当前位置:网站首页>JVM 内存布局详解,图文并茂,写得太好了!
JVM 内存布局详解,图文并茂,写得太好了!
2022-07-04 12:48:00 【Java知音_】
点击关注公众号,实用技术文章及时了解
来源:cnblogs.com/hyxiao97/p/15395886.html
今年行情差,面试也卷,面试官喜欢上来就问JVM,来分享一篇JVM干货
内存布局
Heap 堆区
Metaspace 元空间
JVM Stacks 虚拟机栈
Native Method Stacks(本地方法栈)
Program Counter Register (程序计数寄存器)
小结
内存布局
JVM内存布局规定了Java在运行过程中内存申请、分配、管理的策略,保证了JVM的稳定高效运行。不同的JVM对于内存的划分方式和管理机制存在部分差异。结合JVM虚拟机规范,一起来探讨jVM的内存布局。如下图所示:
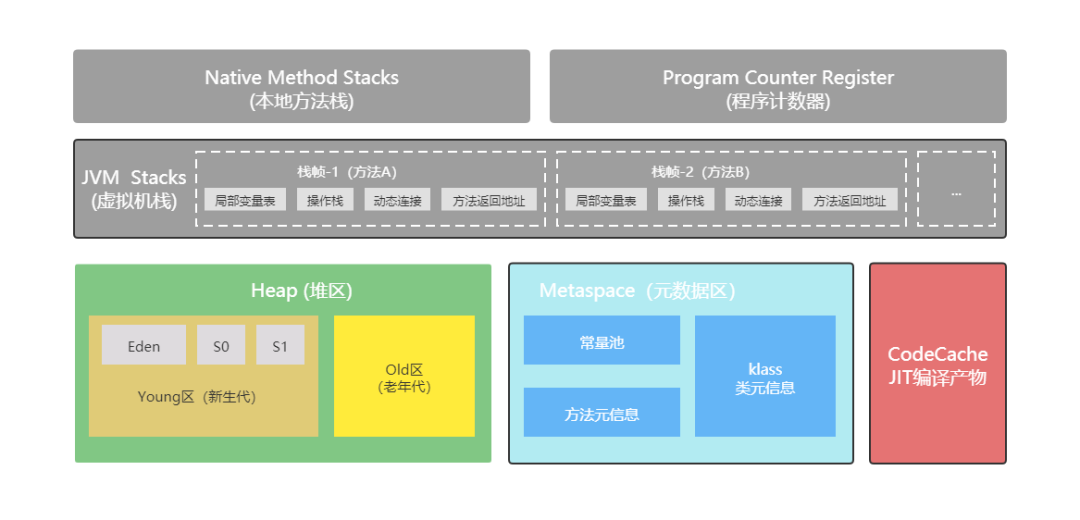
Heap 堆区
Heap堆区是Java发生OOM(Out Of Memory)故障的地方,堆中存储着我们平时创建的实例对象,最终这些不再使用的对象会被垃圾收集器回收掉,而且堆是线程共享的。一般情况下,堆所占用的内存空间是JVM内存区域中最大的,我们在平时编码中,创建对象如果不加以克制,内存空间也会被耗尽。
堆的内存空间是可以自定义大小的,同时也支持在运行时动态修改,通过 -Xms 、-Xmx 这两参数去改变堆的初始值和最大值。-X指的是JVM运行参数,ms 是memory start的简称,代表的是最小堆容量,mx是memory max的简称,代表的是最大堆容量;如 -Xms256M代表堆的初始值是256M,-Xmx1024M代表堆的最大值是1024M。
由于堆的内存空间是可以动态调整的,所以在服务器运行的时候,请求流量的不确定性可能会导致我们堆的内存空间不断调整,会增加服务器的压力,所以我们一般都会将JVM的Xms和Xmx的值设置成一样,同样也为了避免在GC(垃圾回收)之后调整堆大小时带来的额外压力。
堆区分为两大区:Young区和Old区,又称新生代和老年代。对象刚创建的时候,会被创建在新生代,到一定阶段之后会移送至老年代 ,如果创建了一个新生代无法容纳的新对象,那么这个新对象也可以创建到老年代。如上图所示。
