当前位置:网站首页>Spark学习(3)-Spark环境搭建-Standalone
Spark学习(3)-Spark环境搭建-Standalone
2022-07-31 14:06:00 【-------江湖-------】
1 Standalone 架构
Standalone模式是Spark自带的一种集群模式,不同于前面本地模式启动多个进程来模拟集群的环境,Standalone模式是真实地在多个机器之间搭建Spark集群的环境,完全可以利用该模式搭建多机器集群,用于实际的大数据处理。
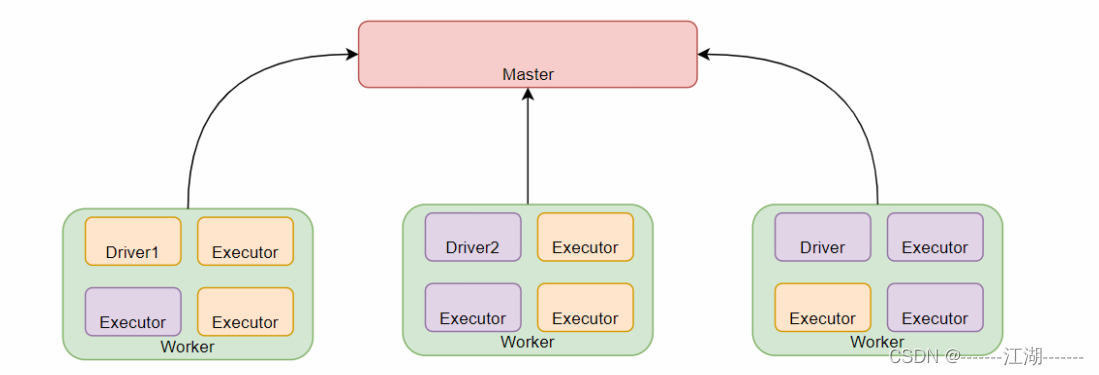
StandAlone是完整的Spark运行环境,其中:Master角色以Master进程存在, Worker角色以Worker进程存在,Driver和Executor运行于Worker进程内, 由Worker提供资源供给它们运行。
StandAlone集群在进程上主要有3类进程:
- 主节点Master进程:
- Master角色, 管理整个集群资源,并托管运行各个任务的Driver。
- 从节点Workers:
- Worker角色, 管理每个机器的资源,分配对应的资源来运行Executor(Task); 每个从节点分配资源信息给Worker管理,资源信息包含内存Memory和CPU Cores核数。
- 历史服务器HistoryServer(可选):
- Spark Application运行完成以后,保存事件日志数据至HDFS,启动HistoryServer可以查看应用运行相关信息。
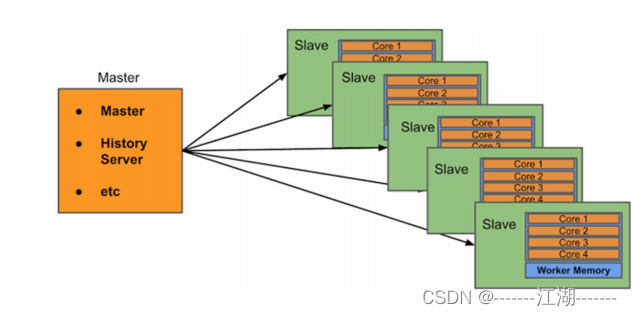
- Spark Application运行完成以后,保存事件日志数据至HDFS,启动HistoryServer可以查看应用运行相关信息。
2 Standalone环境安装操作
2.1 集群规划
使用三台Linux虚拟机来组成集群环境, 分别是:
node1\ node2\ node3
node1运行: Spark的Master进程 和 1个Worker进程
node2运行: spark的1个worker进程
node3运行: spark的1个worker进程
整个集群提供: 1个master进程 和 3个worker进程
2.2 在所有机器安装Python(Anaconda)
同时不要忘记 都创建pyspark虚拟环境,以及安装虚拟环境所需要的包pyspark jieba pyhive。
2.3 在所有机器配置环境变量
参考 Local模式下 环境变量的配置内容。确保3台都配置
2.4 配置配置文件
进入到spark的配置文件目录中, cd $SPARK_HOME/conf
配置workers文件
# 改名, 去掉后面的.template后缀
mv workers.template workers
# 编辑worker文件
vim workers
# 将里面的localhost删除, 追加
node1
node2
node3
到workers文件内
# 功能: 这个文件就是指示了 当前SparkStandAlone环境下, 有哪些worker
配置spark-env.sh文件
# 1. 改名
mv spark-env.sh.template spark-env.sh
# 2. 编辑spark-env.sh, 在底部追加如下内容
## 设置JAVA安装目录
JAVA_HOME=/export/server/jdk
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
## 指定spark老大Master的IP和提交任务的通信端口
# 告知Spark的master运行在哪个机器上
export SPARK_MASTER_HOST=node1
# 告知sparkmaster的通讯端口
export SPARK_MASTER_PORT=7077
# 告知spark master的 webui端口
SPARK_MASTER_WEBUI_PORT=8080
# worker cpu可用核数
SPARK_WORKER_CORES=1
# worker可用内存
SPARK_WORKER_MEMORY=1g
# worker的工作通讯地址
SPARK_WORKER_PORT=7078
# worker的 webui地址
SPARK_WORKER_WEBUI_PORT=8081
## 设置历史服务器
# 配置的意思是 将spark程序运行的历史日志 存到hdfs的/sparklog文件夹中
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
注意, 上面的配置的路径 要根据你自己机器实际的路径来写。
在HDFS上创建程序运行历史记录存放的文件夹:
hadoop fs -mkdir /sparklog
hadoop fs -chmod 777 /sparklog
配置spark-defaults.conf文件
# 1. 改名
mv spark-defaults.conf.template spark-defaults.conf
# 2. 修改内容, 追加如下内容
# 开启spark的日期记录功能
spark.eventLog.enabled true
# 设置spark日志记录的路径
spark.eventLog.dir hdfs://node1:8020/sparklog/
# 设置spark日志是否启动压缩
spark.eventLog.compress true
配置log4j.properties 文件 [可选配置]
# 1. 改名
mv log4j.properties.template log4j.properties
# 2. 修改内容 参考下图

