当前位置:网站首页>Building intelligent gray-scale data system from 0 to 1: Taking vivo game center as an example
Building intelligent gray-scale data system from 0 to 1: Taking vivo game center as an example
2022-07-04 13:03:00 【51CTO】
author :
vivo Internet data analysis team -Dong Chenwei vivo
Internet big data team -Qin Cancan、Zeng Kun
This paper introduces vivo Practical experience of game center in gray data analysis system , from “ Experimental ideas - Mathematical methods - Data model - Product plan ” The four levels provide a relatively complete set of intelligent gray-scale data solutions , To ensure the scientificity of version evaluation 、 Fast closed loop of project progress and gray level verification . The highlight of this scheme is , The introduction of index change root cause analysis method and the design of the whole process automation product scheme .
One 、 introduction
The user scale of the game business is large , The service link is long , Data logic is complicated . As the core user product of the game business platform , Version iterations are very frequent , Before each version goes online, a small amount of gray level verification must be carried out .2021 Since then , The average 1~2 Every week, there will be an important version of grayscale , And sometimes there are multiple versions of gray-scale testing online at the same time . The whole process of grayscale mainly involves 3 A question :
- How to ensure the scientificity of version gray evaluation ?
- How to improve the output efficiency of gray data , Ensure the progress of the project ?
- When there is an abnormal index problem in the grayscale version , How to quickly locate the problem and complete the closed loop ?
In the past two years , We will gradually systematize the gray-scale evaluation method to agile BI And other data products , At present, the gray data system has solved this problem well 3 A question . This paper first paves the way with the basic concept and development process of version gray data system , Then with “ methodology + Solution ” As the main line, this paper expounds the practice of game center in gray data system , And look to the future .
Two 、 Development of gray data system
2.1 What is grayscale publishing
When the game center develops a new homepage interface , How to verify whether the new homepage is accepted by users , And whether the function is perfect 、 Whether the performance is stable ? answer : Grayscale publishing . That is, before the new version is pushed to the full number of users , Select some users according to certain strategies , Let them experience the new homepage first , To get their information about “ The new homepage is easy to use or not ” as well as “ If it's not easy to use , What's wrong ” Using feedback . If there is a major problem , Rollback the old version in time ; On the contrary, it will check and fill the gaps according to the feedback results , And continue to enlarge the launch scope of the new version in due time until the full upgrade .
2.2 Development stage of gray scale evaluation scheme
The key to judge whether grayscale publishing is scientific is to control variables , The process of solving this problem , It is also the process of iteration and development of gray-scale evaluation scheme .
") Stage 1 : Ensure that the comparison time is the same , However, the difference in upgrade speed means that the users who have priority to upgrade and the users who have not upgraded are not homogeneous users , Failed to avoid the impact of sample differences on data result differences .
Stage 1 : Ensure that the comparison time is the same , However, the difference in upgrade speed means that the users who have priority to upgrade and the users who have not upgraded are not homogeneous users , Failed to avoid the impact of sample differences on data result differences .
Stage two : It ensures that the comparison group is the same , But user behavior may change over time , It is impossible to eliminate the difference of time factors before and after .
Stage three : At the same time, it ensures that the time is the same as the crowd , It has the following three advantages :
- Package the old version as a comparison package , Together with the new version of grayscale package , Release to two groups of homogeneous users , The sample properties of gray-scale package and comparison package are guaranteed 、 The time factor is consistent ;
- Calculate a reasonable sample size according to the product target , Avoid too few samples leading to unreliable results 、 Too much leads to waste of resources ;
- Rely on the silent installation function to quickly upgrade , Shorten the time of gray level verification .
2.3 Content of gray data system
Gray scale data systems usually involve Early flow strategy and Later data inspection 2 Parts of .
The former includes sample size calculation and grayscale duration control , The latter includes the comparison of core indicators between new and old versions 、 Data performance of index changes or new functions in product optimization . In addition to conventional gray scale evaluation , The introduction of root cause analysis can improve the interpretation of gray results .
2.4 vivo The practice of game center
We built “ Game center intelligent gray data system ”, And gradually solve the problem mentioned at the beginning of this article through three versions of iteration 3 A question . The data system consists of index test results 、 Dimension drill down interpretation 、 User attribute verification 、 It is composed of subject Kanban such as index anomaly diagnosis and gray conclusion report pushed automatically .
After the deployment of the complete scheme goes online , It basically realizes the automatic data production in the gray evaluation stage 、 Effect test 、 Closed loop of data interpretation and decision recommendations , It has greatly released manpower .
3、 ... and 、 Methodology in gray data system
Before introducing the data scheme design , First, introduce the background knowledge and methodology involved in the gray-scale data system , Help you better understand this article .
