当前位置:网站首页>MySQL 30000 word essence summary + 100 interview questions, hanging the interviewer is more than enough (Collection Series
MySQL 30000 word essence summary + 100 interview questions, hanging the interviewer is more than enough (Collection Series
2022-07-06 13:04:00 【Java misty rain】

Written in the book before : Don't suggest that up is a variety of interview questions listed , And then endorsing to remember , It's very little help to improve the technology , It doesn't help a good interview either , The interviewer who has a little bit of stuff is confused when he digs deep .
I suggest that you take the interview questions as a review of Feynman's learning method 、 Simplify the process , Preparing for the interview , Tell yourself the topic first , See if you will be satisfied , If you are not satisfied, continue to learn this point , So again and again , well offer It's not far from you , cheer up
One 、MySQL framework
Compared with other databases ,MySQL It's a little different , Its architecture can be applied in many different scenarios and play a good role . Mainly reflected in the storage engine architecture , The plug-in storage engine architecture separates query processing from other system tasks and data storage and extraction . This architecture can choose the right storage engine according to the needs of the business and the actual needs .

adjoining course : At the top are some clients and connection services . Mainly completes some similar to the connection processing 、 Authorized certification 、 And related safety programs . The concept of thread pool is introduced in this layer , Provide threads for clients accessing through authentication security . Also on this layer, we can implement the system based on SSL Security links for . The server will also verify the operation permissions it has for each client of secure access .
Service layer : The second service layer , It mainly completes most of the core service functions , Including query parsing 、 analysis 、 Optimize 、 cache 、 And all the built-in functions , All the functions across storage engines are also implemented in this layer , Including triggers 、 stored procedure 、 View etc.
Engine layer : The third tier is the storage engine tier , The storage engine is really responsible for MySQL The storage and extraction of data in , Server pass API Communicating with the storage engine . Different storage engines have different functions , So we can choose according to our actual needs
Storage layer : The fourth layer is the data storage layer , It mainly stores data on the file system running on the device , And complete the interaction with the storage engine
*Draw MySQL Architecture diagram , This kind of abnormal questions can be asked
MySQL The specific query process is ?or One SQL Statements in MySQL How to execute ?
Client request ---> The connector ( Verify user identity , Give authority ) ---> The query cache ( If there is a cache, it directly returns , If it does not exist, follow-up operations will be performed ) ---> analyzer ( Yes SQL Carry out lexical analysis and grammatical analysis ) ---> Optimizer ( Mainly for the implementation of sql Optimize the method of selecting the best execution plan ) ---> actuator ( When executing, it will first see whether the user has execution permission , You can use the interface provided by this engine ) ---> Go to the engine layer to get the data and return it ( If query caching is turned on, query results will be cached ) chart : Geek time

*say something MySQL What storage engines are there ? What are the differences ?
Two 、 Storage engine
The storage engine is MySQL The components of , Used to handle different types of tables SQL operation . Different storage engines provide different storage mechanisms 、 Indexing techniques 、 Lock level and other functions , Using different storage engines , You can also get specific functions .
You can choose which engine to use flexibly , Multiple tables in a database can use different engines to meet various performance and practical requirements , Use the right storage engine , Will improve the performance of the entire database .
MySQL Server usage Pluggable Architecture of storage engine based on XML , From the running MySQL The server loads or unloads the storage engine .
View storage engine
-- Check out the supported storage engines
SHOW ENGINES
-- View the default storage engine
SHOW VARIABLES LIKE 'storage_engine'
-- View the storage engine used by a specific table , The default storage engine has been modified !
show create table tablename
-- Accurately view the storage engine used by a table in a database
show table status like 'tablename'
show table status from database where name="tablename"
Set up the storage engine
-- Specify the storage engine when creating the table . The default is INNODB, You don't have to set it
CREATE TABLE t1 (i INT) ENGINE = INNODB;
CREATE TABLE t2 (i INT) ENGINE = CSV;
CREATE TABLE t3 (i INT) ENGINE = MEMORY;
-- Modify the storage engine
ALTER TABLE t ENGINE = InnoDB;
-- Modify the default storage engine , It can also be found in the configuration file my.cnf Modify the default engine in
SET default_storage_engine=NDBCLUSTER;
By default , whenever CREATE TABLE or ALTER TABLE When the default storage engine cannot be used , Will generate a warning . To prevent confusing unexpected behavior when the required engine is not available , Enable NO_ENGINE_SUBSTITUTION SQL Pattern . If the required engine is not available , This setting will produce an error instead of a warning , And no tables are created or changed
Storage engine comparison
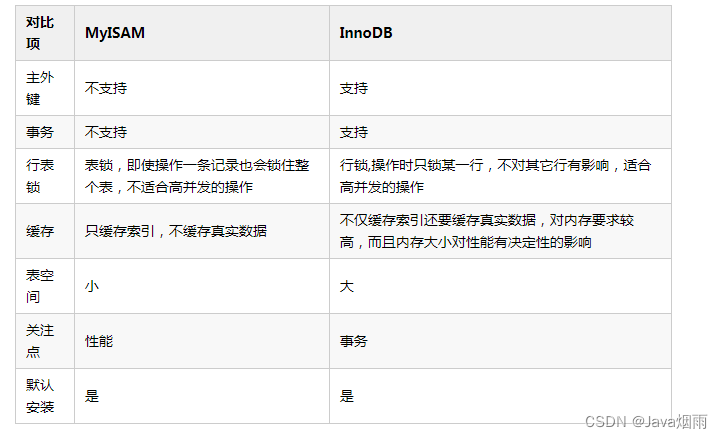
The common storage engine is InnoDB、MyISAM、Memory、NDB.
InnoDB Now it is MySQL The default storage engine , Support Business 、 Row level locking and foreign keys
File storage structure comparison
stay MySQL Create any data table in , There are corresponding tables in the database directory corresponding to its data directory .frm file ,.frm The file is used to hold the metadata of each data table (meta) Information , Including the definition of table structure, etc , Nothing to do with the database storage engine , In other words, the data table of any storage engine must have .frm file , The name is Data table name .frm, Such as user.frm.
see MySQL Where is the data stored :show variables like 'data%'
MyISAM The physical file structure is :
.frmfile : Metadata information related to tables is stored in frm file , Including the definition information of table structure.MYD(MYData) file :MyISAM Storage engine specific , Used to store MyISAM The data table.MYI(MYIndex) file :MyISAM Storage engine specific , Used to store MyISAM Table index information
InnoDB The physical file structure is :
.frmfile : Metadata information related to tables is stored in frm file , Including the definition information of table structure.ibdFile or.ibdatafile : These two kinds of documents are stored InnoDB Data files , There are two kinds of files InnoDB The data of , Because InnoDB The way of data storage can be determined by configuration Shared tablespace Storing data , Or use it Exclusive table space Storing data .Exclusive table space storage
.ibdfile , And one for each watch.ibdfile Shared table space is stored in.ibdatafile , All tables use one.ibdatafile ( Or more , You can configure it yourself )
*ps: Serious company , These are all done by professional operation and maintenance , The data backup 、 Recovery or something , Let me have one Javaer In this case , No more money ?
The interview answers like this
InnoDB Support transactions ,MyISAM Unsupported transaction . This is a MySQL Set the default storage engine from MyISAM become InnoDB One of the important reasons ;
InnoDB Support foreign keys , and MyISAM I won't support it . For one containing a foreign key InnoDB Table to MYISAM Will fail ;
InnoDB It's a clustered index ,MyISAM It's a non clustered index . The files of the cluster index are stored on the leaf node of the primary key index , therefore InnoDB There must be a primary key , Indexing through the primary key is very efficient . But the secondary index needs two queries , First query to the primary key , Then query the data through the primary key . therefore , The primary key should not be too large , Because the primary key is too big , Other indexes will be big . and MyISAM Yes no clustered index , Data files are separate , The index holds the pointer of the data file . Primary key index and secondary index are independent .
InnoDB Do not save the specific rows of the table , perform
select count(*) from tableYou need a full scan . and MyISAM A variable is used to save the number of rows in the whole table , When executing the above statement, you only need to read the variable , fast ;InnoDB The smallest lock granularity is row locks ,MyISAM The smallest lock granularity is table locks . An update statement locks the entire table , As a result, other queries and updates will be blocked , So concurrent access is limited . This is also MySQL Set the default storage engine from MyISAM become InnoDB One of the important reasons ;
A watch , There are ID Since the primary key , When insert 了 17 After that , Delete the first 15,16,17 Bar record , And then Mysql restart , Again insert A record , This record is ID yes 18 still 15 ?
If the table type is MyISAM, So 18. because MyISAM The table will automatically increase the maximum primary key ID Record it in a data file , restart MySQL Maximum of auto increment primary key ID It won't lose ;
If the table type is InnoDB, So 15. because InnoDB The table just adds the maximum value of the auto incrementing primary key ID Record in memory , So restart the database or change the table OPTION operation , Will lead to the maximum ID The loss of .
*Which storage engine performs select count(*) faster , Why? ?
MyISAM faster , because MyISAM Internal maintenance of a counter , It can be called directly .
stay MyISAM In the storage engine , Store the total number of rows of the table on disk , When executed select count(*) from t when , Return the total data directly .
stay InnoDB In the storage engine , Follow MyISAM Dissimilarity , The total number of rows is not stored on disk , When executed select count(*) from t when , It's going to read the data first , The accumulation of lines , Finally, the total quantity is returned .
InnoDB in count(*) Statements are executed , Total number of full table scans , So as the data gets bigger , The statement becomes more and more time-consuming , Why? InnoDB The engine doesn't look like MyISAM Engine like , Store the total number of rows on disk ? This one InnoDB The transaction characteristics of , Due to multi version concurrency control (MVCC) Why ,InnoDB surface “ How many lines should be returned ” It's also uncertain .
3、 ... and 、 data type
It mainly includes the following five categories :
Integer types :BIT、BOOL、TINY INT、SMALL INT、MEDIUM INT、 INT、 BIG INT
Floating point type :FLOAT、DOUBLE、DECIMAL
String type :CHAR、VARCHAR、TINY TEXT、TEXT、MEDIUM TEXT、LONGTEXT、TINY BLOB、BLOB、MEDIUM BLOB、LONG BLOB
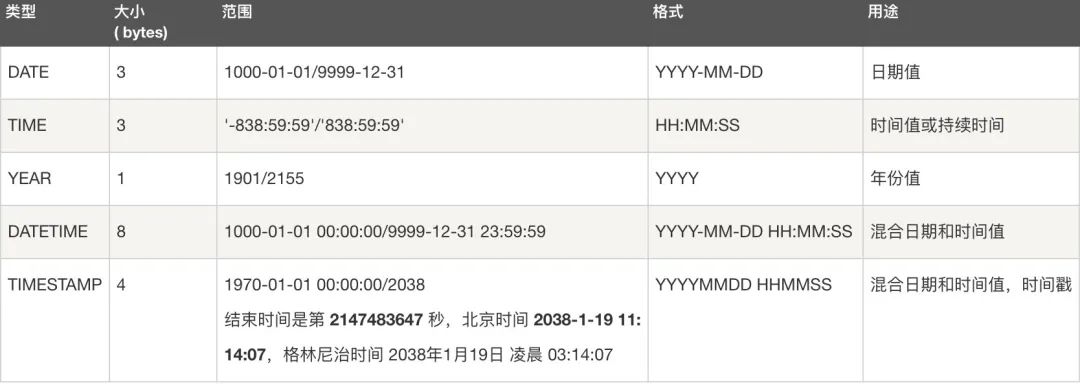
The date type :Date、DateTime、TimeStamp、Time、Year
Other data types :BINARY、VARBINARY、ENUM、SET、Geometry、Point、MultiPoint、LineString、MultiLineString、Polygon、GeometryCollection etc.