这个文件的修改不是必须的, 为什么修改为WARN. 因为Spark是个话痨,会疯狂输出日志, 设置级别为WARN 只输出警告和错误日志, 不要输出一堆废话。
2.5 将Spark安装文件夹 分发到其它的服务器上
scp -r spark-3.1.2-bin-hadoop3.2 node2:/export/server/
scp -r spark-3.1.2-bin-hadoop3.2 node3:/export/server/
不要忘记, 在node2和node3上 给spark安装目录增加软链接
`ln -s /export/server/spark-3.1.2-bin-hadoop3.2 /export/server/spark`
2.6 检查
检查每台机器的:
JAVA_HOME
SPARK_HOME
PYSPARK_PYTHON
等等 环境变量是否正常指向正确的目录
2.7 启动历史服务器
`sbin/start-history-server.sh`
2.8 启动Spark的Master和Worker进程
# 启动全部master和worker
sbin/start-all.sh
# 或者可以一个个启动:
# 启动当前机器的master
sbin/start-master.sh
# 启动当前机器的worker
sbin/start-worker.sh
# 停止全部
sbin/stop-all.sh
# 停止当前机器的master
sbin/stop-master.sh
# 停止当前机器的worker
sbin/stop-worker.sh
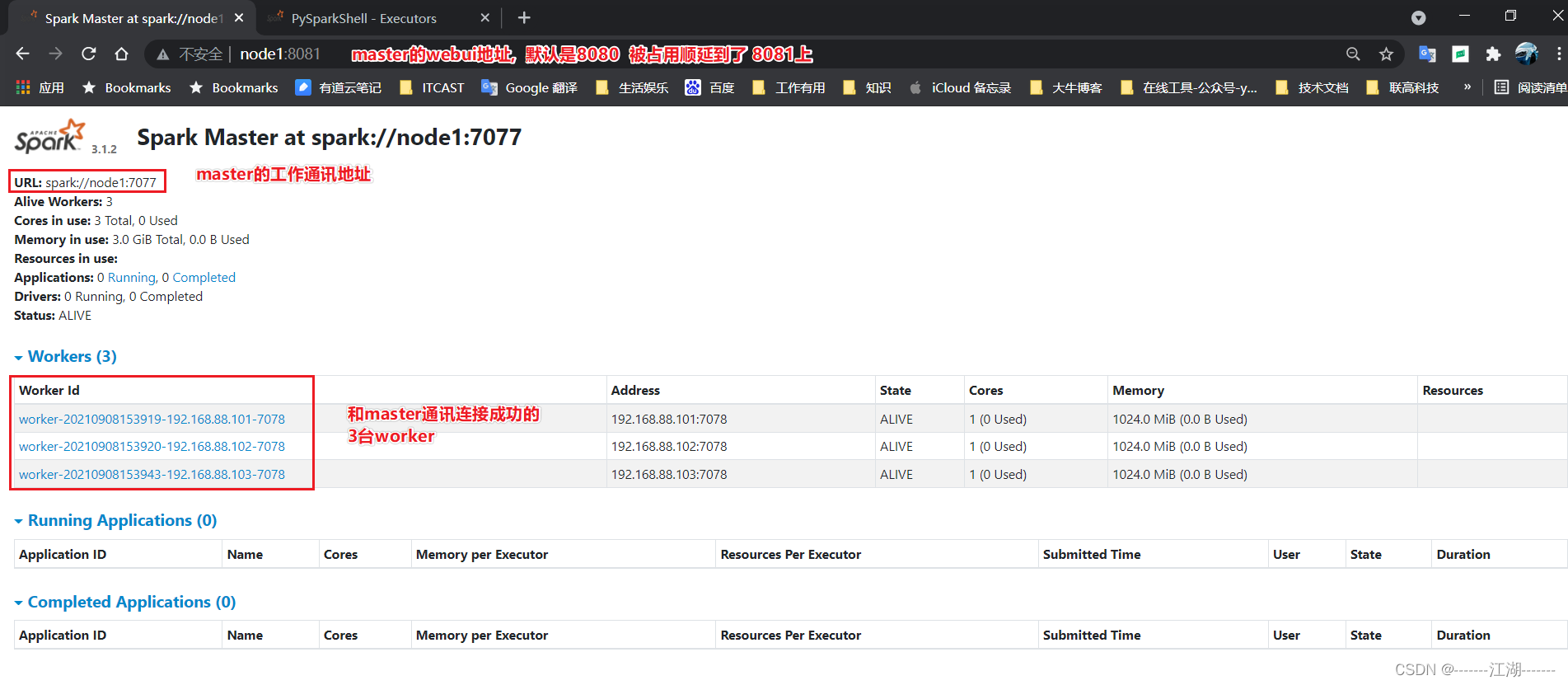
2.9 查看Master的WEB UI
- 默认端口master我们设置到了8080。
- 如果端口被占用, 会顺延到8081 …;8082… 8083… 直到申请到端口为止。
- 可以在日志中查看, 具体顺延到哪个端口上。
3 连接到StandAlone集群
3.1 bin/pyspark
执行:
bin/pyspark --master spark://node1:7077
# 通过--master选项来连接到 StandAlone集群
# 如果不写--master选项, 默认是local模式运行

