当前位置:网站首页>Interpretation of ernie1.0 and ernie2.0 papers
Interpretation of ernie1.0 and ernie2.0 papers
2022-07-02 07:22:00 【lwgkzl】
executive summary
This article mainly introduces Baidu's ERNIE1.0 Model and ERNIE2.0 Model .
1. ERNIE1.0 Enhanced Representation through Knowledge Integration
Motivation
BERT That kind of prediction is random mask The method ignores the entity information in the sentence and the relationship between entities ( That is, external knowledge ).
Model
 The training of the model is divided into three stages , Each stage uses different mask Strategy , Random respectively mask, Random mask Some phrases in the sentence , And random mask Entities in sentences . In the process of pre training , Make the model to predict the mask Dropped words , Phrases and entities to learn more comprehensive semantic information of sentences .
The training of the model is divided into three stages , Each stage uses different mask Strategy , Random respectively mask, Random mask Some phrases in the sentence , And random mask Entities in sentences . In the process of pre training , Make the model to predict the mask Dropped words , Phrases and entities to learn more comprehensive semantic information of sentences .
2. ERNIE2.0 A Continual Pre-Training Framework for Language Understanding
Motivation
The pre training task of previous pre training model modeling is based on the co-occurrence relationship between vocabulary and vocabulary . You can't learn words with complete sentences , Syntax and statement information . We can continue to mine a large number of pre training tasks to model this information , Such as the order of all sentences in the paragraph , Entities with special significance ( The person's name , Place names, etc ).
For a large number of pre training tasks , With multi-task Can't dynamically add new pre training tasks , Therefore, it is not flexible . And those who can dynamically add new tasks continue learning Every pre training task will have the problem of task forgetting .
This paper proposes a model framework to comprehensively solve the above two problems . And on the basis of this framework , Several pre training tasks are proposed to mine the vocabulary of sentences , Grammatical and semantic information .
Model

