当前位置:网站首页>【Matlab印刷字符识别】OCR印刷字母+数字识别【含源码 1861期】
【Matlab印刷字符识别】OCR印刷字母+数字识别【含源码 1861期】
2022-06-11 06:43:00 【Matlab佛怒唐莲】
一、代码运行视频(哔哩哔哩)
【Matlab印刷字符识别】OCR印刷字母+数字识别【含源码 1861期】
二、OCR简介
OCR技术是光学字符识别的缩写, 是通过扫描等光学输入方式将各种票据、报刊、书籍、文稿及其它印刷品的文字转化为图像信息, 再利用文字识别技术将图像信息转化为可以使用的计算机输入技术。由于其应用前景广泛, 在应用领域有着重要的意义。
1 预处理部分
本部分可进一步细分为要素定位、二值化、切割、文字归整几个部分。由清分机或者高速扫描仪扫入的原始票据经过本部分的处理, 其识别要素如金额、日期按照单个汉字分别被存储为汉字点阵, 其中手写体大写汉字、印刷体大写汉字以及印刷体小写数字, 被存储为6464的点阵, 而手写的小写数字被存储为9680的点阵, 然后对此汉字点阵进行字符识别处理。由于某些种类的票据中, 即便为同一张票据, 其各要素的背景噪声都不相同, 所以对各不同要素区域采用了不同的二值化方法。在切割完成之后, 各要素已经成为单独的字符点阵, 文字归整则是针对单个字符点阵进行。票据上的金额、日期、帐号等都分别要经过上面的流程处理。
2 文字识别部分
按照识别系统所要识别的字符种类来分, 本系统需识别的文字有:印刷体汉字、印刷体数字、手写体汉字、手写体数字。按照识别要素, 系统包含日期识别、金额识别、帐号识别、磁码识别几个不同模块。
本系统对汉字识别采用了模板匹配方法, 对数字识别采用了人工神经网络方法。
模板匹配的基本原理是抽取未知文字的特征与事先存储好的标准的文字特征进行匹配, 在一定的距离或相似度测度下, 找出与未知文字的特征匹配得最好的标准特征, 将该标准特征所代表的文字作为未知文字的识别结果。
3 特征训练
训练是识别的基础, 标准特征的好坏直接影响到识别结果, 选取具有代表性的样本作为训练样本。训练前先将样本按一定的顺序存放起来, 训练样本也是64*64的点阵。与识别部分的特征抽取相对应, 训练部分的特征抽取也是在对文字图像进行规整和分割基础之上进行的。抽取的标准特征是每个汉字不同的样本的特征值的平均值, 还抽取了每个汉字的标准方差, 方差记录了每个字的离散度。标准特征和标准方差在识别过程中都有很重要的作用。
4 印刷体数字和英文字母识别算法开发
首先, 改进汉字识别算法, 必须充分考虑即将要开发的识别算法所要面对的识别对象与原有算法所面对的识别对象之间的区别。原算法是面对变形较大、笔划比较稠密的手写汉字, 而所开发的算法面对的是字形比较固定、笔划比较稀疏的小写数字, 相对来讲, 识别对象简单了很多。而且识别字符集也小了不少, 由原来的3755个汉字变为简单的十个数字, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 不过其中相似字仍然存在, 如5和6, 3和8; 其次是识别要求上的变化, 识别率由原来的手写汉字的识别率要求基本达到100%。
三、matlab版本及参考文献
1 matlab版本
2019b
2 参考文献
[1]张殿东,包常新,温尚卓.OCR技术在银行票据识别系统中的应用[J]. 山东科学. 2005,(02)
3 备注
简介此部分摘自互联网,仅供参考,若侵权,联系删除
边栏推荐
- 你知道IT人才外派服务报价是怎样的么?建议程序员也了解下
- ijkPlayer中的错误码
- 不同VLAN间的通信
- Pytest automated test - easy tutorial (01)
- UEFI finding PCI devices
- Open source cartoon server mango
- How exactly does instanceof judge the reference data type!
- Metasploitabile2 target learning
- Sohu employees encounter wage subsidy fraud. What is the difference between black property and gray property and how to trace the source?
- 347. top k high frequency elements
猜你喜欢

