当前位置:网站首页>Improved schemes for episodic memory based lifelong learning
Improved schemes for episodic memory based lifelong learning
2022-06-12 07:17:00 【Programmer long】
The address of the paper is here
One . Introduce
At present, deep neural network can achieve remarkable performance on a single task , However, when the network is retrained to a new task , His performance has fallen sharply on previously trained tasks , This phenomenon is called catastrophic forgetting . In sharp contrast to it is , The human cognitive system can acquire new knowledge without destroying previous knowledge .
Catastrophic forgetting has inspired the field of lifelong learning . One of the core problems of lifelong learning is how to strike a balance between old tasks and new tasks . In the process of learning new tasks , The knowledge learned in the past is usually disturbed , Leading to catastrophic forgetting . On the other hand , Learning algorithms that favor old tasks will interfere with the learning of new tasks . In this scenario , At present, several strategies are proposed . Including regularization based methods , Methods based on knowledge transfer and episodic memory . Especially in the method based on episodic memory , Such as gradient episodic memory (GEM) And average gradient episodic memory (A-GEM) Realize significant performance . In episodic memory , Use small episodic memory to store instances in old tasks , To guide the optimization of the current task .
In this paper the author , From the perspective of optimization, this paper puts forward the viewpoint of lifelong learning method based on episodic memory ( in the light of GEM and A- GEM). The optimization problem is approximately solved by using one-step random gradient descent method , The standard gradient is replaced by the mixed random gradient method . At the same time, two different schemes are proposed ,MEGA-1,MEGA-2, It can be used in different scenarios .
Two . Related work
Regularization based approach : Classical method EWC use fisher information The matrix prevents the weight of old tasks from changing dramatically .PI in , The author introduces the intelligent synapse , And give each prominent local importance measure , To avoid old memories being overwritten .R-WALK Based on KL Divergent regularization to preserve knowledge of old tasks . And in the MAS in , The importance measure of each parameter of the network is calculated based on the sensitivity of the predictive output function to parameter changes .
Based on the way of knowledge transfer : stay PROG-NN in , Add a new column for each task , This column is connected to the hidden layer of the previous task . meanwhile , There is also the use of unmarked ( not used ) Data to avoid catastrophic forgetting , That is, knowledge distillation .
Based on episodic memory : Using external memory to enhance standard neural networks is a widely adopted practice . In the method of lifelong learning based on episodic memory , A small reference memory is used to store information from old tasks . When the angle between the current gradient and the gradient calculated on the reference memory is an obtuse angle ,GEM and A-GEM Rotate the current gradient .
The scheme proposed by the author aims to improve the method based on episodic memory . And A-GEM Different , The scheme explicitly considers the performance of the model for old tasks and new tasks in the current gradient rotation process .
3、 ... and . Lifelong learning
Lifelong learning considers the problem of learning new tasks without reducing the performance of old tasks to avoid catastrophic forgetting . Suppose there is T Tasks correspond to T Data sets : { D 1 , D 2 , . . . , D T } \{D_1,D_2,...,D_T\} { D1,D2,...,DT}. Every data set D t D_t Dt Is a tuple { x i , y i , t } \{x_i,y_i,t\} { xi,yi,t} A list of components . Similar to supervised learning , Every data set D t D_t Dt It can be divided into training sets D t t r D_t^{tr} Dttr And test set D t t e D_t^{te} Dtte.
stay A-GEM in , Tasks are divided into D C V = { D 1 , D 2 , . . . , D T C V } D^{CV}=\{D_1,D_2,...,D_{T^{CV}}\} DCV={ D1,D2,...,DTCV} and D E V = { D T C V + 1 D T C V + 2 , . . . , D T } D^{EV}=\{D_{T^{CV}+1}D_{T^{CV}+2},...,D_T\} DEV={ DTCV+1DTCV+2,...,DT}. among D C V D^{CV} DCV Used for cross validation to search for super parameters . D E V D^{EV} DEV For practical training and evaluation . When searching for super parameters , We can do it in D C V D^{CV} DCV The example is propagated many times in , stay D E V D^{EV} DEV On the execution of training , Pass the example only once .
