当前位置:网站首页>Pisa-Proxy SQL 解析之 Lex & Yacc
Pisa-Proxy SQL 解析之 Lex & Yacc
2022-07-07 14:51:00 【InfoQ】
一、前言
1.1 作者介绍
1.2 背景
二、编译器初探
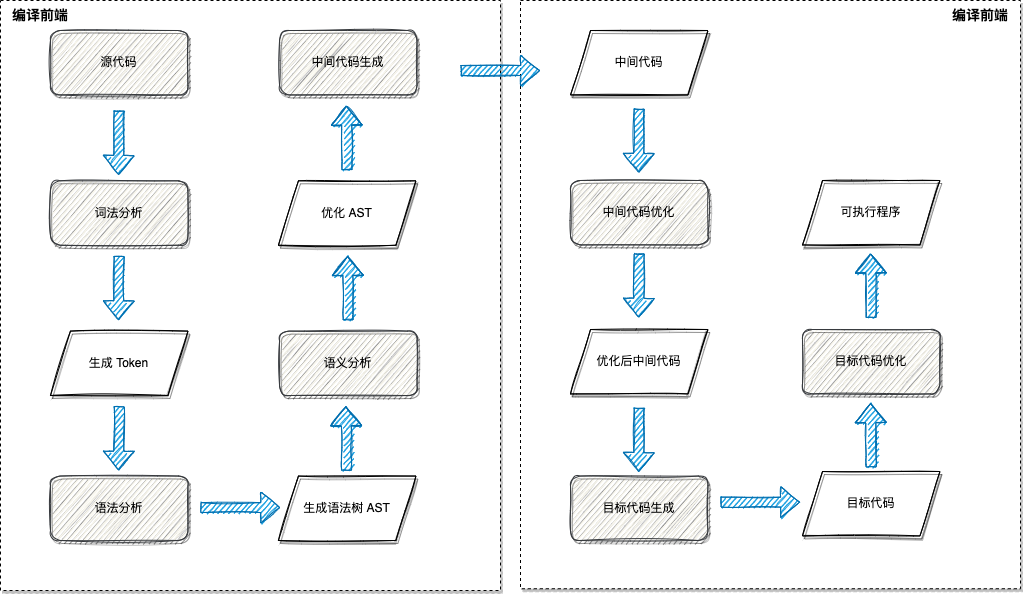
2.1 编译器工作流程
- 对源文件进行扫描,将源文件的字符流拆分分一个个的词(token),此为词法分析
- 根据语法规则将这些记号构造出语法树,此为语法分析
- 对语法树的各个节点之间的关系进行检查,检查语义规则是否被违背,同时对语法树进行必要的优化,此为语义分析
- 遍历语法树的节点,将各节点转化为中间代码,并按特定的顺序拼装起来,此为中间代码生成
- 对中间代码进行优化
- 将中间代码转化为目标代码
- 对目标代码进行优化,生成最终的目标程序
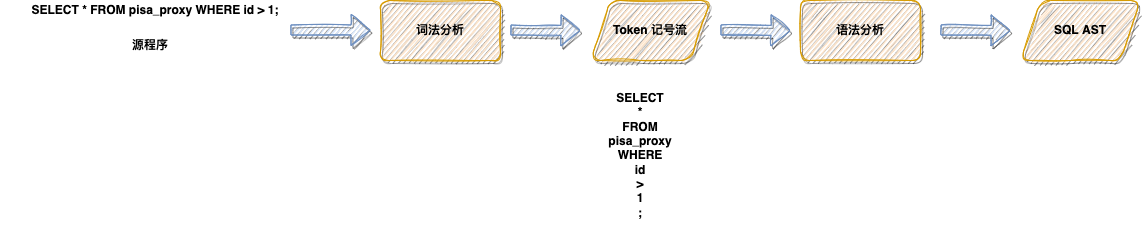
2.2 词法分析
SELECT*FROMpisa_proxySELECTINSERTDELETE2.2.1 直接扫描法
# -*- coding: utf-8 -*-
single_char_operators_typeA = {
";", ",", "(", ")","/", "+", "-", "*", "%", ".",
}
single_char_operators_typeB = {
"<", ">", "=", "!"