3.2 bin/spark-shell
bin/spark-shell --master spark://node1:7077
# 同样适用--master来连接到集群使用
// 测试代码
sc.parallelize(Array(1,2,3,4,5)).map(x=> x + 1).collect()
3.3 bin/spark-submit (PI)
bin/spark-submit --master spark://node1:7077 /export/server/spark/examples/src/main/python/pi.py 100
# 同样使用--master来指定将任务提交到集群运行
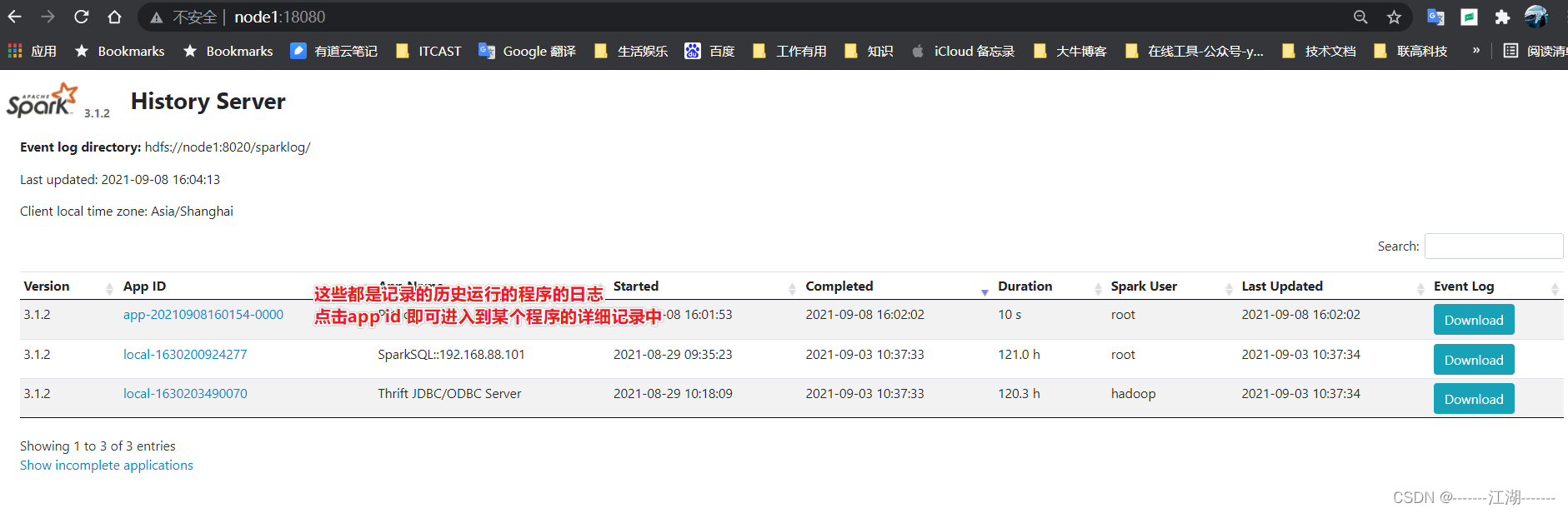
4 查看历史服务器WEB UI
- 历史服务器的默认端口是: 18080
- 我们启动在node1上, 可以在浏览器打开:
node1:18080来进入到历史服务器的WEB UI上.
边栏推荐
- Linux bash: redis-server: command not found
- Linux bash: redis-server: 未找到命令
- SetoolKit使用指南
- 常用工具命令速查表
- 龟速乘【模板】
- A detailed explanation of the usage of Async and Await in C#
- Selenium自动化测试之Selenium IDE
- Analysis of the startup source code of hyperf (2) - how the request reaches the controller
- SetoolKit User Guide
- MySQL 23 classic interviews hang the interviewer
猜你喜欢