新生代分为1个Eden区和2个S区,S代表Survivor。大部分的对象会在Eden区中生成,当Eden区没有足够的空间容纳新对象时,会触发Young Garbage Collection,即YGC。在Eden区进行垃圾清除时,它的策略是会把没有引用的对象直接给回收掉,还有引用的对象会被移送到Survivor区。
Survivor区有S0和S1两个内存空间,每次进行YGC的时候,会将存活的对象复制到未使用的那块内存空间,然后将当前正在使用的空间完全清除掉,再交换两个空间的使用状况。如果YGC要移送的对象Survivor区无法容纳,那么就会将该对象直接移交给老年代。
上面说了,到一定阶段的对象会移送到老年区,这是什么意思呢?每一个对象都有一个计数器,当每次进行YGC的时候,都会 +1。通过-XX:MAXTenuringThrehold参数可以配置当计数器的值到达某个阈值时,对象就会从新生代移送至老年代。
该参数的默认值为15,也就是说对象在Survivor区中的S0和S1内存空间交换的次数累加到15次之后,就会移送至老年代。如果参数配置为1,那么创建的对象就会直接移送至老年代。具体的对象分配即回收流程可观看下图所示。
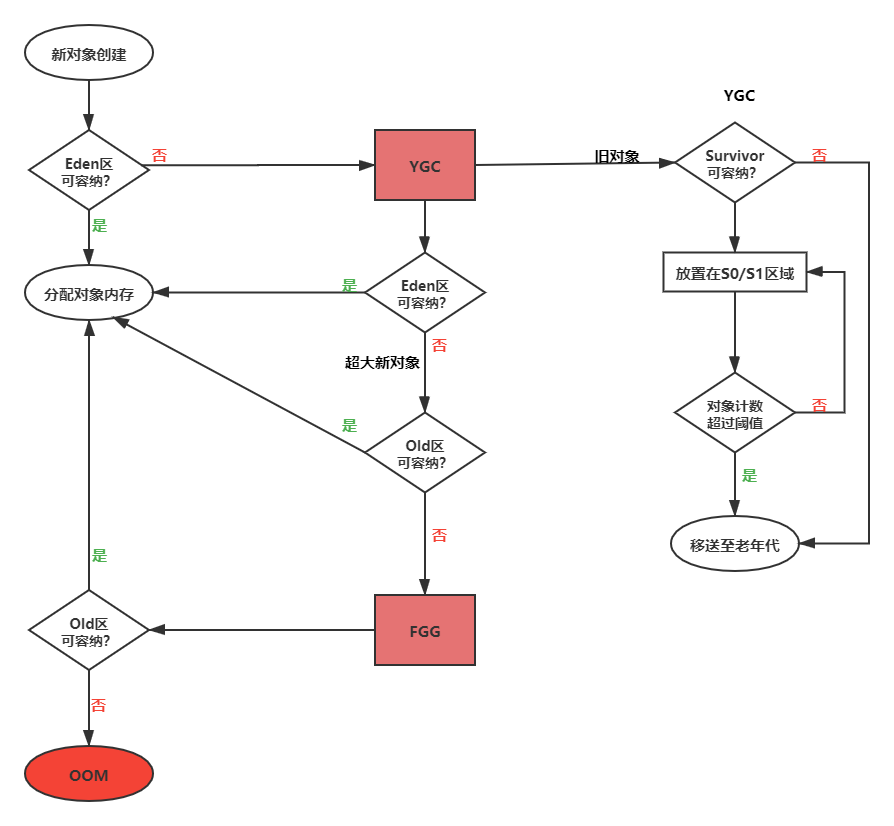
如果Survivor区无法放下,或者创建了一个超大新对象,Eden和Old区都无法存放,就会触发Full Garbage Collection,即FGG,便再尝试放在Old区,如果还是容纳不了,就会抛出OOM异常。在不同的JVM实现及不同的回收机制中,堆内存的划分方式是不一样的。
Metaspace 元空间
在JDK8版本中,元空间的前身Pern区已经被淘汰。在JDK7及之前的版本中,Hotspot还有Pern区,翻译为永久代,在启动时就已经确定了大小,难以进行调优,并且只有FGC时会移动类元信息。不同于之前版本的Pern(永久代),JDK8的元空间已经在本地内存中进行分配,并且,Pern区中的所有内容中字符串常量移至堆内存,其他内容也包括了类元信息、字段、静态属性、方法、常量等等都移至元空间内。
JVM Stacks 虚拟机栈
栈(Stack)是一个先进后出的数据结构,先进后出怎么理解?类似于我们平时打羽毛球时,装羽毛球的球筒,第一个先放进去的往往最后一个才能拿出来,最后放进去的一个最先拿出来。
