当前位置:网站首页>什么是embedding(把物体编码为一个低维稠密向量),pytorch中nn.Embedding原理及使用
什么是embedding(把物体编码为一个低维稠密向量),pytorch中nn.Embedding原理及使用
2022-07-03 14:53:00 【Hali_Botebie】
文章目录
简单来说,embedding就是用一个低维的向量表示一个物体,可以是一个词,或是一个商品,或是一个电影等等。这个embedding向量的性质是能使距离相近的向量对应的物体有相近的含义,比如 Embedding(复仇者联盟)和Embedding(钢铁侠)之间的距离就会很接近,但 Embedding(复仇者联盟)和Embedding(乱世佳人)的距离就会远一些。
除此之外Embedding甚至还具有数学运算的关系,比如Embedding(马德里)-Embedding(西班牙)+Embedding(法国)≈Embedding(巴黎)
从另外一个空间表达物体,甚至揭示了物体间的潜在关系,上次体会这样神奇的操作还是在学习傅里叶变换的时候,从某种意义上来说,Embedding方法甚至具备了一些本体论的哲学意义。
言归正传,Embedding能够用低维向量对物体进行编码还能保留其含义的特点非常适合深度学习。在传统机器学习模型构建过程中,我们经常使用one hot encoding对离散特征,特别是id类特征进行编码,但由于one hot encoding的维度等于物体的总数,比如阿里的商品one hot encoding的维度就至少是千万量级的。这样的编码方式对于商品来说是极端稀疏的,甚至用multi hot encoding对用户浏览历史的编码也会是一个非常稀疏的向量。而深度学习的特点以及工程方面的原因使其不利于稀疏特征向量的处理(这里希望大家讨论一下为什么?)。因此如果能把物体编码为一个低维稠密向量再喂给DNN,自然是一个高效的基本操作。
使embedding空前流行的word2vec
对word的vector表达的研究早已有之,但让embedding方法空前流行,我们还是要归功于google的word2vec。我们简单讲一下word2vec的原理,这对我们之后理解AirBnB对loss function的改进至关重要。
句子的表达
既然我们要训练一个对word的语义表达,那么训练样本显然是一个句子的集合。假设其中一个长度为T的句子为 w 1 , w 2 , . . . , w T w_{1},w_{2},...,w_{T} w1,w2,...,wT。这时我们假定每个词都跟其相邻的词的关系最密切,换句话说每个词都是由相邻的词决定的(CBOW模型的动机),或者每个词都决定了相邻的词(Skip-gram模型的动机)。如下图,CBOW的输入是 w t w_{t} wt 周边的词,预测的输出是 w t w_{t} wt ,而Skip-gram则反之,经验上讲Skip-gram的效果好一点,所以本文从Skip-gram模型出发讲解模型细节。

训练样本
那么为了产生模型的正样本,我们选一个长度为2c+1(目标词前后各选c个词)的滑动窗口,从句子左边滑倒右边,每滑一次,窗口中的词就形成了我们的一个正样本。
损失函数
有了训练样本之后我们就可以着手定义优化目标了,既然每个词 都决定了相邻词 ,基于极大似然,我们希望所有样本的条件概率 p ( w t + j ∣ w t ) p(w_{t+j}|w_{t}) p(wt+j∣wt)之积最大,这里我们使用 log probability。我们的目标函数有了:
接下来的问题是怎么定义 p ( w t + j ∣ w t ) p(w_{t+j}|w_{t}) p(wt+j∣wt),作为一个多分类问题,最简单最直接的方法当然是直接用softmax函数,我们又希望用向量 v w v_{w} vw 表示每个词w,用词之间的距离 v i T v j v_{i}^{T}v_{j} viTvj表示语义的接近程度,那么我们的条件概率的定义就可以很直观的写出。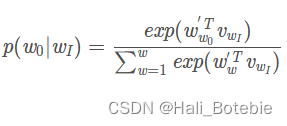
输入向量表达和输出向量表达 v w v_{w} vw
w t w_{t} wt 去预测 w t + j w_{t+j} wt+j ,但其实这二者的向量表达并不在一个向量空间内。就像上面的条件概率公式写的一样, v w ′ v_{w}' vw′ 和 v w v_{w} vw分别是词w的输出向量表达和输入向量表达。
那什么是输入向量表达和输出向量表达呢?我们画一个word2vec的神经网络架构图就明白了。

根据 p ( w t + j ∣ w t ) p(w_{t+j}|w_{t}) p(wt+j∣wt) 的定义,我们可以把两个vector的乘积再套上一个softmax的形式转换成上面的神经网络架构(需要非常注意的一点事hidden layer的激活函数,大家要思考一下,到底是sigmoid函数还是普通的线性函数,为什么?)。在训练过程中我们就可以通过梯度下降的方式求解模型参数了。那么上文所说的输入向量表达就是input layer到hidden layer的权重矩阵 W V × N W_{V\times N} WV×N,而输出向量表达就是hidden layer到output layer的权重矩阵 W N × V ′ W_{N\times V}^{'} WN×V′
那么到底什么是我们通常意义上所说的词向量 v w v_{w} vw呢?
