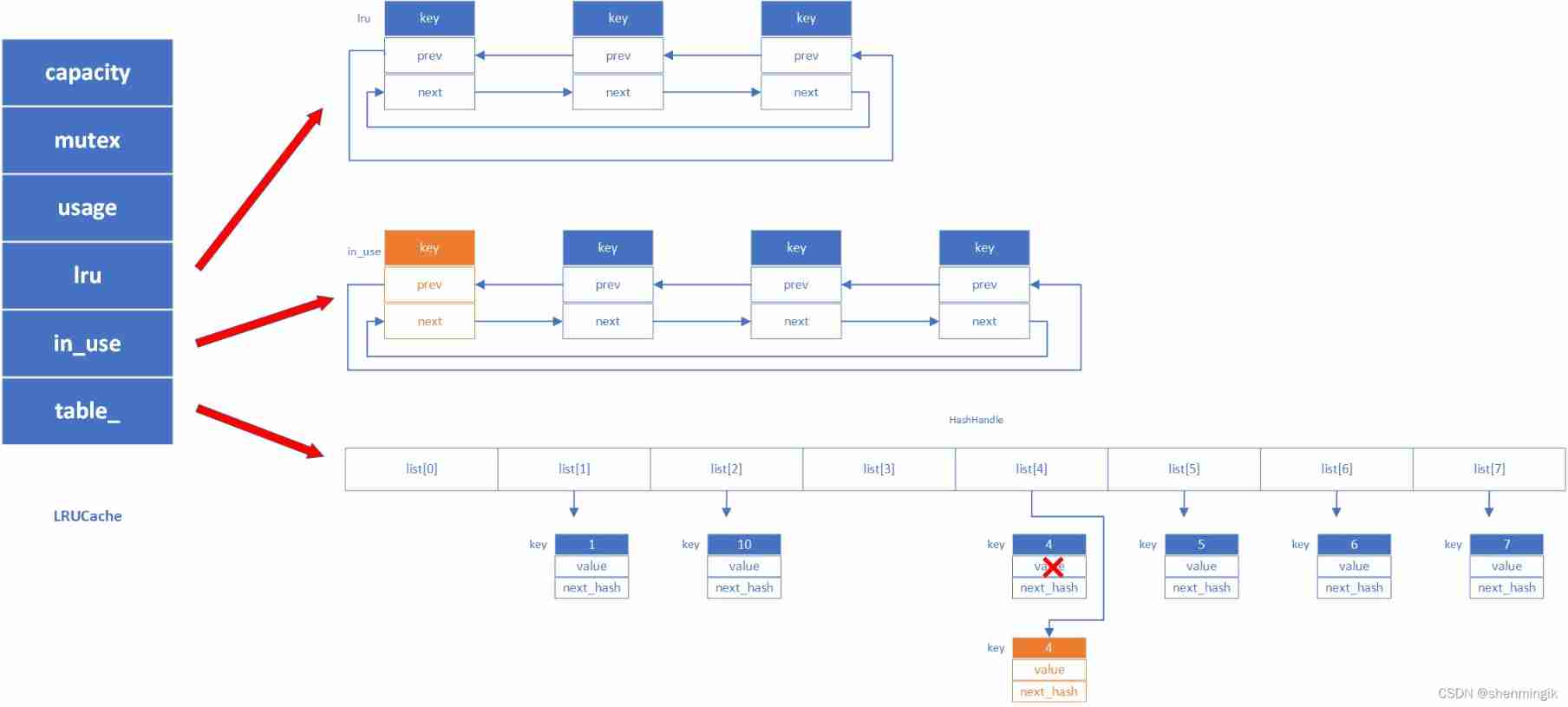
and LRUCache There is no such thing as HashTable Such capacity expansion mechanism , So once it exceeds the limit, it will delete the oldest data .
