当前位置:网站首页>Implementation of super large-scale warehouse clusters in large commercial banks
Implementation of super large-scale warehouse clusters in large commercial banks
2022-07-04 17:24:00 【51CTO】
This article is based on Teacher Chen Xiaoxin is 〖2021 Gdevops Global agile operations Summit - Guangzhou Railway Station 〗 The content of the live speech is organized .

Chen Xiaoxin
Jianxin Jinke DB Product owner
- have 8 year MPP Database work experience , CCB is developing a new generation MPP Architecture database Long Yun MPP DB Product owner , Responsible for CCB 4000 platform Greenplum Cluster planning 、 build 、 O & M and optimization .
Share summary
One 、 R & D background
Two 、 Application solutions
3、 ... and 、 Operation and maintenance solution
Hello everyone , I'm Chen Xiaoxin from CCB financial technology . It is a great honor to be here today to share our experience in the construction of super large-scale data warehouse clusters , We Jianxin Jinke introduced the technology of many cooperative companies , Jointly developed a product called Longyun MPP DB New generation cloud native data warehouse .
The data warehouse adopts metadata 、 Calculation 、 Storage three-tier separation architecture design , In the reserved MPP Under the premise of high-performance computing power of database , At the same time, it has high concurrency 、 High scalability 、 Dynamic resource scaling 、 Fault self-healing and other capabilities , It provides a foundation for the construction of super large-scale data clusters .
2020 year 3 month , The first application is launched on the data warehouse cluster . And then , Tieyuan 、 Public access 、 Journey management 、 Group consolidation 、 Bad assets and so on , Have been successfully launched . By the end of 2021 year 6 month , The scale of the data warehouse cluster has reached 16000 Servers , The amount of data exceeds 9PB, Run millions of jobs every day , function SQL Reach ten million level .

surface (1)

chart (2)
chart (3) It's our whole dragon MPP DB Monitoring screen of . You can see , Our current version is 3.9.8, Calculate the cluster size 79 set , And near 24 Hour run SQL Count 、 near 1 Run for hours SQL Count 、 The number of connections 、 Resource utilization 、 Various health conditions and other information .
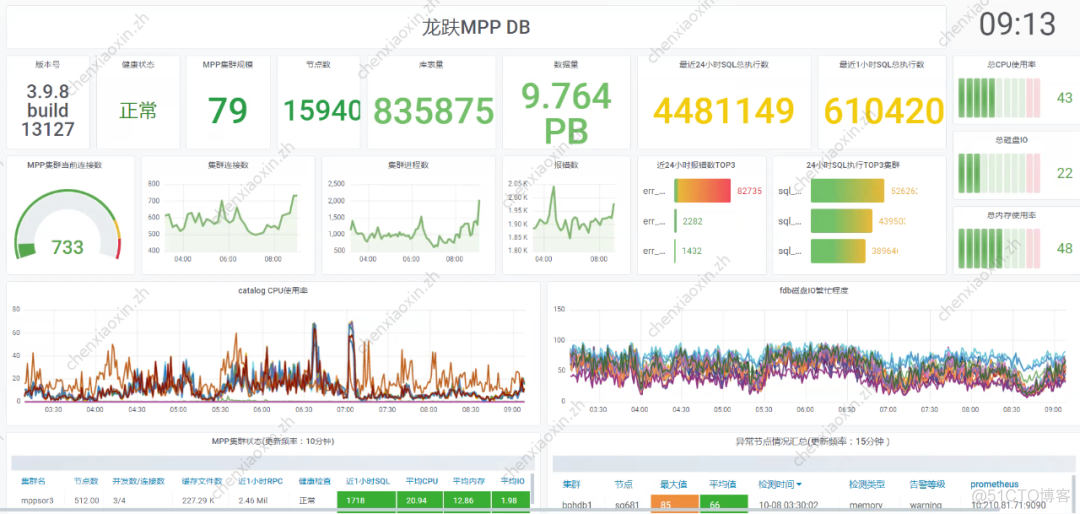
chart (3)
From tradition MPP database , To Longyun MPP DB, Here we first make a simple performance comparison .
Take the post source integration application of CCB as an example , Pictured (4). At present, we use Longyun in our post source application MPP DB Computing resources for , And the previous tradition MPP The computing resources of are basically equal , But the amount of data carried has reached the traditional MPP(200TB) Of 5 times , That is to say 1000TB.
