当前位置:网站首页>Argminer: a pytorch package for processing, enhancing, training, and reasoning argument mining datasets
Argminer: a pytorch package for processing, enhancing, training, and reasoning argument mining datasets
2022-07-04 12:39:00 【deephub】
Argument mining (Argument Mining) It is a task to extract argument components from text , Usually as part of an automated writing evaluation system . This is a very popular field in natural language processing . A good AM The model can mark a sequence of original texts as the argument content they belong to . Although historically, this problem has been regarded as a semantic segmentation problem , State-of-the-art (SOTA) AM Technology recognizes it as a named entity (NER) Long sequence of text of the problem .

Despite the history of this field , About NER AM There is relatively little literature on data sets , since 2014 The only contribution since is Christian Stab and Iryna Gurevych Of Argument Annotated Essays. lately ( By 2022 year 3 month ), With PERSUADE( stay Kaggle competition Feedback Prize Use in ) and ARG2020 Data sets ( stay GitHub Release ), Although this situation has been improved , But there is little about AM Cross dataset performance test of the model . Therefore, there is no research on how to improve antagonistic training AM Cross dataset performance of the model . Yes AM There are also few studies on the robustness of models against examples .
Because each data set is stored in a different format , Complicate these challenges , This makes it difficult to standardize the data in the experiment (Feedback Prize The game can confirm this , Because most of the code is used to process data ).
This paper introduces ArgMiner Is a tool for using based on Transformer Your model is right SOTA Argument mining data set for standardized data processing 、 Data to enhance 、 Trained and inferred pytorch My bag . This article starts with the introduction of package features , And then there was SOTA Introduction to dataset , And describes in detail ArgMiner Processing and extension features . Finally, the reasoning and evaluation of the argument mining model ( adopt Web Applications ) A brief discussion .
ArgMiner brief introduction
ArgMiner The main features of the project are summarized as follows :
- Handle SOTA Data sets , Without writing any additional lines of code
- The following markup methods can be generated at the word and sub markup levels {io, bio, bioo, bixo}, No extra code
- You can customize enhancements without changing the data processing pipeline
- Provide a For use with any HuggingFace TokenClassification Model for argument mining fine tuning PyTorch Dataset class
- Provide efficient training and reasoning processes
The image below shows ArgMiner End to end work :
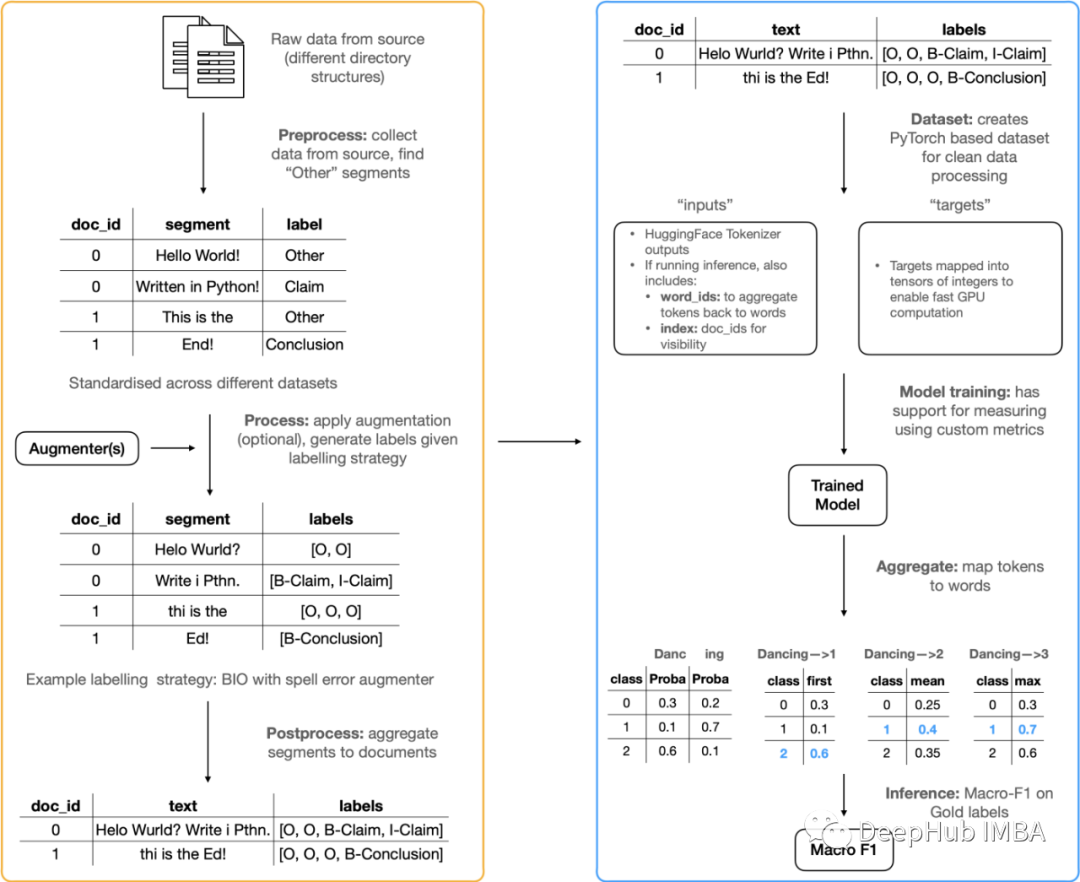
Data processing and enhancement
Data sets