In lifelong learning , A model f ( x ; w ) f(x;w) f(x;w) Trained in a series of tasks { D T C V + 1 , D T C V + 2 , . . . , D T } \{D_{T^{CV}+1},D_{T^{CV}+2},...,D_T\} { DTCV+1,DTCV+2,...,DT}. When the model is trained to the task D t D_t Dt, The goal is to predict D t t e D_t^{te} Dtte By minimizing D t t r D^{tr}_t Dttr Experience loss l t ( w ) l_t(w) lt(w) Not lower in { D T C V + 1 t e , D T C V + 2 t e , . . . , D t − 1 t e } \{D_{T^{CV}+1}^{te},D_{T^{CV}+2}^{te},...,D_{t-1}^{te}\} { DTCV+1te,DTCV+2te,...,Dt−1te}
Four . The view of lifelong learning based on episodic memory
GEM and A-GEM By using a small episodic memory M k M_k Mk To store tasks k A subset of the examples in . Episodic memory is filled by randomly and evenly selecting examples for each task . When training on mission t t t when , The loss of episodic memory can be calculated as : l r e f ( w t ; M k ) = 1 ∣ M k ∣ ∑ ( x i , y i ) ∈ M k l ( f ( x i ; w t ) , y i ) l_{ref}(w_t;M_k)=\frac{1}{|M_k|}\sum_{(x_i,y_i)\in M_k}l(f(x_i;w_t),y_i) lref(wt;Mk)=∣Mk∣1∑(xi,yi)∈Mkl(f(xi;wt),yi).
stay GEM and A-GEM in , Training lifelong learning model by small batch random gradient descent method . We use w k t w_k^t wkt Expressed as a model in the task t Is the awkward part of the training to the k individual mini-batch The weight of . In order to establish the old task with the t Performance tradeoffs for tasks , We consider the following compound objective optimization problem in each update step :
min w α 1 ( w k t ) l t ( w ) + α 2 ( w k t ) l r e f ( w ) = E ξ , ζ [ α 1 ( w k t ) l t ( w ; ξ ) + α 2 ( w k t ) l r e f ( w ; ζ ) ] \min_{w}\alpha_1(w_k^t)l_t(w)+\alpha_2(w_k^t)l_{ref}(w)=\mathbb{E_{\xi,\zeta}}[\alpha_1(w_k^t)l_t(w;\xi)+\alpha_2(w_k^t)l_{ref}(w;\zeta)] wminα1(wkt)lt(w)+α2(wkt)lref(w)=Eξ,ζ[α1(wkt)lt(w;ξ)+α2(wkt)lref(w;ζ)]
among ξ , ζ \xi,\zeta ξ,ζ Represents a random vector with finite support , l t ( w ) l_t(w) lt(w) For the first time t Training loss of missions , l r e f ( w ) l_{ref}(w) lref(w) Is the predicted loss calculated from the data stored in the episodic memory , α 1 ( w ) , α 2 ( w ) \alpha_1(w),\alpha_2(w) α1(w),α2(w) For control at each mini-batch in l t ( w ) l_t(w) lt(w) and l r e f ( w ) l_{ref}(w) lref(w) The relative importance of .
So mathematically , We can consider using the following updates :
w k + 1 t = a r g min w α 1 ( w k t ) l t ( w ; ξ ) + α 2 ( w k t ) l r e f ( w ; ζ ) w^t_{k+1} = arg\min_{w}\alpha_1(w_k^t)l_t(w;\xi)+\alpha_2(w_k^t)l_{ref}(w;\zeta) wk+1t=argwminα1(wkt)lt(w;ξ)+α2(wkt)lref(w;ζ)
GEM and A- GEM The first-order method ( Random gradient ) Approximate optimization of the above formula , One step of the random gradient is from the initial point w k t w_k^t wkt At the beginning :
w k + 1 t = w k t − η ( α 1 ( w k t ) ∇ l t ( w ; ξ ) + α 2 ∇ ( w k t ) l r e f ( w ; ζ ) ) w^t_{k+1} = w_k^t - \eta( \alpha_1(w_k^t)\nabla l_t(w;\xi)+\alpha_2\nabla (w_k^t)l_{ref}(w;\zeta)) wk+1t=wkt−η(α1(wkt)∇lt(w;ξ)+α2∇(wkt)lref(w;ζ))
stay GEM and A-GEM in α 1 ( w ) \alpha_1(w) α1(w) by 1, This means that the current task is always given the same attention during training , No matter how the loss changes with time . In the process of lifelong learning , Current losses and scenario losses are dynamic in each small batch , And if the α 1 ( w ) \alpha_1(w) α1(w) Always be 1 May not strike a good balance .
5、 ... and . Mixed random gradient
In this section , The authors introduce the mixed random gradient (MEGA) To solve GEM and A-GEM The limitations of . because A-GEM Better performance than GEM, use A- GEM To calculate the scenario reference loss .