3.1 Gray scale experiment
Grayscale experiments include Sampling and effect inspection Two parts , Corresponding to the idea of hypothesis testing and the verification of historical differences of samples .
3.1.1 Hypothesis testing
Hypothesis testing is to put forward a hypothetical value for the overall parameters , Then use the sample performance to judge whether this hypothesis is true .
")
3.1.2 Verification of sample historical differences
Although the grayscale has been passed in advance hash Algorithm for sampling , But because of the randomness of sampling , Generally, statistical test and effect test are conducted at the same time , Verify the historical differences of samples , Eliminate the index fluctuation caused by the difference of the sample itself . The grayscale period is usually 7 God , We used 7 Sampling method of sliding window .
")
3.2 Root cause analysis
Gray scale indicators are often associated with multidimensional attributes ( Such as user attributes 、 Channel source 、 Page module, etc ) There is a connection , When the test results of indicators have abnormal significant differences , Want to remove the exception , Locating the root cause is a key step . However , This step is often challenging , Especially when the root factor is a combination of multiple dimension attribute values . To solve this problem , We introduce the method of root cause analysis , In order to make up for the lack of interpretation of gray test results . We combine index logic analysis with Adtributor Algorithm 2 Methods , To ensure the reliability of the analysis results .
3.2.1 Index logical analysis
Because the index system constructed in the gray-scale experiment is basically rate value index or mean value index , These two kinds of indicators can be disassembled into two factors, numerator and denominator, through the indicator formula , The numerator and denominator of the indicator are obtained by adding the dimension values under each dimension . Therefore, it is proposed that Index logical analysis , Based on certain disassembly methods , From the index factor and index dimension 2 The index value is logically disassembled at three levels .
")
3.2.2 Adtributor Algorithm
In addition to the common dimension drilling method of root cause analysis , We introduced Adtributor Algorithm , To better deal with the situation of multi-dimensional combination impact indicators , And through the cross validation of the two methods to ensure the reliability of the analysis results . Adtributor The algorithm was developed by Microsoft Research in 2014 An abnormal root cause analysis method of multidimensional time series proposed in , It has good reliability in the scenario of multi-dimensional complex root causes . The whole process of the algorithm includes data preprocessing 、 Anomaly detection 、 Root cause analysis and simulation visualization 4 A step , We mainly learn from the method of root cause analysis .
")
Four 、 Gray scale intelligent solution
4.1 The overall framework
Version grayscale can be divided into grayscale before - In gray - After grayscale 3 Stages , The overall framework of productization is as follows :
")
4.2 Process design
Based on the above framework , How do we design and implement ? The following is a flowchart describing the whole process :
")
4.3 The core content of the scheme
4.3.1 Sample size estimation scheme
Kanban provides : Under multiple sets of confidence levels and test efficiency standards ( Default display 95% Degree of confidence 、80% Test performance ), According to the recent performance of the index , Predict the minimum sample size that the index can be detected significantly under different expected ranges of change . The scheme has 3 Big feature :
- Output multiple sets of Standards , Flexibly adjust the expected range ;
- Automatically select the latest full version of data as data input ;
- The average index and rate value index adopt differentiated calculation logic .
")
4.3.2 Significance test scheme of effect index
The question that the index significance test model needs to answer is : The grayscale version is compared with the contrast version , Is the change of the index statistically believable or unbelievable . at present , The grayscale version and the contrast version under three confidence levels are realized in 20 Significance judgment on business indicators . The implementation process is as follows :
Rate value indicators
... ...
#
The following index data have been obtained
variation_visitors
#
Denominator of grayscale version index
control_visitors
#
The denominator of the comparison version indicator
variation_p
#
Grayscale version index value
control_p
#
Compare the version index value
z
#
Different confidence levels (
90
%/
95
%/
99
%)
Under the z value , Business mainly focuses on 95
%
Significant test results at confidence level
#
Calculate the standard deviation of the index
variation_se
=
math.
sqrt(
variation_p
* (
1
-
variation_p))
control_se
=
math.
sqrt(
control_p
* (
1
-
control_p))
#
Calculate the index change value and change rate
gap
=
variation_p
-
control_p
rate
=
variation_p
/
control_p
-
1
#
Calculate the confidence interval
gap_interval_sdown
=
gap
-
z
*
math.
sqrt(
math.
pow(
control_se,
2)
/
control_visitors
+
math.
pow(
variation_se,
2)
/
variation_visitors)
#
Lower bound of confidence interval of change value
gap_interval_sup
=
gap
+
z
*
math.
sqrt(
math.
pow(
control_se,
2)
/
control_visitors
+
math.
pow(
variation_se,
2)
/
variation_visitors)
#
Upper bound of confidence interval of change value
confidence_interval_sdown
=
gap_interval_sdown
/
control_p
#
Lower bound of the confidence interval of the rate of change
confidence_interval_sup
=
gap_interval_sup
/
control_p
#
Upper bound of confidence interval of change value
#
Significance judgment
if (
confidence_interval_sdown
>
0
and
confidence_interval_sup
>
0)
or (
confidence_interval_sdown
<
0
and
confidence_interval_sup
<
0):
print(
" remarkable ")
elif (
confidence_interval_sdown
>
0
and
confidence_interval_sup
<
0)
or (
confidence_interval_sdown
<
0
and
confidence_interval_sup
>
0):
print(
" No significant ")
... ...