}
double_char_operators = {
">=", "<=", "==", "~="
}
reservedWords = {
"select", "insert", "update", "delete", "show",
"create", "set", "grant", "from", "where"
}
class Token:
def __init__(self, _type, _val = None):
if _val is None:
self.type = "T_" + _type;
self.val = _type;
else:
self.type, self.val = _type, _val
def __str__(self):
return "%-20s%s" % (self.type, self.val)
class NoneTerminateQuoteError(Exception):
pass
def isWhiteSpace(ch):
return ch in " \t\r\a\n"
def isDigit(ch):
return ch in "0123456789"
def isLetter(ch):
return ch in "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
def scan(s):
n, i = len(s), 0
while i < n:
ch, i = s[i], i + 1
if isWhiteSpace(ch):
continue
if ch == "#":
return
if ch in single_char_operators_typeA:
yield Token(ch)
elif ch in single_char_operators_typeB:
if i < n and s[i] == "=":
yield Token(ch + "=")
else:
yield Token(ch)
elif isLetter(ch) or ch == "_":
begin = i - 1
while i < n and (isLetter(s[i]) or isDigit(s[i]) or s[i] == "_"):
i += 1
word = s[begin:i]
if word in reservedWords:
yield Token(word)
else:
yield Token("T_identifier", word)
elif isDigit(ch):
begin = i - 1
aDot = False
while i < n:
if s[i] == ".":
if aDot:
raise Exception("Too many dot in a number!\n\tline:"+line)
aDot = True
elif not isDigit(s[i]):
break
i += 1
yield Token("T_double" if aDot else "T_integer", s[begin:i])
elif ord(ch) == 34: # 34 means '"'
begin = i
while i < n and ord(s[i]) != 34:
i += 1
if i == n:
raise Exception("Non-terminated string quote!\n\tline:"+line)
yield Token("T_string", chr(34) + s[begin:i] + chr(34))
i += 1
else:
raise Exception("Unknown symbol!\n\tline:"+line+"\n\tchar:"+ch)
if __name__ == "__main__":
print "%-20s%s" % ("TOKEN TYPE", "TOKEN VALUE")
print "-" * 50
sql = "select * from pisa_proxy where id = 1;"
for token in scan(sql):
print token
TOKEN TYPE TOKEN VALUE
--------------------------------------------------
T_select select
T_* *
T_from from
T_identifier pisa_proxy
T_where where
T_identifier id
T_= =
T_integer 1
T_; ;
reservedWordssingle_char_operators_typeA2.2.2 正则表达式扫描法
2.3 语法分析
你我他爱RustPisanix语句 -> 主语 谓语 宾语
主语 -> 我
主语 -> 你
主语 -> 他
谓语 -> 爱
宾语 -> Rust
宾语 -> Pisanix
产生式非终结符终结符起始符号语句 -> 主语 谓语 宾语
主语 -> 你|我|他
谓语 -> 爱
宾语 -> Rust | Pisanix
Expr => Expr Expr + Expr => SELECT Expr + Expr => SELECT number + Expr => SELECT number + number => SELECT 1 + 2
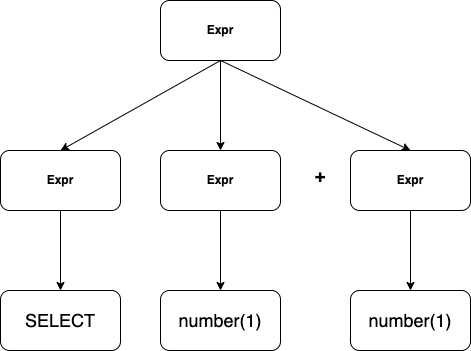
2.3.1 两种分析方法
- 自顶向下分析:自顶向下分析就是从起始符号开始,不断的挑选出合适的产生式,将中间句子中的非终结符的展开,最终展开到给定的句子。
- 自底向上分析:自底向上分析的顺序和自顶向下分析的顺序刚好相反,从给定的句子开始,不断的挑选出合适的产生式,将中间句子中的子串折叠为非终结符,最终折叠到起始符号
2.4 小结
三、认识 Lex 和 Yacc
3.1 认识 Lex
3.1.1 Lex由三部分组成
- 定义部分:定义段包括文字块、定义、内部表声明、起始条件和转换。
- 规则部分:规则段为一系列匹配模式和动作,模式一般使用正则表达式书写,动作部分为 C 代码。
- 用户子程序段:这里为 C 代码,会被原样复制到c文件中,一般这里定义一些辅助函数等,如动作代码中使用到的辅助函数。
%{
#include <stdio.h>
%}
%%
select printf("KW-SELECT : %s\n", yytext);
from printf("KW-FROM : %s\n", yytext);
where printf("KW-WHERE : %s\n", yytext);
and printf("KW-AND : %s\n", yytext);
or printf("KW-OR : %s\n", yytext);
[*] printf("IDENTIFIED : %s\n", yytext);
[,] printf("IDENTIFIED : %s\n", yytext);
[=] printf("OP-EQ : %s\n", yytext);