相对于基于寄存器的运行环境来说,JVM是基于栈结构的运行环境。因为栈结构移植性更好,可控性更强。JVM的虚拟机栈是描述Java方法执行的内存区域,并且是线程私有的。栈中的元素用于支持虚拟机进行方法调用,每个方法从开始调用到执行完成的过程,就是栈帧从入帧到出帧的过程。
在活动线程中,只有位于栈顶的帧才是有效的,称为当前栈帧。正在执行的方法称为当前方法,栈帧是方法运行的基本结构。在执行引擎运行时,所有指令都只能针对当前栈帧进行操作。而StackOverflowError表示请求的栈溢出,导致内存耗尽,通常出现在递归方法中。如果把JVM当做一个棋盘,虚拟机栈就是棋盘上的将/帅,当前方法的栈帧就是棋子能走的区域,而操作栈就是每一个棋子。操作栈的压栈和出栈如下图所示:
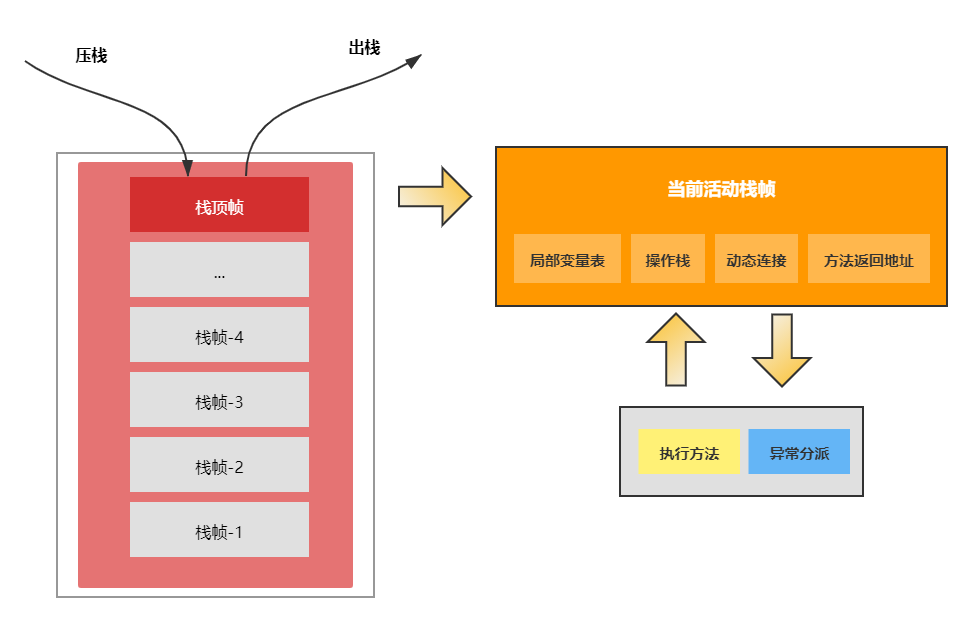
虚拟机栈通过压栈和出栈的方式,对每个方法对应的活动栈帧进行运算处理,方法正常执行结束,肯定会跳转到另外一个栈帧上。在执行的过程中,如果出现异常,会进行异常回溯,返回地址通过异常处理表确定。栈帧在整个JVM体系中的地位颇高,包括局部变量表、操作栈、动态连接、方法返回地址等。
下面对栈帧的各个活动栈帧进行简要的分析
(1)局部变量表
局部变量表是存放方法参数和局部变量的区域。我们都知道,类属性变量一共要经历两个阶段,分为准备阶段和初始化阶段,而局部变量是没有准备阶段,只有初始化阶段,而且必须是显示的。如果是非静态方法,则在index[0]位置上存储的是方法所属对象的实例引用,随后存储的是参数和局部变量。字节码指令中的STORE指令就是将操作栈中计算完成的局部变量写回局部变量表的存储空间内。
(2)操作栈
操作栈是一个初始状态为空的桶式结构栈。在方法执行过程中,会有各种指令往栈中写入和提取信息。JVM的执行引擎是基于栈的执行引擎,其中的栈指的就是操作栈。字节码指令集的定义都是基于栈类型的,栈的深度在方法元信息的stack属性中,下面就通过一个例子来说明下操作栈与局部变量表的交互:
public int add() {
int x = 10;
int y = 20;
int z = x + y;
return z;
}字节码操作顺序如下:
public int add();
Code:
0: bipush 10 // 常量 10 压入操作栈