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
Average index
... ...
#
The following index data have been obtained
variation_visitors
#
Denominator of grayscale version index
control_visitors
#
The denominator of the comparison version indicator
variation_p
#
Grayscale version index value
control_p
#
Compare the version index value
variation_x
#
Gray version single user index value
control_x
#
Compare the single user index value of the version
z
#
Different confidence levels (
90
%/
95
%/
99
%)
Under the z value , Business mainly focuses on 95
%
Significant test results at confidence level
#
Calculate the standard deviation of the index
variation_se
=
np.
std(
variation_x,
ddof
=
1)
control_se
=
np.
std(
control_x,
ddof
=
1)
#
Calculate the index change value and change rate
gap
=
variation_p
-
control_p
rate
=
variation_p
/
control_p
-
1
#
Calculate the confidence interval
gap_interval_sdown
=
gap
-
z
*
math.
sqrt(
math.
pow(
control_se,
2)
/
control_visitors
+
math.
pow(
variation_se,
2)
/
variation_visitors)
#
Lower bound of confidence interval of change value
gap_interval_sup
=
gap
+
z
*
math.
sqrt(
math.
pow(
control_se,
2)
/
control_visitors
+
math.
pow(
variation_se,
2)
/
variation_visitors)
#
Upper bound of confidence interval of change value
confidence_interval_sdown
=
gap_interval_sdown
/
control_p
#
Lower bound of the confidence interval of the rate of change
confidence_interval_sup
=
gap_interval_sup
/
control_p
#
Upper bound of confidence interval of change value
#
Significance judgment
if (
confidence_interval_sdown
>
0
and
confidence_interval_sup
>
0)
or (
confidence_interval_sdown
<
0
and
confidence_interval_sup
<
0):
print(
" remarkable ")
elif (
confidence_interval_sdown
>
0
and
confidence_interval_sup
<
0)
or (
confidence_interval_sdown
<
0
and
confidence_interval_sup
>
0):
print(
" No significant ")
... ...
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
The Kanban is shown below :
")
4.3.3 Negative indicator automatic root cause analysis scheme
The automatic root cause analysis scheme for negative indicators of gray-scale scenes includes change detection 、 Verification of sample historical differences 、 Index logic disassembly and Adtributor Automatic root cause analysis 4 A step .
")
among ,Adtributor Automatic root cause analysis can calculate the factor that contributes the most to the indicator change in the dimension of the same level , We adapt to specific indicator business scenarios by layering indicator dimensions and setting relationships , Build a logical model of multi-level attribution Algorithm , So as to realize the automatic output of business level root cause conclusion .
")
The Kanban is shown below :
")
4.3.4 Gray scale report intelligent splicing push scheme
") Automatic acquisition of version information content :
Automatic acquisition of version information content :
Get the version number through the publishing platform 、 Actual loading 、 Cumulative number of days of release and version related content , As the beginning of the grayscale report .
The conclusion is that :
According to whether the indicators are all positive / Partially negative / All negative 、 Whether the statistical results such as uneven samples are automatically combined and mapped to the preset conclusion document , A total of 10 Various conclusion templates .
Interpretation of significance test of core indicators ( According to different gray levels , Interpret different types of indicators ):
- T+1~T+2: Performance indicators 、 Activity rate index
- T+3~T+6: Active performance indicators 、 Distribute performance indicators 、 Download installation process conversion indicators
- T+7: Active performance indicators 、 Distribute performance indicators 、 Download installation process conversion indicators 、 The latter transformation indicators
Interpretation of the attribution of the first level module dimension :
If the grayscale version has clearly input the specific change points to a level-1 module in the early stage , The module will be interpreted automatically , And output the data of other modules with index differences ; If the grayscale version does not input the change points at the module level , On the output indicators, the effect is remarkable ( Positive significant 、 Negative significant ) The interpretation conclusion of the first level module .
Interpretation of sample size uniformity :
Business indicators , Judge whether the distribution is uniform by significance test ; Non business indicators , Judge by distribution differences .
Interpretation of negative diagnosis :
According to the results of the multi-level automated root cause model , Modifiers mapped according to different dimension types 、 Dimension quantity positioning ( One dimension / multidimensional ) And the conclusion of sample historical difference verification , Corresponding to different templates , Finally, the negative diagnosis copy is spliced .