/** * @brief Element is inserted into the cache * * @param key key * @param hash Elements key Of hash value * @param value Elements value * @param charge Memory size occupied by element * @param deleter Custom delete * @return Cache::Handle* Returns a pointer to an element */
Cache::Handle* LRUCache::Insert(const Slice& key, uint32_t hash, void* value,
size_t charge,
void (*deleter)(const Slice& key,
void* value)) {
MutexLock l(&mutex_);
// Memory build cache elements
// here -1 Because char key[1];
LRUHandle* e =
reinterpret_cast<LRUHandle*>(malloc(sizeof(LRUHandle) - 1 + key.size()));
e->value = value;
e->deleter = deleter;
e->charge = charge;
e->key_length = key.size();
e->hash = hash;
e->in_cache = false;
e->refs = 1; // for the returned handle.
// This is referenced by the return value
std::memcpy(e->key_data, key.data(), key.size());
if (capacity_ > 0) {
e->refs++; // for the cache's reference. This is cache quote
e->in_cache = true;
LRU_Append(&in_use_, e); // Join in in_use list
usage_ += charge; // Number of bytes used by cache ++
FinishErase(table_.Insert(e)); // Element added to hash surface
} else {
// The cache has no capacity , Return alone at this time e
e->next = nullptr;
}
// Not enough capacity , And lru Link list is not empty
// Here is cleaning lru list Until the capacity is met
while (usage_ > capacity_ && lru_.next != &lru_) {
LRUHandle* old = lru_.next;
assert(old->refs == 1);
bool erased = FinishErase(table_.Remove(old->key(), old->hash));
if (!erased) {
// to avoid unused variable when compiled NDEBUG
assert(erased);
}
}
return reinterpret_cast<Cache::Handle*>(e);
}
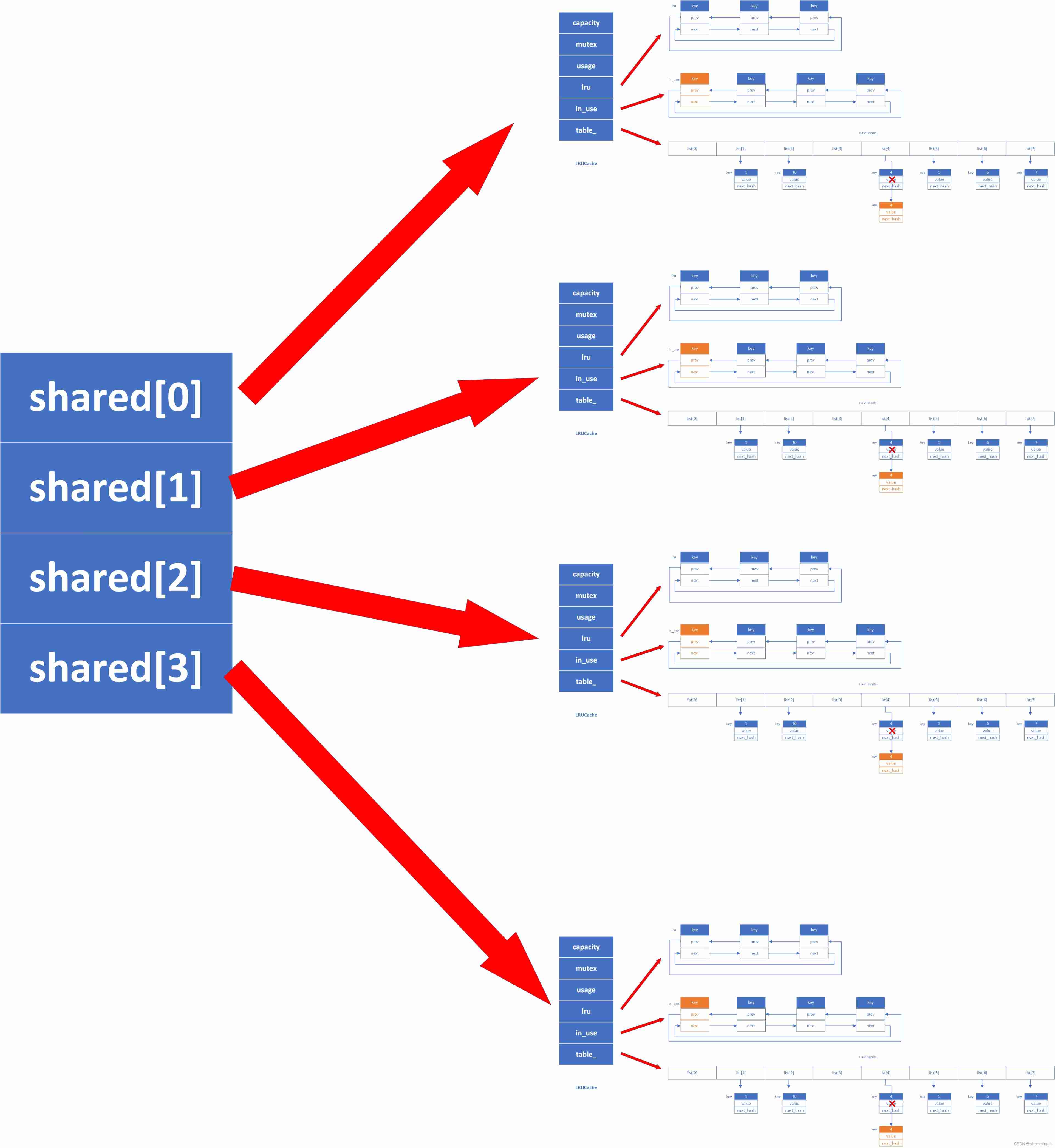
ShardedLRUCache
I said that before ,ShardedLRUCache It is a partition based mechanism used to avoid lock overhead . We can also learn from its Insert The function shows that . Its basis key Calculate what it should be LRUCache, Then call this LRUCache Of Insert Operation is OK .
Handle* Insert(const Slice& key, void* value, size_t charge,
void (*deleter)(const Slice& key, void* value)) override {
// Calculation key Of hash value
const uint32_t hash = HashSlice(key);
//Shared It's a hash function