The focus of the whole framework is in the lower right corner , You can simply understand the four story pyramid in the lower right corner , First train the task 1 A quarter of the data , Then training tasks 1 A quarter of the data and tasks 2 One third of the data . The third training task 1 Of 1/4, Mission 2 Of 1/3 And the mission 3 Of 1/2 The data of . And so on , Finally, all the data can be trained , The model gradually increases tasks in an iterative way , Ensure that new tasks can be added dynamically , At the same time, the old tasks will not be forgotten , And it does not increase the amount of calculation .
Based on this framework , This paper has explored many new pre training tasks : They are the vocabulary sector , Grammatical structure level and semantic level .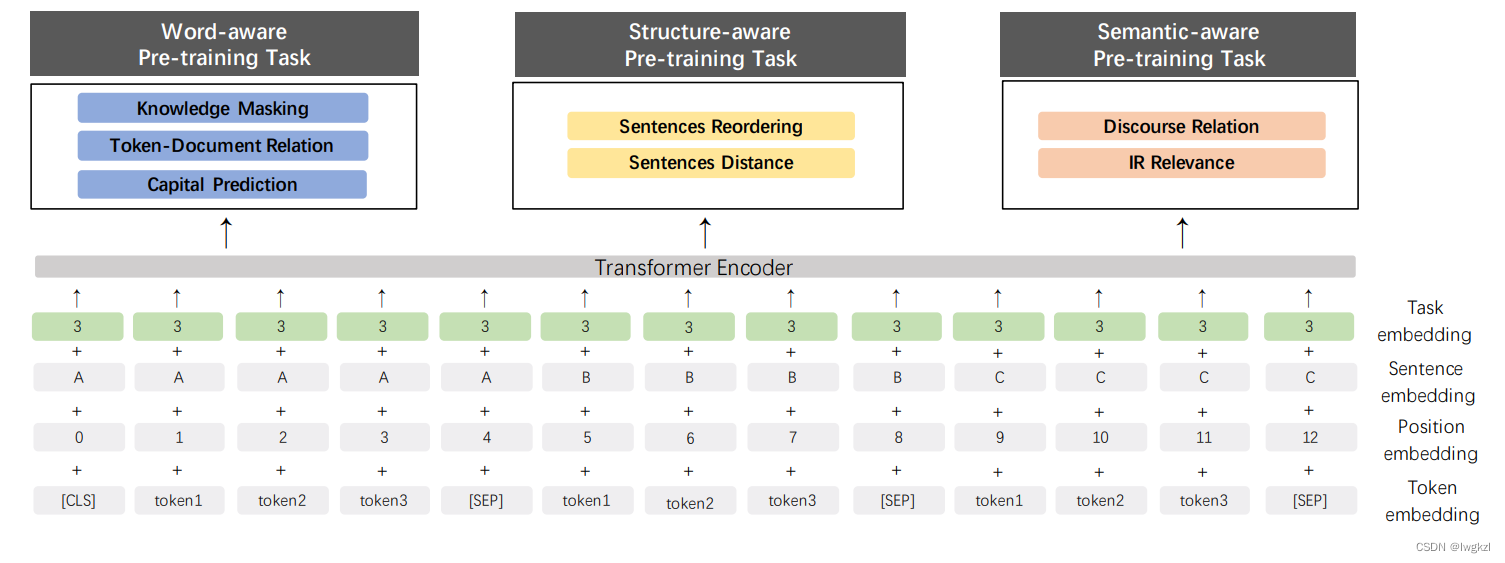
among
word-aware Of and ernie1.0 Their training objectives are basically the same , In addition, a prediction of capitalized words is added ( Predict whether a word is capitalized ), Because capitalized words usually have special meanings .
Structure-aware Your tasks are 1. Predict the relative position of all sentences in the paragraph 2. Judge whether the two sentences are in the same document .
Semantic-aware Your tasks are 1. Judge the relationship between entities ( Rough annotation with tools ) 2. Use user click data as weak supervision , Learn to ask about the relevance of documents ( If the user clicks, it is roughly counted as relevant )
ps
ERNIE2.0 The proposed framework has very practical significance in industry , Because it has good scalability , Can continue to learn , And more weak supervision or self supervision information can be mined .
BTW, ERNIE2.0 The summary of is hard to say ummm
边栏推荐
- 【Ranking】Pre-trained Language Model based Ranking in Baidu Search
- SSM garbage classification management system
- 矩阵的Jordan分解实例
- SSM second hand trading website
- Sqli-labs customs clearance (less1)
- [Bert, gpt+kg research] collection of papers on the integration of Pretrain model with knowledge
- Implementation of purchase, sales and inventory system with ssm+mysql
- Write a thread pool by hand, and take you to learn the implementation principle of ThreadPoolExecutor thread pool
- view的绘制机制(二)
- view的绘制机制(一)
猜你喜欢

Take you to master the formatter of visual studio code

SSM supermarket order management system

第一个快应用(quickapp)demo

外币记账及重估总账余额表变化(下)
中年人的认知科普

ORACLE EBS 和 APEX 集成登录及原理分析
Only the background of famous universities and factories can programmers have a way out? Netizen: two, big factory background is OK
Spark SQL task performance optimization (basic)
TCP攻击
【信息检索导论】第二章 词项词典与倒排记录表
随机推荐
使用Matlab实现:弦截法、二分法、CG法,求零点、解方程
[medical] participants to medical ontologies: Content Selection for Clinical Abstract Summarization
Sqli-labs customs clearance (less1)
ORACLE 11G利用 ORDS+pljson来实现json_table 效果
Sparksql data skew
SSM second hand trading website
Changes in foreign currency bookkeeping and revaluation general ledger balance table (Part 2)
Typeerror in allenlp: object of type tensor is not JSON serializable error
Classloader and parental delegation mechanism
Delete the contents under the specified folder in PHP
SSM garbage classification management system
view的绘制机制(二)
Three principles of architecture design
叮咚,Redis OM对象映射框架来了
矩阵的Jordan分解实例
Laravel8中的find_in_set、upsert的使用方法
allennlp 中的TypeError: Object of type Tensor is not JSON serializable错误
Sqli labs customs clearance summary-page2
Oracle segment advisor, how to deal with row link row migration, reduce high water level
Oracle RMAN automatic recovery script (migration of production data to test)