Tieyuan runs every day 7 Ten thousand assignments ,100 About ten thousand SQL. chart (4) The graph on the left shows the number of jobs completed in each time period , It's on it base Job comparison , It's on it stage Job comparison . You can see , At every point in time , Red represents the Dragon MPP DB Number of jobs completed , Basically, it is larger than the tradition represented by blue MPP Number of jobs completed . in other words , When the amount of data expands 5 In the case of times , Long Yun MPP DB The performance of can still meet the application requirements .
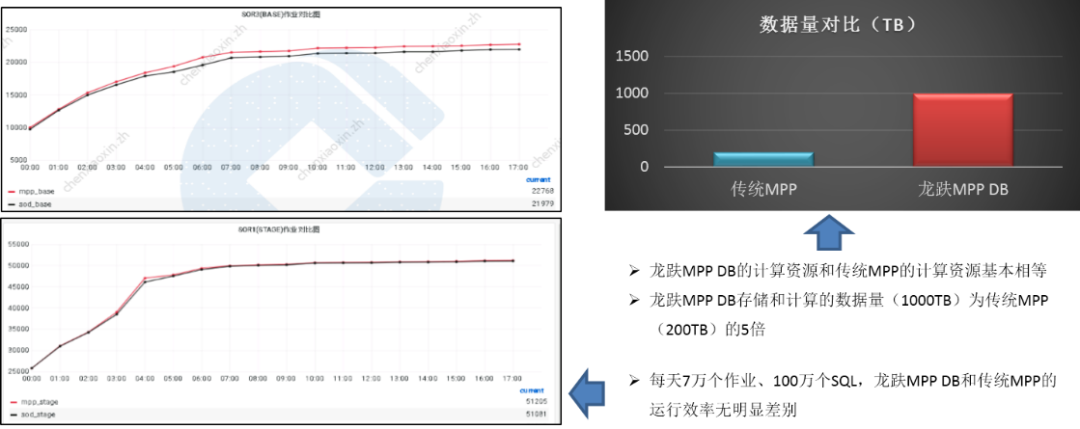
chart (4)
One 、 R & D background
CCB has been in the construction of several warehouses for more than 20 years , Great achievements have been made , But also encountered many problems . Tradition MPP Database products , There are several common problems :
- Insufficient concurrency and scalability , A large number of sub databases and sub tables cause serious data redundancy ;
- Data storage and calculation are not separated , This leads to serious database isolation ;
- upgrade 、 Capacity expansion 、 Fault recovery and other operations are complex and time-consuming , The operation and maintenance cost is high ;
- Non cloud native architecture , Dynamic resource scheduling is difficult , And it is difficult to integrate into the cloud construction of CCB .
To solve the above problems , Our dragon MPP DB emerge as the times require .
Long Yun MPP DB The logical architecture can be divided into two modules , One is the management module , One is the user module , Pictured (5). The management module is mainly responsible for the management of basic resources 、 Create cluster 、 Start stop 、 Expansion and contraction, monitoring and alarm services . User modules are divided into 3 layer , That is, the metadata layer 、 Computing tier and shared storage tier .
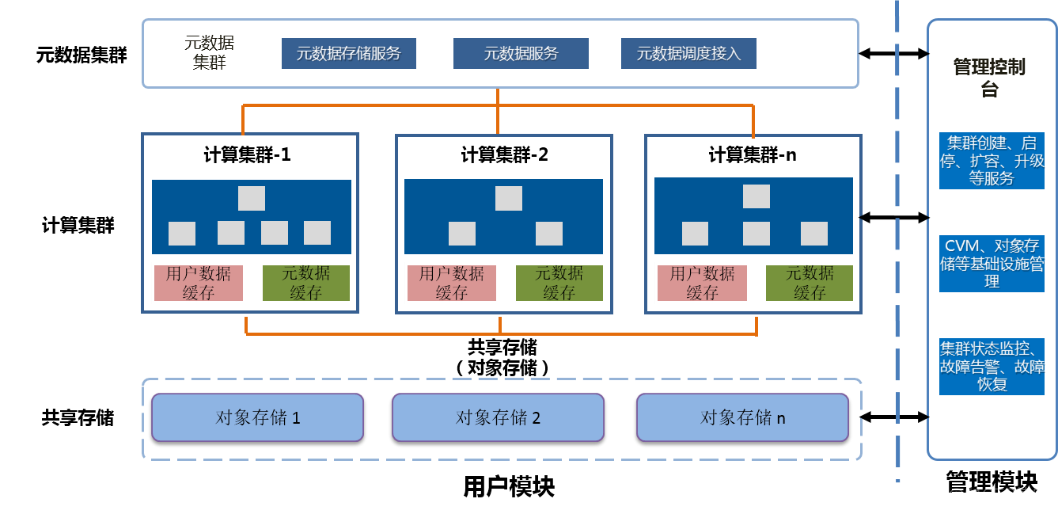
chart (5)
chart (6) It's our management console UI Interface . All resources are created 、 The destruction 、 Expansion and contraction capacity 、 upgrade 、 Fault self healing , And monitoring , This can be done on the console .