*CHAR and VARCHAR The difference between ?
char It's a fixed length ,varchar Variable length :
char(n) and varchar(n) In brackets n Represents the number of characters , It doesn't mean the number of bytes , such as CHAR(30) You can store 30 Characters .
When the storage , The former does not care about the length of the data actually stored , Directly by char Allocate storage space according to the specified length ; The latter allocates the final storage space according to the data actually stored
The same thing :
char(n),varchar(n) Medium n All represent the number of characters
exceed char,varchar Maximum length n After the limitation of , The string will be truncated .
Difference :
char No matter how many characters are actually stored, it will take up n Space of characters , and varchar Will only take up the actual characters should take up byte space plus 1( Actual length length,0<=length<255) Or add 2(length>255). because varchar When saving data, in addition to the string, a byte will be added to record the length ( If the column declaration length is greater than 255 Then use two bytes to save the length ).
The maximum storage limit is different :char The maximum storage limit for is 255 byte .
char The trailing spaces will be truncated during storage , and varchar Can't .
char It's suitable for very short storage 、 General fixed length string . for example ,char Perfect for storing passwords MD5 value , Because it's a fixed length value . For very short columns ,char Than varchar It's also more efficient in terms of storage space .
*What string types of columns can be ?
The string type is :SET、BLOB、ENUM、CHAR、CHAR、TEXT、VARCHAR
*BLOB and TEXT What's the difference? ?
BLOB It's a binary object , Can hold a variable amount of data . There are four types of BLOB:TINYBLOB、BLOB、MEDIUMBLO and LONGBLOB
TEXT It's a case insensitive BLOB. Four kinds of TEXT type :TINYTEXT、TEXT、MEDIUMTEXT and LONGTEXT.
BLOB Save binary data ,TEXT Save character data .
Four 、 Indexes
*Tell me about your right MySQL Understanding of index ?
The principle of database index , Why use B+ Trees , Why not use a binary tree ?
The difference between a clustered index and a nonclustered index ?
InnoDB Index strategy in the engine , Do you know ?
What are the ways to create an index ?
Cluster index / Nonclustered index ,mysql Index underlying implementation , Why not B-tree, Why not hash, Does the leaf node store data or point to the memory address of the data , There are a few things to pay attention to when using index ?
MYSQL The official definition of index is : Indexes (Index) Help MySQL Data structure for efficient data acquisition , So The essence of index is : data structure
The purpose of indexing is to improve query efficiency , It can be compared to a dictionary 、 Train station watch of train No 、 A catalogue of books, etc .
It can be simply understood as “ Quickly find data structures in order ”, Beyond the data itself , The database also maintains a data structure that satisfies a specific search algorithm , These data structures are referenced in some way ( Point to ) data , In this way, advanced search algorithms can be implemented on these data structures . This data structure , It's index. . The following figure is an example of a possible indexing method .

The data table on the left , There are two columns and seven records , On the far left is the physical address of the data record . In order to speed up Col2 Lookup , You can maintain a binary search tree as shown on the right , Each node contains an index key value , And a pointer to the physical address of the corresponding data record , In this way, we can use binary search to get the corresponding data within a certain complexity , So as to quickly retrieve the qualified records .
The index itself is big , It's impossible to store everything in memory , It is usually stored on disk in the form of index file
The usual index , If not specified , Namely B+ Trees ( Multiple search trees , It doesn't have to be a binary tree ) Index of structural organization . Where the clustered index , Secondary index , Overlay index , In line with the index , Prefix index , The only index defaults to B+ Tree index , Collectively, index . In addition, there are hash indexes and so on .

Basic grammar :
establish :
Create index :
CREATE [UNIQUE] INDEX indexName ON mytable(username(length));If it is CHAR,VARCHAR type ,length It can be less than the actual length of the field ; If it is BLOB and TEXT type , Must specify length.
Modify table structure ( Add index ):
ALTER table tableName ADD [UNIQUE] INDEX indexName(columnName)
Delete :
DROP INDEX [indexName] ON mytable;see :
SHOW INDEX FROM table_name\G-- You can do it by adding \G To format the output information .Use ALERT command
ALTER TABLE tbl_name ADD PRIMARY KEY (column_list):This statement adds a primary key , This means that the index value must be unique , And cannot be NULL.ALTER TABLE tbl_name ADD UNIQUE index_name (column_listThe value of the index created by this statement must be unique ( except NULL Outside ,NULL There may be many times ).ALTER TABLE tbl_name ADD INDEX index_name (column_list)Add a normal index , Index values can appear multiple times .ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list)The statement specifies that the index is FULLTEXT , For full-text indexing .
advantage
Improve the efficiency of data retrieval , Lower the database IO cost
Reduce the cost of sorting data , Reduce CPU Consumption of
Inferiority
Index is also a table , Save the primary key and index fields , And points to the record of the entity table , So it also needs to take up memory
Although the index greatly improves the query speed , At the same time, it will reduce the speed of updating the table , Such as on the table INSERT、UPDATE and DELETE. Because when updating tables ,MySQL Not only to save data , Also save the fields in the index file that have index columns added every time it is updated , Will adjust the index information after the key value changes due to the update
MySQL Index classification
Data structure perspective
B+ Tree index
Hash Indexes
Full-Text Full-text index
R-Tree Indexes
From the perspective of physical storage
Clustered index (clustered index)
Nonclustered indexes (non-clustered index), Also called secondary index (secondary index)
Both clustered and nonclustered indexes are B+ Tree structure
From a logical point of view
primary key : Primary key index is a special unique index , No null values are allowed
Common index or single column index : Each index contains only a single column , A table can have multiple single-column indexes
Multi column index ( Composite index 、 Joint index ): A composite index is an index created on multiple fields , Only the first field that created the index is used in the query criteria , Indexes are used . Follow the leftmost prefix set when using composite indexes
Unique index or non unique index
Spatial index : A spatial index is an index of a field of a spatial data type ,MYSQL The spatial data types in are 4 Kind of , Namely GEOMETRY、POINT、LINESTRING、POLYGON.MYSQL Use SPATIAL Keyword extension , Enables syntax for creating regular index types to create spatial indexes . A column that creates a spatial index , It must be declared as NOT NULL, Spatial index can only be used when the storage engine is MYISAM Create... In the table of
*Why? MySQL In the index B+tree, no need B-tree Or other trees , Why not Hash Indexes
Cluster index / Nonclustered index ,MySQL Index underlying implementation , Does the leaf node store data or point to the memory address of the data , There are a few things to pay attention to when using index ?
Can index query improve query performance ? Why? ?
MySQL Index structure
First, understand the index (index) It's in the storage engine (storage engine) Level realized , instead of server level . Not all storage engines support all index types . Even if multiple storage engines support a certain index type , Their implementation and behavior may also differ .
B+Tree Indexes
MyISAM and InnoDB Storage engine , All use B+Tree Data structure of , It's relative to B-Tree structure , All the data is stored on the leaf node , And the leaf nodes are connected together through pointers , Form a linked list of data , To speed up the retrieval efficiency of adjacent data .
Let's get to know B-Tree and B+Tree The difference between
B-Tree
B-Tree It is a balanced search tree designed for external storage devices such as disks .
When the system reads data from the disk to memory, it uses disk blocks (block) In basic units , Data in the same disk block will be read out at one time , It's not about taking what you need .
InnoDB There are pages in the storage engine (Page) The concept of , Page is the smallest unit of its disk management .InnoDB The default size of each page in the storage engine is 16KB, You can use the parameters innodb_page_size Set the page size to 4K、8K、16K, stay MySQL You can view the size of the page through the following command :show variables like 'innodb_page_size';
The storage space of a disk block in the system is not so large , therefore InnoDB Each time you apply for disk space, there will be several consecutive address blocks to reach the page size 16KB.InnoDB When reading disk data into disk, it will take page as basic unit , When querying data, if every piece of data in a page can help locate the location of data records , This will reduce the number of disks I/O frequency , Improve query efficiency .
B-Tree The structure of data allows the system to efficiently find the disk block where the data is located . To describe B-Tree, First, define a record as a binary [key, data] ,key For the key value of the record , Corresponds to the primary key value in the table ,data For data in a row of records other than the primary key . For different records ,key The values are different from each other .
A tree m Step B-Tree Has the following characteristics :
Each node has at most m A child
Except for the root node and the leaf node , Every other node has at least Ceil(m/2) A child .
If the root node is not a leaf node , At least 2 A child
All leaf nodes are on the same layer , And does not contain other keyword information
Each non terminal node contains n Keyword information (P0,P1,…Pn, k1,…kn)
Number of keywords n Satisfy :ceil(m/2)-1 <= n <= m-1
ki(i=1,…n) Keyword , And the keywords are sorted in ascending order
Pi(i=1,…n) Is the pointer to the root node of the subtree .P(i-1) All node keywords of the pointed subtree are less than ki, But they are greater than k(i-1)
B-Tree Each node in can contain a lot of keyword information and branches according to the actual situation , As shown in the figure below is a 3 Step B-Tree:

picture :DobbinSoong
Each node occupies the disk space of a disk block , A node has two ascending keywords and three pointers to the root node of the subtree , The pointer stores the address of the disk block where the child node is located . The two keywords are divided into three range fields corresponding to the range fields of the data of the subtree pointed by three pointers . Take the root node as an example , Keyword is 17 and 35,P1 The data range of the subtree that the pointer points to is less than 17,P2 The data range of the subtree that the pointer points to is 17~35,P3 The data range of the subtree that the pointer points to is greater than 35.
Simulation search keywords 29 The process of :
Find the disk block according to the root node 1, Read in memory .【 disk I/O Operation No. 1 Time 】
Compare keywords 29 In the interval (17,35), Find the disk block 1 The pointer to P2.
according to P2 Pointer to disk block 3, Read in memory .【 disk I/O Operation No. 2 Time 】
Compare keywords 29 In the interval (26,30), Find the disk block 3 The pointer to P2.
according to P2 Pointer to disk block 8, Read in memory .【 disk I/O Operation No. 3 Time 】
On disk block 8 Find the keyword in the keyword list in 29.
Analyze the above process , Discover the need for 3 Secondary disk I/O operation , and 3 Secondary memory lookup operation . Because the keyword in memory is an ordered table structure , You can use dichotomy to improve efficiency . and 3 Secondary disk I/O Operation affects the whole B-Tree Look for the determinants of efficiency .B-Tree be relative to AVLTree Reduced the number of nodes , Make every disk I/O All the data fetched to memory works , Thus, the query efficiency is improved .
B+Tree
B+Tree Is in B-Tree An optimization based on , Make it more suitable to implement the external storage index structure ,InnoDB The storage engine just uses B+Tree Implement its index structure .
From... In the previous section B-Tree In the structure diagram, you can see that each node contains not only the key value , also data value . The storage space of each page is limited , If data Large data will result in each node ( It's a page ) Can store key The number is very small , When the amount of data stored is large, it will also cause B-Tree The depth is greater , Increase the disk size of the query I/O frequency , And then affect the query efficiency . stay B+Tree in , All data record nodes are stored on the same layer of leaf nodes according to the order of key values , Instead of just storing on the leaf node key Value information , This can greatly increase the storage capacity of each node key Value quantity , Reduce B+Tree Height .
B+Tree be relative to B-Tree There are several differences :
Non leaf nodes only store key information ;
There is a chain pointer between all leaf nodes ;
Data records are stored in leaf nodes
Take the B-Tree Optimize , because B+Tree The non leaf node only stores key information , Suppose that each disk block can store 4 Key value and pointer information , Has become a B+Tree Its structure is shown in the figure below :

Usually in B+Tree There are two head pointers on it , One points to the root node , Another one points to the smallest leaf node of the keyword , And all the leaf nodes ( Data nodes ) Between them is a kind of chain ring structure . So it's OK to B+Tree Do two kinds of search operations : One is the range search and paging search for the primary key , The other is starting from the root node , Make a random search .
Maybe in the above example only 22 Data records , I can't see B+Tree The advantages of , Let's make a calculation :
InnoDB The page size in the storage engine is 16KB, The primary key type of a general table is INT( Occupy 4 Bytes ) or BIGINT( Occupy 8 Bytes ), The pointer type is also generally 4 or 8 Bytes , That is to say, a page (B+Tree One of the nodes in ) About storage in 16KB/(8B+8B)=1K Key value ( Because it's valuation , For ease of calculation , there K The value is 10^3). That is to say, a depth is 3 Of B+Tree Indexes can be maintained 10^3 * 10^3 * 10^3 = 10 Billion Bar record .
In practice, each node may not be full , So in the database ,B+Tree The height of is usually in 2-4 layer .MySQL Of InnoDB The storage engine is designed to keep the root node in memory , That is to say, to find the row record of a key value, you only need to 1~3 Secondary disk I/O operation .
B+Tree nature
Through the above analysis , We know IO The frequency depends on b+ The number of highly h, Suppose the data in the current data table is N, The number of data items per disk block is m, Then there are h=㏒(m+1)N, When the amount of data N Under certain circumstances ,m The bigger it is ,h The smaller it is ; and m = The size of the disk block / The size of the data item , The size of the disk block is the size of a data page , Is constant , If the data items take up less space , The more data items there are , The lower the height of the tree . That's why every data item , That is, keep the index field as small as possible , such as int Occupy 4 byte , than bigint8 Half the number of bytes . That's why b+ Trees require real data to be placed in leaf nodes instead of inner nodes , Once in the inner node , The data items of the disk block will be greatly reduced , Cause trees to rise . When the data item is equal to 1 It will degenerate into a linear table .
When b+ The data items of the tree are composite data structures , such as (name,age,sex) When ,b+ The Numbers are built from left to right , For example, when ( Zhang San ,20,F) When such data is retrieved ,b+ Trees take precedence name To determine the next step of the search direction , If name Compare the same again age and sex, Finally, the retrieved data is obtained ; But when (20,F) No such thing name When the data comes in ,b+ The tree doesn't know which node to look up next , Because when you build the search tree name That's the first comparison factor , It has to be based on name Search to know where to search next . For example, when ( Zhang San ,F) When such data is retrieved ,b+ A tree can be used name To specify the search direction , But the next field age The lack of , So we can only find the data whose name is equal to zhang SAN , And then match the gender F The data of the , This is a very important property , namely Leftmost matching feature of the index .
MyISAM The structure of primary key index and secondary index
MyISAM The index file and data file of the engine are separated .MyISAM The data field of the leaf node of the engine index structure , It's not the actual data record , It's the address of the data record . The index file is separated from the data file , Such an index is called " Nonclustered index ".MyISAM There is little difference between the primary index and the secondary index , It's just that the primary key index can't have duplicate keywords .

