当前位置:网站首页>半监督之mixmatch
半监督之mixmatch
2022-07-02 06:26:00 【想搞钱的小陈】
自洽正则化:以前遇到标记数据太少,监督学习泛化能力差的时候,人们一般进行训练数据增广,比如对图像做随机平移,缩放,旋转,扭曲,剪切,改变亮度,饱和度,加噪声等。数据增广能产生无数的修改过的新图像,扩大训练数据集。自洽正则化的思路是,对未标记数据进行数据增广,产生的新数据输入分类器,预测结果应保持自洽。即同一个数据增广产生的样本,模型预测结果应保持一致。此规则被加入到损失函数中,有如下形式,
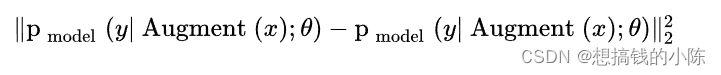
其中 x 是未标记数据,Augment(x) 表示对x做随机增广产生的新数据, θ 是模型参数,y 是模型预测结果。注意数据增广是随机操作,两个 Augment(x) 的输出不同。这个 L2 损失项,约束机器学习模型,对同一个图像做增广得到的所有新图像,作出自洽的预测。MixMatch 集成了自洽正则化。数据增广使用了对图像的随机左右翻转和剪切(Crop)。
第二种方案称作 最小化熵(Entropy Minimization)【5】。许多半监督学习方法都基于一个共识,即分类器的分类边界不应该穿过边际分布的高密度区域。具体做法就是强迫分类器对未标记数据作出低熵预测。实现方法是在损失函数中简单的增加一项,最小化 ![]() 对应的熵。
对应的熵。
MixMatch 使用 "sharpening" 函数,最小化未标记数据的熵。这一部分后面会介绍。
第三种方案称作传统正则化(Traditional Regularization)。为了让模型泛化能力更好,一般的做法对模型参数做 L2 正则化,SGD下L2正则化等价于Weight Decay。MixMaxtch 使用了 Adam 优化器,而之前有篇文章发现 Adam 和 L2 正则化同时使用会有问题,因此 MixMatch 从谏如流使用了单独的Weight decay。
最近发明的一种数据增广方法叫 Mixup 【6】,从训练数据中任意抽样两个样本,构造混合样本和混合标签,作为新的增广数据,
其中 lambda 是一个 0 到 1 之间的正数,代表两个样本的混合比例。MixMatch 将 Mixup 同时用在了标记数据和未标记数据中。
mixmatch的具体步骤:
- 使用 MixMatch 算法,对一个 Batch 的标记数据 x和一个 Batch 的未标记数据u 做数据增广,分别得到一个 Batch 的增广数据 x'和 K 个Batch的 u'。
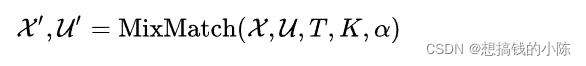
其中 T, K, 是超参数,后面会介绍。MixMatch 数据增广算法如下,

算法描述:for 循环对一个Batch的标记图片和未标记图片做数据增广。对标记图片,只做一次增广,标签不变,记为 p 。对未标记数据,做 K 次随机增广(文章中超参数K=2),输入分类器,得到平均分类概率,应用温度Sharpen 算法(T 是温度参数,此算法后面介绍),得到未标记数据的“猜测”标签 。此时增广后的标记数据 有一个Batch,增广后的未标记数据 有 K 个Batch。将 和 混合在一起,随机重排得到数据集 。最终 MixMatch 增广算法输出的,是将 与 做了MixUp() 的一个 Batch 的标记数据 ,以及 与 做了MixUp() 的 K 个Batch 的无标记增广数据.
. 对增广后的标记数据 x ,和无标记增广数据u 分别计算损失项,




边栏推荐
- Tencent machine test questions
- Interpretation of ernie1.0 and ernie2.0 papers
- 《Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer》论文翻译
- Win10 solves the problem that Internet Explorer cannot be installed
- Two dimensional array de duplication in PHP
- @Transational踩坑
- 华为机试题-20190417
- SSM二手交易网站
- 类加载器及双亲委派机制
- Oracle EBs and apex integrated login and principle analysis
猜你喜欢







随机推荐
MMDetection模型微调
Module not found: Error: Can't resolve './$$_gendir/app/app.module.ngfactory'
【Torch】解决tensor参数有梯度,weight不更新的若干思路
常见的机器学习相关评价指标
離線數倉和bi開發的實踐和思考
Agile development of software development pattern (scrum)
Practice and thinking of offline data warehouse and Bi development
《Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer》论文翻译
PHP returns the corresponding key value according to the value in the two-dimensional array
Faster-ILOD、maskrcnn_benchmark训练自己的voc数据集及问题汇总
parser.parse_args 布尔值类型将False解析为True
MySQL无order by的排序规则因素
[Bert, gpt+kg research] collection of papers on the integration of Pretrain model with knowledge
使用Matlab实现:Jacobi、Gauss-Seidel迭代
Transform the tree structure into array in PHP (flatten the tree structure and keep the sorting of upper and lower levels)
SSM二手交易网站
Mmdetection installation problem
中年人的认知科普
CRP implementation methodology
一个中年程序员学习中国近代史的小结