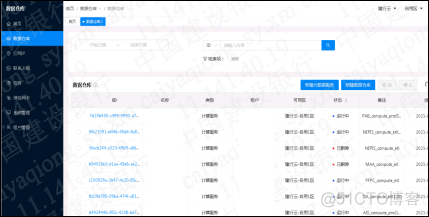
chart (6)
User module , chart (7) It's our metadata cluster , It is mainly used to provide metadata persistence storage, read and write 、 Business 、 Lock management and other services . Metadata cluster uses ETCD As service discovery and load balancing , Use FDB As a data storage layer . The stateless service layer in the middle is responsible for receiving and processing metadata requests from all computing clusters . Each layer of services can be expanded according to the load demand , To improve the service capacity .
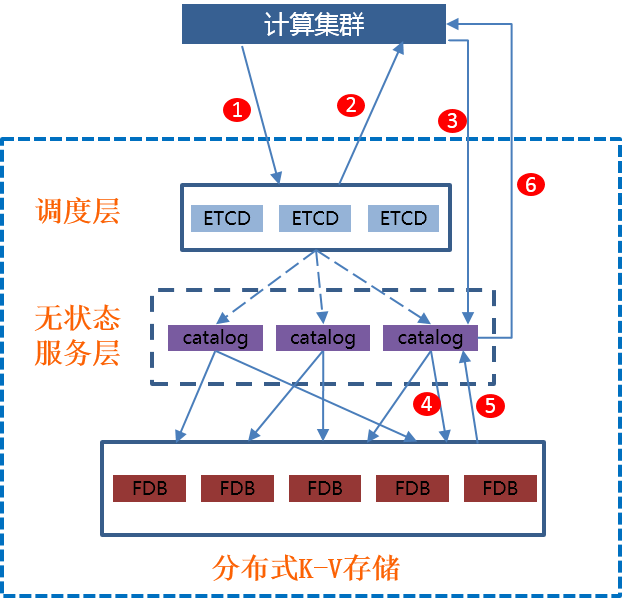
chart (7)
Next is the computing layer , Pictured (8). In the computing layer , Each computing cluster is a database service of independent computing resources , Users can create computing clusters on demand 、 Delete 、 Expand and shrink capacity etc , Jobs can also be flexibly deployed among existing computing clusters . When the concurrency and expansion capacity of a set of computing clusters are insufficient , Users can realize the linear expansion of concurrency by creating new clusters .
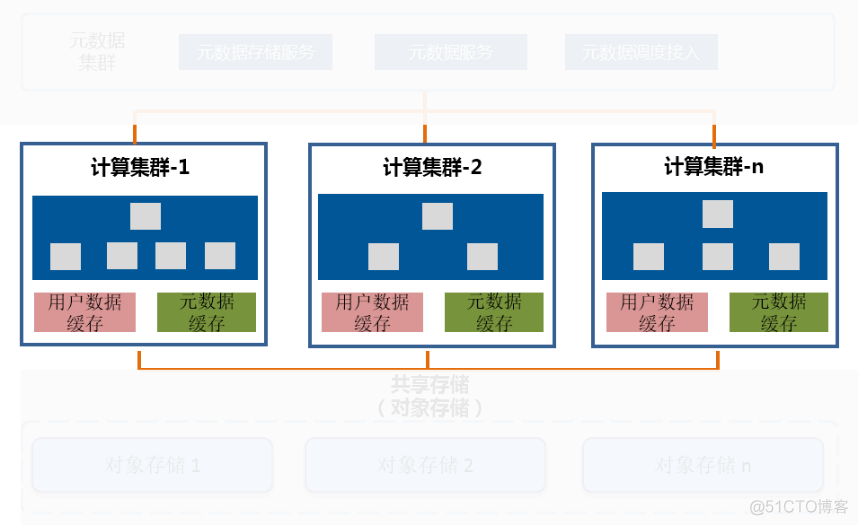
chart (8)
Finally, the shared storage layer , Pictured (9). Shared storage uses object storage to persist user data , Data is written once , All computing clusters share . By using the massive file storage of object storage 、 High concurrency 、 High availability and persistence of data , Meet the application of massive data access 、 High job concurrency 、 Data security and other requirements .