其实就是我们上面所说的输入向量矩阵 W V × N W_{V\times N} WV×N 中每一行对应的权重向量。于是这个权重矩阵自然转换成了word2vec的lookup table。

那么问题也来了,我们能把输出矩阵 W N × V ′ W_{N\times V}^{'} WN×V′ 的列向量当作word的vector表达吗?大家可以讨论一下。
当然在训练word2vec的过程中还有很多工程技巧,比如用negative sampling或Hierarchical Softmax减少词汇空间过大带来的计算量,对高频词汇进行降采样避免对于这些低信息词汇的无谓计算等。我们在之前的专栏文章中有过讨论,在具体实现的时候最好参考Google的原文 Distributed Representations of Words and Phrases and their Compositionality
从word2vec到item2vec
在word2vec诞生之后,embedding的思想迅速从NLP领域扩散到几乎所有机器学习的领域,我们既然可以对一个序列中的词进行embedding,那自然可以对用户购买序列中的一个商品,用户观看序列中的一个电影进行embedding。而广告、推荐、搜索等领域用户数据的稀疏性几乎必然要求在构建DNN之前对user和item进行embedding后才能进行有效的训练。具体来讲,如果item存在于一个序列中,item2vec的方法与word2vec没有任何区别。而如果我们摒弃序列中item的空间关系,在原来的目标函数基础上,自然是不存在时间窗口的概念了,取而代之的是item set中两两之间的条件概率。
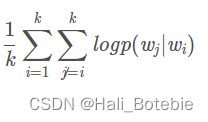
item2vec目标函数:大小为K的item set中两两item的log probability之和
具体可以参考item2vec的原文 Item2Vec:Neural Item Embedding for Collaborative Filtering
但embedding的应用又远不止于此,事实上,由于我们也可以把输出矩阵的列向量当作item embedding,这大大解放了我们可以用复杂网络生成embedding的能力。读过我专栏上一篇文章 YouTube深度学习推荐系统的十大工程问题的同学肯定知道,YouTube在serve其candidate generation model的时候,只将最后softmax层的输出矩阵的列向量当作item embedding vector,而将softmax之前一层的值当作user embedding vector。在线上serving时不用部署整个模型,而是只存储user vector和item vector,再用最近邻索引进行快速搜索,这无疑是非常实用的embedding工程经验,也证明了我们可以用复杂网络生成user和item的embedding。

YouTube的user和video embedding网络
也介绍了Airbnb的embedding最佳实践,下周我们再详细介绍Airbnb如何将业务场景与embedding方法结合起来。
讨论环节
又到了收获最大的问题讨论的环节了,希望所有人都能各抒己见,互通有无,相信之前专栏的讨论已经让所有读者获益。
- 为什么说深度学习的特点不适合处理特征过于稀疏的样本?
