当前位置:网站首页>Week 2: convolutional neural network
Week 2: convolutional neural network
2022-07-25 22:59:00 【The Pleiades of CangMao】
Preface

Basic structure
One 、 Convolution Convolutional
1 Traditional neural networks VS Convolutional neural networks

2 Concept
Convolution is a mathematical operation on two functions of real variables .
3 Calculation of convolution layer
Because the image is two-dimensional , So we need to carry out two-dimensional convolution on the image .
How convolution kernel works ?
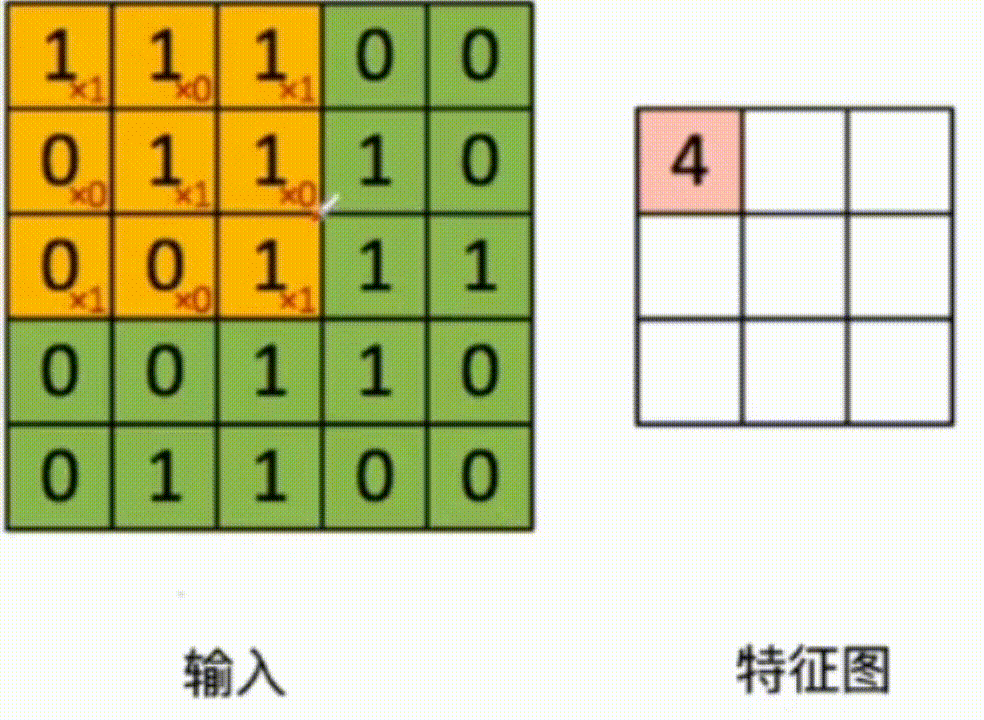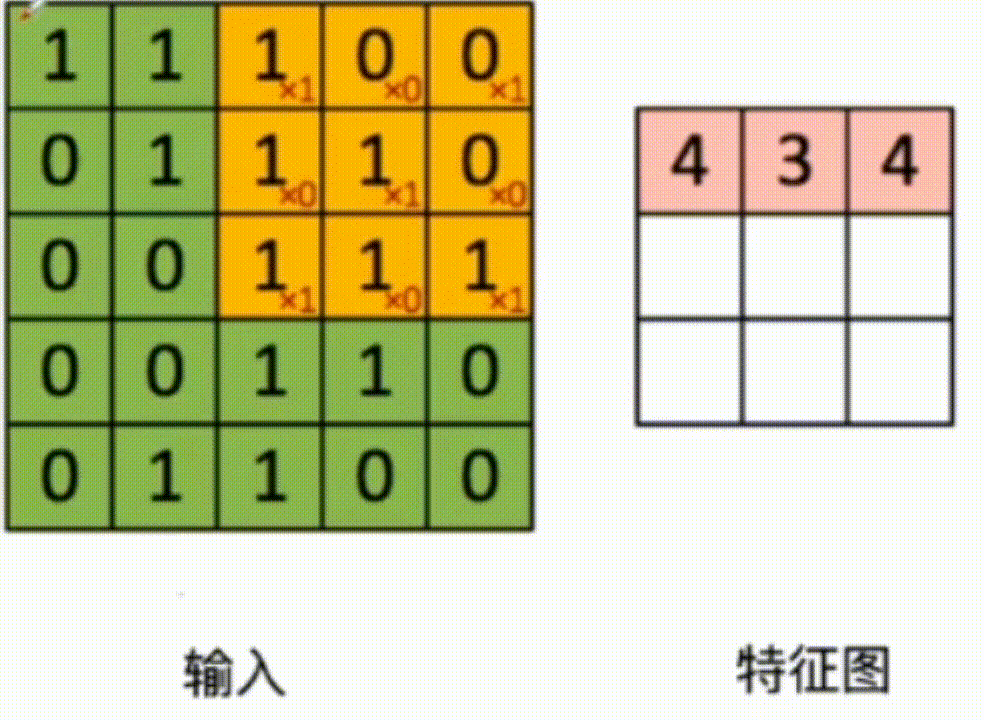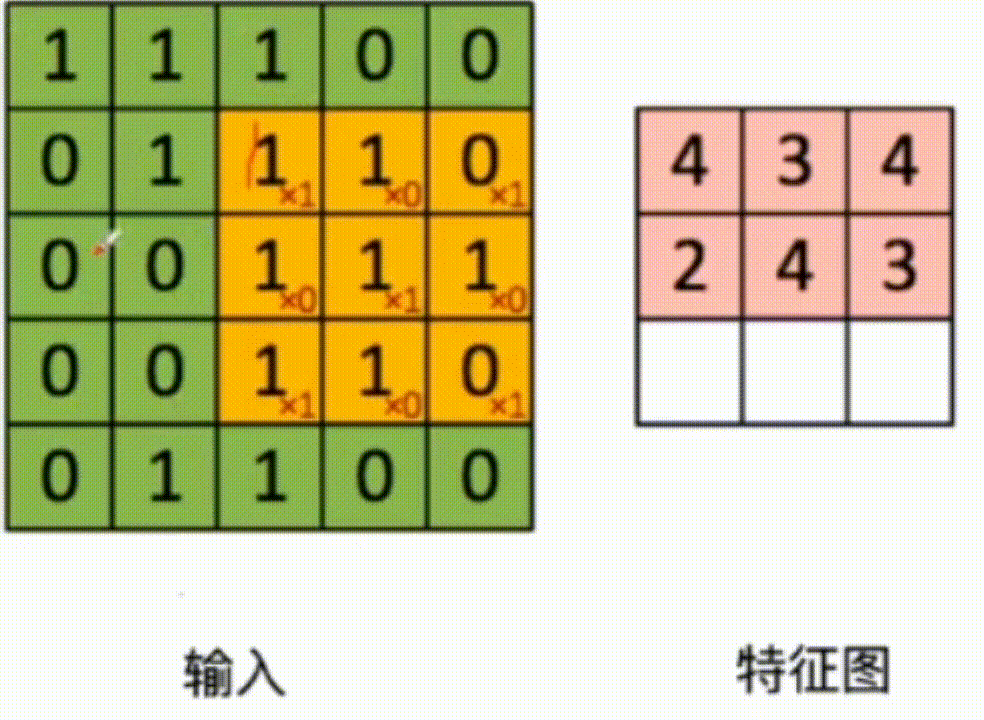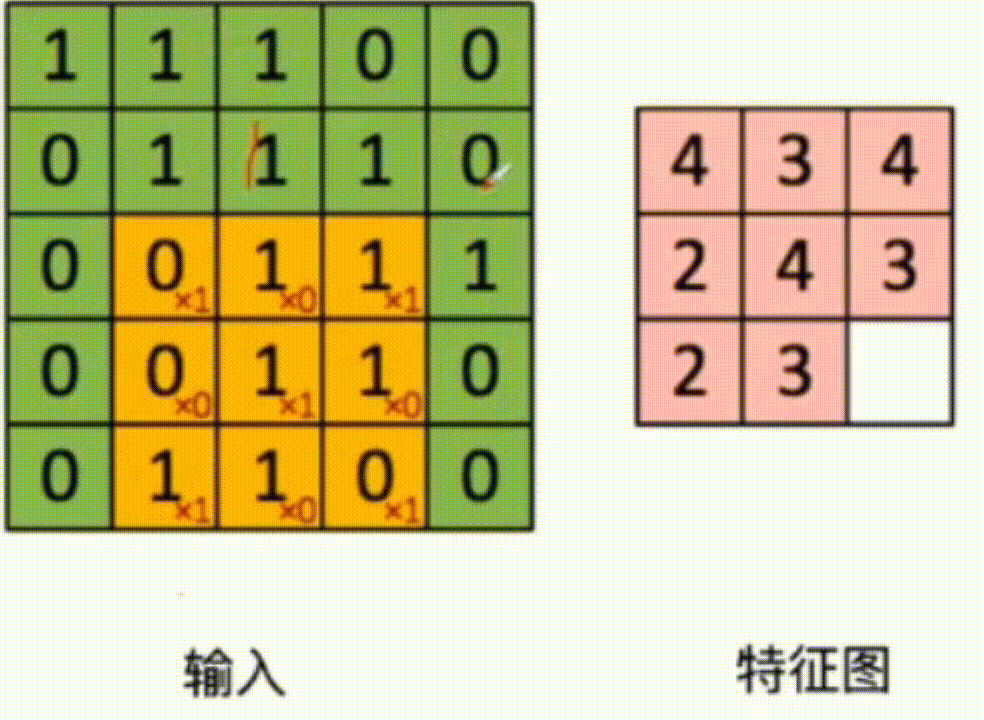
example 1: Input :5x5
Convolution kernel :3x3 [ 1 0 1 0 1 0 1 0 1 ] \begin{bmatrix}1&0&1\\0&1&0\\1&0&1\end{bmatrix} ⎣⎡101010101⎦⎤
step :1
Characteristics of figure :3x3
3x3 The convolution kernel of acts on the input data , Multiply and add the corresponding values , As shown in the figure below :
When Set the step size (stride) Does not match the size of the input picture when , The picture can be externally Zero fill , Thus, the input image size becomes larger .eg. example 1 Of padding by 0, example 2 Of padding by 1~
example 2:2 individual channel(2 individual filter, The final output is 2 individual feature map),padding=1
7x7x3,(3 A different weight matrix )
channel For the generated feature map The number of layers , Here is 2

