当前位置:网站首页>【Ranking】Pre-trained Language Model based Ranking in Baidu Search
【Ranking】Pre-trained Language Model based Ranking in Baidu Search
2022-07-02 06:25:00 【lwgkzl】
总述
这篇文章重点在解决以下几个问题:
- 现有的预训练语言模型由于处理长文本对时间和计算资源的高需求使得其无法应用于online ranking system,因为网络文本通常比较长。
- 现有的预训练范式,如随机mask词汇,下一轮句子预测等,都有Rank任务没有关系,因此会忽略文本中的相关性,从而减弱其在ad-hoc 检索中的效果。
- 在真实的信息检索系统中,Ranking 模块通常需要与其他模块结合起来使用,如何使得ranking 模块能够更好的兼容检索系统的其他模块也是一个值得探索的问题。
针对以上问题,该论文给出了具体的解决方案。
针对第一个问题,即长文本处理问题。
该文首先提出了一种快速抽取长文本摘要的方法,然后使用摘要来代替原文本的内容,从而减小了文本的长度。其次,该文提出一种Pyramid-ERNIE的结构,能一定程度上减少query与摘要之间交互的时间复杂度。
针对第二个问题,即普通的预训练任务无法建模文本间的相关系,对于web检索而言,尤其是query与document的相关性。该文使用百度搜索的query和用户点击数据作为弱监督信号进行训练。并且介绍了如何使用一些去噪的方法来建立高质量的用户点击数据集对ENRIE进行预训练。
针对第三个问题,即ranking模块与系统其他模块的兼容性。该文使用人类标注的数据再次进行fine-tuning,争取系统与人类的相关性评分保持一致性,使得系统具备有更好的可解释性以及与其他模块的兼容性(其他模块也需要与人类的标注保持一致)
具体的方法介绍如下:
具体方法介绍
- 一种快速的摘要提取算法

