当前位置:网站首页>Design a key value cache to save the results of the most recent Web server queries
Design a key value cache to save the results of the most recent Web server queries
2022-07-06 13:08:00 【Geometer】
The old rule is to look at the question first
Use cases We’ll scope the problem to handle only the following use cases
User sends a search request resulting in a cache hit
User sends a search request resulting in a cache miss
Service has high availability Constraints and assumptions
State assumptions Traffic is not evenly distributed
Popular queries should almost always be in the cache
Need to determine how to expire/refresh Serving from cache requires fast lookups
Low latency between machines Limited memory in cache
Need to determine what to keep/remove
Need to cache millions of queries 10 million users 10 billion queries per month
Calculation :
The ordered lists of cached keys are query, value: results
query - 50 bytes
title - 20 bytes
snippet - 200 bytes
Total: 270 bytes
That is to say, a single cache probably needs 270bytes
If 10 billion Every data of our users is unique
It can be calculated that the storage consumption of a month is 2.7t
4000 requests per second = 01 billion requests per month
That is, about 4000 requests per second, on average
Create a high level design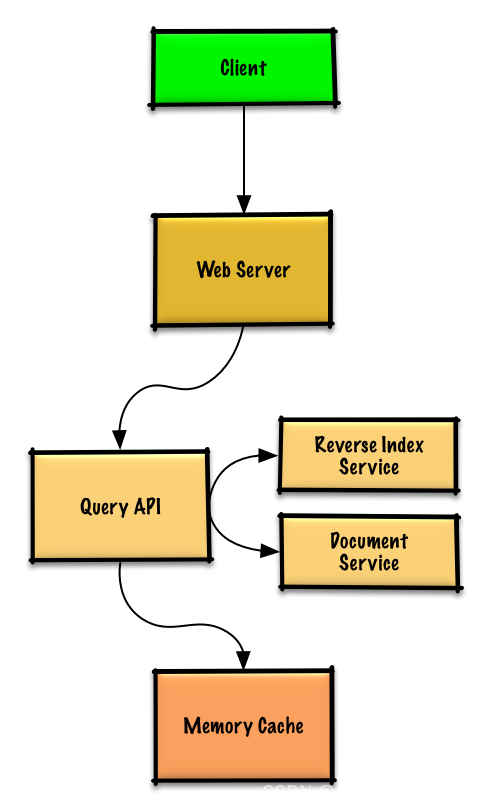
Because the capacity of cache is limited , So we need to set an expiration policy , Here we can use LRU Mechanism
The specific design is as follows :
1.client Send a request to webserver, Run the reverse proxy
2.webserver Execute the query api
3. Inquire about api Will perform the following operations
1) Analytic grammar :
Delete tag
Break the text down into terms
Fix spelling mistakes
Normalized capitalization
Convert queries to use Boolean operations
2) Check whether the cache is hit :
If hit :
utilize LRU Mechanism update cache
Return cached content
If you don't hit :
Use Reverse Index Service Find matching documents , Rank the documents found by using matching pairs , The highest ranking document is the document to be found
Use Document Service return titles and snippets
Update the contents of the cache , to update LRU
About LRU The implementation of is actually a good design , Yes, it is hash+ The structural design of the linked list can make the time complexity of its insertion and search constant ,lc There is a related algorithm problem , If you forget, you can have a look , This question Java It's faster to write ,cpp Write all the basic operations by yourself hhh
https://leetcode.cn/problems/lru-cache/
Inquire about api The implementation of the :
class QueryApi(object):
def __init__(self, memory_cache, reverse_index_service):
self.memory_cache = memory_cache
self.reverse_index_service = reverse_index_service
def parse_query(self, query):
"""Remove markup, break text into terms, deal with typos, normalize capitalization, convert to use boolean operations. """
...
def process_query(self, query):
query = self.parse_query(query)
results = self.memory_cache.get(query)
if results is None:
results = self.reverse_index_service.process_search(query)
self.memory_cache.set(query, results)
return results
Implementation of nodes :
class Node(object):
def __init__(self, query, results):
self.query = query
self.results = results
The realization of linked list :
class LinkedList(object):
def __init__(self):
self.head = None
self.tail = None
def move_to_front(self, node):
...
def append_to_front(self, node):
...
def remove_from_tail(self):
...
Cache implementation :
class Cache(object):
def __init__(self, MAX_SIZE):
self.MAX_SIZE = MAX_SIZE
self.size = 0
self.lookup = {
} # key: query, value: node
self.linked_list = LinkedList()
def get(self, query)
"""Get the stored query result from the cache. Accessing a node updates its position to the front of the LRU list. """
node = self.lookup[query]
if node is None:
return None
self.linked_list.move_to_front(node)
return node.results
def set(self, results, query):
"""Set the result for the given query key in the cache. When updating an entry, updates its position to the front of the LRU list. If the entry is new and the cache is at capacity, removes the oldest entry before the new entry is added. """
node = self.lookup[query]
if node is not None:
# Key exists in cache, update the value
node.results = results
self.linked_list.move_to_front(node)
else:
# Key does not exist in cache
if self.size == self.MAX_SIZE:
# Remove the oldest entry from the linked list and lookup
self.lookup.pop(self.linked_list.tail.query, None)
self.linked_list.remove_from_tail()
else:
self.size += 1
# Add the new key and value
new_node = Node(query, results)
self.linked_list.append_to_front(new_node)
self.lookup[query] = new_node
Cache finer conditions :
Page content changes
Delete a page or add a new page
Page ranking changes
The most direct way to solve these problems is to set a maximum time
Thank you very much for reading to the end , Thank you for your support . Interested students can see this post of mine
System design study ( One )Design Pastebin.com (or Bit.ly)
边栏推荐
- 162. Find peak - binary search
- [algorithm] sword finger offer2 golang interview question 5: maximum product of word length
- Record: Navicat premium can't connect to MySQL for the first time
- 图书管理系统小练习
- 服务未正常关闭导致端口被占用
- 2年经验总结,告诉你如何做好项目管理
- Answer to "software testing" exercise: Chapter 1
- 记录:Navicat Premium初次无法连接数据库MySQL之解决
- 记录:下一不小心写了个递归
- 121道分布式面试题和答案
猜你喜欢
![[算法] 剑指offer2 golang 面试题8:和大于或等于k的最短子数组](/img/8c/1b6ba3b1830ad28176190170c98628.png)
![[algorithm] sword finger offer2 golang interview question 10: subarray with sum K](/img/63/7422489d09a64ec9f0e79378761bf1.png)

随机推荐
Introduction pointer notes
Fairygui bar subfamily (scroll bar, slider, progress bar)
[算法] 剑指offer2 golang 面试题6:排序数组中的两个数字之和
Problems and solutions of robust estimation in rtklib single point location spp
Realization of the code for calculating the mean square error of GPS Height Fitting
[algorithm] sword finger offer2 golang interview question 8: the shortest subarray with a sum greater than or equal to K
C code implementation of robust estimation in rtklib's pntpos function (standard single point positioning spp)
MYSQL索引钟B-TREE ,B+TREE ,HASH索引之间的区别和应用场景
[algorithm] sword finger offer2 golang interview question 2: binary addition
XV Function definition and call
Record: Navicat premium can't connect to MySQL for the first time
初识C语言(下)
[untitled]
How do architects draw system architecture blueprints?
分支语句和循环语句
Excel导入,导出功能实现
Code example of MATLAB reading GNSS observation value o file
One article to get UDP and TCP high-frequency interview questions!
Experience summary of autumn recruitment of state-owned enterprises
[algorithme] swordfinger offer2 golang question d'entrevue 2: addition binaire