一方面,如果我们深入到神经网络的梯度下降学习过程就会发现,特征过于稀疏会导致整个网络的收敛非常慢,因为每一个样本的学习只有极少数的权重会得到更新,这在样本数量有限的情况下会导致模型不收敛。
另一个方面,One-hot 类稀疏特征的维度往往非常地大,可能会达到千万甚至亿的级别,如果直接连接进入深度学习网络,那整个模型的参数数量会非常庞大,这对于一般公司的算力开销都是吃不消的。
所以基于上面两个原因,我们往往先通过 Embedding 把原始稀疏特征稠密化,然后再输入复杂的深度学习网络进行训练,这相当于把原始特征向量跟上层复杂深度学习网络做一个隔离。
原文链接:https://blog.csdn.net/l491899327/article/details/110143463
我们能把输出矩阵中的权重向量当作词向量吗?
为什么在计算word similarity的时候,我们要用cosine distance,我们能够用其他距离吗?
在word2vec的目标函数中,两个词 w_i,w_j 的词向量 v_i,v_j 其实分别来自输入权重矩阵和输出权重矩阵,那么在实际使用时,我们需要分别存储输入矩阵和输出矩阵吗?还是直接用输入矩阵当作word2vec计算similarity就好了?
隐层的激活函数是什么?是sigmoid吗?
隐层的激活函数是为什么用线性函数?
更加简单;
承认都是线性关系,不用加非线性变换。
pytorch中nn.Embedding原理及使用
在PyTorch中,针对词向量有一个专门的层nn.Embedding,用来实现词与词向量的映射。
nn.Embedding具有一个权重(.weight),形状是(num_words, embedding_dim)。例如一共有10个词,每个词用2维向量表征,对应的权重就是一个10×2的矩阵。
Embedding的输入形状N×W,N是batch size,W是序列的长度,输出的形状是N×W×embedding_dim。
输入必须是LongTensor,FloatTensor需通过tensor.long()方法转成LongTensor。
Embedding的权重是可以训练的,既可以采用随机初始化,也可以采用预训练好的词向量初始化。
# coding:utf8
import torch as t
from torch import nn
if __name__ == '__main__':
embedding = nn.Embedding(10, 2) # 10个词,每个词用2维词向量表示
input = t.arange(0, 6).view(3, 2).long() # 3个句子,每句子有2个词
input = t.autograd.Variable(input)
output = embedding(input)
print(output.size())
print(embedding.weight.size())
pytorch中nn.Embedding原理及使用
torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None,
max_norm=None, norm_type=2.0, scale_grad_by_freq=False,
sparse=False, _weight=None)
其为一个简单的存储固定大小的词典的嵌入向量的查找表,意思就是说,给一个编号,嵌入层就能返回这个编号对应的嵌入向量,嵌入向量反映了各个编号代表的符号之间的语义关系。
输入为一个编号列表,输出为对应的符号嵌入向量列表。
参数解释
num_embeddings (python:int) – 词典的大小尺寸,比如总共出现5000个词,那就输入5000。此时index为(0-4999)
embedding_dim (python:int) – 嵌入向量的维度,即用多少维来表示一个符号。
padding_idx (python:int, optional) – 填充id,比如,输入长度为100,但是每次的句子长度并不一样,后面就需要用统一的数字填充,而这里就是指定这个数字,这样,网络在遇到填充id时,就不会计算其与其它符号的相关性。(初始化为0)
max_norm (python:float, optional) – 最大范数,如果嵌入向量的范数超过了这个界限,就要进行再归一化。
norm_type (python:float, optional) – 指定利用什么范数计算,并用于对比max_norm,默认为2范数。
scale_grad_by_freq (boolean, optional) – 根据单词在mini-batch中出现的频率,对梯度进行放缩。默认为False.
sparse (bool, optional) – 若为True,则与权重矩阵相关的梯度转变为稀疏张量。
下面是关于Embedding的使用
torch.nn包下的Embedding,作为训练的一层,随模型训练得到适合的词向量。
#建立词向量层
embed = torch.nn.Embedding(n_vocabulary,embedding_size)
找到对应的词向量放进网络:词向量的输入应该是什么样子
实际上,上面通过随机初始化建立了词向量层后,建立了一个“二维表”,存储了词典中每个词的词向量。每个mini-batch的训练,都要从词向量表找到mini-batch对应的单词的词向量作为RNN的输入放进网络。那么怎么把mini-batch中的每个句子的所有单词的词向量找出来放进网络呢,输入是什么样子,输出是什么样子?
