当前位置:网站首页>Sparksql data skew
Sparksql data skew
2022-07-02 07:19:00 【Software development heart】
Tips : When the article is finished , Directories can be generated automatically , How to generate it, please refer to the help document on the right
List of articles
- Preface
- One 、 What is data skew ?
- Two 、 The phenomenon of data skew
- 3、 ... and 、 Data skew generation principle
- Four 、 Data skew generation scenario
- 5、 ... and 、 The harm of data skew
- 6、 ... and 、 Data skew solution
- 1、 Filtering a few causes tilting key
- 2、 adjustment shuffle Parallelism of operations
- 3、 Little watch broadcast
- 4、 Use random numbers and double aggregation
- 5、 tilt key Increase random numbers for independent join
- 6、 Tilt table random number and expansion table join
- 7、SparkSQL Adaptive partitioning
- 8、 Use Hive ETL Preprocessing data , Process in the predecessor task or table .
- summary
Preface
Yes Hadoop Spark Flink In terms of such a big data system , Large amount of data is not terrible , The scary thing is data skew .
One 、 What is data skew ?
What is data skew ? Data skew means , Data sets for parallel processing , A certain task The amount of data or time processed is significantly more than other parts , Thus, the processing speed of this part becomes the bottleneck of the whole task processing . Simply put, data skew is key The differentiation of is seriously uneven .
Two 、 The phenomenon of data skew
1、 most task It's very fast , But individually task Very slow execution . such as , All in all 1000 individual task,997 individual task All in 1 It's done in minutes , But there are two or three left task want 5 times ,10 times , Even give more time to complete . This is very common .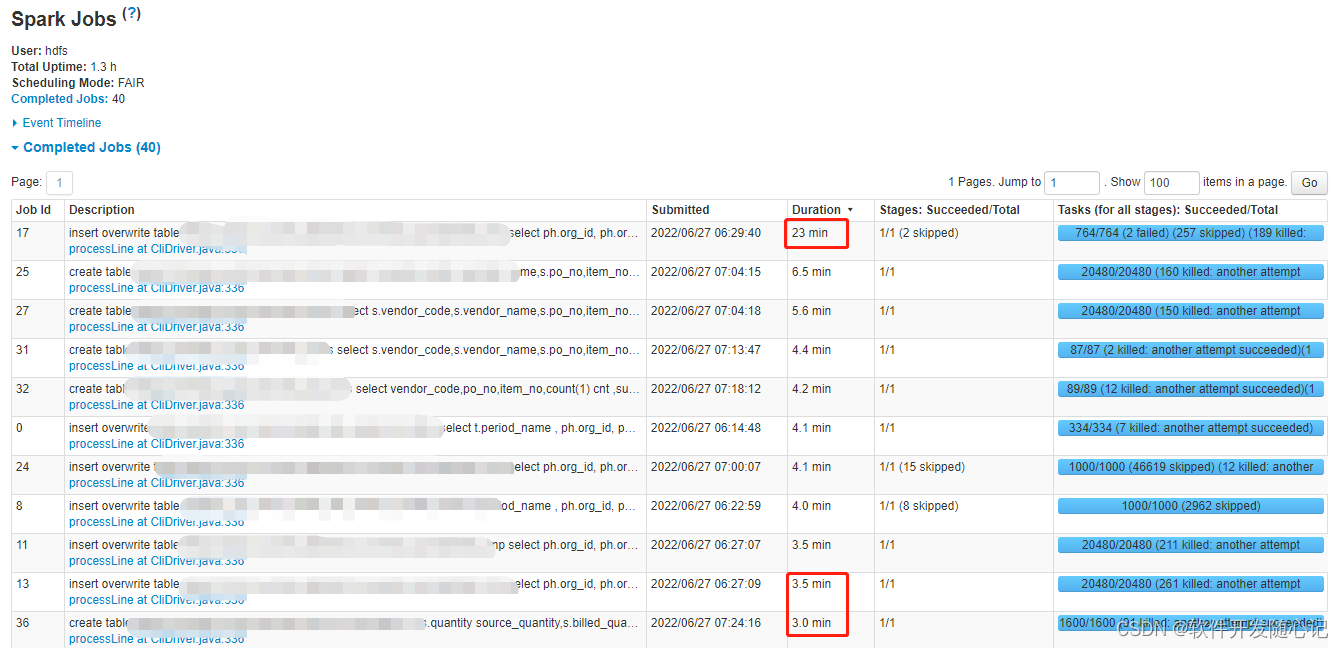
2、 What could have been performed normally Spark Homework , One day suddenly reported OOM( out of memory ) abnormal , Observe the exception stack , It's the business code we wrote that caused . This is rare .
3、 ... and 、 Data skew generation principle
It's going on shuffle When , You must set the same... On each node key Pull to a node task To process , For example, according to key To aggregate or join Wait for the operation . At this point, if some key If the corresponding amount of data is very large , Data skew happens . For example, most of key Corresponding 10 Data , But individually key But it corresponds to 100 Ten thousand data , So most of it task Maybe it will only be allocated to 10 Data , then 1 In seconds ; But individually task May have been assigned to 100 All the data , It's going to run for an hour or two . therefore , Whole Spark The running progress of the job is determined by the one with the longest running time task Decisive .
So when data skews ,Spark Jobs seem to run very slowly , Maybe even because of some task The amount of data processed is too large, resulting in memory overflow .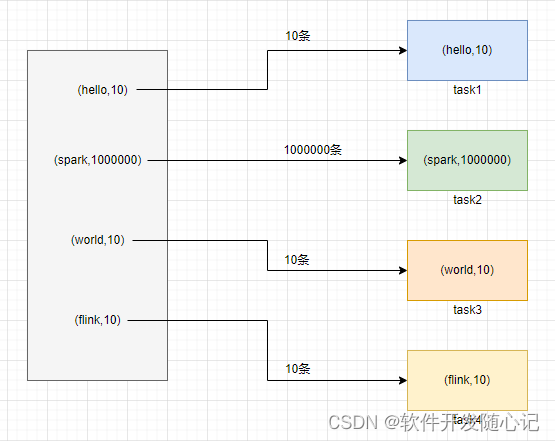
Four 、 Data skew generation scenario
It is mainly divided into 3 class :
1、shuffle tilt :
Generally by shuffle Operators cause , for example :count ,distinct ,avg ,min, max etc. aggregation Operation and join tilt ( Five big Join ).
stay spark UI You can see the whole assignment on (action/application) all stage in Duration Value is the largest , And there are Shuffle Read, No, Input.
2、 Reading tilt :
The source data is skewed ( Especially the same key Lots of scenes ), Plus columnar storage ( same key Store only once ).
stay spark UI You can see the whole assignment on (action/application) all stage in Duration Value is the largest , And there are Input, No, Shuffle Read.
3、 Write slant :
commonly distribute by perhaps partition over perhaps reparation Small perhaps Low concurrency In the end, there are only a few task Production data file .
5、 ... and 、 The harm of data skew
1、 The overall time consumption is too large ( The whole task is completed by the one with the longest execution time Task decision )
2、 The application may exit abnormally ( Some Task The amount of data processed during execution is much larger than that of normal nodes , Then the required resources are prone to bottlenecks , When resources are insufficient , The application exits )
3、 Idle resources ( Handle waiting state Task Resources are not released in time , In a state of idleness and waste )
6、 ... and 、 Data skew solution
1、 Filtering a few causes tilting key