提出这种算法的原因是: 由于web document太长,之前的工作可能均只使用document的title作为document的信息,但是title对document的信息总结的过于抽象,会损失大量的文本信息。因此需要想办法把document的关键信息抽取出来。
大概总结一下这个算法就是: 为每个词设置权重,然后根据query和已选择的句子中与候选句子(文档中的句子)的公共词汇权重和,决定该候选句子的分数。每次选择分数最大的候选句子加入摘要中。并且选择完句子后,会动态的更新词的权重,使得选择的句子覆盖更多的词汇。 根据选取句子的数量可以动态的权衡最终摘要的长度。
具体细节可看算法伪代码。
2. Pyramid-ERNIE的结构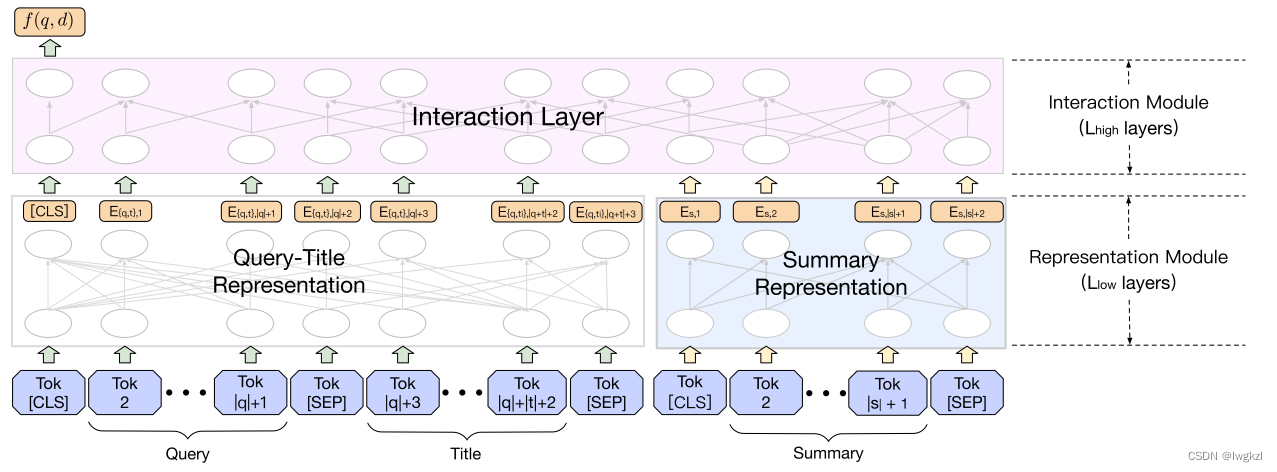
Pyramid-ERNIE的结构相对比较直观,是经典的双塔架构,左侧输入为query+标题的结合,右侧输入为抽取的文档摘要。和大多数双塔模型一样,左右两个分支分别提取完特征之后,进入交互层进行交互。
与直接拼接query,标题和摘要然后输入到ERNIE中比较而言,双塔模型的建立具有更优的时间复杂度(减低了单次输入的句子长度)。
分析:(个人见解)
如果左侧的输入是query,而右侧的输入是标题+摘要的话,整个模型的线上效率会提升很多,因为在应用中,可以预处理所有摘要的的特征提取部分,在线上时,只需要处理query部分,然后对应做特征交互即可。
不过后续有实验证明标题应该和query一起放到左侧效果会更好。而且,本文应用在Ranking阶段,故document的数量相对较少,因此这样处理在时间上应该也可以接受。
3. 使用用户点击数据进行预训练
为了建模文本相关性的预训练任务,一种直观的解决方案就是使用真实场景下的用户点击数据来做弱监督信号进行预训练。然而这种直接的做法会存在一些问题:
a. 收集的用户点击数据中会存在假阳性问题(用户误点)
b. 曝光性偏差,已有系统排行在前几页的document会收获更多的点击,而排名靠后的不会获得点击,因此无法获取靠后文档的标签。而在真实上线的时候,有可能用户就需要当前排名靠后的文档(没有伪标签,因此也没有被模型训练),这样会造成线上线下的性能差异。
c. 点击信号并不能完全代表相关性,可能用户对某个检索出来的网页产生了新的兴趣。因此朴素的用户点击与文本相关性并不能划等号。
有问题便会存在解决方案:
针对问题a, 该文利用了一些经验主义的指标,如网页浏览时长,滚动速度等评价是否为误点。
针对问题b, 该文利用#click/#skip的比值来解决(这一点不太明白)
针对问题c, 该文人工标注了一个相关性数据集,并且基于该数据集,以及前面提取的人工特征,训练了一个树模型来对大量无标注的用户点击数据进行筛选。具体树模型如下图所示:
最终,预训练任务为(g(x)为树模型预测的标签):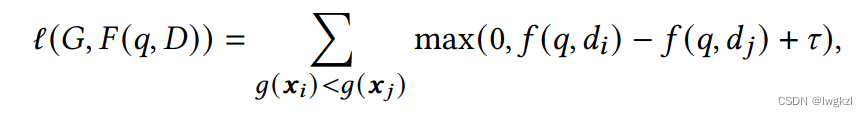
.
4. 使用人类标注数据进行Fine-Tuning
原因:
a. ranking model需要和检索系统的其他模块(权威性,新鲜性等)保持一致性,不能只用点击数据预训练相关性。
b. 只使用pairwise的loss来训练模型会有很大的query分布的方差(高频的询问可以训练得到很多相关文档,而低频询问因为较少得到训练,因此不能很好的找到相关文档)
c. pairwise的训练注重训练相对的相关性,而忽略了query与文档之间真实的相关性,因此rank model的打分是缺乏实际意义的。
为了解决以上三个问题,该文还是选择人工标注了一个大规模的相关性数据集,并且在Pyramid-ERNIE Fine-tuning的时候,加上了预测真实标签的point-loss。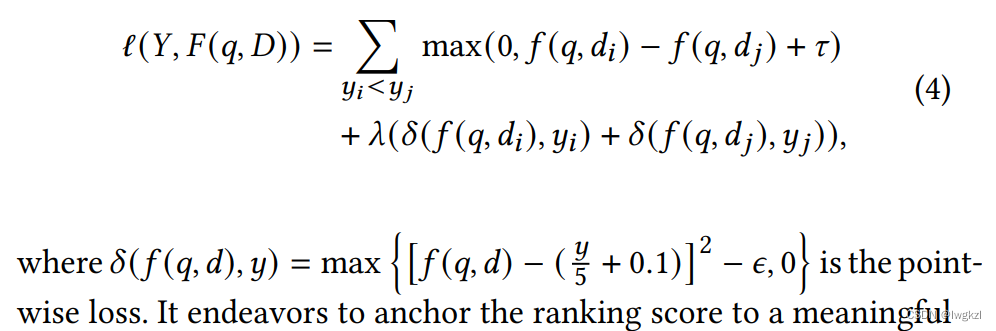
边栏推荐
- ORACLE 11G利用 ORDS+pljson来实现json_table 效果
- 2021-07-19C#CAD二次开发创建多线段
- How to call WebService in PHP development environment?
- @Transational踩坑
- pm2简单使用和守护进程
- PM2 simple use and daemon
- Network security -- intrusion detection of emergency response
- 中年人的认知科普
- Module not found: Error: Can't resolve './$$_ gendir/app/app. module. ngfactory'
- 外币记账及重估总账余额表变化(下)
猜你喜欢

Wechat applet Foundation

sparksql数据倾斜那些事儿
Only the background of famous universities and factories can programmers have a way out? Netizen: two, big factory background is OK

ORACLE 11G利用 ORDS+pljson来实现json_table 效果

Proteus -- RS-232 dual computer communication

The first quickapp demo
TCP attack

UEditor . Net version arbitrary file upload vulnerability recurrence
MySQL无order by的排序规则因素
2021-07-05C#/CAD二次开发创建圆弧(4)
随机推荐
php中删除指定文件夹下的内容
php中通过集合collect的方法来实现把某个值插入到数组中指定的位置
Sqli labs customs clearance summary-page4
Oracle apex 21.2 installation and one click deployment
Build FRP for intranet penetration
腾讯机试题
Oracle RMAN automatic recovery script (migration of production data to test)
Oracle EBS DataGuard setup
Yaml file of ingress controller 0.47.0
Laravel8中的find_in_set、upsert的使用方法
Flex Jiugongge layout
2021-07-17C#/CAD二次开发创建圆(5)
RMAN incremental recovery example (1) - without unbacked archive logs
Explanation of suffix of Oracle EBS standard table
pySpark构建临时表报错
Uniapp introduces local fonts
外币记账及重估总账余额表变化(下)
@Transational踩坑
ssm+mysql实现进销存系统
SQLI-LABS通关(less2-less5)