Argument notes paper (Argument Annotated Essays ): This is a 402 A collection of papers . It has three argument components :Claim, MajorClaim, Premise. Data sets can be stored in TUDarmstadt Find ; The original paper is in ACL On , Subsequent papers are in MIT Press Direct On .PERSUADE: This is a book written by the United States 6-12 Written by grade students 15000 A collection of articles . It has 7 There are three parts of the argument :Lead, Position, Claim, Counterclaim, Rebuttal, Evidence, Concluding****Statement. Data sets can be accessed through Kaggle Competition visit .
ARG2020: This is a book 145 A collection of middle school students' compositions . It has two argument components :Claim Premise. The dataset is in GitHub Go public , Papers on this work are in ArXiv On .
These datasets are stored and processed in different ways . for example ,AAE and ARG2020 The dataset has ann file , The data is also attached with the original paper text .txt file . And ARG2020 Different ,AAE Dataset with training and testing for segmenting data id.
PERSUADE There is a more complex directory structure , Including the original .txt Training and testing catalogue of papers . The actual information about the argument tag is contained in train.csv in .
No data set actually indicates that the part of the article that is not part of the argument , That is to say “ other ” class . however NER Problems usually require this ( Otherwise, you are selectively viewing information from the article rather than the entire article ). Therefore, it is necessary to extract these contents from the paper itself .
In order to process these greatly changed original texts in a standardized format ,ArgMiner Adopted 3 Stages :
Preprocessing : Extract data from the source
This step is in the original format ( For each data set ) get data , And use span_start and span_end Features and raw text generate a DataFrame, Its structure is as follows :[essay_id, text, argument_component].
This supports the use of standard methods to generate NER label , Or enhance data . These processes are based on a basic DataProcessor class , This class has save and apply train-test-split Built in features of , So you can easily create new processing classes from it .
from argminer.data import TUDarmstadtProcessor, PersuadeProcessor, DataProcessor
# process the AAE dataset from source
processor = TUDarmstadtProcessor('path_to_AAE_dir').preprocess()
print(processor.dataframe.head())
# process the Persuade dataset from source
processor = PersuadeProcessor('path_to_persuade_dir').preprocess()
print(processor.dataframe.head())
# create a custom processor for new dataset (e.g. ARG2020 will be done this way)
class ARG2020Processor(DataProcessor):
def __init__(self, path=''):
super().__init__(path)
def _preprocess(self):
pass
Generate tags and ( Optional ) Add data
The data has been processed and changed into a standard format , Then the next step is to generate data NER Style label . At the end of this step , Data sets will look like this :[essay_id, text, argument_component, NER_labels].