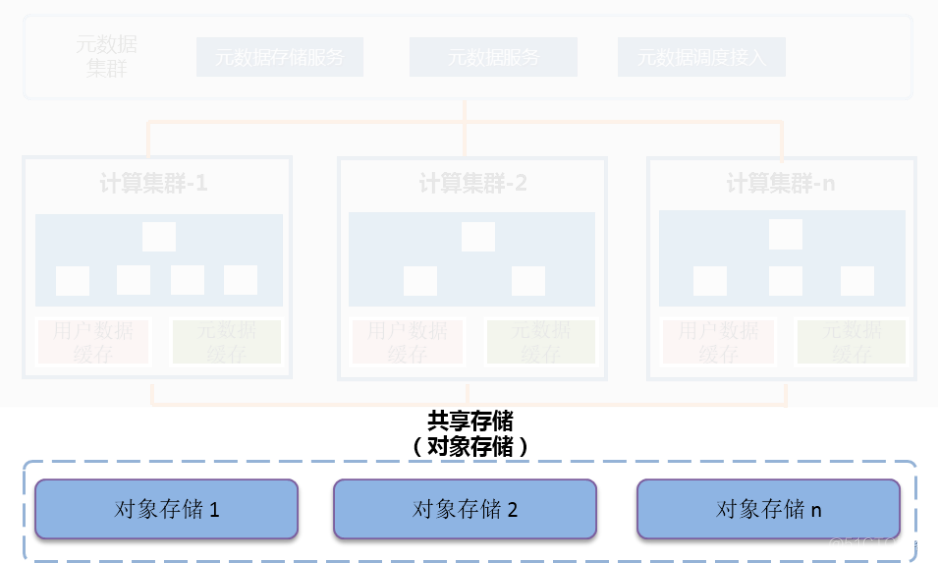
chart (9)
Two 、 Application solutions
By using dragon MPP DB Such a service hierarchy , The architecture of data sharing , We optimize our application solutions . Pictured (10), The traditional MPP database , The application construction is vertical chimney , Each application needs to create one or more independent clusters . A large amount of data needs to be replicated between different clusters , Managing complex , And the waste of resources is serious . And the use of dragon MPP DB, The computing and concurrency requirements of applications can be met by creating computing clusters , Data replication is no longer required , At the same time, application jobs can be flexibly scheduled to different clusters in real time according to requirements , Greatly improve application flexibility and resource utilization .
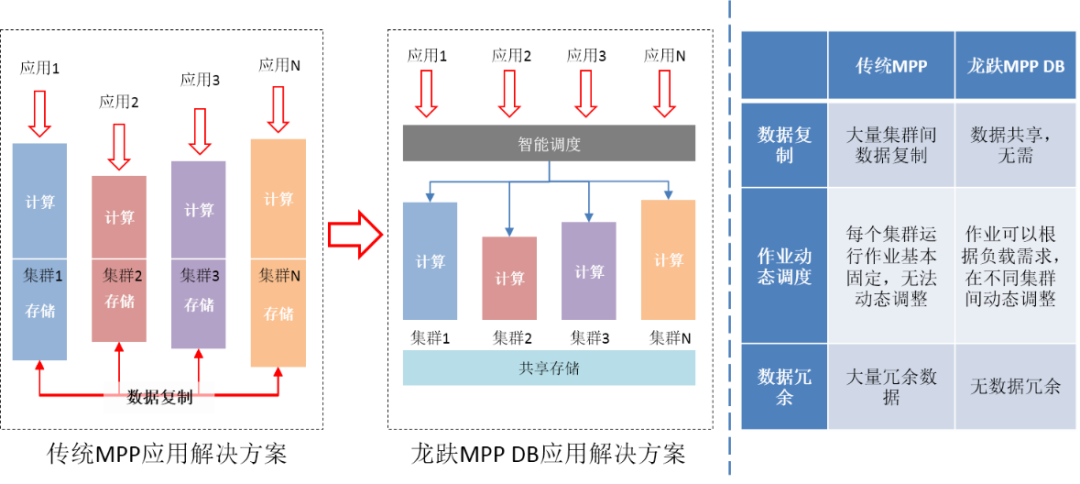
Pictured (10)
3、 ... and 、 Operation and maintenance solution
In terms of operation and maintenance , Long Yun MPP DB It also provides a more efficient and convenient solution , Pictured (11). Because of the Dragon MPP DB All computing clusters are stateless , With the help of IaaS Rapid resource supply of services , We can quickly complete the creation or destruction of some nodes and even the whole cluster . It looks like , We can realize the dynamic expansion of the cluster 、 Shrinkage capacity 、 Upgrade and other operations . When a node failure occurs , It can also quickly isolate and recover failed nodes , Realize self-healing of faults , Greatly improve the operation and maintenance efficiency .