Yes padding The size of the output characteristic graph ( The side length of a characteristic graph ): ( N + p a d d i n g ∗ 2 − F ) s t r i d e + 1 \frac{(N+padding*2-F)}{stride}+1 stride(N+padding∗2−F)+1
Two 、 Pooling
- While pooling retains the main features Reduce parameters and Amount of computation , Prevent over fitting , Improve the model generalization ability .
- It is generally between the convolution layer and the convolution layer , Between the full connection layer and the full connection layer .
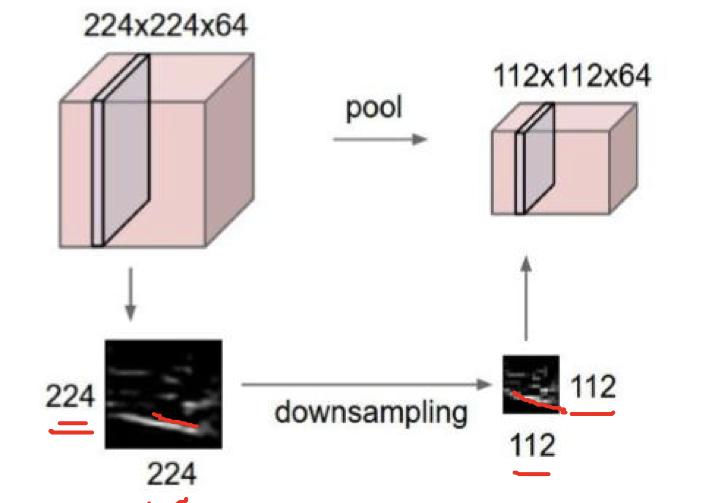
Pooling The type of :
- Max pooling: Maximum pooling ( Commonly used for classification tasks )
- Average pooling: The average pooling

3、 ... and 、 Full connection
Usually the last part , Change the multi-dimensional matrix into a one-dimensional vertical column matrix for classification .
Four 、 Summary

Typical structure of convolutional neural network
One 、AlexNet
AlexNe The network brings deep learning back to the stage of history ~
- To prevent over fitting
(1) Used Dropout( Immediate deactivation ), During training, some neurons are shut down randomly , Integrate all neurons during the test ;
(2) Data to enhance :
· reverse 、 translation 、 symmetry : Random crop( Scale the picture )、 Flip horizontal ( Multiply the number of samples );
· change RGB Channel strength , Yes RGB Gaussian perturbation in space ; - The nonlinear activation function is used ReLU( Solved the problem of gradient disappearance 、 The calculation speed is very fast, just 2 Determine whether the input is >0、 The convergence rate is much faster than sigmoid)