5.1 MEGA-I
MEGA-I It is an adaptive loss based method , Balance the current task with the old task by using only the loss information . The author introduces a predefined sensitive parameter ϵ \epsilon ϵ. as follows :
{ α 1 ( w ) = 1 , α 2 ( w ) = l r e f ( w ; ζ ) / l t ( w ; ξ ) if l t ( w ; ξ ) > ϵ α 1 ( w ) = 0 , α 2 ( w ) = 1 if l t ( w ; ξ ) < = ϵ \begin{dcases} \alpha_1(w)=1,\alpha_2(w)=l_{ref}(w;\zeta)/l_t(w;\xi) \ \ \ \ &\text{if } l_t(w;\xi) > \epsilon\\ \alpha_1(w)=0,\alpha_2(w)=1 &\text{if } l_t(w;\xi) <= \epsilon \end{dcases} { α1(w)=1,α2(w)=lref(w;ζ)/lt(w;ξ) α1(w)=0,α2(w)=1if lt(w;ξ)>ϵif lt(w;ξ)<=ϵ
Intuitively , If the model performs well on the current task ( That is to say loss Very small ), that MEGA-I Focus on improving the performance of data stored in episodic memory . Because of the choice α 1 ( w ) = 0 , α 2 ( w ) = 1 \alpha_1(w)=0,\alpha_2(w)=1 α1(w)=0,α2(w)=1. otherwise , When the loss is large ,MEGA-I Then keep the equilibrium of these two mixed random gradients through l r e f ( w ; ζ ) , l t ( w ; ξ ) l_{ref}(w;\zeta),l_t(w;\xi) lref(w;ζ),lt(w;ξ).
5.2 MEGA-II
MEGA-I The size of the blending gradient depends on the current gradient and the scenario related gradient , And the loss of current tasks and episodic memory . and MEGA-II The mixed gradient of is lost A- GEM Inspired by the , From the rotation of the current gradient , Its size depends only on the current gradient .
MEGA-II Firstly, the random gradient calculated by the current task is rotated properly , Through an angle θ k t \theta^t_k θkt. Then the rotated vector is used as a mixed random gradient , Update each small batch .
We use g m i x g_{mix} gmix To represent the desired mixed random gradient , The size and the ∇ l t ( w ; ξ ) \nabla l_t(w;\xi) ∇lt(w;ξ) equally . We're looking for directions that match ∇ l t ( w ; ξ ) , ∇ l r e f ( w ; ζ ) \nabla l_t(w;\xi),\nabla l_{ref}(w;\zeta) ∇lt(w;ξ),∇lref(w;ζ). And MEGA-I similar , We use the loss balancing scheme and want to maximize it :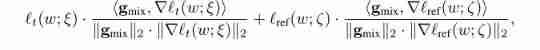
Look for the following θ \theta θ:
θ = a r g max β ∈ [ 0 , π ] l t ( w ; ξ ) c o s ( β ) + l r e f ( w ; ξ ) c o s ( θ ~ − β ) \theta = arg\max_{\beta\in[0,\pi]}l_t(w;\xi)cos(\beta)+l_{ref}(w;\xi)cos(\tilde{\theta}-\beta) θ=argβ∈[0,π]maxlt(w;ξ)cos(β)+lref(w;ξ)cos(θ~−β)
among θ ~ ∈ [ 0 , π ] \tilde{\theta}\in[0,\pi] θ~∈[0,π] For in ∇ l t ( w ; ξ ) \nabla l_t(w;\xi) ∇lt(w;ξ) To ∇ l r e f ( w ; ζ ) \nabla l_{ref}(w;\zeta) ∇lref(w;ζ) The angle between , β ∈ [ 0 , π ] \beta\in[0,\pi] β∈[0,π] For in g m i x g_{mix} gmix and ∇ l t ( w ; ξ ) \nabla l_t(w;\xi) ∇lt(w;ξ) The angle between . among θ \theta θ The closed form of is θ = π 2 − α \theta = \frac{\pi}{2}-\alpha θ=2π−α, among α = a r c t a n ( k + c o s θ ~ s i n θ ~ ) , k = l t ( w ; ξ ) / l r e f ( w ; ζ ) \alpha = arctan(\frac{k+cos\tilde{\theta}}{sin\tilde{\theta}}),k=l_t(w;\xi)/l_{ref}(w;\zeta) α=arctan(sinθ~k+cosθ~),k=lt(w;ξ)/lref(w;ζ).