Open Inventor 10.12 Major Improvements - Harmony Edition
组合系列--有排列就有组合
STM32的CAN过滤器

技能大赛训练题:域用户和组织单元的创建
使用NVM进行node版本切换管理
Analysis of the startup source code of hyperf (2) - how the request reaches the controller
Small test knife: Go reflection helped me convert Excel to Struct

Why do we need to sub-library and sub-table?

LeetCode·每日一题·1161.最大层内元素和·层次遍历

The recently popular domestic interface artifact Apipost experience
随机推荐
小试牛刀:Go 反射帮我把 Excel 转成 Struct
页面整屏滚动效果
Open Inventor 10.12 Major Improvements - Harmony Edition
组合系列--有排列就有组合
1-hour live broadcast recruitment order: industry leaders share dry goods, and enterprise registration is open丨qubit · point of view
Asynchronous processing business using CompletableFuture
The 232-layer 3D flash memory chip is here: the single-chip capacity is 2TB, and the transmission speed is increased by 50%
CLion用于STM32开发
【Pytorch】F.softmax()方法说明
[QNX Hypervisor 2.2 User Manual] 9.13 rom
尚硅谷-JVM-内存和垃圾回收篇(P1~P203)
The use of thread pool two
搭建私有的的Nuget包服务器教程
为什么要分库分表?
Sentinel服务熔断和降级
AI cocoa AI frontier introduction (7.31)
使用CompletableFuture进行异步处理业务
MySQL [subquery]
MySQL [aggregate function]
已解决(pymysqL连接数据库报错)pymysqL.err.ProgrammingError: (1146,“Table ‘test.students‘ doesn‘t exist“)