Two 、ZFNet

3、 ... and 、VGG
VGG Is a deeper network . An auxiliary classifier is added , Solve the problem of gradient disappearance caused by too deep depth .
Four 、GoogleNet
Set up Inception modular ( Multiple Inception Structure stacking ), stay Inception Pass through Multiple convolution kernels Increase the diversity of features ( The following figure on the left ), But the final output is very large , It will lead to high computational complexity .
The solution is : Insert 1*1 Convolution kernel Conduct Dimension reduction ( Top right )
Then use a small convolution kernel instead of a large convolution kernel , Further reduce the amount of parameters .
for example : Use Two 3 * 3 Convolution kernel Come on replace One 5 * 5 Convolution kernel , It can reduce the parameter quantity 
Add nonlinear activation function between convolution kernel and convolution kernel , It is the network that produces more independent features , Stronger representation , Faster training .
The output has no additional full connection layer ( Except for the last category output layer )
5、 ... and 、ResNet
depth 152 layer .
Residual learning network (deep residual learning network)
Residual thought : Remove the same main part , To highlight small changes , It can be used to train very deep Networks .
set up F(x) + x = f( g( h(x) + x ) + x ) + x, Derivation of the formula , have to derivative = (f’ + 1)(g’ + 1)(h’ + 1). Even if the derivative of the function is zero or the function itself is zero , But add 1 Then there will be no gradient disappear .
Programming
torchvision.datasets.MNIST(root, train=True, transform=None, target_transform=None, download=False)
- root Download the data set to the local root directory , Include training.pt and test.pt file
- train, If set to True, from training.pt Create a dataset , Otherwise, from test.pt establish .
- transform, A function or transformation , Input PIL picture , Return the transformed data .
- target_transform A function or transformation , Input target , To transform .
- download, If set to True, Download data from the Internet and put it in root Under the folder
- DataLoader Is a more important class , The common operations provided are :
- batch_size( Every batch Size ), shuffle( Whether to randomly disrupt the order ),
- num_workers( When loading data, several sub processes are used )
transforms.Compose
Composes several transforms together. This transform does not support torchscript.
Combine several transformations . This transformation doesn't support torchscript.
- That is, combine several transformation methods , Transform the corresponding data in order .
- among torchscript Script module , Used to encapsulate scripts for cross platform use , If you need to support this situation , Need to use
torch.nn.Sequential, instead ofcompose- Corresponding to the code in the problem description , Apply first
ToTensor()send [0-255] Transformation for [0-1], Then applyNormalizeCustom standardization
transforms.ToTensor()
Convert a PIL Image or numpy.ndarray to tensor
Change one PIL Library pictures ornumpyThe array of istensorTensor type ; Convert from [0,255]->[0,1]
- Realization principle : Deal with different types , That is, divide each value by 255, Finally through
torch.from_numpytake PIL Library pictures ornumpy.ndarrayFor specific value types, such asInt32,int16,floatEqual conversiontorch.tensordata type
transforms.Normalize()
Normalize a tensor image with mean and standard deviation
Normalize a by means of mean and standard deviation tensor Images ( Standardizing images ), Formula for :output[channel] = (input[channel] - mean[channel]) / std[channel]
explain :transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
- first
(0.5, 0.5 ,0.5)That is, the average of the three channels- the second
(0.5, 0.5, 0.5)That is, the standard deviation of the three channels
becauseToTensor()The image has been changed to [0, 1], We make it [-1, 1], Take the first channel as an example , Substitute the maximum and minimum values into the formula :- (0-0.5)/0.5=-1
- (1-0.5)/0.5=1
That is, mapping to [-1,1]
One 、MNIST Data set classification : Build a simple CNN Yes mnist Data sets are classified .
Two 、CIFAR10 Data set classification : Use CNN Yes CIFAR10 Data sets are classified
3、 ... and 、 Use VGG16 Yes CIFAR10 classification
problem
- dataloader Inside shuffle What's the difference between taking different values ?
shuffle = truewhen , You can disrupt the order of pictures to increase diversity- Generally in
trainSet upshuffle=true, staytestSet upshuffle=false.- Pytorch Of DataLoader Medium shuffle Is to disrupt , Retake batch.
If the training set shuffle Not set to true The trained model is not generalized , That is, it is only suitable for predicting this data set , If the effect is not good on other data sets, it may also be bad on this data set . our shuffle The purpose of is to increase the generalization ability of the model , The test set is used to evaluate the performance of our training model on unknown data . Let the test set keep the original order convolution .
transform in , Different values are taken , What's the difference between this ?
Common data preprocessing methods , Such as below , The data set in the training part enhances the data , Use random cropping and random flipping , To enhance the generalization ability of the model , Prevent over fitting .epoch and batch The difference between ?
- When a complete data set passes through the neural network once , And return once , This process is called a epoch.( Multiple required epoch: In deep learning , It is not enough to transmit the entire data set to the neural network once , You need to train on neural network many times .)
- When the data set is large , For each epoch, It is difficult to read all data sets into memory at one time , This is the need to divide the data set into several reads , Call it one at a time batch.
- bach_size:batch Number of samples in .
1x1 Convolution sum of FC What's the difference? ? What role does it play ?
There is no difference in mathematical principle . but 1x1 The input size of convolution kernel of is not fixed ; The full connection is fixed .1*1 Convolution can be used to increase dimension ,FC Usually at the end .residual leanring Why can we improve the accuracy ?
Solved the problem of gradient disappearance , It can be used to train deeper NetworksCode exercise 2 , The Internet and 1989 year Lecun Proposed LeNet What's the difference? ?
Code 2 is used ReLu As an activation function ,LeNet The activation function of is SigmodCode exercise 2 , After convolution feature map It's going to get smaller , How to apply Residual Learning Residual learning ?
You can choose to use 1*1 Convolution 、 fill padding And other methods to adjust feature map SizeWhat methods can further improve the accuracy ?
Prevent over fitting :Dropout、 The data set in the training part enhances the data ( Data preprocessing )
Appropriately increase the depth of the model , Use a more appropriate activation function , Change the network structure of the model
边栏推荐
- What are the differences between FileInputStream and bufferedinputstream?
- [paper notes] a meta reinforcement learning algorithm for causal discovery
- How to obtain the cash flow data of advertising services to help analyze the advertising effect?
- Summary of my 2020 online summer camp
- [training day15] paint road [minimum spanning tree]
- Ribbon execution logic source code analysis
- recyclerview计算滑动距离之computeHorizontalScrollExtent-computeHorizontalScrollRange-computeHorizontalScrol
- 为啥谷歌的内部工具不适合你?
- 技术美术百人计划学习笔记(1)--基础渲染管线
- 贴片微型滚珠振动开关的结构原理
猜你喜欢