- Here are some special cases
- When l r e f ( w ; ζ ) = 0 l_{ref}(w;\zeta)=0 lref(w;ζ)=0, here θ = 0 \theta =0 θ=0, under these circumstances α 1 ( w ) = 1 , α 2 ( w ) = 0 \alpha_1(w)=1,\alpha_2(w)=0 α1(w)=1,α2(w)=0. This means no forgetting , So learn new tasks directly .
- When l t ( w ; ξ ) = 0 l_{t}(w;\xi)=0 lt(w;ξ)=0, here θ = θ ~ \theta =\tilde{\theta} θ=θ~, under these circumstances α 1 ( w ) = 0 \alpha_1(w)=0 α1(w)=0, α 2 ( w ) = ∣ ∣ ∇ l t ( w ; ξ ) ∣ ∣ 2 / ∣ ∣ ∇ l r e f ( w ; ζ ) ∣ ∣ 2 \alpha_2(w) = ||\nabla l_t(w;\xi)||_2/||\nabla l_{ref}(w;\zeta)||_2 α2(w)=∣∣∇lt(w;ξ)∣∣2/∣∣∇lref(w;ζ)∣∣2. In this case , The direction of the mixed random gradient is the same as that of the random gradient calculated from the data in the episodic memory .
6、 ... and . Key code interpretation
Code point here
The author's code is very complicated , Integrate a variety of lifelong learning methods , The algorithm proposed by the author of this paper is mainly aimed at GEM and A-GEM Medium α 1 ( w ) \alpha_1(w) α1(w) and α 2 ( w ) \alpha_2(w) α2(w) Make changes , So the code section only describes this part , and GEM Part I will use other codes to cooperate with the thesis to explain .MEGA-II Can be said to be MEGA-I A more applicable version of , We will explain this .
First , Explicit parameters , According to the above, when our model carries out back propagation , We can get ∇ l t ( w ; ξ ) \nabla l_t(w;\xi) ∇lt(w;ξ) and ∇ l r e f ( w ; ζ ) \nabla l_{ref}(w;\zeta) ∇lref(w;ζ), For the convenience of writing , Write them down as g t g_t gt and g r g_r gr( The corresponding loss is recorded as l t , l r l_t,l_r lt,lr). Again MEGA-II in , θ ~ \tilde{\theta} θ~ by g t g_t gt and g r g_r gr The angle between :
θ ~ = a r c c o s ( g t ∗ g r ∣ ∣ g t ∣ ∣ 2 ∗ ∣ ∣ g r ∣ ∣ 2 ) \tilde{\theta}=arccos(\frac{g_t*g_r}{||g_t||_2*||g_r||_2}) θ~=arccos(∣∣gt∣∣2∗∣∣gr∣∣2gt∗gr)
The corresponding code is as follows :
## Multiply the distances of two vectors
self.deno1 = (tf.norm(flat_task_grads) * tf.norm(flat_ref_grads))
## Multiply two vectors
self.num1 = tf.reduce_sum(tf.multiply(flat_task_grads, flat_ref_grads))
## Find the angle
self.angle_tilda = tf.acos(self.num1/self.deno1)
Then there was θ ~ \tilde{\theta} θ~ after , We can update θ \theta θ 了 , Here we use a gradient to update .
set up k = l r l t k = \frac{l_r}{l_t} k=ltlr, We solve it θ \theta θ The formula becomes :
θ = a r g max β [ c o s ( β ) + k ∗ c o s ( θ ~ − β ) ] \theta = arg\max_{\beta}[cos(\beta)+k*cos(\tilde{\theta}-\beta)] θ=argβmax[cos(β)+k∗cos(θ~−β)]
Gradient update ( Due to time demand argmax Therefore, it is used + Number )
θ = θ + [ − s i n ( θ ) + k ∗ s i n ( θ ~ − θ ) ] \theta=\theta+[-sin(\theta)+k*sin(\tilde{\theta}-\theta)] θ=θ+[−sin(θ)+k∗sin(θ~−θ)]
θ \theta θ For the range of [ 0 , π 2 ] [0,\frac{\pi}{2}] [0,2π]( Here the author gives proof )
Therefore, we need to prevent overflow after updating .