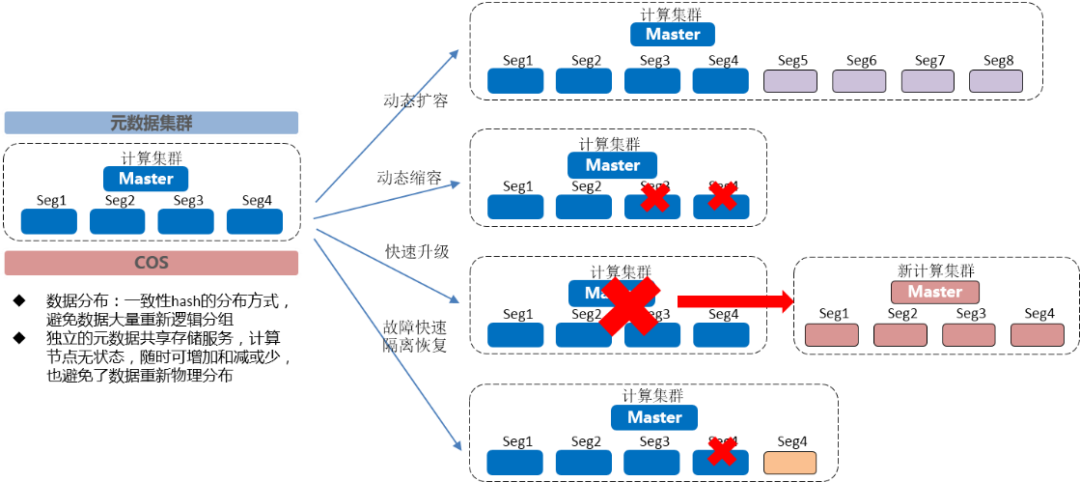
chart (11)
Over the past year , CCB Longyun MPP DB The server size of the cluster has increased 50 times , The amount of data has increased 45 times , There are already dozens of applications running on it . However, with the continuous increase of cluster size and application load , It turns out that all kinds of trivial problems have also begun to be solved by infinite methods , Cause a serious chain reaction :
- Ten billion levels of metadata every day RPC How to respond stably to requests ;
- How to efficiently meet the massive data access requirements of object storage ;
- How to efficiently operate and maintain a super large-scale cluster ;
- How to guarantee the high availability demand at the bank level .
To address these issues , We have carried out research and development in the following aspects .
Metadata service capability improvement , According to the service type and load , We split and distributed the metadata service , From the original day can handle a billion levels RPC request , Upgrade to a level that can handle 10 billion RPC request , While improving the service ability , It also improves high availability , Pictured (12):
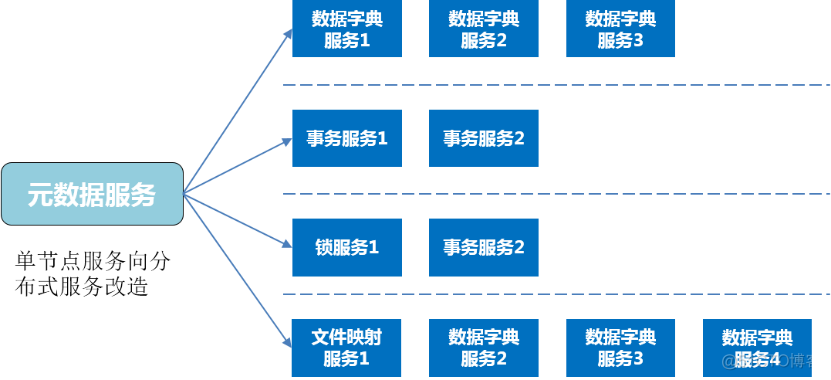
chart (12)
Storage service capability improvement , On the one hand, we merge through small files 、 Data prefetching 、 Unified cache layer establishment and other methods , Greatly reduce the pressure on storage ; On the other hand , Store each... For the object bucket The number of objects that can be stored and IO The problem of limited capacity , We create separate for each application tablespace, Every tablespace According to the demand, there are several bucket. This way bucket Split , Realize the shared storage IO Isolation and flow control , And avoid single bucket Problems of insufficient ability and inclination .