return shard_[Shard(hash)].Insert(key, hash, value, charge, deleter);
}
reference
[1] leveldb And cache
[2] levelDB Source code
边栏推荐
- Change vs theme and set background picture
- First acquaintance with C language (Part 2)
- 抽象类和接口
- First acquaintance with C language (Part 1)
- 1.C语言矩阵加减法
- Branch and loop statements
- Introduction pointer notes
- (ultra detailed onenet TCP protocol access) arduino+esp8266-01s access to the Internet of things platform, upload real-time data collection /tcp transparent transmission (and how to obtain and write L
- ROS machine voice
- 初识指针笔记
猜你喜欢
4.二分查找
3.输入和输出函数(printf、scanf、getchar和putchar)
5.函数递归练习

View UI plus released version 1.2.0 and added image, skeleton and typography components
4.分支语句和循环语句
阿里云微服务(一)服务注册中心Nacos以及REST Template和Feign Client
5. Function recursion exercise

Decomposition relation model of the 2022 database of tyut Taiyuan University of Technology
更改VS主题及设置背景图片
Alibaba cloud microservices (III) sentinel open source flow control fuse degradation component
随机推荐
系统设计学习(二)Design a key-value cache to save the results of the most recent web server queries
Alibaba cloud microservices (IV) service mesh overview and instance istio
Application architecture of large live broadcast platform
The overseas sales of Xiaomi mobile phones are nearly 140million, which may explain why Xiaomi ov doesn't need Hongmeng
Wei Pai: the product is applauded, but why is the sales volume still frustrated
凡人修仙学指针-2
Relational algebra of tyut Taiyuan University of technology 2022 database
C language to achieve mine sweeping game (full version)
分支语句和循环语句
4.二分查找
Design a key value cache to save the results of the most recent Web server queries
阿里云微服务(四) Service Mesh综述以及实例Istio
Small exercise of library management system
FileInputStream和BufferedInputStream的比较
12 excel charts and arrays
阿里云微服务(二) 分布式服务配置中心以及Nacos的使用场景及实现介绍
7. Relationship between array, pointer and array
4.30 dynamic memory allocation notes
View UI plus released version 1.2.0 and added image, skeleton and typography components
MySQL 30000 word essence summary + 100 interview questions, hanging the interviewer is more than enough (Collection Series