首先我们知道肯定先要建立一个词典,建立词典的时候都会建立一个dict:word2id:存储单词到词典序号的映射。假设一个mini-batch如下所示:
['I am a boy.','How are you?','I am very lucky.']
显然,这个mini-batch有3个句子,即batch_size=3
第一步首先要做的是:将句子标准化,所谓标准化,指的是:大写转小写,标点分离,这部分很简单就略过。经处理后,mini-batch变为:
[['i','am','a','boy','.'],['how','are','you','?'],['i','am','very','lucky','.']]
可见,这个list的元素成了一个个list。还要做一步:将上面的三个list按单词数从多到少排列。标点也算单词。至于为什么,后面会说到。
那就变成了:
batch = [['i','am','a','boy','.'],['i','am','very','lucky','.'],['how','are','you','?']]
可见,每个句子的长度,即每个内层list的元素数为:5,5,4。这个长度也要记录。
lens = [5,5,4]
之后,为了能够处理,将batch的单词表示转为在词典中的index序号,这就是word2id的作用。转换过程很简单,假设转换之后的结果如下所示,当然这些序号是我编的。
batch = [[3,6,5,6,7],[6,4,7,9,5],[4,5,8,7]]
同时,每个句子结尾要加EOS,假设EOS在词典中的index是1。
batch = [[3,6,5,6,7,1],[6,4,7,9,5,1],[4,5,8,7,1]]
那么长度要更新:
lens = [6,6,5]
很显然,这个mini-batch中的句子长度不一致!所以为了规整的处理,对长度不足的句子,进行填充。填充PAD假设序号是2,填充之后为:
batch = [[3,6,5,6,7,1],[6,4,7,9,5,1],[4,5,8,7,1,2]]
就可以直接取词向量训练了吗?
不能!上面batch有3个样例,RNN的每一步要输入每个样例的一个单词,一次输入batch_size个样例,所以batch要按list外层是时间步数(即序列长度),list内层是batch_size排列。即batch的维度应该是:
[seq_len,batch_size]
[seq_len,batch_size]
[seq_len,batch_size]
重要的问题说3遍!
怎么变换呢?变换方法可以是:使用itertools模块的zip_longest函数。而且,使用这个函数,连填充这一步都可以省略,因为这个函数可以实现填充!
batch = list(itertools.zip_longest(batch,fillvalue=PAD))
# fillvalue就是要填充的值,强制转成list
经变换,结果应该是:
batch = [[3,6,4],[6,4,5],[5,7,8],[6,9,7],[7,5,1],[1,1,2]]
记得我们还记录了一个lens:
lens = [6,6,5]
batch还要转成LongTensor:
batch=torch.LongTensor(batch)
这里的batch就是词向量层的输入。
词向量层的输出是什么样的?