The corresponding code is :
def loop(steps, theta):
## \theta The calculation of , It is worth noting that , The author also * On a 1/(1+k), there self.ratio The corresponding is k
theta = theta + (1 / (1+self.ratio)) * (-tf.sin(theta) + self.ratio * tf.sin(self.angle_tilda - theta))
## Prevent exceeding the range
theta = tf.cond(tf.greater_equal(theta, 0.5*pi), lambda: tf.identity(0.5*pi), lambda: tf.identity(theta))
theta = tf.cond(tf.less_equal(theta, 0.0), lambda: tf.identity(0.0), lambda: tf.identity(theta))
steps = tf.add(steps, 1)
The author has solved many times here θ \theta θ, by :
for idx in range(3):
steps = tf.constant(0.0)
_, thetas[idx] = tf.while_loop(
condition,
loop,
[steps, thetas[idx]]
)
objectives[idx] = self.old_task_loss * tf.cos(thetas[idx]) + self.ref_loss * tf.cos(self.angle_tilda - thetas[idx])
objectives = tf.convert_to_tensor(objectives)
max_idx = tf.argmax(objectives)
self.theta = tf.gather(thetas, max_idx)
Finally, according to θ \theta θ solve α 1 \alpha_1 α1 and α 2 \alpha_2 α2 了 , Here the author also gives the solution :
That is, simultaneous equations a and b that will do , The corresponding code is as follows :
tr = tf.reduce_sum(tf.multiply(flat_task_grads, flat_ref_grads))
tt = tf.reduce_sum(tf.multiply(flat_task_grads, flat_task_grads))
rr = tf.reduce_sum(tf.multiply(flat_ref_grads, flat_ref_grads))
def compute_g_tilda(tr, tt, rr, flat_task_grads, flat_ref_grads):
a = (rr * tt * tf.cos(self.theta) - tr * tf.norm(flat_task_grads) * tf.norm(flat_ref_grads) * tf.cos(self.angle_tilda-self.theta)) / self.deno
b = (-tr * tt * tf.cos(self.theta) + tt * tf.norm(flat_task_grads) * tf.norm(flat_ref_grads) * tf.cos(self.angle_tilda-self.theta)) / self.deno
return a * flat_task_grads + b * flat_ref_grads
self.deno = tt * rr - tr * tr
g_tilda = tf.cond(tf.less_equal(self.deno, 1e-10), lambda: tf.identity(flat_task_grads), lambda: compute_g_tilda(tr, tt, rr, flat_task_grads, flat_ref_grads))
To go here about MEGA-II And we're done , Author combination A-GEM The rotation angle is used to balance the loss of old tasks and the loss of new tasks , It can be used for reference .
边栏推荐
- "I was laid off by a big factory"
- TypeScript基础知识全集
- Dépannage de l'opération cl210openstack - chapitre expérience
- Use case design of software testing interview questions
- Android studio uses database to realize login and registration interface function
- Detailed explanation of 8086/8088 system bus (sequence analysis + bus related knowledge)
- NOI openjudge 计算2的N次方
- D
- LVDS drive adapter
- linux下怎么停止mysql服务
猜你喜欢

Day 6 of pyhon
Test left shift real introduction

Detailed explanation of TF2 command line debugging tool in ROS (parsing + code example + execution logic)

晶闸管,它是很重要的,交流控制器件

Dépannage de l'opération cl210openstack - chapitre expérience

2022电工(初级)考试题库及模拟考试
CL210OpenStack操作的故障排除--章節實驗

6 functions
![‘CMRESHandler‘ object has no attribute ‘_timer‘,socket.gaierror: [Errno 8] nodename nor servname pro](/img/de/6756c1b8d9b792118bebb2d6c1e54c.png)
‘CMRESHandler‘ object has no attribute ‘_timer‘,socket.gaierror: [Errno 8] nodename nor servname pro

2022年G3锅炉水处理复训题库及答案
随机推荐
Stm32cubemx learning (I) USB HID bidirectional communication
【WAX链游】发布一个免费开源的Alien Worlds【外星世界】脚本TLM
Win10 list documents
knife4j 初次使用
Noi openjudge computes the n-th power of 2
Source code learning - [FreeRTOS] privileged_ Understanding of function meaning
Network packet loss troubleshooting
Detailed explanation of addressing mode in 8086
Study on display principle of seven segment digital tube
5 lines of code identify various verification codes
When SQL server2019 is installed, the next step cannot be performed. How to solve this problem?
ROS dynamic parameter configuration: use of dynparam command line tool (example + code)
Lambda function perfect use guide
Recommend 17 "wheels" to improve development efficiency
Unable to load bean of class marked with @configuration
Pyhon的第六天
[data clustering] data set, visualization and precautions are involved in this column
Error mcrypt in php7 version of official encryption and decryption library of enterprise wechat_ module_ Open has no method defined and is discarded by PHP. The solution is to use OpenSSL
lambda 函数完美使用指南
libprint2