2: istore_1 // 并保存到局部变量表的 slot_1 中 (第 1 处)
3: bipush 20 // 常量 20 压入操作栈
5: istore_2 // 并保存到局部变量表的 slot_2 中
6: iload_1 // 把局部变量表的 slot_1 元素(int x)压入操作栈
7: iload_2 // 把局部变量表的 slot_2 元素(int y)压入操作栈
8: iadd // 把上方的两个数都取出来,在 CPU 里加一下,并压回操作栈的栈顶
9: istore_3 // 把栈顶的结果存储到局部变量表的 slot_3 中
10: iload_3
11: ireturn // 返回栈顶元素值第 1 处说明:局部变量表就像一个快递柜,有着很多的柜子,依次编号为1,2,3,...,n,字节码指令 istore_1 就代表打开了 1 号柜子,再把栈顶中的值 10 存进去。栈就好如一个桶,任何时候只能对桶口的元素进行操作,所以数据只能在栈顶进行存取。部分指令可以直接在柜子里面直接进行,比如 iinc指令,直接对抽屉里的数值进行 +1操作。我们经常遇到的 i++ 和 ++i,通过字节码对比起来,答案一下子就一目了然了。如下表格所示:

左列中,iload_1 从局部变量表的第1号柜子取出一个数,压入栈顶,下一步直接在柜子里实现 + 1的操作,而这个操作时对栈顶元素的值没有任何影响,所以 istore_2 只是把栈顶元素赋值给 a,而右列,它是先在柜子里面进行 +1的操作,然后再通过 iload_1 把第1号柜子里的数压入栈顶,所以istore_2赋给a的值是 +1 之后的值。扩展下,i++ 并非是原子操作。即使通过volatile关键字来修饰,多线程情况下,还是会出现数据互相覆盖的情况。
(3)动态连接
每个栈帧中包含一个在常量池中对当前方法的引用,目的是支持方法调用过程的动态连接。
(4)方法返回地址
方法执行时有两种退出情况:第一,正常退出,即正常执行到任何方法的返回字节码指令,如 RETURN、IRETURN、ARETURN等;第二,异常退出。无论何种退出情况,都将返回方法当前被调用的位置。方法退出的过程相当于弹出当前栈帧,而退出可能有三种方式:
返回值压入上层调用栈帧。
异常信息抛给能够处理的栈帧。
PC 计数器指向方法调用后的下一条指令。
Native Method Stacks(本地方法栈)