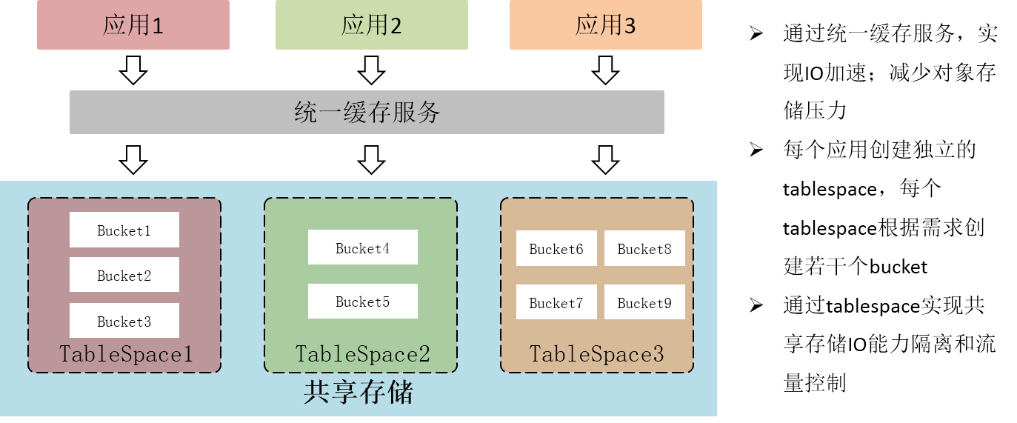
chart (13)
In terms of automatic monitoring and operation and maintenance , As mentioned earlier , Long Yun MPP DB It has the function of fault self-healing . meanwhile , By collecting jobs in real time 、SQL、 Storage 、 Server and other operation data , And aggregate and analyze these data , Such as whether the load meets historical expectations 、 Completion of key operations, etc , We can further judge whether the database performance is normal 、 Whether the load is inclined 、 Whether the resources are sufficient , And provide support for dynamic scheduling of resources and fault analysis and location , Pictured (14)、 chart (15).
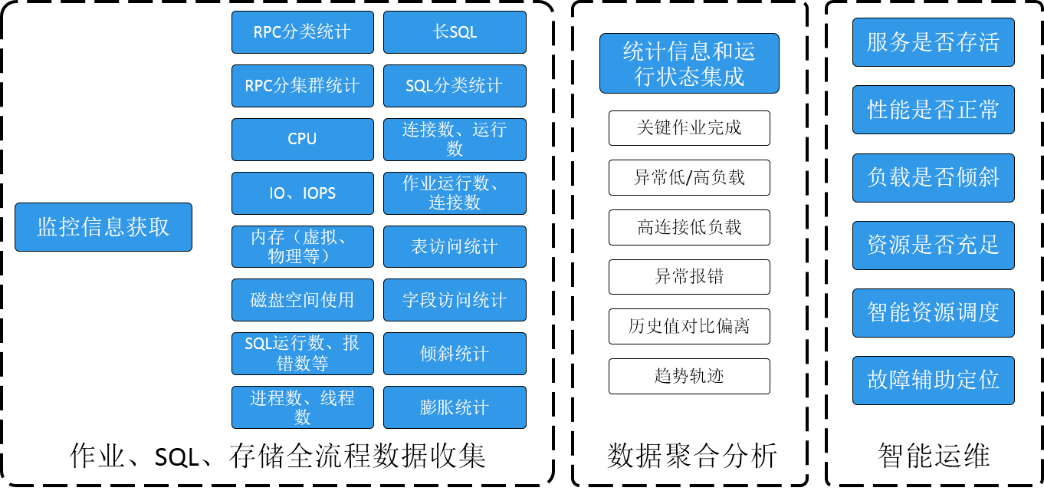
chart (14)
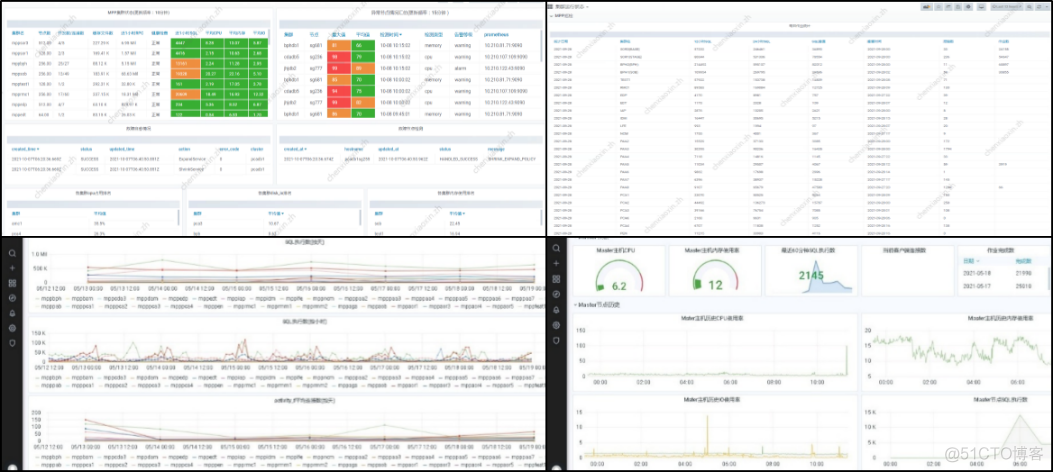
chart (15)
Finally, high availability guarantee . Everybody knows , The system used by the bank , The requirements for high availability are very high . Based on the original distributed architecture and the high availability guarantee of fault self-healing , In order to cope with the overall failure at the cluster level 、AZ Level service