当前位置:网站首页>Two table Association of pyspark in idea2020 (field names are the same)
Two table Association of pyspark in idea2020 (field names are the same)
2022-07-02 07:13:00 【wuzd】
Preface
Use GROUPLENS The big data set of film evaluation ,Windows in IDEA2020 Environment SPARK Do two table correlation test to learn .
Individual users learn big data , Generally, it will be built based on Linux The virtual machine HDFS colony . and SPARK It mainly runs in memory , If it runs in the memory of the virtual machine, it is not in Windows It is efficient to run directly in . So suggest SPARK Your learning lies in Windows It's in . If you want to in Linux function , The written program can also be modified ( Mainly SparkSession And the path of the read file ) And then in Linux The virtual machine HDFS Running on a cluster .
One 、 Project environment
Windows: IDEA2020
JDK: java version 1.8.0_231
Python: 3.8.3
Spark:spark-3.2.1-bin-hadoop2.7.tgz
Two 、 Movie reviews Big data set download
1. Download address
http://files.grouplens.org/datasets/movielens/

2. Used in the test CSV Data files
2.1 The movie name movies.csv( Example ):
movieId,title,genres
1,Toy Story (1995),Adventure|Animation|Children|Comedy|Fantasy
2,Jumanji (1995),Adventure|Children|Fantasy
3,Grumpier Old Men (1995),Comedy|Romance
4,Waiting to Exhale (1995),Comedy|Drama|Romance
5,Father of the Bride Part II (1995),Comedy2.2 Movie reviews ratings.csv( Example ):
userId,movieId,rating,timestamp
1,1,4.0,964982703
1,3,4.0,964981247
1,6,4.0,964982224
1,47,5.0,964983815
1,50,5.0,9649829313、 ... and 、 stay IDEA of use Python To write
1. Import and stock in
# coding:utf8
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType,StringType,IntegerType,DoubleType
from pyspark.sql import functions as F2. establish SparkSession Execution environment entry
if __name__ == '__main__':
# structure SparkSession Execution environment entry object
spark = SparkSession.builder.appName("test").master("local[*]").getOrCreate()
# adopt SparkSession Object acquisition SparkContext object
sc = spark.sparkContext3. Read movie reviews ratings.csv Data sets , establish DataFrame
# todo 1: Read movie reviews ratings.csv Data sets
# Defining structure 1
# userId,movieId,rating,timestamp
schemaRank = StructType().add("userId", StringType(), nullable=True).\
add("movieId",IntegerType(),nullable=True). \
add("rating",DoubleType(),nullable=True). \
add("timestamp",StringType(),nullable=True)
# use , Split read CSV file 1
dfRank = spark.read.format("csv").option("sep", ",").\
option("header",True).\
option("encoding","utf-8").\
schema(schema=schemaRank).\
load("../data/input/ratings.csv")
# Sample file content
# userId,movieId,rating,timestamp
# 1,1,4.0,964982703
# 1,3,4.0,964981247
# 1,6,4.0,964982224
# 1,47,5.0,9649838154. Read the movie name movies.csv Data sets , establish DataFrame
# Defining structure 2
# movieId,title,genres
schemaMovie = StructType().add("movieId",IntegerType(),nullable=True). \
add("title", StringType(), nullable=True). \
add("genres", StringType(), nullable=True)
# use , Split read CSV file 2
dfMovie = spark.read.format("csv").option("sep", ","). \
option("header",True). \
option("encoding","utf-8"). \
schema(schema=schemaMovie). \
load("../data/input/movies.csv")
# Sample file content
# movieId,title,genres
# 1,Toy Story (1995),Adventure|Animation|Children|Comedy|Fantasy
# 2,Jumanji (1995),Adventure|Children|Fantasy
# 3,Grumpier Old Men (1995),Comedy|Romance5. Use the movie title DataFrame, Build table movies surface
dfMovie.createOrReplaceTempView("movies")
# verification movies Table content
spark.sql("SELECT movieId,title,genres FROM movies").show()