2、 adjustment shuffle Parallelism of operations
set spark.sql.shuffle.partitions=1600;// Default 200, Can press 200、400、800、1600、3200… increase
3、 Little watch broadcast
Force to add broadcast hint grammar , namely /*+ broadcast( Small table alias ) */, take sortmergejoin Convert to broadcastjoin
4、 Use random numbers and double aggregation
Original aggregation SQL Logic
select id,count(1) from tbl group by id ;
Change to
Now aggregate SQL Logic
SELECT split(t2.new_id,'_')[0] AS id,sum(t2.cnt) AS cnt
FROM
(SELECT t1.new_id ,
count(1) AS cnt
FROM
(SELECT id,
value,
concat(id,
'_',cast(rand()*10000 as int)%3) AS new_id
FROM tbl) t1
GROUP BY new_id ) t2
GROUP BY split(t2.new_id,'_')[0];
5、 tilt key Increase random numbers for independent join
1. Adaptive scene : Two tables join, All big watches , Can't use broadcast Join, But tilt key Not much . One of them RDD There are a few Key Too much data , Another one RDD Of Key Well distributed .
2. solve : First split the tilt of the tilt table key, Add random numbers to form a temporary table a1, Other non inclined parts of the tilt table form a temporary a2 surface ; Filter skew for non skew tables key, The expansion forms a temporary table b1, Non tilt table non tilt key formation b2 then a1 and b1 Conduct join( Remove random numbers at the same time ),a2 and b2 Conduct join, Final merger .
The original SQL Logic
select t1.id,t2.value from t1 join t2 on t1.id=t2.id where t1.dt=20191001 ;
Change to
After optimization SQL Logic
2 individual join One union Replace the original join
-- Inclined part
select split(a.id,'_')[0],split(b.id,'_')[0],a.value,b.value from
(select concat(t1.id,'_',cast(rand()*10000 as int)%3) AS id,t2.value from t1 where t1.id in (' tilt id list ')) a
join
( SELECT id, value,concat(id,'_',suffix) AS id FROM
(SELECT id, value , suffix FROM t2 Lateral View explode(array(0,1,2)) tmp AS suffix where t2.id in (' tilt id list ')) tt
) b
on a.id=b.id
union all -- Finally, merge the tilted and non tilted parts
-- Non inclined part
select t1.id,t2.value from t1
join t2
on t1.id=t2.id
where t1.dt='20191001' and t1.id not in (' tilt id list ') and t2.id not in (' tilt id list '); // Non tilt key
6、 Tilt table random number and expansion table join
1. scene : Two tables join, They are all big watches But there is a skew in the data of one table Key More , The other dataset is more evenly distributed .
2. solve : All the data of the tilt table are scattered , The capacity of the non tilt meter is expanded , then join, Remove the prefix .
original A Logical modification of the table :
select id,value from A
Change to
select id,value,concat(id,'_',cast(rand()*10000 as int)%3) as new_id from A
original B Logical modification of the table :
select id,value from B
Change to
select id,value,concat(id,'_',suffix) as new_id
from (
select id,value ,suffix
from B Lateral View explode(array(0,1,2)) tmp as suffix
)
Join Logic modification ==
select a.id, count(1) from
A a join B b
on a.id=b.id
Change to
SELECT split(c.new_id,'_')[0] AS id, sum(cnt) AS cnt
FROM
(SELECT a.new_id,count(1) AS cnt
FROM
(SELECT id,value,concat(id,'_',cast(rand()*10000 as int )%3) AS new_id FROM t1) a
JOIN
( SELECT id, value,concat(id,'_',suffix) AS new_id FROM (SELECT id, value , suffix FROM t2 Lateral View explode(array(0,1,2)) tmp AS suffix ) tt ) b
ON a.new_id=b.new_id
) c
GROUP BY split(c.new_id,'_')[0]
7、SparkSQL Adaptive partitioning
Turn on adaptive zoning
set spark.sql.adaptive.enabled = true;
Turn on automatic processing tilt
set spark.sql.adaptive.skewJoin.enabled = true;
Tilt factor
set spark.sql.adaptive.skewJoin.skewedPartitionFactor =5;
8、 Use Hive ETL Preprocessing data , Process in the predecessor task or table .
summary
The optimization item is to keep trying , Continuous debugging , Then we can get a feasible , Effective methods .
vicente.liu 2022-06-27
notes : This article quotes other articles and pictures , If there is any infringement , Please send me a private message , Then delete .
边栏推荐
- 【Torch】解决tensor参数有梯度,weight不更新的若干思路
- 【信息检索导论】第七章搜索系统中的评分计算
- 2021-07-05c /cad secondary development create arc (4)
- Two table Association of pyspark in idea2020 (field names are the same)
- CAD二次开发 对象
- IDEA2020中测试PySpark的运行出错
- Oracle general ledger balance table GL for foreign currency bookkeeping_ Balance change (Part 1)
- ssm超市订单管理系统
- Go common compilation fails
- 图解Kubernetes中的etcd的访问
猜你喜欢