stay MyISAM in , Indexes ( Nodes with leaves ) Store in a separate .myi In file , The leaf node stores the physical address offset of the data ( Access by offset is random access , fast ).
The primary index is the primary key index , Key values cannot be repeated ; The secondary index is the general index , The key value may be repeated .
The process of finding data by index : First, find the index node from the index file , The file pointer from which to get the data , And then to the data file, through the file pointer to locate the specific data . Secondary index is similar to .
InnoDB The structure of primary key index and secondary index
InnoDB The data field of the leaf node of the engine index structure , What's stored is the actual data record ( For the primary index , All the data records in the table will be stored here ; For secondary indexes, primary keys are referenced here , When retrieving, find the corresponding data row in the primary key index through the primary key ), Or say ,InnoDB The data file itself is the primary key index file , Such an index is called “ Cluster index ”, A table can only have one clustered index .
primary key :
We know InnoDB An index is a clustered index , Its index and data are stored in the same .idb In the document , So its index structure is to store index and data in the same tree node at the same time , As shown in the figure below, the lowest leaf node has three lines of data , Corresponding to... In the data table id、stu_id、name Data item .

stay Innodb in , Index is divided into leaf node and non leaf node , The non leaf node is like the directory of Xinhua dictionary , Stored separately in the index segment , The leaf nodes are arranged in order , In the data segment .Innodb The data file can be divided according to the table ( Just turn on innodb_file_per_table), Cut and store in xxx.ibd in , Default no segmentation , Store in xxx.ibdata in .
auxiliary ( Non primary key ) Indexes :
This time, let's take an example of name Column to build secondary index , Its index structure is very different from that of primary key index , There are two rows of data in the bottom leaf node , The string on the first line is the secondary index , according to ASCII Code to sort , The integer in the second line is the value of the primary key .
That means , Yes name Column to search , Two steps are required :
① Search... On the secondary index name, Go to its leaf node to get the corresponding primary key ;
② Use the primary key to perform the corresponding retrieval operation on the primary index
That's what we call it “ Return to the table for query ”

InnoDB The key points of index structure
The data file itself is the index file
Table data file itself is by pressing B+Tree An index structure file of an organization
A leaf node in a clustered index contains a complete data record
InnoDB The table must have a primary key , And it is recommended to use integer auto incrementing primary key
As we mentioned above InnoDB Storage structure , Indexes and data are stored together , Whether it's a primary key index or a secondary index , When searching, we can get the corresponding data only by finding the index node first , If we don't explicitly specify index columns when we design the table structure ,MySQL The index will be built by selecting the column with non duplicate data from the table , If there are no matching Columns , be MySQL Automatically for InnoDB Table generates an implicit field as the primary key , And the length of this field is 6 Bytes , Type is integer .
*So why recommend using integer auto incrementing primary keys instead of choosing UUID?
UUID Is string , More storage space than integers ;
stay B+ When searching in the tree, you need to compare the size with the value of the passing node , The comparison of integer data is faster than string ;
Self incrementing integer indexes are continuously stored on disk , When reading a page of data, it is also continuous ;UUID It's random , The upper and lower rows of data read are stored separately , Not suitable for execution where id > 5 && id < 20 Conditional query statement of .
When inserting or deleting data , An integer autoincrement primary key creates a new leaf node at the end of the leaf node , It doesn't destroy the structure of the left subtree ;UUID It's easy to have a primary key like this ,B+ In order to maintain its own characteristics , It's possible to restructure , Consume more time .
*Why do leaf nodes of non primary key index structure store primary key values ?
Ensure data consistency and save storage space , It's understandable : The order table of the mall system stores a user ID As an associated foreign key , It is not recommended to store complete user information , Because when we use the information in the user table ( Real name 、 cell-phone number 、 Shipping address ···) After modification , There is no need to maintain the user data of the order table again , It also saves storage space .
Hash Indexes
Mainly through Hash Algorithm ( common Hash The algorithm has direct address method 、 Square with the middle method 、 Folding method 、 Division and remainder 、 Random number method ), Convert database field data to fixed length Hash value , Store with the row pointer of this data Hash The corresponding position of the table ; In case of Hash Collision ( Two different keywords Hash Same value ), It corresponds to Hash The key is stored as a linked list .
Search algorithm : When retrieving a query , Just do the same thing again Hash Algorithm , obtain Hash value , Corresponding to Hash Take the data from the corresponding position of the table , In case of Hash Collision , You need to filter when you take the value . Currently in use Hash There are not many databases to index , There are mainly Memory etc. .
MySQL There are Memory The engine and NDB Engine support Hash Indexes .
full-text Full-text index
Full text index is also MyISAM A special index type of , Mainly used for full-text indexing ,InnoDB from MYSQL5.6 Version provides support for full-text indexing .
It's used to replace the less efficient LIKE Fuzzy matching operation , Moreover, the full-text index of multi field combination can match multiple fields at one time .
Also use B-Tree Storing index data , But using a specific algorithm , Divide the field data and index it ( In general 4 One byte at a time ), The index file stores the set of index strings before segmentation , And the index information after segmentation , Corresponding Btree The node of the structure stores the word information after segmentation and its position in the index string set before segmentation .
R-Tree Spatial index
The spatial index is MyISAM A special index type of , Mainly used for geospatial data types
*Why? Mysql Index to use B+ Trees are not B Trees ?
use B+ No trees B The tree is thinking about IO Impact on performance ,B Each node of the tree stores data , and B+ Only leaf nodes in the tree store data , So look for the same amount of data ,B Trees are higher ,IO More often . Database indexes are stored on disk , When the amount of data is large , You can't load the entire index into memory , You can only load each disk page one by one ( The node corresponding to the index tree ). Among them in MySQL Bottom pair B+ Tree for further optimization : In the leaf node is a two-way linked list , And the head node and tail node of the linked list also point to the loop .
*interviewer : Why not use Hash The way ?
because Hash The bottom layer of the index is the hash table , Hash table is a kind of key-value Structure of stored data , So there is no sequential relationship between multiple data in the storage relationship , therefore , For interval query, it is impossible to query directly through index , You need a full scan . therefore , Hash index is only applicable to the scenario of equivalent query . and B+ Tree It's a multi way balanced query tree , So his nodes are natural and orderly ( The left child node is smaller than the parent node 、 The parent node is smaller than the right child ), Therefore, full table scanning is not necessary for range query .
Hash index does not support the leftmost matching rule of multi column union index , If there are a lot of duplicate keys worth it , Hash indexing is inefficient , Because there is a hash collision problem .
Which situations need to be indexed
Primary key automatically creates unique index
Frequent fields as query criteria
Fields associated with other tables in the query , Index foreign key relationship
Single key / The choice of Composite Index , High and low tendency to create composite index
Fields sorted in the query , Sorting field greatly improves sorting speed through index access
Statistics or grouping fields in a query
When not to create indexes
There are too few records
Often add or delete tables
Table fields with duplicate and evenly distributed data , Only the most frequently queried and sorted data columns should be indexed ( If a data class contains too much duplicate data , Indexing doesn't make much sense )
Frequently updated fields are not suitable for index creation ( It will aggravate IO burden )
where The fields that are not used in the condition are not indexed
MySQL Efficient indexing
Overlay index (Covering Index), Or index overlay , That is to say, there is no need to return table operation
Namely select The data columns of can be obtained only from the index , You don't have to read rows of data ,MySQL You can use the index to return select Fields in the list , Instead of having to read the data file again according to the index , let me put it another way The query column should be covered by the index .
Indexing is an efficient way to find rows , But the general database can also use the index to find the data of a column , So it doesn't have to read the entire line . After all, index leaf nodes store the data they index , When you can get the desired data by reading the index , Then there's no need to read lines . An index contains ( Cover ) The data that satisfies the query result is called overlay index .
Criteria of judgment
Use explain, It can be output through extra Let's judge , For an index overlay query , Is shown as using index,MySQL The query optimizer will decide whether there is an index override query before executing the query
5、 ... and 、MySQL Inquire about
*count(*) and count(1) and count( Name ) difference ps: There are a lot of statements about this question
On the effect of execution :
count(*) It includes all the columns , Equivalent to the number of lines , When it comes to statistical results , Column values of... Are not ignored NULL
count(1) Including all the columns , use 1 Represents the line of code , When it comes to statistical results , Column values of... Are not ignored NULL
count( Name ) Only include the column of the list , When it comes to statistical results , Will ignore null column values ( The null here is not just an empty string or 0, It means null) Count of , That is, the value of a field is NULL when , No statistics .
In terms of execution efficiency :
The column name is primary key ,count( Name ) than count(1) fast
Column name is not primary key ,count(1) than count( Name ) fast
If the table has multiple columns and no primary key , be count(1) Is superior to the execution efficiency count(*)
If there is a primary key , be select count( Primary key ) The efficiency of execution is optimal
If the table has only one field , be select count(*) The optimal .
*MySQL in in and exists The difference between ?
exists:exists For external use loop Query item by item , Every time you query, you will see exists Conditional statement , When exists When the conditional statement in can return the record line ( No matter how many record lines are , As long as you can go back ), The condition is true , Returns the current loop This record I got ; conversely , If exists The conditional statement in cannot return a record line , Is the current loop The record we got was discarded ,exists It's like a bool Conditions , When the result set can be returned, it is true, If the result set cannot be returned, it is false
in:in A query is equivalent to multiple or The superposition of conditions
SELECT * FROM A WHERE A.id IN (SELECT id FROM B);
SELECT * FROM A WHERE EXISTS (SELECT * from B WHERE B.id = A.id);
If the two tables in the query are the same size , Then use in and exists Not much difference .
If one of the two tables is smaller , One is a big watch , Then the sub query table is very useful exists, Small use of subquery table in:
*UNION and UNION ALL The difference between ?
UNION and UNION ALL Both merge two result sets into one , Two to unite SQL sentence The number of fields must be the same , And the field type is “ Compatible with ”( Agreement );
UNION Duplicate data records will be filtered out after table join ( Low efficiency ), and UNION ALL The duplicate data records will not be removed ;
UNION It's sorted in the order of the fields , and UNION ALL Simply merge the two results and return ;
SQL Execution order
Handwriting
SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOIN <right_table> ON <join_condition> WHERE <where_condition> GROUP BY <group_by_list> HAVING <having_condition> ORDER BY <order_by_condition> LIMIT <limit_number>Machine reading
FROM <left_table> ON <join_condition> <join_type> JOIN <right_table> WHERE <where_condition> GROUP BY <group_by_list> HAVING <having_condition> SELECT DISTINCT <select_list> ORDER BY <order_by_condition> LIMIT <limit_number>summary

*mysql The inner connection of 、 Left connection 、 What's the difference between a right join ?
What is inner join 、 External connection 、 Cross connect 、 Cartesian product ?
Join chart