Redux learning (II) -- encapsulating the connect function

MongoDB安装

538. convert binary search tree to cumulative tree

Detailed installation instructions for MySQL
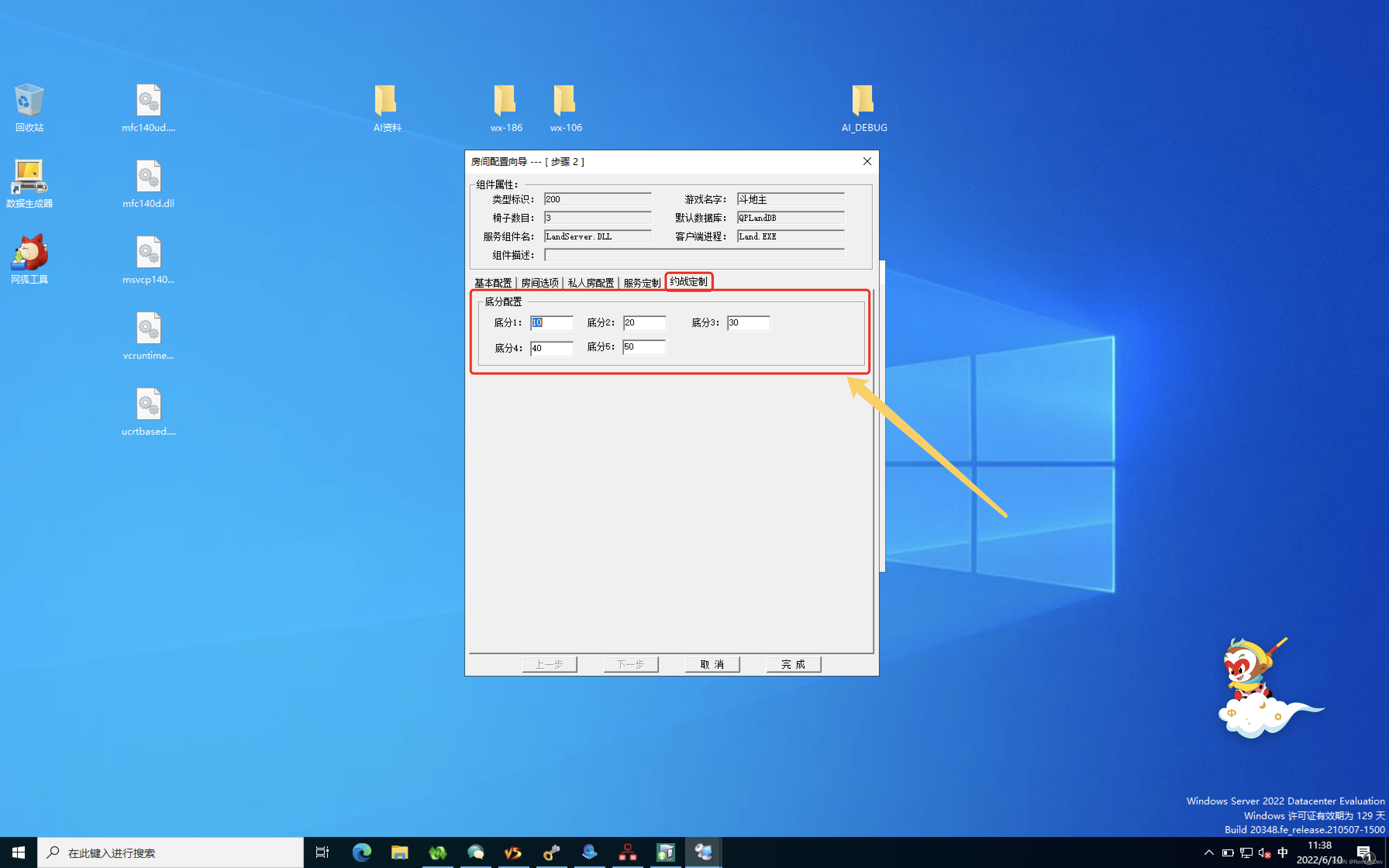
The realization of online Fox game server room configuration battle engagement customization function

Autojs, read one line, delete one line, and stop scripts other than your own
Communication between different VLANs

Implementation of customization function page of online Fox game server room configuration wizard service

On cursor in MySQL
538.把二叉搜索树转换成累加树
随机推荐
FMT package usage of go and string formatting
JVM from getting started to giving up 2: garbage collection
动态import
【Matlab WSN通信】A_Star改进LEACH多跳传输协议【含源码 487期】
On cursor in MySQL
Vulnhub's breach1.0 range exercise
Convert text label of dataset to digital label
UEFI查找PCI设备
JS judge whether the year is a leap year and the number of days in the month
538.把二叉搜索树转换成累加树
Who is stronger, zip or 7-Zip, and how to choose?
Do you use typescript or anyscript
SQL语言-查询语句
Open source cartoon server mango
QT socket setting connection timeout
EasyGBS接入的设备视频直播突然全部无法播放是为什么?数据库读写不够
022 basic introduction to redis database 0
572. subtree of another tree
Oracle prompt invalid number
QT script document translation (I)