5、 ... and 、 At the end
Requirements for scientific evaluation and rapid decision-making in business gray-scale publishing , We combine a variety of methods , from “ Experimental ideas - Mathematical methods - Data model - Product plan ” The four levels provide a relatively complete solution of intelligent gray-scale data system . This paper hopes to provide reference for the construction of gray data system in business , However, it should be reasonably designed in combination with the characteristics of each business . The data model design involved in the scheme is not introduced in detail here , Interested students are welcome to discuss learning with the author . Besides , Gray data system still needs to be improved , Throw it out here first , Some of them are also being studied and solved :
1. When gray traffic is grouped , It usually adopts the method of random grouping . But because of completely random uncertainty , After grouping ,2 Group samples may naturally be unevenly distributed in some index characteristics . Compared with the post sample uniformity verification method , Stratified sampling can also be considered to avoid this problem ;
2. In the process of gray index analysis , There is still room for improvement in the automatic multidimensional root cause analysis model , At present, the model is very dependent on the comprehensiveness of the dimensions in its own data source , And only quantitative reasons can be detected . Later, we hope to put the quantitative root cause model , Combine qualitative factors for a more comprehensive and accurate interpretation ;
3. At present, the whole gray-scale solution of the game center is essentially based on 2 sample-test Test model , However, the model needs to improve the core indicators according to the expected improvement of the gray version compared with the comparative version , To estimate the minimum sample size in advance , In the actual grayscale process, the core index may not reach the expected situation . Try it in the future mSPRT And other inspection methods , Weaken the limitation of minimum sample size on significant results .
reference :
- Mao Shisong , Wang Jinglong , Pu Xiaolong . 《 Advanced mathematical statistics ( The second edition )》
- It's Lao Li, that's right . 《 Five minutes to master AB Principle of experiment and sample size calculation 》. CSDN Blog
- Ranjita Bhagwan, Rahul Kumar, Ramachandran Ramjee, et al. 《Adtributor: Revenue Debugging in Advertising Systems》
边栏推荐
- Two dimensional code coding theory
- Using nsproxy to forward messages
- Daily Mathematics Series 57: February 26
- mysql三级分销代理关系存储
- A treasure open source software, cross platform terminal artifact tabby
- Can Console. Clear be used to only clear a line instead of whole console?
- 「小技巧」给Seurat对象瘦瘦身
- PostgreSQL 9.1 飞升之路
- Etcd storage, watch and expiration mechanism
- runc hang 导致 Kubernetes 节点 NotReady
猜你喜欢
Concepts and theories related to distributed transactions
强化学习-学习笔记1 | 基础概念
Runc hang causes the kubernetes node notready

众昂矿业:为保障萤石足量供应,开源节流势在必行
Transformer principle and code elaboration (pytorch)
Transformer principle and code elaboration (tensorflow)

诸神黄昏时代的对比学习
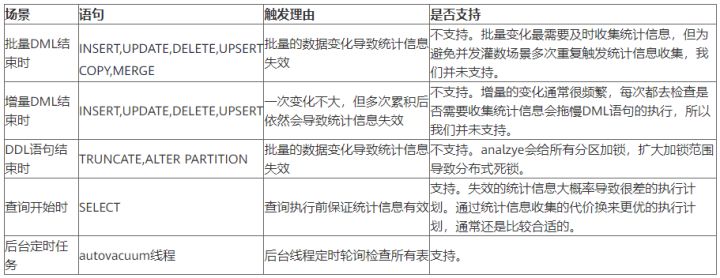
Master the use of auto analyze in data warehouse

2022年中国移动阅读市场年度综合分析

Full arrangement (medium difficulty)
随机推荐
MDK在头文件中使用预编译器时,#ifdef 无效的问题
游戏启动后提示安装HMS Core,点击取消,未再次提示安装HMS Core(初始化失败返回907135003)
C language: find the length of string
【Android Kotlin】lambda的返回语句和匿名函数
Transformer principle and code elaboration (pytorch)
C language array
A treasure open source software, cross platform terminal artifact tabby
Peak detection of measured signal
实时云交互如何助力教育行业发展
游戏启动后提示安装HMS Core,点击取消,未再次提示安装HMS Core(初始化失败返回907135003)
敏捷开发/敏捷测试感受
How real-time cloud interaction helps the development of education industry
16. Memory usage and segmentation
在 Apache 上配置 WebDAV 服务器
【AI系统前沿动态第40期】Hinton:我的深度学习生涯与研究心法;Google辟谣放弃TensorFlow;封神框架正式开源
0x15 string
C#/VB. Net to add text / image watermarks to PDF documents
诸神黄昏时代的对比学习
DVWA range exercise 4
再说rsync+inotify实现数据的实时备份