6、 ... and 、MySQL Business
*What are the isolation levels of transactions ?MySQL What is the default isolation level for ?
What is unreal reading , Dirty reading , It can't be repeated ?
MySQL The four characteristics of transaction and its implementation principle
MVCC Familiar with? , Its underlying principle ?
MySQL Transactions are mainly used to handle large amount of operations , Data with high complexity . for instance , In the people management system , You delete a person , You need to delete the basic information of the personnel , Also delete information related to the person , Such as mailbox , Articles, etc , such , These database operation statements constitute a transaction !
ACID — The basic elements of business
The business is made up of a group of SQL A logical processing unit made up of statements , have 4 Attributes , Usually referred to as transaction ACID attribute .
A (Atomicity) Atomicity : All operations in the whole transaction , Or it's all done , Or not at all , It's impossible to stop in the middle . An error occurred during the execution of the transaction , Will be rolled back (Rollback) Status to the beginning of the transaction , It's like this transaction has never been executed
C (Consistency) Uniformity : Before and after transaction start , The database integrity constraint is not broken
I (Isolation) Isolation, : The execution of a transaction cannot be interfered by other transactions . That is, the operation and data used within a transaction are isolated from other concurrent transactions , Transactions that execute concurrently cannot interfere with each other
D (Durability) persistence : After the transaction is completed , Changes made by the firm to the database are persisted in the database , It will not be rolled back
Problems caused by concurrent transaction processing
Update missing (Lost Update): Business A And transaction B Select the same line , When the row is then updated based on the originally selected value , Because neither transaction knows the existence of each other , There will be lost updates
Dirty reading (Dirty Reads): Business A Read transaction B Updated data , then B Rollback operation , that A The data read is dirty
It can't be read repeatedly (Non-Repeatable Reads): Business A Read the same data multiple times , Business B In the transaction A During multiple reads , The data has been updated and submitted , Cause transaction A When reading the same data multiple times , Inconsistent results .
Fantasy reading (Phantom Reads): Unreal reading is similar to nonrepeatable reading . It happens in a transaction A Read a few lines of data , Then another concurrent transaction B When some data is inserted . In the subsequent query , Business A There will be more records that don't exist , It's like an illusion , So it's called Unreal reading .
The difference between unreal reading and unrepeatable reading :
The point of unrepeatable reading is to modify : In the same business , The same conditions , The data read the first time is not the same as the data read the second time .( Because there are other transactions in the middle that commit changes )
The point of unreal reading is to add or delete : In the same business , The same conditions ,, The number of records read out the first time and the second time is not the same .( Because there are other transactions committed to insert / Delete )
Solutions to problems caused by concurrent transaction processing :
“ Update missing ” Usually it should be avoided completely . But prevent updates from being lost , It can't be solved by the database transaction controller alone , It needs the application to lock the data to be updated , therefore , It should be the responsibility of the application to prevent the loss of updates .
“ Dirty reading ” 、 “ It can't be read repeatedly ” and “ Fantasy reading ” , In fact, it's all about database read consistency , The database must provide some transaction isolation mechanism to solve :
One is to lock : Before reading the data , Lock it , Prevent other transactions from modifying data .
The other is data multi version concurrency control (MultiVersion Concurrency Control, abbreviation MVCC or MCC), Also known as a multi version database : Don't put any locks on it , Through a certain mechanism to generate a data request point in time consistent data snapshot (Snapshot), And use this snapshot to provide a certain level ( Statement level or transaction level ) Consistent read of . From the user's point of view , It seems that a database can provide multiple versions of the same data .
Transaction isolation level
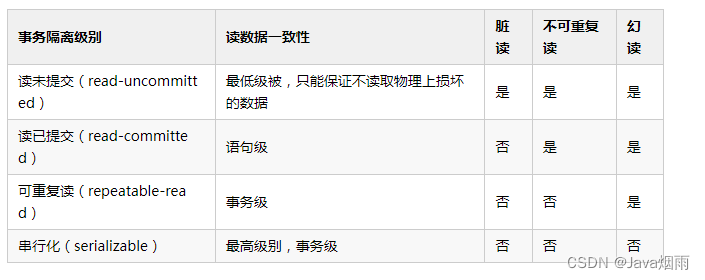
The isolation level for database transactions is 4 Kind of , From low to high
READ-UNCOMMITTED( Read uncommitted ): Lowest isolation level , Allow read of uncommitted data changes , Can cause dirty reading 、 Phantom or unrepeatable reading .
READ-COMMITTED( Read submitted ): Allow to read data submitted by concurrent transactions , Can prevent dirty reading , But phantom or unrepeatable reads can still occur .
REPEATABLE-READ( Repeatable ): Multiple reads of the same field are consistent , Unless the data is modified by the transaction itself , Can prevent dirty and unrepeatable read , But phantom reading can still happen .
SERIALIZABLE( Serializable ): Highest isolation level , Completely obey ACID Isolation level . All transactions are executed one by one , In this way, there is no interference between transactions , in other words , This level prevents dirty reads 、 Unrepeatable reading and phantom reading .
View the transaction isolation level of the current database :
show variables like 'tx_isolation'
The following examples illustrate that dirty reads may occur in the concurrent operation of transactions , It can't be read repeatedly , The connection between unreal reading and transaction isolation level .
The more strict the transaction isolation of the database , The less side effects , But the more it costs , Because transaction isolation essentially makes transactions to a certain extent “ Serialization ” Conduct , This is obviously related to “ Concurrent ” Is contradictory . meanwhile , Different applications have different requirements for read consistency and transaction isolation , For example, many applications are right for “ It can't be read repeatedly ” and “ Fantasy reading ” It's not sensitive , Perhaps more concerned about the ability of concurrent data access .
Read uncommitted
Read uncommitted , That is, one transaction can read the data of another uncommitted transaction .
Example : The boss pays the programmers , Programmers are paid 3.6 ten thousand / month . But the boss accidentally put the wrong number on the payroll , According to a 3.9 ten thousand / month , The money has been paid to the programmer's account , But the transaction has not yet committed , At this moment , The programmer checks his salary for the month , More than usual 3 One thousand yuan , I'm glad I got a raise . But the boss found out in time , Immediately roll back the nearly committed transaction , Change the number to 3.6 All submitted again .
analysis : The actual programmer's salary this month is still 3.6 ten thousand , But what the programmer sees is this 3.9 ten thousand . He saw the data before the boss had committed the transaction . This is dirty reading .
How to solve the problem of dirty reading ?Read committed! Read the submission , It can solve the problem of dirty reading .
Read committed
Read the submission , seeing the name of a thing one thinks of its function , It means that one transaction cannot read data until another transaction is committed .
Example : Programmers take credit cards to enjoy life ( Cary, of course, only has 3.6 ten thousand ), When he pays the bill ( Programmer transaction on ), The charging system detected in advance that his card had 3.6 ten thousand , Right now !! The programmer's wife wants to transfer all the money out for household use , And submit . When the charging system is ready to deduct , Check the amount of the card , It turns out there's no money left ( Of course, the amount of the second test has to wait for the wife's transfer out amount transaction to be submitted ). Programmers are depressed , It's clear that Cary has money …
analysis : That's reading submission , If there is a transaction to update the data (UPDATE) In operation , Read transactions wait for this update operation transaction to commit before reading data , Can solve the problem of dirty reading . But in this case , There is a transaction scope in which two identical queries return different data , This is it. It can't be read repeatedly .
How to solve the problem of non repeatable reading ?Repeatable read !
Repeatable read
Repeated reading , You're just starting to read the data ( The transaction open ) when , Modification operations are no longer allowed .MySQL Default transaction isolation level for
Example : Programmers take credit cards to enjoy life ( Cary, of course, only has 3.6 ten thousand ), When he pays the bill ( The transaction open , No other business is allowed UPDATE Modify the operating ), The charging system detected in advance that his card had 3.6 ten thousand . At this time, his wife can't transfer the amount . Next, the charging system can deduct money .
analysis : Repeated reading solves the problem of unrepeatable reading . Write here , One thing to understand is this , Unrepeatable reads correspond to modifications , namely UPDATE operation . But there may be problems with phantom reading . Because the phantom reading problem corresponds to insertion INSERT operation , instead of UPDATE operation .
When will there be unreal reading ?
Example : Programmers will spend one day , It took 2 One thousand yuan , Then his wife went to check his consumption record today ( Full table scan FTS, Wife business starts ), See, it really took 2 One thousand yuan , Right now , Programmers spend 1 Wan bought a computer , That is, adding INSERT I have a consumption record , And submit . When my wife prints the programmer's list of consumption records ( Wife's affairs ), It took 1.2 Ten thousand yuan , There seems to be an illusion , This is unreal reading .
How to solve the problem of unreal reading ?Serializable!
Serializable serialize
Serializable Is the highest level of transaction isolation , At this level , Sequential execution of transactions , Avoid dirty reading 、 No repetition or unreal reading . Simply speaking ,Serializable Lock every read row , So it may cause a lot of timeout and lock contention problems . This level of transaction isolation is inefficient , Compare database performance , Generally not used .
Compare
It should be noted that , Transaction isolation level and data access concurrency are opposite , The higher the transaction isolation level, the worse the concurrency . Therefore, the appropriate transaction isolation level should be determined according to the specific application , There is no universal principle in this place .
MySQL InnoDB The default isolation level supported by the storage engine is REPEATABLE-READ( Can be reread ). We can go through SELECT @@tx_isolation; Order to see ,MySQL 8.0 The order was changed to SELECT @@transaction_isolation;
What needs to be noted here is : And SQL The difference in standards is InnoDB Storage engine in REPEATABLE-READ( Can be reread ) The transaction isolation level uses Next-Key Lock Algorithm , So we can avoid the production of unreal reading , It works with other database systems ( Such as SQL Server) Is different . So InnoDB The default isolation level supported by the storage engine is REPEATABLE-READ( Can be reread ) The transaction isolation requirements can be fully guaranteed , That is to say SQL The standard SERIALIZABLE( Serializable ) Isolation level , It also retains good concurrency performance .
Because the lower the isolation level , The fewer locks the transaction requests , So the isolation level of most database systems is READ-COMMITTED( Read submitted ):, But what you need to know is InnoDB The storage engine uses... By default REPEATABLE-READ( Can be reread ) There will be no loss of performance .
MVCC Multi version concurrency control
MySQL Most of the transactional storage engine implementations are not simple row level locks . Based on the consideration of improving concurrency , Generally, multi version concurrency control is implemented at the same time (MVCC), Include Oracle、PostgreSQL. It's just that the implementation mechanisms are different .
It can be said that MVCC It's a variant of row lock , But it avoids locking operation in many cases , So the cost is lower . Although the implementation mechanism is different , But most of them realize non blocking read operation , Write operations are just locking the necessary lines .
MVCC The implementation of is realized by saving the snapshot of data at a certain point in time . That is, no matter how long it takes , Everything sees the same data .
Typical MVCC Realization way , It is divided into optimistic (optimistic) Concurrency control and pessimism (pressimistic) concurrency control . Below through InnoDB To illustrate MVCC How it works .
InnoDB Of MVCC, This is achieved by saving two hidden columns behind each row of records . These two columns , A save line creation time , Expiration time of a save line ( Delete time ). Of course, it's not the real time that's stored , It's the system version number (system version number). Every time you start a new business , The system version number will increase automatically . The system version number at the start of the transaction will be the version number of the transaction , Used to compare with the version number of each row of records found .
REPEATABLE READ( Can be reread ) Under isolation level MVCC How to work :
SELECT
InnoDB Each row of records will be checked according to the following two conditions :
Only those meeting the above two conditions will be found
InnoDB Only look up data rows with version earlier than the current transaction version , This ensures that the rows read by the transaction , Either it existed before the transaction started, or it was inserted or modified by the transaction itself
The deleted version number of the row is either undefined , Either greater than the current transaction version number , This ensures that the rows read by the transaction are not deleted before the transaction begins
INSERT:InnoDB Save the current system version number for each newly inserted row as the row version number
DELETE:InnoDB Save the current system version number for each deleted row as the row deletion ID
UPDATE:InnoDB Save the current system version number as the row version number for a new record inserted , At the same time, save the current system version number to the original line as the deletion identification
Save these two extra system version numbers , So that most operations are not locked . Make data operation simple , Performance is very good , It also guarantees that only the rows that meet the requirements will be read . The drawback is that each row of records requires additional storage space , More line checks and some extra maintenance work are needed .
MVCC Only in COMMITTED READ( Read the submission ) and REPEATABLE READ( Repeatable ) Working at two levels of isolation .
Transaction log
InnoDB Use logs to reduce the overhead of committing transactions . Because the transaction has been recorded in the log , There is no need to refresh the dirty blocks in the buffer pool when every transaction is committed (flush) To disk .
Data and indexes modified by transactions are usually mapped to random locations in the table space , So refreshing these changes to disk requires a lot of random IO.
InnoDB Suppose you use a regular disk , Random IO Than the order IO It's much more expensive , Because a IO The request takes time to move the head to the correct position , Then wait for the disk to read out what you need , Go back to the starting position .
InnoDB Log the random IO Into order IO. Once the log is safely written to disk , The transaction is persistent , Even if the power goes out ,InnoDB You can replay logs and recover committed transactions .
InnoDB Use a background thread to intelligently refresh these changes to the data file . This thread can write in batches , Make data write more sequential , To improve efficiency .
Transaction logging can help improve transaction efficiency :
Use transaction log , When the storage engine modifies the data of the table, it only needs to modify its memory copy , Record the modification to the transaction log persistent on the hard disk , Instead of persisting the modified data to disk every time .
The transaction log is appended , So the operation of writing log is the order of a small area on the disk I/O, It's not like random I/O You need to move the heads in multiple places on the disk , So it's much faster to use transaction log .
After the transaction log is persisted , The modified data in memory can be slowly brushed back to disk in the background .
If data changes have been logged to the transaction log and persisted , But the data itself is not written back to disk , At this point the system crashes , The storage engine can automatically recover this part of the modified data when it is restarted .
For the moment , Most storage engines are implemented like this , We usually call it Pre written logs (Write-Ahead Logging), You need to write the disk twice to modify the data .
Implementation of transactions
The implementation of transaction is a storage engine based on database . Different storage engines support transactions differently .MySQL The storage engines that support transactions in are InnoDB and NDB.
The implementation of a transaction is how to implement ACID characteristic .
The isolation of transactions is achieved through locks , And the atomicity of transactions 、 Consistency and persistence are achieved through transaction logging .
*How transactions are implemented through logs , The deeper you talk, the better .
The transaction log includes : Redo log redo and Rollback log undo
redo log( Redo log ) Achieve persistence and atomicity
stay innoDB In the storage engine of , The transaction log is redone (redo) Journal and innoDB Log buffer for storage engine (InnoDB Log Buffer) Realization . When the transaction is opened , Operations in transactions , Will be written to the log buffer of the storage engine first , Before transaction commit , These buffered logs need to be flushed to disk in advance for persistence , This is it. DBA They often say that “ Log first ”(Write-Ahead Logging). When the transaction is committed , stay Buffer Pool The data file mapped in will be slowly refreshed to disk . At this time, if the database crashes or goes down , So when the system restarts for recovery , It can be based on redo log Logs recorded in , Restore the database to its pre crash state . Unfinished business , You can continue to submit , You can also choose to roll back , It depends on the recovery strategy .
When the system starts , It has been redo log Allocated a contiguous block of storage space , Record in the form of sequential addition Redo Log, By order IO To improve performance . All transactions share redo log Storage space , Their Redo Log In the order in which statements are executed , Record in turn .
undo log( Rollback log ) Achieve consistency
undo log Mainly for transaction rollback service . In the process of transaction execution , Except for the records redo log, There will be a certain amount of records undo log.undo log Record the status of data before each operation , If rollback is needed during transaction execution , It can be based on undo log Roll back . Rollback of a single transaction , Only operations done by the current transaction are rolled back , It doesn't affect the operation of other transactions .
Undo Records incomplete transactions that have been partially completed and written to the hard disk , By default, the rollback log records... In the following table space ( Shared or exclusive table space )
Both logs can be regarded as a recovery operation ,redo_log Is to resume page operations that commit transaction modifications , and undo_log Is to roll back row records to a specific version . The contents of the two records are also different ,redo_log It's a physical log , Record the physical modification of the page , and undo_log It's a logical log , Record according to each line .
*Another question : You know, MySQL How many kinds of logs are there ?
Error log : Record error information , Also record some warning or correct information .
Query log : Record all information requested for the database , Whether or not these requests are properly executed .
Slow query log : Set a threshold , Will run for more than the value of all SQL Statements are recorded in the log file of slow query .
Binary log : Record all changes to the database .
relay logs : Relay logs are also binary logs , To give slave Library recovery
Transaction log : Redo log redo And rollback logs undo
*Distributed transaction related issues , You may also ask 2PC、3PC,,,
MySQL Support for distributed transactions
There are many ways to implement distributed transactions , Both can be used InnoDB Provides native transaction support , Message queuing can also be used to achieve the final consistency of distributed transactions . Here we mainly talk about InnoDB Support for distributed transactions .
MySQL from 5.0.3 InnoDB The storage engine is starting to support XA Protocol distributed transactions . A distributed transaction involves multiple actions , The actions themselves are transactional . All actions must be accomplished successfully together , Or rolled back together .
stay MySQL in , Using distributed transactions involves one or more resource managers and one transaction manager .