The new media operation strategy (taking xiaohongshu as an example) helps you quickly master the creative method of popular models

QT的Tree View Model示例

Notification设置的小图标显示的是小方块

Use of qvariant
![[training day15] paint road [minimum spanning tree]](/img/12/2d4ad1e2b8133b6c92875faa4b4182.png)
[training day15] paint road [minimum spanning tree]

Design of Butterworth filter and drawing of amplitude frequency characteristic curve

Network Security Learning (XII) OSI and TCP

Mocha test

Learning notes of technical art hundred people plan (2) -- vector
Tree view model example of QT
随机推荐
How to obtain the cash flow data of advertising services to help analyze the advertising effect?
[PMP learning notes] Chapter 1 Introduction to PMP System
DOM event object
The difference between abstract classes and interface interfaces
Learning notes of technical art hundred people plan (1) -- basic rendering pipeline
Recommend short videos every week: more and more smart devices need collaboration, posing a greater challenge to the development of the Internet of things?
What is the difference between bio, NiO and AIO?
Kibana~后台启动Kibana之后无法找到进程号
721. 账户合并 ●●、并查集
Deep recursion, deep search DFS, backtracking, paper cutting learning.
Mysql数据类型
单元测试,写起来到底有多痛?
QT log file system
Structure principle of micro ball vibration switch with chip
Use of qvariant
武汉理工大学第三届程序设计竞赛 B-拯救DAG王国(拓扑性质处理可达性统计问题)
MySQL data type
Experiment 1, experiment 2 and Experiment 3 of assembly language and microcomputer principle: branch program design / loop program design / subroutine design
Network Security Learning (XII) OSI and TCP
Similarities and differences between equals and "= ="