failure 、 Data loss / Delete by mistake , We also offer cross AZ Deploy 、 Continuous metadata backup 、 Double active deployment and other schemes , It further improves the level of Longyun MPP High availability service capability of , Pictured (16).
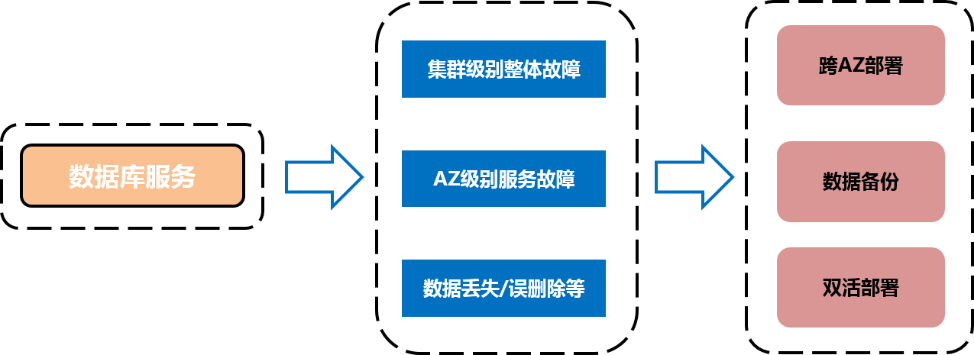
chart (16)
Over the past few years , We have completed countless version iterations and online optimization . The mature development of a database product , Need products 、 framework 、 Research and development 、 Operation and maintenance 、 The long-term cooperation and investment of many people, such as application . In the Dragon MPP DB On , We :
- It has gathered a large number of excellent R & D personnel from Jianxin Jinke and the industry ;
- Provides the most complex 、 Richest 、 The application scenario with the highest load ;
- CCB has more than 20 years of experience in data warehouse construction and operation , It can find product pain points fastest , Put forward the product design that best meets the needs of users .

边栏推荐
- [acwing] 58 weeks 4490 dyeing
- DataKit——真正的统一可观测性 Agent
- 散列表
- kaili不能输入中文怎么办???