Pictured ,MySQL The distributed transaction model of . There are three parts in the model : Applications (AP)、 Explorer (RM)、 Transaction manager (TM):
Applications : Defines the boundaries of a transaction , Specify what needs to be done ;
Explorer : Provides a way to access transactions , Usually a database is a resource manager ;
Transaction manager : Coordinate the transactions involved in the global transaction .
Distributed transactions are committed in two phases (two-phase commit) The way :
In the first stage, all the transaction nodes begin to prepare , Tell the transaction manager ready.
In the second phase, the transaction manager tells each node that it is commit still rollback. If one node fails , You need all the global nodes rollback, In order to guarantee the atomicity of the transaction .
7、 ... and 、MySQL Locking mechanism
*Optimistic lock and pessimistic lock of database ?
MySQL What kinds of locks are there , Give me a list ?
MySQL in InnoDB How to realize the row lock of engine ?
MySQL Do you know about the clearance lock , Do you know about deadlocks , Writing a paragraph will cause a deadlock sql sentence , How to solve the deadlock ,MySQL Is there any mechanism to solve deadlock
A lock is a mechanism by which a computer coordinates multiple processes or threads to access a resource concurrently .
In the database , In addition to traditional computing resources ( Such as CPU、RAM、I/O etc. ) Beyond contention , Data is also a resource that is Shared by many users . The database locking mechanism is simple , It is the database to ensure the consistency of data , A rule designed to make all kinds of shared resources orderly in concurrent access .
For example , Let's go to Taobao and buy a product , There is only one item in stock , At this time, if there is another person to buy , So how to solve the problem of whether you bought it or another person bought it ? There must be something here , Let's take the quantity from the inventory first , Then insert the order , Insert payment form information after payment , Then update the number of items . In the process , Using locks can protect limited resources , Solve the contradiction between isolation and concurrency .
Classification of locks
From the classification of the types of data operations :
Read the lock ( Shared lock ): For the same data , Multiple read operations can be performed simultaneously , No interaction
Write lock ( Exclusive lock ): Before the current write operation is completed , It blocks other write and read locks
From the granular classification of data operations :
In order to improve the concurrency of the database as much as possible , The smaller the data range is locked each time, the better , In theory, only locking the data of the current operation at a time will get the maximum concurrency , But managing locks is a resource consuming thing ( It's about getting , Check , Release the lock, etc ), Therefore, the database system needs to balance the high concurrent response and system performance , That's what happened “ Lock granularity (Lock granularity)” The concept of .
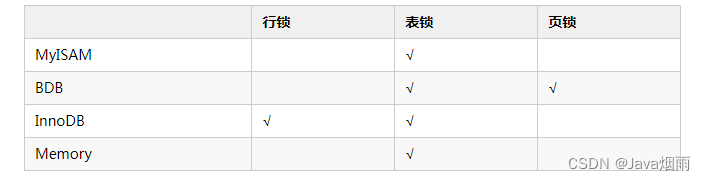
Table lock : Low overhead , Locked fast ; A deadlock will not occur ; Large locking size , The highest probability of lock collisions , Lowest degree of concurrency (MyISAM and MEMORY The storage engine uses table level locks );
Row-level locks : Spending big , Lock the slow ; A deadlock occurs ; Locking granularity minimum , The lowest probability of lock collisions , The highest degree of concurrency (InnoDB Storage engine supports both row level lock and table level lock , But the default is row level locking );
Page lock : Cost and lock time are between table lock and row lock ; A deadlock occurs ; Lock granularity is between table lock and row lock , The concurrency is average .
apply : From the point of view of locks , Table-level locking is better suited for query-oriented locking , Only a small number of applications update data by index criteria , Such as Web application ; Row level lock is more suitable for a large number of concurrent updates of different data according to index conditions , At the same time, there are applications of concurrent queries , Like some online transactions (OLTP) System .
MyISAM Table locks
MyISAM There are two modes of table locking :
Table share read lock (Table Read Lock): Does not block other users' read requests for the same table , But it blocks write requests to the same table ;
Table Write Lock (Table Write Lock): Will block other users from reading and writing to the same table ;
MyISAM Between the read and write operations of a table , And write operations are serial . When a thread gets a write lock on a table , Only the thread holding the lock can update the table . Other threads read 、 Write operations will wait , Until the lock is released .
By default , Write lock has higher priority than read lock : When a lock is released , This lock will give priority to the acquisition lock request waiting in the write lock queue , Then give the acquisition lock request waiting in the read lock queue .
InnoDB Row lock
InnoDB Two types of Row lock :
Shared lock (S): Allow a transaction to read a line , Prevent other transactions from obtaining exclusive locks for the same dataset .
Exclusive lock (X): Allow to get transaction update data of exclusive lock , Prevent other transactions from obtaining the shared read lock and exclusive write lock of the same dataset .
To allow row locks and table locks to coexist , Implement multi granularity lock mechanism ,InnoDB There are also two internal intention locks (Intention Locks), Both of these intention locks are Table locks :
Intention sharing lock (IS): Transaction intends to add row sharing lock to data row , A transaction must obtain the table's IS lock .
Intention exclusive lock (IX): Transaction intends to add row exclusive lock to data row , A transaction must obtain the table's IX lock .
Index failure will cause row lock to change into table lock . such as vchar Query without single quotation marks .
Lock mechanism
Optimistic lock and pessimistic lock are two ideas of concurrency control , Can be used to resolve lost updates
Optimism will “ Optimistically ” Assume that there is no concurrent update conflict with high probability , visit 、 There is no lock in the process of processing data , Only when updating data, judge whether there is conflict according to version number or time stamp , If there is one, deal with , Commit transaction if none . With data version (Version) Record mechanism implementation , This is the most common implementation of optimistic locking
Pessimistic lock will “ Pessimistically ” Suppose there is a high probability of Concurrent update conflicts , visit 、 Add an exclusive lock before processing data , Lock the data in the whole data processing process , The lock is released after the transaction is committed or rolled back . In addition, the optimistic phase locking corresponds to , Pessimistic lock is implemented by the database itself , When it's time to use , We can directly call the relevant statements of the database .
The lock mode (InnoDB There are three algorithms for row locking )
Record locks (Record Locks): Locks on a single line record . Lock index entries , Lock qualified rows . Other transactions cannot modify or delete locked items ;
SELECT * FROM table WHERE id = 1 FOR UPDATE;It will be id=1 Add a record lock to your records , To prevent other transactions from inserting , to update , Delete id=1 This business
Through primary key And unique index Do... On data rows UPDATE In operation , Record lock will also be applied to this line of data :
-- id Column is the primary key column or unique index column UPDATE SET age = 50 WHERE id = 1;Clearance lock (Gap Locks): When we use the range condition instead of the equality condition to retrieve data , And request sharing or exclusive lock ,InnoDB It will lock the index entries of existing data records that meet the conditions . For records where the key value is in the condition range but does not exist , be called “ The gap ”.
InnoDB It's also about this “ The gap ” Lock , This kind of lock mechanism is called gap lock .
Between index items “ The gap ” Lock , Lock the range of records ( Lock the gap before the first record or the gap after the last record ), Does not contain the index entry itself . Other transactions cannot insert data within the scope of the lock , This prevents other transactions from adding phantom lines .
Gap locks are based on non unique indexes , It locks a range of index records . The clearance lock is based on
Next-Key LockingAlgorithm , Please remember : The gap lock is used to lock an interval , Not just every piece of data in this range .SELECT * FROM table WHERE id BETWEN 1 AND 10 FOR UPDATE;That is, all in
(1,10)All the record lines in the interval will be locked , all id by 2、3、4、5、6、7、8、9 The insertion of rows of data will be blocked , however 1 and 10 Two record lines are not locked .GAP Purpose of lock , To prevent two current reads of the same transaction , There is a situation of unreal reading
Temporary key lock (Next-key Locks): Temporary key lock , yes Record lock and clearance lock combination , Its blockade area , Include both index records , It also includes index range .( The main purpose of temporary key lock , It's also to avoid Fantasy reading (Phantom Read). If you downgrade the isolation level of a transaction to RC, Temporary key lock will also fail .)
Next-Key It can be understood as a special kind of Clearance lock , It can also be understood as a special Algorithm . adopt Temporary lock It can solve the problem of unreal reading . There is a temporary key lock on the non unique index column of each data row , When a transaction holds a temporary key lock for that row of data , It will lock the data of a section of left open and right closed sections . One thing to emphasize is ,
InnoDBRow level locking is based on index , A temporary key lock is only related to a non unique index column , In the unique index column ( Include primary key columns ) There is no temporary key lock on .For row queries , All of them adopt this method , The main purpose is to solve the problem of unreal reading .
*select for update What does it mean , Will lock table or row or other
for update Only applicable to InnoDB, And must be in the transaction block (BEGIN/COMMIT) In order to take effect . When doing transaction operations , adopt “for update” sentence ,MySQL An exclusive lock is added to each row of data in the query result set , Other threads will block the update and deletion of the record . Exclusive locks include row locks 、 Table locks .
InnoDB This row lock implementation feature means : Data is retrieved only through index conditions ,InnoDB To use row level locks , otherwise ,InnoDB Table locks will be used ! Suppose there's a form products , There are id Follow name Two fields ,id It's the primary key .
Explicitly specify the primary key , And there is this information ,row lock
SELECT * FROM products WHERE id='3' FOR UPDATE;
SELECT * FROM products WHERE id='3' and type=1 FOR UPDATE;
Explicitly specify the primary key , If there is no such information , nothing lock
SELECT * FROM products WHERE id='-1' FOR UPDATE;
No primary key ,table lock
SELECT * FROM products WHERE name='Mouse' FOR UPDATE;
The primary key is not clear ,table lock
SELECT * FROM products WHERE id<>'3' FOR UPDATE;
The primary key is not clear ,table lock
SELECT * FROM products WHERE id LIKE '3' FOR UPDATE;
notes 1: FOR UPDATE Only applicable to InnoDB, And it has to be in the trading block (BEGIN/COMMIT) In order to take effect . notes 2: To test the condition of the lock , You can use MySQL Of Command Mode , Open two windows to test .
*MySQL Have you ever had a deadlock problem , How did you solve ?
Deadlock
Deadlock occurs :
Deadlock means that two or more transactions occupy each other on the same resource , And request to lock the resources occupied by the other party , Which leads to a vicious circle
When a transaction attempts to lock resources in a different order , A deadlock may occur . When multiple transactions lock the same resource at the same time, deadlock may also occur
The behavior and order of locks are related to the storage engine . Execute statements in the same order , Some storage engines generate deadlocks and some don't —— There are two reasons for deadlock : Real data conflict ; How the storage engine is implemented .
Detection of deadlock : The database system implements various deadlock detection and deadlock timeout mechanisms .InnoDB The storage engine can detect the cyclic dependency of deadlock and return an error immediately .
Deadlock recovery : After deadlock , Only one of the transactions is partially or completely rolled back , To break the deadlock ,InnoDB The current way to deal with deadlocks is , Rollback the transaction with the least row level exclusive lock . So transactional applications must consider how to deal with deadlocks when they are designed , In most cases, only transactions rolled back due to deadlock need to be executed again .
Deadlock detection of external lock : After a deadlock occurs ,InnoDB Generally, it can automatically detect , And let a transaction release the lock and back , Another transaction gets a lock , Continue to complete the transaction . But when it comes to external locks , Or in the case of a watch lock ,InnoDB Deadlocks are not automatically detected , This needs to be done by setting the lock wait timeout parameter innodb_lock_wait_timeout To solve
Deadlocks affect performance : Deadlocks can affect performance rather than cause serious errors , because InnoDB Deadlock conditions are automatically detected and one of the affected transactions is rolled back . On high concurrency systems , When many threads wait for the same lock , Deadlock detection can slow down . Sometimes when a deadlock occurs , Disable deadlock detection ( Use innodb_deadlock_detect configuration option ) It might be more effective , You can rely on innodb_lock_wait_timeout Set transaction rollback .
MyISAM Avoid deadlock :
In the case of automatic locking ,MyISAM Always get SQL All the locks required by the statement , therefore MyISAM The watch will not deadlock .
InnoDB Avoid deadlock :
For in a single InnoDB Avoid deadlock when multiple concurrent write operations are performed on the table , You can do this at the beginning of a transaction by using the ( That's ok ) Use
SELECT ... FOR UPDATEStatement to get the necessary lock , Even if the change statements for these lines are executed later .In business , If you want to update records , You should directly apply for a lock of sufficient level , Just lock it , Instead of applying for a shared lock first 、 Apply for exclusive lock when updating , Because when the user applies for exclusive lock again , Another transaction may have acquired a shared lock on the same record , This causes lock conflicts , Even deadlock.
If the transaction needs to modify or lock multiple tables , Then lock statements should be used in the same order in each transaction . In the application , If different programs access multiple tables simultaneously , Try to agree to access tables in the same order , This can greatly reduce the chance of deadlock
adopt
SELECT ... LOCK IN SHARE MODEAfter obtaining the read lock of the line , If the current transaction needs to update the record again , It is likely to cause deadlock .Change transaction isolation level
If there is a deadlock , It can be used show engine innodb status; Command to determine the cause of the last deadlock . The return result includes details of deadlock related transactions , Such as causing deadlock SQL sentence , The lock that the transaction has acquired , Waiting for something to lock , And the transaction rolled back . According to this, we can analyze the cause of deadlock and improve measures .
8、 ... and 、MySQL tuning
*How do you optimize your daily work SQL Of ?
SQL What are the general steps of optimization , What about the execution plan (explain), How to understand the meaning of each field ?
How to write sql Can effectively use the composite index ?
One sql Execution takes too long , How do you optimize , From what aspects ?
What is the leftmost prefix principle ? What is the leftmost matching principle ?
influence mysql The performance factor of
Business needs to MySQL Influence ( Fit )
Storage positioning for MySQL Influence
System configuration and rule data
Basic information data of active users
Personalized information data of active users
Quasi real time statistical data
Other frequently accessed but less changed data
Binary multimedia data
Pipeline data
Big text data
It's not suitable for MySQL The data of
Data that needs to be put into the cache
Schema The impact of design on system performance
Minimize requests for database access
Minimize query requests for useless data
The influence of hardware environment on system performance
Performance analysis
MySQL Query Optimizer
MySQL Among them are those who are responsible for optimization SELECT Statement optimizer module , The main function : By calculating the statistics collected in the analysis system , Requested for client Query Provide the best execution plan he thinks ( He thinks the best way to retrieve data , But not necessarily DBA Think it's the best , This part is the most time consuming )
When the client MySQL Ask for one Query, The command parser module completes the request classification , The difference is SELECT And forward it to MySQL Query Optimize r when ,MySQL Query Optimizer First of all, the whole Query To optimize , Deal with the budget of some constant expressions , Convert directly to constant value . Also on Query Simplification and transformation of query conditions in , Such as removing some useless or obvious conditions 、 Structural adjustment, etc . Then analysis Query Medium Hint Information ( If there is ), Look at the display Hint Whether the information can completely determine the Query Implementation plan of . without Hint or Hint The information is not enough to fully determine the implementation plan , The statistics of the object involved will be read , according to Query Write the corresponding calculation and analysis , And then come up with the final execution plan .
MySQL Common bottlenecks
CPU:CPU When saturated, it usually occurs when data is loaded into memory or read from disk
IO: disk I/O The bottleneck occurs when the load data is much larger than the memory capacity
The performance bottleneck of server hardware :top,free,iostat and vmstat To see the performance status of the system
Performance degradation SQL slow Long execution time Long waiting time Cause analysis
The query statement is poorly written
Index failure ( Single value 、 Reunite with )
Too many associated queries join( Design defects or unavoidable requirements )
Server tuning and parameter settings ( buffer 、 Number of threads, etc )
MySQL Common performance analysis methods
Optimizing MySQL when , It is usually necessary to analyze the database , Common means of analysis are Slow query log ,EXPLAIN Analysis query ,profiling analysis as well as show Command to query system status and system variables , Analyze performance bottlenecks by positioning , In order to better optimize the performance of the database system .
Performance bottleneck positioning
We can go through show Command view MySQL States and variables , Find the bottleneck of the system :
Mysql> show status —— Display status information ( Expand show status like ‘XXX’)
Mysql> show variables —— Show system variables ( Expand show variables like ‘XXX’)
Mysql> show innodb status —— Show InnoDB The state of the storage engine
Mysql> show processlist —— View the current SQL perform , Including execution status 、 Lock the watch, etc
Shell> mysqladmin variables -u username -p password—— Show system variables
Shell> mysqladmin extended-status -u username -p password—— Display status information
Explain( Implementation plan )
What is it? : Use Explain Keyword can simulate optimizer execution SQL Query statement , So they know MySQL How to deal with you SQL Of the statement . Analyze the performance bottleneck of your query statement or table structure
Can you do it :
Read order of tables
Operation type of data read operation
Which indexes can be used
Which indexes are actually used
References between tables
How many rows per table are queried by the optimizer
How do you play? :
Explain + SQL sentence
Information contained in the implementation plan ( If there are partition tables, there will be partitions)