本地方法栈(Native Method Stack)在JVM内存布局中,也是线程对象私有的,但是虚拟机栈“主内”,而本地方法栈“主外”。这个“内外”是针对JVM来说的,本地方法栈为Native方法服务。线程开始调用本地方法时,会进入一个不再受JVM约束的世界。本地方法可以通过JVNI(Java Native Interface)来访问虚拟机运行时的数据区,甚至可以调用寄存器,具有和JVM相同的能力和权限。当大量本地方法出现时,势必会削弱JVM对系统的控制力,因为它的出错信息都比较黑盒,难以捉摸。对于内存不足的情况,本地方法栈还是会抛出 native heap OutOfMemory。
重点说下JNI类本地方法,最常用的本地方法应该是System.currentTimeMills(),JNI使Java深度使用操作系统的特性功能,复用非Java代码。但是在项目过程中,如果大量使用其他语言来实现JNI,就会丧失跨平台特性,威胁到程序运行的稳定性。假如需要与本地代码交互,就可以用中间标准框架来进行解耦,这样即使本地方法崩溃也不至于影响到JVM的稳定。
Program Counter Register (程序计数寄存器)
在程序计数寄存器(Program Counter Register,PC)中,Register的命名源于CPU的寄存器,CPU只有把数据装载到寄存器才能够运行。寄存器存储指令相关的现场信息,由于CPU时间片轮限制,众多线程在并发执行过程中,任何一个确定的时刻,一个处理器或者多核处理器中的一个内核,只会执行某个线程中的一个指令。
这样必然会导致经常中断或恢复,如何才能保证分毫无差呢?每个线程在创建之后,都会产生自己的程序计数器和栈帧,程序计数器用来存放执行指令的偏移量和行号指示器等,线程执行或恢复都要依赖程序计数器。程序计数器在各个线程之间互不影响,此区域也不会发生内存溢出异常。
小结
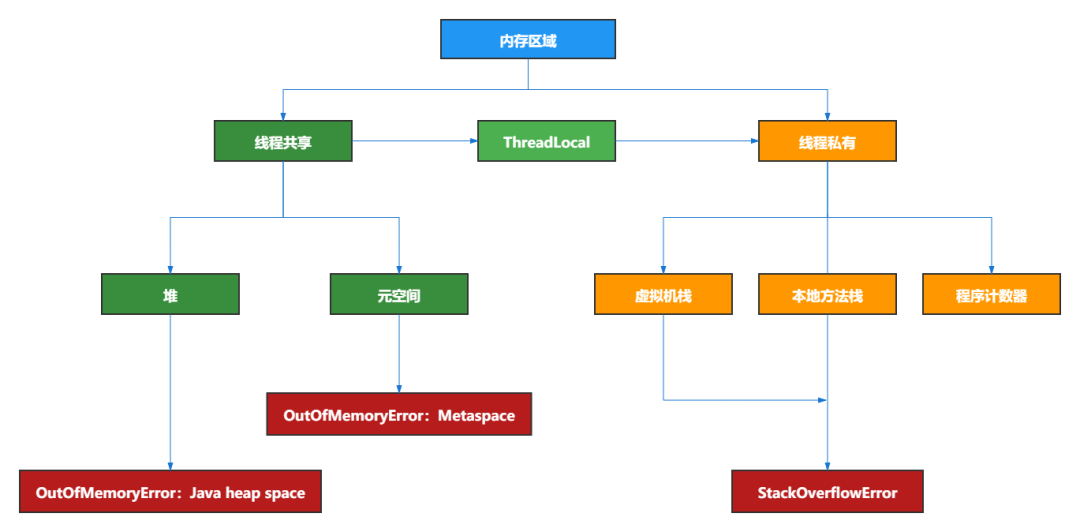
最后,从线程的角度来看,堆和元空间是所有线程共享的,而虚拟机栈、本地方法栈、程序计数器是线程内部私有的,我们以线程的角度再来看看Java的内存结构图:
推荐

PS:因为公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。点“在看”支持我们吧!