# Example of query results
# +-------+--------------------+--------------------+
# |movieId| title| genres|
# +-------+--------------------+--------------------+
# | 1| Toy Story (1995)|Adventure|Animati...|
# | 2| Jumanji (1995)|Adventure|Childre...|
# | 3|Grumpier Old Men ...| Comedy|Romance|6. Inquire about Evaluation times exceed 100 Second movie , Average score ranking Top10 Of DataFrame
# todo 3 Inquire about Evaluation times exceed 100 Second movie , Average score ranking Top10
print(" Inquire about Evaluation times exceed 100 Second movie , Average score ranking Top10 ")
dfRank2 = dfRank.groupBy("movieId").agg(
F.count("movieId").alias("cnt"),
F.round(F.avg("rating"),2).alias("avgRank")
).where("cnt >100").\
orderBy("avgRank",ascending=False).\
limit(10)
dfRank2.show()
# Example of query results
# +-------+---+-------+
# |movieId|cnt|avgRank|
# +-------+---+-------+
# | 318|317| 4.43|
# | 858|192| 4.29|
# | 2959|218| 4.27|
# todo Evaluate with movies , Build table ranks
dfRank2.createOrReplaceTempView("ranks")7. Two dataframe relation , Take the title of the movie
# todo 4 Two dataframe relation , Take the title of the movie
dfRank2.join(dfMovie, "movieId", "inner").createOrReplaceTempView("movieRankTable")
print("DataFrame style front 10 Movie name ")
# todo The field contents are all displayed show(10,False)
spark.sql("SELECT movieId,title,avgRank,genres "
"FROM movieRankTable ").show(10,False)
# Example of query results
# +-------+--------------------------------+-------+---------------------------------------+
# |movieId|title |avgRank|genres |
# +-------+--------------------------------+-------+---------------------------------------+
# |50 |Usual Suspects, The (1995) |4.24 |Crime|Mystery|Thriller |
8. The two tables are linked , Take the title of the movie
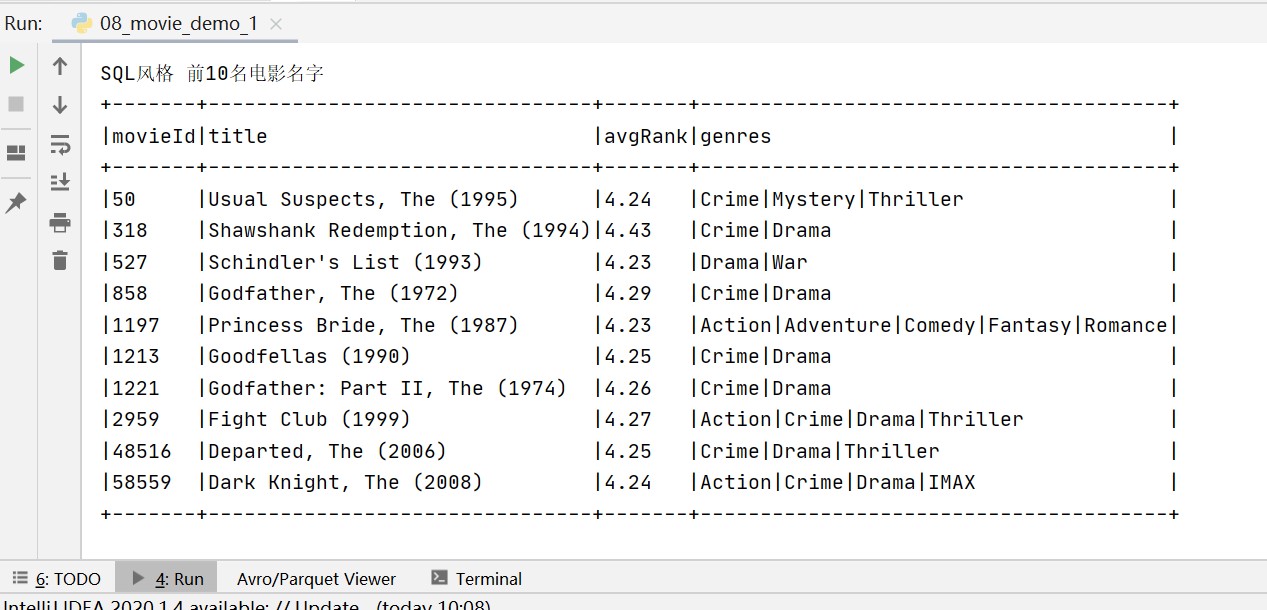
print("SQL style front 10 Movie name ")
spark.sql("SELECT r.movieId,m.title,r.avgRank,m.genres "
" FROM movies m,ranks r"
" WHERE m.movieId =r.movieId").show(10,False)
# Example of query results
# +-------+--------------------------------+-------+---------------------------------------+
# |movieId|title |avgRank|genres |
# +-------+--------------------------------+-------+---------------------------------------+
# |50 |Usual Suspects, The (1995) |4.24 |Crime|Mystery|Thriller |
# |318 |Shawshank Redemption, The (1994)|4.43 |Crime|Drama |
# |527 |Schindler's List (1993) |4.23 |Drama|War |Four 、 Running results
5、 ... and . Problems encountered
Two dataframe After correlation , Duplicate columns appear , Same field , When you pull it out, you make a mistake
pyspark.sql.utils.AnalysisException: Reference 'movieId' is ambiguous, # could be: movieranktable.movieId, movieranktable.movieId.; line 1 pos 7
pyspark.sql.utils.AnalysisException: Reference 'movieId' is ambiguous,could be: movieranktable.movieId, movieranktable.movieId.; line 1 pos 7countermeasures :join(dfMovie,"movieId","inner") The way
# @ The wrong way to write : dfRank2.join(dfMovie, dfRank2.movieId == dfMovie.movieId).createOrReplaceTempView("movieRankTable")
# @ Correct writing : dfRank2.join(dfMovie, "movieId", "inner").createOrReplaceTempView("movieRankTable")
边栏推荐
猜你喜欢







随机推荐
2021-07-19c CAD secondary development creates multiple line segments
Explanation of suffix of Oracle EBS standard table
php中判断版本号是否连续
SSM二手交易网站
Take you to master the formatter of visual studio code
TCP攻击
IDEA2020中测试PySpark的运行出错
JSP intelligent community property management system
读《敏捷整洁之道:回归本源》后感
2021-07-05c /cad secondary development create arc (4)
DNS attack details
Oracle rman半自动恢复脚本-restore阶段
Brief analysis of PHP session principle
Ceaspectuss shipping company shipping artificial intelligence products, anytime, anywhere container inspection and reporting to achieve cloud yard, shipping company intelligent digital container contr
ORACLE EBS接口开发-json格式数据快捷生成
User login function: simple but difficult
Oracle EBS DataGuard setup
Pyspark build temporary report error
@Transational踩坑
PM2 simple use and daemon