expalin
Explanation of each field
id(select The serial number of the query , Contains a set of numbers , Represents execution in a query select The order of clauses or operation tables )
id identical , The execution order is from top to bottom
id It's all different , If it's a subquery ,id The serial number of will increase ,id The higher the value, the higher the priority , The first to be executed
id Part of the same , The order of execution is to execute first according to the large number , Then the numbers are the same, in order from top to bottom
select_type( Query type , Used to distinguish ordinary queries 、 The joint query 、 Complex queries such as subqueries )
SIMPLE : ordinary select Inquire about , The query does not contain subqueries or UNION
PRIMARY: If the query contains any complex sub parts , The outermost query is marked as PRIMARY
SUBQUERY: stay select or where The list contains subqueries
DERIVED: stay from The subqueries contained in the list are marked with DERIVED,MySQL These subqueries will be executed recursively , Put the results on the provisional list
UNION: If the second select Appear in the UNION after , Is marked as UNION, if UNION Included in from Clause , Outer layer select Will be marked as DERIVED
UNION RESULT: from UNION Table to get the result select
table( Show which table this row's data is about )
type( Show which type the query uses , From the best to the worst system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL )
tip: Generally speaking , Make sure that the query is at least range Level , Better get to ref
system: There is only one line in the table ( It's equal to the system table ), yes const Special case of type , Not usually
const: Indicates that it is found through index once ,const For comparison primary key or unique Indexes , Because only one row of data is matched , So soon , For example, place the primary key in where In the list ,mysql You can convert the query to a constant
eq_ref: Unique index scan , For each index key , Only one record in the table matches it , Common in primary key or unique index scan
ref: Non unique index scan , Scope matches a single value to all lines . In essence, it is also an index access , He returns all the rows that match a single value , However , It may also find multiple rows that match the criteria , It should be a mixture of search and scan
range: Retrieve only rows in the given range , Use an index to select rows .key Column shows which index is used , It's usually in your where In the sentence between、<、>、in And so on , This range scan index is better than full table scan , Because it only needs to start at a certain point in the index , And end at another point , Don't scan all indexes
index:Full Index Scan,index On ALL The difference for index Type only traverses the index tree . Often than ALL fast , Because index files are usually smaller than data files .( That is to say, although all and index Read the whole watch , but index It's read from the index , and all It's read from the hard disk )
ALL:Full Table Scan, Will traverse the entire table to find the matching row
possible_keys( Show the indexes that may be applied to this table , One or more , If there is an index in the field involved in the query , Then the index will be listed , But it doesn't have to be actually used by the query )
key
Actual index used , If NULL, No index is used
If an overlay index is used in the query , Then the index and query select Fields overlap , Only in key In the list