- [glide] cache implementation - memory and disk cache
- 智慧物流园区供应链管理系统解决方案:数智化供应链赋能物流运输行业供应链新模式
- What grade does Anxin securities belong to? Is it safe to open an account
- OPPO小布推出预训练大模型OBERT,晋升KgCLUE榜首
- 【Unity UGUI】ScrollRect 动态缩放格子大小,自动定位到中间的格子
- NFT liquidity market security issues occur frequently - Analysis of the black incident of NFT trading platform quixotic
猜你喜欢

How to implement a delay queue?

智慧物流園區供應鏈管理系統解决方案:數智化供應鏈賦能物流運輸行業供應鏈新模式
容器环境minor gc异常频繁分析
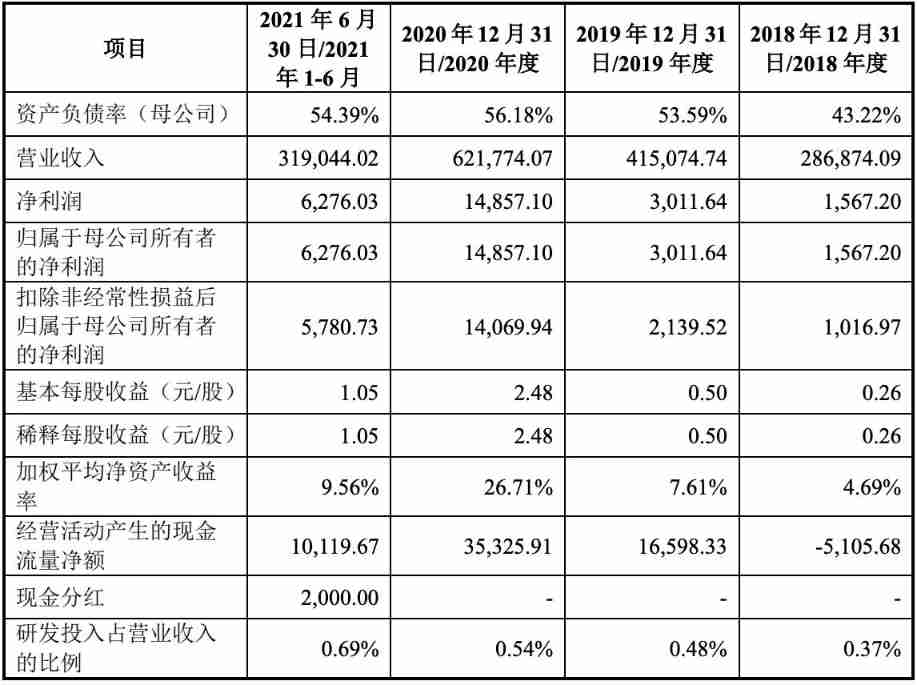
Yanwen logistics plans to be listed on Shenzhen Stock Exchange: it is mainly engaged in international express business, and its gross profit margin is far lower than the industry level
矿产行业商业供应链协同系统解决方案:构建数智化供应链平台,保障矿产资源安全供应

Ble HCI flow control mechanism
Vb无法访问数据库stocks
MVC模式和三层架构
智慧物流园区供应链管理系统解决方案:数智化供应链赋能物流运输行业供应链新模式

祝贺Artefact首席数据科学家张鹏飞先生荣获 Campaign Asia Tech MVP 2022
随机推荐
周大福践行「百周年承诺」,真诚服务推动绿色环保
PingCode 性能测试之负载测试实践
Solution du système de gestion de la chaîne d'approvisionnement du parc logistique intelligent
Yanwen logistics plans to be listed on Shenzhen Stock Exchange: it is mainly engaged in international express business, and its gross profit margin is far lower than the industry level
Is it safe for Anxin securities to open an account online? Is the account opening fee charged
[Acwing] 58周赛 4489. 最长子序列
Readis configuration and optimization of NoSQL (final chapter)
Visual Studio 2019 (LocalDB)MSSQLLocalDB SQL Server 2014 数据库版本为852无法打开,此服务器支持782
[Acwing] 58周赛 4490. 染色
Leetcode list summary
Spark 中的 Rebalance 操作以及与Repartition操作的区别
安信证券排名 网上开户安全吗
安信证券网上开户安全吗 开户收费吗
Can you really use MySQL explain?
Inside and outside: flow chart drawing elementary: six common mistakes
长城证券安全不 证券开户
GO开发:如何利用Go单例模式保障流媒体高并发的安全性?
如何实现一个延时队列 ?
Integration of ongdb graph database and spark
How to implicitly pass values when transferring forms