边栏推荐
- Introduction to XML III
- Flet教程之 03 FilledButton基础入门(教程含源码)(教程含源码)
- The old-fashioned synchronized lock optimization will make it clear to you at once!
- Summary of recent days (non-technical article)
- unity不识别rider的其中一种解决方法
- 8 expansion sub packages! Recbole launches 2.0!
- 基于STM32+华为云IOT设计的酒驾监控系统
- How to choose a technology stack for web applications in 2022
- Use fail2ban to prevent password attempts
- Flet tutorial 03 basic introduction to filledbutton (tutorial includes source code) (tutorial includes source code)
猜你喜欢
Redis - how to install redis and configuration (how to quickly install redis on ubuntu18.04 and centos7.6 Linux systems)

光环效应——谁说头上有光的就算英雄

上汽大通MAXUS正式发布全新品牌“MIFA”,旗舰产品MIFA 9正式亮相!
CommVault cooperates with Oracle to provide metallic data management as a service on Oracle cloud
提高MySQL深分页查询效率的三种方案

博士申请 | 西湖大学学习与推理系统实验室招收博后/博士/研究实习等

Database lock table? Don't panic, this article teaches you how to solve it
JVM系列——栈与堆、方法区day1-2
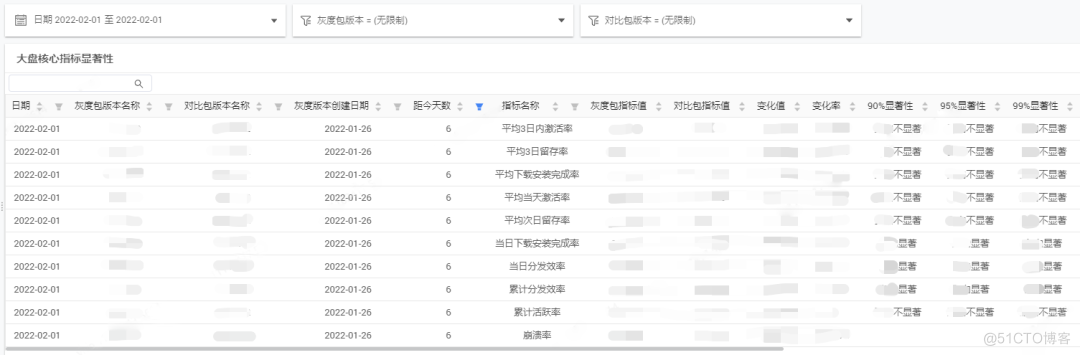
Building intelligent gray-scale data system from 0 to 1: Taking vivo game center as an example

SCM polling program framework based on linked list management

随机推荐
C#基础补充
N++ is not reliable
C語言宿舍管理查詢軟件
Introduction to XML I
Rsyslog configuration and use tutorial
2022年山东省安全员C证考试题库及在线模拟考试
FS7867S是一款应用于数字系统供电电源电压监控的电压检测芯片
Read the BGP agreement in 6 minutes.
Web知识补充
面试拆解:系统上线后Cpu使用率飙升如何排查?
SQL language
Building intelligent gray-scale data system from 0 to 1: Taking vivo game center as an example
30:第三章:开发通行证服务:13:开发【更改/完善用户信息,接口】;(使用***BO类承接参数,并使用了参数校验)
Introduction to XML II
CVPR 2022 | 大幅减少零样本学习所需的人工标注,提出富含视觉信息的类别语义嵌入(源代码下载)...
Automatic filling of database public fields
嵌入式编程中五个必探的“潜在错误”
Fisher信息量检测对抗样本代码详解
高质量软件架构的唯一核心指标
Annual comprehensive analysis of China's mobile reading market in 2022