explain-key
key_len
Represents the number of bytes used in the index , You can use this column to calculate the length of the index used in the query . Without losing accuracy , The shorter the length, the better
key_len The displayed value is the maximum possible length of the index field , It's not the actual length , namely key_len It is calculated according to the table definition , It is not retrieved from the table
ref( Shows which column of the index is used , If possible , It's a constant . Which columns or constants are used to find values on index columns )
rows( According to table statistics and index selection , Roughly estimate the number of rows to read to find the required record )
Extra( Contains additional information that is not suitable for display in other columns but is important )
using filesort: explain mysql Will use an external index to sort the data , It is not read in the order of the index in the table .mysql The sort operations that can't be done with indexes in are called “ File sorting ”. Common in order by and group by In the sentence
Using temporary: Temporary tables are used to save intermediate results ,mysql Use temporary tables when sorting query results . It is common in sorting order by And group queries group by.
using index: It means corresponding select The override index is used in the operation , Avoid accessing the data rows of the table , Good efficiency , If it appears at the same time using where, Indicates that the index is used to perform index key value lookups ; Otherwise, the index is used to read data instead of performing lookup operations
using where: Used where Filter
using join buffer: Connection caching is used
impossible where:where The value of the clause is always false, It can't be used to obtain any ancestor
select tables optimized away: In the absence of group by In the case of clause , Index based optimization operations or for MyISAM Storage engine optimization COUNT(*) operation , You don't have to wait until the execution phase to do the calculation , The query execution plan generation phase completes the optimization
distinct: Optimize distinct operation , After finding the first matching ancestor, stop looking for the same value
case:

explain-demo
first line ( Execution order 4):id As a 1, Said is union The first one in select,select_type Column primary Indicates that the query is an outer query ,table The column is marked , Indicates that the query results are from a derived table , among derived3 in 3 Represents that the query is derived from the third select Inquire about , namely id by 3 Of select.【select d1.name......】
The second line ( Execution order 2):id by 3, It's the third in the whole query select Part of . Because the query is contained in from in , So for derived.【select id,name from t1 where other_column=''】
The third line ( Execution order 3):select Subqueries in the list select_type by subquery, For the second of the entire query select.【select id from t3】
In the fourth row ( Execution order 1):select_type by union, Explain the fourth select yes union The second one in select, The first to perform 【select name,id from t2】
The fifth row ( Execution order 5): For from union The stage of reading rows in the temporary table of ,table Column <union1,4> The first and the fourth select The result of union operation .【 Two results union operation 】
Slow query log
MySQL The slow query log of is MySQL A type of logging provided , It is used to record in MySQL Statement whose response time exceeds the threshold , Specifically, the running time exceeds long_query_time It's worth it SQL, It will be recorded in the slow query log .
long_query_timeThe default value is 10, It means running 10 Seconds or moreBy default ,MySQL Slow query log is not enabled in the database , You need to set parameters manually to turn on
Check the on Status
SHOW VARIABLES LIKE '%slow_query_log%'
Open slow query log
Temporary configuration :
mysql> set global slow_query_log='ON';
mysql> set global slow_query_log_file='/var/lib/mysql/hostname-slow.log';
mysql> set global long_query_time=2;
Can also be set file location , The system will default to a default file host_name-slow.log
Use set The slow query log is only valid for the current database , If MySQL Restart will fail .
Permanent configuration
Modify the configuration file my.cnf or my.ini, stay [mysqld] Add two configuration parameters below the line
[mysqld]
slow_query_log = ON
slow_query_log_file = /var/lib/mysql/hostname-slow.log
long_query_time = 3
notes :log-slow-queries The parameter is the location where the slow query log is stored , Generally, this directory should have MySQL The writable permission of the running account , This directory is usually set to MySQL Data storage directory ;long_query_time=2 Medium 2 Indicates that the query is logged for more than two seconds ; stay my.cnf perhaps my.ini Add log-queries-not-using-indexes Parameters , Indicates that the query without index is recorded .
It can be used select sleep(4) Verify that it is turned on successfully .
In the production environment , If you analyze the log manually , lookup 、 analysis SQL, It's still a lot of work , therefore MySQL Provides log analysis tools mysqldumpslow.
adopt mysqldumpslow --help View the operation help information
Get the most returned recordset 10 individual SQL
mysqldumpslow -s r -t 10 /var/lib/mysql/hostname-slow.logThe most visited 10 individual SQL
mysqldumpslow -s c -t 10 /var/lib/mysql/hostname-slow.logGet the top... In chronological order 10 There are left connected query statements in the bar
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/hostname-slow.logIt can also be used with pipes
mysqldumpslow -s r -t 10 /var/lib/mysql/hostname-slow.log | more
You can also use pt-query-digest analysis RDS MySQL Slow query log
Show Profile Analysis query
What can be known through slow log query SQL Statement execution is inefficient , adopt explain We can see SQL The specific execution of the statement , Index usage, etc , It can also be combined with Show Profile Command view execution status .
Show Profile yes MySQL Provides resource consumption that can be used to analyze statement execution in the current session . It can be used for SQL The measurement of tuning
By default , Parameter is off , And save the latest 15 The result of the run
Analysis steps
mysql> show profiles; +----------+------------+---------------------------------+ | Query_ID | Duration | Query | +----------+------------+---------------------------------+ | 1 | 0.00385450 | show variables like "profiling" | | 2 | 0.00170050 | show variables like "profiling" | | 3 | 0.00038025 | select * from t_base_user | +----------+------------+---------------------------------+
converting HEAP to MyISAM Query result is too large , There's not enough memory. I moved it to disk .
create tmp table Create a temporary table , This is something to watch out for
Copying to tmp table on disk Copy the memory temporary table to disk
locked
The diagnosis SQL,show profile cpu,block io for query id( The previous question SQL Number )
Conclusions that need attention in daily development
Do you support , Look at the current mysql Does the version support
mysql>Show variables like 'profiling'; -- The default is off , It needs to be turned on before useTurn on the function , The default is off , It needs to be turned on before use
mysql>set profiling=1;function SQL
View results
*Which cases in the query will not use index ?
performance optimization
Index optimization
Full value matching my favorite
The best left prefix rule , For example, establishing a joint index (a,b,c), In fact, the indexes we can use are (a), (a,b), (a,b,c)
Do nothing on the index column ( Calculation 、 function 、( Automatically or Manual ) Type conversion ), It will cause index invalidation and turn to full table scan
The storage engine cannot use the column to the right of the range condition in the index
Try to use overlay index ( Queries that only access the index ( The index column is consistent with the query column )), Reduce select
is null ,is not null You can't use indexes
like "xxxx%" Index can be used ,like "%xxxx" No way. (like "%xxx%" Empathy ).like Start with a wildcard ('%abc...') Index invalidation will become a full table scan operation ,
String index is invalid without single quotation marks
To use less or, Using it to connect will invalidate the index
<,<=,=,>,>=,BETWEEN,IN Available to index ,<>,not in ,!= No way. , Causes a full table scan
General advice
For single key indexes , Try to choose the current query Better filtering index
When choosing a composite index , At present Query The most filterable field in the index field order , The higher the position, the better .
When choosing a composite index , Try to include the current query Medium where Index of more fields in a sentence
By analyzing statistics and adjusting as much as possible query To achieve the purpose of selecting the appropriate index
To use less Hint Force index
Query optimization
Always small label drives big watch ( Small data sets drive large data sets )
slect * from A where id in (select id from B)` Equivalent to
# Equivalent to
select id from B
select * from A where A.id=B.id
When B The data set of the table must be less than A When the data set of the table , use in be better than exists
select * from A where exists (select 1 from B where B.id=A.id)
# Equivalent to
select * from A
select * from B where B.id = A.id`
When A The data set of the table is less than B When the data set of the table , use exists It's better than using in
Be careful :A Table and B Tabular ID Fields should be indexed .
order by Keyword optimization
order by Clause , Use as much as possible Index Sort by , Avoid using FileSort Sort by
MySQL Support two ways of sorting ,FileSort and Index,Index Efficient , It means MySQL Scan index itself to complete sorting ,FileSort Low efficiency ;
ORDER BY There are two cases , Will use Index Sort by ;①ORDER BY The statement uses the left most front of the index ② Use where Clause and ORDER BY Clause condition column combination satisfies the left most front of index
Sort as much as possible on the index columns , The best prefix built according to the index
If not on the index column ,filesort There are two algorithms ,mysql We need to start two-way sorting and one-way sorting
Two way sorting :MySQL 4.1 It used to be two-way sorting , Literally, two scans of the disk , And finally get the data
One way sorting : Read all the columns needed for the query from disk , according to order by Listed in buffer Sort them out , Then scan the sorted list for output , Efficiency is higher than two-way sorting
Optimization strategy
increase sort_buffer_size Parameter settings
increase max_lencth_for_sort_data Parameter settings
GROUP BY Keyword optimization
group by The essence is sorting first and then grouping , Follow the best left prefix created by the index
When index columns cannot be used , increase
max_length_for_sort_dataParameter settings , increasesort_buffer_sizeParameter settingswhere higher than having, It can be written in where Don't go to... Under certain conditions having Limit the
Data type optimization
MySQL Many data types are supported , Choosing the right data type is crucial for high performance . No matter what type of data is stored , Here are a few simple principles to help you make a better choice .
Smaller ones are usually better : In general , Try to use the smallest data type that can store data correctly .
Simple is good : Simple data types usually require less CPU cycle . for example , Integer operations cost less than character operations , Because of the character set and proofreading rules ( Sort rule ) Make character comparison more complex than integer .
Try to avoid NULL: In general, it's best to specify NOT NULL
Nine 、 Partition 、 table 、 sub-treasury
MySQL Partition
In general, the tables we create correspond to a set of storage files , Use MyISAM Storage engine is a .MYI and .MYD file , Use Innodb Storage engine is a .ibd and .frm( Table structure ) file .
When the amount of data is large ( More than ten million records in general ),MySQL Will start to degrade , At this point, we need to distribute the data to multiple groups of storage files , Ensure the execution efficiency of its single file
What can I do?
Logical data segmentation
Speed up single write and read applications
Improve the speed of partition range read query
Split data can have multiple physical file paths
Efficient preservation of historical data
How do you play?
First, check whether the current database supports partitioning
MySQL5.6 And previous versions :
SHOW VARIABLES LIKE '%partition%';MySQL5.6:
show plugins;
Partition type and operation
RANGE Partition : Based on the column value belonging to a given continuous interval , Assign multiple rows to partitions .mysql According to the specified split policy ,, Put the data on different table files . It's equivalent to... On the file , It's broken into small pieces . however , It's still a table to the customer , Transparent .
according to range Come to share , It's a continuous piece of data in each database , This is usually done as follows Time range To the , Like the deal list , Sales watch, etc , Data can be stored according to the month and year . There may be hot issues , A lot of traffic is on the latest data .
range Come to share , The advantage is to say , The expansion is very simple .
LIST Partition : It's like pressing RANGE Partition , Each partition must be clearly defined . The main difference between them is ,LIST The definition and selection of each partition in a partition is based on the value of a column belonging to a value in a value list set , and RANGE A partition is a set of values belonging to a continuous interval .
HASH Partition : Partition selection based on the return value of user-defined expression , The expression evaluates with the column values of the rows to be inserted into the table . This function can contain MySQL Effective in 、 Any expression that produces a nonnegative integer value .
hash distribution , The advantage is to say , The amount of data and request pressure for each library can be equally distributed ; The disadvantage is that expansion is more troublesome , There will be a data migration process , Previous data need to be recalculated hash Values are reallocated to different libraries or tables
KEY Partition : It's like pressing HASH Partition , The difference lies in KEY Partition only supports one or more columns to be calculated , And MySQL The server provides its own hash function . One or more columns must contain integer values .
It looks like the partition table is very handsome , Why do most of the Internet choose their own sub database and sub table to expand horizontally ?
Partition table , Partition key design is not very flexible , If you don't use the partition key , It's easy to have a full watch lock
Once the amount of data concurrency comes up , If the association is implemented in the partition table , It's a disaster
Own sub warehouse and sub table , Own business scenarios and access patterns , controllable . Partition table , R & D wrote a sql, Not sure mysql How did it work , Not very controllable
*As the business grows , Business is getting more and more complex , More and more modules are applied , The total amount of data is very large , High concurrent read and write operations exceed the processing capacity of a single database server ?
That's when Data fragmentation , Data fragmentation refers to storing data in a single database in multiple databases or tables according to a certain dimension . The effective method of data fragmentation is to divide relational database into database and table .
What's different from zoning is , Partition is usually placed in a single machine , Most of them use time range partition , Easy to file . It's just that sub database and sub table need code implementation , The partition is mysql Internal implementation . There is no conflict between sub database and sub table and partition , Can be used in combination .
*Talk about the design of sub database and sub table
MySQL table
There are two ways to divide a sub table , A vertical split , Another horizontal split .
Split Vertically
Vertical sub table , Usually according to the usage frequency of business functions , Put the main 、 The hot fields are put together as the main table . And then put the less commonly used , Aggregate according to their business attributes , Split into different secondary tables ; The relationship between the primary table and the secondary table is generally one-to-one .
Horizontal split ( Data fragmentation )
The capacity of a single meter does not exceed 500W, Otherwise, horizontal splitting is recommended . Copy a table into different tables of the same table structure , Then divide the data according to certain rules , Store them separately in these tables , So as to ensure that the capacity of a single meter will not be too large , Lifting performance ; Of course, these tables have the same structure , Can be placed in one or more databases .
Several methods of horizontal segmentation :
Use MD5 Hash , The approach is to UID Conduct md5 encryption , Then take the first few ( Let's take the top two ), Then you can put different UID Hash to different user tables (user_xx) It's in .
You can also put different tables according to the time , such as :article_201601,article_201602.
Split by heat , High click rate entries generate their own tables , Low heat entries are all in one big table , After the low popularity entries reach a certain number of Posts , Then split the low heat form into a single table .
according to ID In the corresponding table , The first table user_0000, the second 100 Ten thousand user data in the second Tables user_0001 in , As the number of users increases , Just add the user table .