好了,现在使用建立了的embedding直接通过batch取词向量了,如:
embed_batch = embed (batch)
假设词向量维度是6,结果是:
tensor([[[-0.2699, 0.7401, -0.8000, 0.0472, 0.9032, -0.0902],
[-0.2675, 1.8021, 1.4966, 0.6988, 1.4770, 1.1235],
[ 0.1146, -0.8077, -1.4957, -1.5407, 0.3755, -0.6805]],
[[-0.2675, 1.8021, 1.4966, 0.6988, 1.4770, 1.1235],
[ 0.1146, -0.8077, -1.4957, -1.5407, 0.3755, -0.6805],
[-0.0387, 0.8401, 1.6871, 0.3057, -0.8248, -0.1326]],
[[-0.0387, 0.8401, 1.6871, 0.3057, -0.8248, -0.1326],
[-0.3745, -1.9178, -0.2928, 0.6510, 0.9621, -1.3871],
[-0.6739, 0.3931, 0.1464, 1.4965, -0.9210, -0.0995]],
[[-0.2675, 1.8021, 1.4966, 0.6988, 1.4770, 1.1235],
[-0.7411, 0.7948, -1.5864, 0.1176, 0.0789, -0.3376],
[-0.3745, -1.9178, -0.2928, 0.6510, 0.9621, -1.3871]],
[[-0.3745, -1.9178, -0.2928, 0.6510, 0.9621, -1.3871],
[-0.0387, 0.8401, 1.6871, 0.3057, -0.8248, -0.1326],
[ 0.2837, 0.5629, 1.0398, 2.0679, -1.0122, -0.2714]],
[[ 0.2837, 0.5629, 1.0398, 2.0679, -1.0122, -0.2714],
[ 0.2837, 0.5629, 1.0398, 2.0679, -1.0122, -0.2714],
[ 0.2242, -1.2474, 0.3882, 0.2814, -0.4796, 0.3732]]],
grad_fn=<EmbeddingBackward>)
维度的前两维和前面讲的是一致的。可见多了一个第三维,这就是词向量维度。所以,Embedding层的输出是:
[seq_len,batch_size,embedding_size]
一些注意的点
- nn.embedding的输入只能是编号,不能是隐藏变量,比如one-hot,或者其它,这种情况,可以自己建一个自定义维度的线性网络层,参数训练可以单独训练或者跟随整个网络一起训练(看实验需要)
- 如果你指定了padding_idx,注意这个padding_idx也是在num_embeddings尺寸内的,比如符号总共有500个,指定了padding_idx,那么num_embeddings应该为501
- embedding_dim的选择要注意,根据自己的符号数量,举个例子,如果你的词典尺寸是1024,那么极限压缩(用二进制表示)也需要10维,再考虑词性之间的相关性,怎么也要在15-20维左右,虽然embedding是用来降维的,但是>- 也要注意这种极限维度,结合实际情况,合理定义。二进制下每个维度都是 boolean 的,embedding 空间每个维度是实数。一个经验公式是embedding 空间维度 等于 vocabulary 大小 开四次方。
参考
https://blog.csdn.net/weixin_44493841/article/details/95341407
边栏推荐
- Open under vs2019 UI file QT designer flash back problem
- Yolov5进阶之九 目标追踪实例1
- QT - draw something else
- Yolov5系列(一)——网络可视化工具netron
- [opengl] bone animation blending effect
- Talking about part of data storage in C language
- [graphics] hair simulation in tressfx
- The latest M1 dedicated Au update Adobe audit CC 2021 Chinese direct installation version has solved the problems of M1 installation without flash back!
- C language STR function
- Devaxpress: range selection control rangecontrol uses
猜你喜欢
ASTC texture compression (adaptive scalable texture compression)
dllexport和dllimport
![[wechat applet] wxss template style](/img/28/f9d12bf761e25f9564d92697cf049d.png)
[wechat applet] wxss template style
![[ue4] geometry drawing pipeline](/img/30/9fcf83a665043fe57389d44c2e16a8.jpg)
[ue4] geometry drawing pipeline

Tonybot humanoid robot infrared remote control play 0630
4-29——4.32

C language fcntl function
Zero copy underlying analysis

Byte practice plane longitude 2

Série yolov5 (i) - - netron, un outil de visualisation de réseau
随机推荐
[opengl] face pinching system
C language dup2 function
My QT learning path -- how qdatetimeedit is empty
Open under vs2019 UI file QT designer flash back problem
Zzuli:1059 highest score
Yolov5进阶之八 高低版本格式转换问题
Tonybot humanoid robot infrared remote control play 0630
Composite type (custom type)
QT program font becomes larger on computers with different resolutions, overflowing controls
cpu飙升排查方法
Zzuli:1058 solving inequalities
How can entrepreneurial teams implement agile testing to improve quality and efficiency? Voice network developer entrepreneurship lecture Vol.03
406. Reconstruct the queue according to height
How does vs+qt set the software version copyright, obtain the software version and display the version number?
牛客 BM83 字符串變形(大小寫轉換,字符串反轉,字符串替換)
Some concepts about agile
ASTC texture compression (adaptive scalable texture compression)
Bucket sorting in C language
Rasterization: a practical implementation (2)
7-3 rental (20 points)