Sometimes people may be interested in enhancing data , Whether it is antagonistic training or robustness test of antagonistic examples . under these circumstances , You can provide a function that accepts a piece of text and returns an enhanced text . Other functions can be used in this function NLP Extended library , Such as textattack and nlpaug.
from argminer.data import PersuadeProcessor
processor = PersuadeProcessor().preprocess().process(strategy='bio')
# augmenters
# remove first word (toy example) on io labelling
first_word_removal = lambda x: ' '.join(x.split()[1:])
processor = PersuadeProcessor().preprocess().process(strategy='io', processors=[first_word_removal])
# remove last word (toy example) on bieo labelling
last_word_removal = lambda x: ' '.join(x.split()[:-1])
processor = PersuadeProcessor().preprocess().process(strategy='io', processors=[last_word_removal])
post-processing : Aggregate sequences into documents
The last step is very simple , Because the tag has been created , Finally, you need to pass the doc_id To connect them . The output of this stage is a DataFrame:[essay_id, full_essay_text, NER_labels]. Using built-in training and test set segmentation is also very easy .
from argminer.data import PersuadeProcessor
processor = PersuadeProcessor().preprocess().process('bio').postprocess()
# full data
print(processor.dataframe.head())
# train test split
df_dict = processor.get_tts(test_size=0.3, val_size=0.1)
df_train = df_dict['train']
df_test = df_dict['test']
df_val = df_dict['val']
PyTorch Data sets
PyTorch Data sets are designed to accept .postprocess() Stage input , Variable strategy_level You can determine whether the marking strategy should be applied to the word level or the marking level . Data sets extend class labels to child tags . And Kaggle Compared with the example on , It's a huge improvement , Because it is vectorized, it can be used effectively GPU. The dataset also creates a mapping , Merge extended tags into their core tags , To infer ( for example “B-Claim, I- claim, E-Claim” Are merged into Claim).
It's also very simple to use , And because it is based on PyTorch It can be easily integrated into training . for example :
from argminer.data import ArgumentMiningDataset
trainset = ArgumentMiningDataset(df_label_map, df_train, tokenizer, max_length)
train_loader = DataLoader(trainset)
for epoch in range(epochs):
model.train()
for i, (inputs, targets) in enumerate(train_loader):
optimizer.zero_grad()
loss, outputs = model(
labels=targets,
input_ids=inputs['input_ids'],
attention_mask=inputs['attention_mask'],
return_dict=False
)
# backward pass
loss.backward()
optimizer.step()
Reasoning
ArgMiner It also provides functions for training models and reasoning .
ArgMiner Write inference functions into efficient ( Where possible , They make use of GPU And Vectorization ) And batch ( Therefore, it is very suitable for low memory settings ), This means that inference functions can also be used in training for validation data . When mapping back words from tags during reasoning , You can easily choose the aggregation level . for example , Given two tags “Unit” and “ed” And the probability of each class , You can use words “Unit” The best probability of 、 The best average probability or the best maximum probability aggregates them into “United”.
And Feedback Prize Compared with the scheme used in the competition , This reasoning scheme has some advantages .
Web Applications
ArgMiner It also contains a web Applications , You can view the output given by the model ( Or anything from HuggingFace Model of ), It can also be used to evaluate the performance of models on custom datasets . This is a useful ( Informal ) Method , You can explore models on specific examples ,
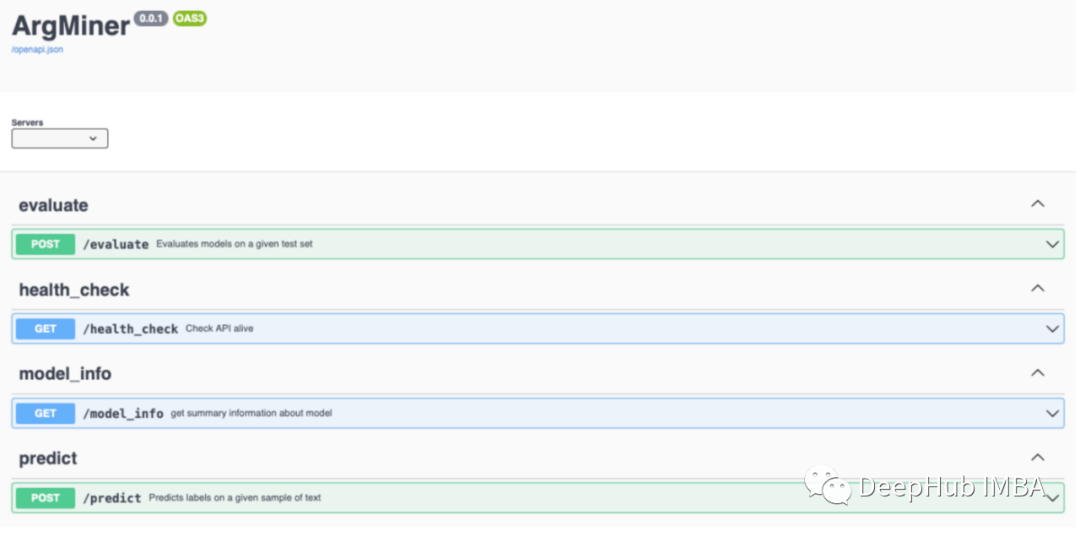
Know what it is doing .