MySQL sub-treasury
*Why do you want to divide the library ?
There are multiple databases in the cluster environment slave, Basically meet the read operation ; But writing or big data 、 Frequent write operations on master The performance impact is relatively large , This is the time , Single library can't solve the problem of large-scale concurrent writing , So we will consider the sub Treasury .
*What is the sub treasury ?
There are too many tables in a library , It leads to massive data , System performance degradation , Split the tables originally stored in one library and store them in multiple libraries , It is usually according to the function module 、 The degree of intimacy is divided into , Deploy to different libraries .
advantage :
Reduce the impact of locks on queries when incremental data is written
Due to the decrease in the number of single tables , Common query operations reduce the number of records that need to be scanned , Make the number of retrieval lines required for single form query less , Reduced disk IO, Shorter time delay
But it can't solve the problem of too much data in a single table
The problem after dividing database and table
The problem with distributed transactions , Data integrity and consistency issues .
Data operation dimension problem : user 、 transaction 、 Different dimensions of orders , User query dimension 、 Different comparative analysis perspectives of product data analysis dimensions . The problem of cross database joint query , It may take two queries Cross node count、order by、group by And aggregate function problems , You may need to get the results on each node and merge them on the application side Additional data management burden , Such as : Navigation to access data tables Extra data computing pressure , Such as : It needs to be performed on multiple nodes , And then merge the program coding development difficulty , There is no good framework to solve , Rely more on business to see how to divide , How to combine , It's a problem .
*Master and slave , Seriously, the company , I won't let Javaer To do it , But it's still important to know
Ten 、 Master slave copy
The fundamentals of replication
slave From master Read binlog To synchronize data
Three steps

img
master Log changes to binary log (binary log). These logging processes are called binary log events ,binary log events;
salve take master Of binary log events Copy to its trunk log (relay log);
slave Redo events in relay log , Apply the changes to your own database .MySQL Replication is asynchronous and serialized .

The basic principle of reproduction
Every slave only one master
Every salve There can only be one unique server ID
Every master There can be multiple salve
The biggest problem with copying
Time delay
11、 ... and 、 Other questions
Let's talk about three paradigms
First normal form (1NF): The fields in the database table are all single property , Can not be further divided . This single property consists of basic types , Including the integer 、 The set of real Numbers 、 Character 、 The logical model 、 Date type, etc .
Second normal form (2NF): There is no partial functional dependence of non key fields on any candidate key fields in the database table ( Partial function dependency refers to the situation that some fields in the combined keyword determine non key fields ), That is, all non key fields are completely dependent on any set of candidate keywords .
Third normal form (3NF): On the basis of the second paradigm , If there is no transfer function dependence of non key fields on any candidate key fields in the data table, it conforms to the third normal form . So called transfer function dependency , It means such as Fruiting "A → B → C" The decisive relationship of , be C The transfer function depends on A. therefore , Database tables that satisfy the third paradigm should not have the following dependencies : Key fields → Non critical fields x → Non critical fields y
How to delete data of million level or above
About index : Because index needs extra maintenance cost , Because the index file is a separate file , So when we add data , modify , Delete , There will be additional operations on the index file , These operations need to consume extra IO, It will decrease and increase / Change / The efficiency of deletion . therefore , When we delete the million level database data , Inquire about MySQL The official manual knows that the speed of deleting data is proportional to the number of indexes created .
So when we want to delete millions of data, we can delete the index first ( It will take more than three minutes )
Then delete the useless data ( This process takes less than two minutes )
Recreate index after deletion ( There's less data at this point ) Indexing is also very fast , About ten minutes .
With the previous direct delete is definitely much faster , Let alone in case the deletion is interrupted , All delete will roll back . That's more of a pit .
Summed up a lot about java Interview materials , I hope I can help you learn java Little buddy . Due to too much information, it is inconvenient to publish articles , It's not easy to create , I hope my friends can give me some motivation to continue to create better java Class learning material articles ,
Please support and pay more attention to the small work , Don't forget to like + Comment on + forward . I reply to the private message in the upper right corner 【03】 You can get free learning materials. Thank you !

边栏推荐
- 记录:动态Web项目servlet访问数据库404错误之解决
- MySQL shutdown is slow
- Record: solution of 404 error of servlet accessing database in dynamic web project
- 阿里云微服务(三)Sentinel开源流控熔断降级组件
- Record: I accidentally wrote a recursion next time
- [算法] 剑指offer2 golang 面试题9:乘积小于k的子数组
- Implementation of Excel import and export functions
- Affichage du changement de valeur du Buff de gain de l'interface graphique de défaillance
- Combination of fairygui check box and progress bar
- FairyGUI增益BUFF数值改变的显示
猜你喜欢

面渣逆袭:Redis连环五十二问,三万字+八十图详解。
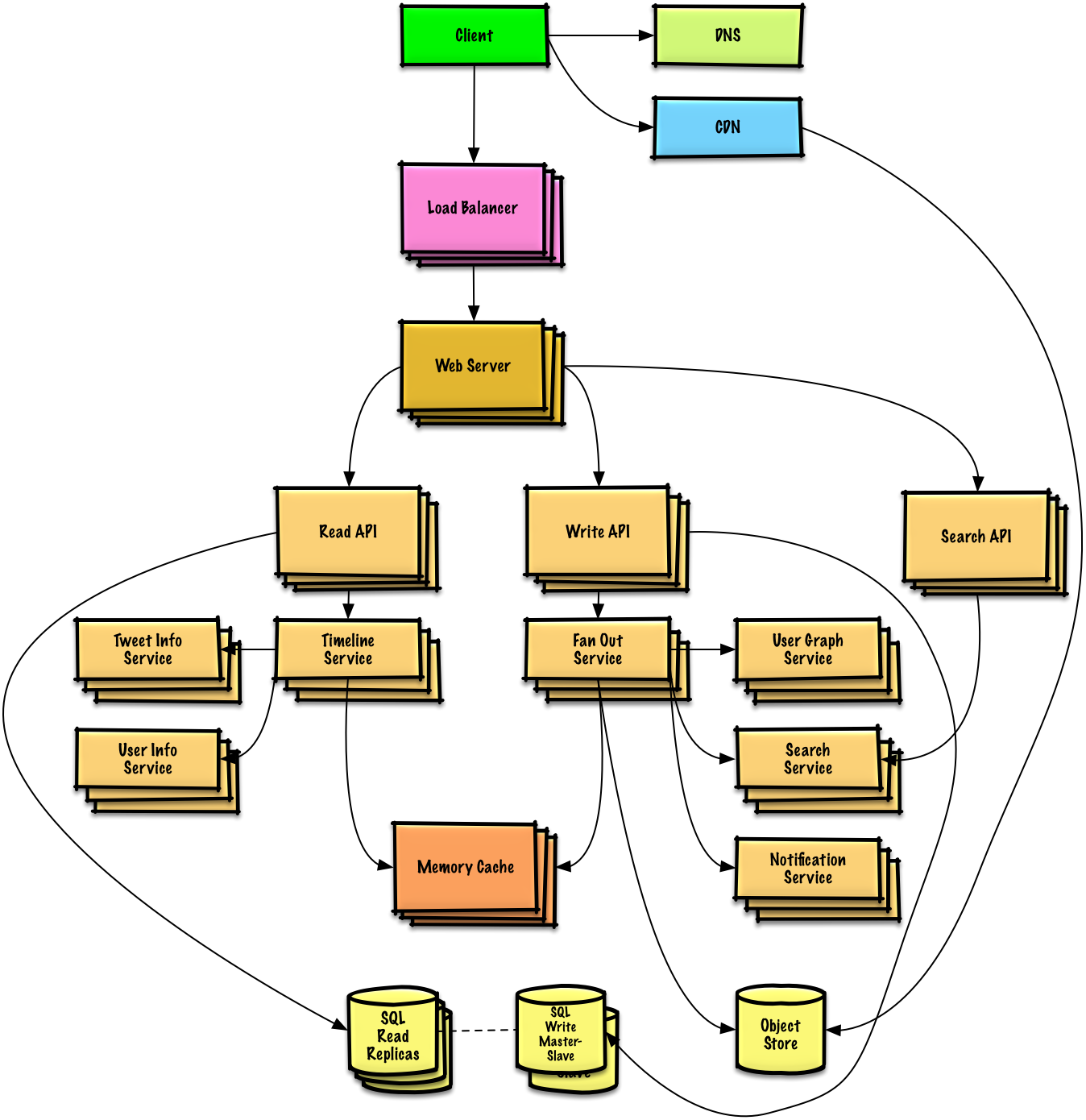
系统设计学习(一)Design Pastebin.com (or Bit.ly)
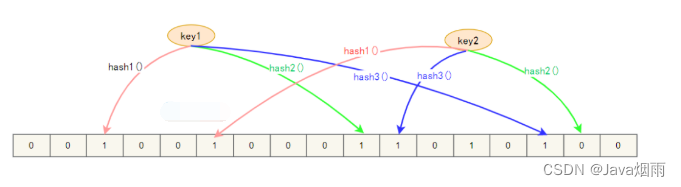
Ten minutes to thoroughly master cache breakdown, cache penetration, cache avalanche
![[dry goods] cycle slip detection of suggestions to improve the fixed rate of RTK ambiguity](/img/9d/7284c1399964d3fb48886f12e4941c.jpg)
[dry goods] cycle slip detection of suggestions to improve the fixed rate of RTK ambiguity

Mixed use of fairygui button dynamics
Matlab读取GNSS 观测值o文件代码示例
Basic DOS commands
![[算法] 剑指offer2 golang 面试题3:前n个数字二进制形式中1的个数](/img/64/0f352232359c7d44f12b20a64c7bb4.png)
[算法] 剑指offer2 golang 面试题3:前n个数字二进制形式中1的个数
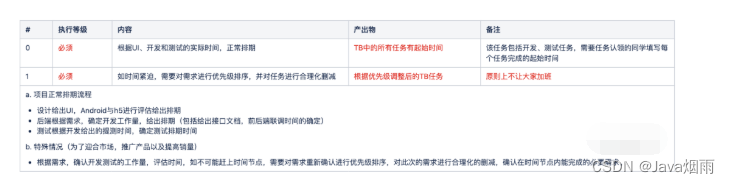
2年经验总结,告诉你如何做好项目管理
Answer to "software testing" exercise: Chapter 1
随机推荐
MySQL shutdown is slow
341. Flatten nested list iterator
【GNSS】抗差估计(稳健估计)原理及程序实现
The earth revolves around the sun
[GNSS] robust estimation (robust estimation) principle and program implementation
[Chongqing Guangdong education] reference materials for regional analysis and planning of Pingdingshan University
[算法] 剑指offer2 golang 面试题6:排序数组中的两个数字之和
Mysql database reports an error: row size too large (> 8126) Changing some columns to TEXT or BLOB or using ROW_ FORMAT=DY
Excel导入,导出功能实现
Code example of MATLAB reading GNSS observation value o file
系统设计学习(二)Design a key-value cache to save the results of the most recent web server queries
FairyGUI循环列表
[算法] 剑指offer2 golang 面试题8:和大于或等于k的最短子数组
KF UD分解之伪代码实现进阶篇【2】
GNSS定位精度指标计算
[算法] 剑指offer2 golang 面试题2:二进制加法
Exception: ioexception:stream closed
The service robots that have been hyped by capital and the Winter Olympics are not just a flash in the pan
121道分布式面试题和答案
阿里云一面:并发场景下的底层细节 - 伪共享问题