Oracle EBs and apex integrated login and principle analysis
Sqli-labs customs clearance (less15-less17)

Yaml file of ingress controller 0.47.0

@Transational踩坑

mapreduce概念和案例(尚硅谷学习笔记)

ORACLE 11G利用 ORDS+pljson来实现json_table 效果

JSP intelligent community property management system
Agile development of software development pattern (scrum)

Oracle EBS database monitoring -zabbix+zabbix-agent2+orabbix

【信息检索导论】第三章 容错式检索
随机推荐
Conda 创建,复制,分享虚拟环境
Error in running test pyspark in idea2020
view的绘制机制(一)
2021-07-19C#CAD二次开发创建多线段
Module not found: Error: Can't resolve './$$_gendir/app/app.module.ngfactory'
搭建frp进行内网穿透
2021-07-17c /cad secondary development creation circle (5)
CSRF攻击
图解Kubernetes中的etcd的访问
Sqli labs customs clearance summary-page2
oracle-外币记账时总账余额表gl_balance变化(上)
Oracle segment advisor, how to deal with row link row migration, reduce high water level
ORACLE APEX 21.2安装及一键部署
腾讯机试题
【信息检索导论】第二章 词项词典与倒排记录表
Oracle apex 21.2 installation and one click deployment
php中生成随机的6位邀请码
SQL injection closure judgment
SSM二手交易网站
Sqli-labs customs clearance (less2-less5)