summary
For a long time , The literature of argument mining has very little description of data sets , But as the PERSUADE and ARG2020 Release , That has changed . The problem of knowledge transfer and robustness in argument mining need to be further studied . But first of all, from the perspective of data processing , This is usually difficult , Because the data format of different sources 、 There are many ways to represent data , And efficiency problems caused by using unequal segments for representation and inference .
ArgMiner yes Early Release Access One of the bags in , It can be used for SOTA The data set of argument mining is standardized 、 expand 、 Train and execute inferences
Although the core of the package is ready , But there are still some scattered parts to be solved , for example :ARG2020 The data processing of dataset is not perfect , Not extended yet DataProcessor Class to allow hierarchical training test segmentation .
If you dig into arguments and NLP Interested in , And interested in this article , You can contact the of the project and apply to become a partner . Because the author wants to make this project a growing project and help more people to easily build the model of argument mining .
The project address is as follows :
https://avoid.overfit.cn/post/8bed8579a0c6485fab8c414dbf6eff90
author :yousefnami
边栏推荐
- The latest idea activation cracking tutorial, idea permanent activation code, the strongest in history
- The database connection code determines whether the account password is correct, but the correct account password always jumps to the failure page with wrong account password
- How to judge the advantages and disadvantages of low code products in the market?
- First knowledge of spark - 7000 words +15 diagrams, and learn the basic knowledge of spark
- [ES6] template string: `string`, a new symbol in es2015
- 'using an alias column in the where clause in PostgreSQL' - using an alias column in the where clause in PostgreSQL
- Article download address
- ASP. Net razor – introduction to VB loops and arrays
- [Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 8
- Data communication and network: ch13 Ethernet
猜你喜欢
Servlet learning notes
![Cadence physical library lef file syntax learning [continuous update]](/img/d5/0671935b074e538a2147dbe51a5a70.jpg)
Cadence physical library lef file syntax learning [continuous update]
22 API design practices
Btrace tells you how to debug online without restarting the JVM
![[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 23](/img/72/a80ee7ee7b967b0afa6018070d03c9.jpg)
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 23
![[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 14](/img/c5/dde92f887e8e73d7db869fcddc107f.jpg)
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 14
Realize cross tenant Vnet connection through azure virtual Wan
![[notes] in depth explanation of assets, resources and assetbundles](/img/e9/ae401b45743ea65986ae01b54e3593.jpg)
[notes] in depth explanation of assets, resources and assetbundles
ArgMiner:一个用于对论点挖掘数据集进行处理、增强、训练和推理的 PyTorch 的包
Fastlane 一键打包/发布APP - 使用记录及踩坑
随机推荐
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 14
记一次 Showing Recent Errors Only Command /bin/sh failed with exit code 1 问题
Ultimate bug finding method - two points
Global and Chinese markets for environmental disinfection robots 2022-2028: Research Report on technology, participants, trends, market size and share
The detailed installation process of Ninja security penetration system (Ninjitsu OS V3). Both old and new VM versions can be installed through personal testing, with download sources
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 19
22 API design practices
. Does net 4 have a built-in JSON serializer / deserializer- Does . NET 4 have a built-in JSON serializer/deserializer?
Lvs+kept highly available cluster
C language: find the length of string
17. Memory partition and paging
[solve the error of this pointing in the applet] SetData of undefined
C语言:求100-999是7的倍数的回文数
Games101 Lesson 8 shading 2 Notes
Openssl3.0 learning 20 provider KDF
Leetcode day 17
How to judge the advantages and disadvantages of low code products in the market?
Ml and NLP are still developing rapidly in 2021. Deepmind scientists recently summarized 15 bright research directions in the past year. Come and see which direction is suitable for your new pit
Kivy tutorial 08 countdown app implements timer call (tutorial includes source code)
[data clustering] section 3 of Chapter 4: DBSCAN performance analysis, advantages and disadvantages, and parameter selection methods