[<] printf("KW-LT : %s\n", yytext);
[>] printf("KW-GT : %s\n", yytext);
[a-zA-Z][a-zA-Z0-9]* printf("IDENTIFIED: : %s\n", yytext);
[0-9]+ printf("NUM: : %s\n", yytext);
[ \t]+ printf(" ");
. printf("Unknown : %c\n",yytext[0]);
%%
int main(int argc, char* argv[]) {
yylex();
return 0;
}
int yywrap() {
return 1;
}
# flex sql.l # 用 flex 编译 .l 文件生成 c 代码
# ls
lex.yy.c sql.l
# gcc -o sql lex.yy.c # 编译生成可执行二进制文件
# ./sql # 执行二进制文件
select * from pisaproxy where id > 1 and sid < 2 # 输入测试 sql
KW-SELECT : select
IDENTIFIED : *
KW-FROM : from
IDENTIFIED: : pisaproxy
KW-WHERE : where
IDENTIFIED: : id
KW-GT : >
NUM: : 1
KW-AND : and
IDENTIFIED: : sid
KW-LT : <
NUM: : 2
3.2 认识 Yacc
- 定义段和预定义标记部分:
%left%right- 规则部分:规则段由语法规则和包括C代码的动作组成。规则中目标或非终端符放在左边,后跟一个冒号(:),然后是产生式的右边,之后是对应的动作(用{}包含)
- 代码部分:该部分是函数部分。当Yacc 解析出错时,会调用
yyerror(),用户可自定义函数的实现。
%{
#include <stdio.h>
#include <string.h>
#include "struct.h"
#include "sql.tab.h"
int numerorighe=0;
%}
%option noyywrap
%%
select return SELECT;
from return FROM;
where return WHERE;
and return AND;
or return OR;
[*] return *yytext;
[,] return *yytext;
[=] return *yytext;
[<] return *yytext;
[>] return *yytext;
[a-zA-Z][a-zA-Z0-9]* {yylval.Mystr=strdup(yytext);return IDENTIFIER;}
[0-9]+ return CONST;
\n {++yylval.numerorighe; return NL;}
[ \t]+ /* ignore whitespace */
%%
%{
%}
%token <numerorighe> NL
%token <Mystr> IDENTIFIER CONST '<' '>' '=' '*'
%token SELECT FROM WHERE AND OR
%type <Mystr> identifiers cond compare op
%%
lines:
line
| lines line
| lines error
;
line:
select identifiers FROM identifiers WHERE cond NL
{
ptr=putsymb($2,$4,$7);
}
;
identifiers:
'*' {$="ALL";}
| IDENTIFIER {$=$1;}
| IDENTIFIER','identifiers
{
char* s = malloc(sizeof(char)*(strlen($1)+strlen($3)+1));
strcpy(s,$1);
strcat(s," ");
strcat(s,$3); $=s;
}
;
select:
SELECT
;
cond:
IDENTIFIER op compare
| IDENTIFIER op compare conn cond;
compare:
IDENTIFIER
| CONST
;
op:
'<'
|'='
|'>'
;
conn:
AND
| OR
;
%%
# 此处由于编译过程较为繁琐,此处仅为大家展示关键结果
# ./parser "select id,name,age from pisaproxy1,pisaproxy2,pisaproxy3 where id > 1 and name = 'dasheng'"
''Row #1 is correct
columns: id name age
tables: pisaproxy1 pisaproxy2 pisaproxy3
columntables四、Pisa-Proxy SQL 解析实现浅析
lex.rsgrammar.y五、总结
六. 相关链接:
6.1 Pisanix:
6.2 社区
七、参考资料
- 《编译原理》
- 《现代编译原理》
- https://github.com/mysql/mysql-server/blob/8.0/sql/sql_yacc.yy
- http://web.stanford.edu/class/archive/cs/cs143/cs143.1128/
边栏推荐
- three.js打造酷炫下雪效果
- 字节跳动高工面试,轻松入门flutter
- AutoLISP series (1): function function 1
- 01tire+ chain forward star +dfs+ greedy exercise one
- 【DesignMode】代理模式(proxy pattern)
- "The" "PIP" "entry cannot be recognized as the name of a cmdlet, function, script file, or runnable program."
- Three. JS series (2): API structure diagram-2
- 低代码(lowcode)帮助运输公司增强供应链管理的4种方式
- 二叉搜索树(特性篇)
- 【DesignMode】外观模式 (facade patterns)
猜你喜欢
![[Android -- data storage] use SQLite to store data](/img/f6/a4930276b3da25aad3ab1ae6f1cf49.png)
随机推荐
prometheus api删除某个指定job的所有数据
Logback logging framework third-party jar package is available for free
ORACLE进阶(六)ORACLE expdp/impdp详解
JS中null NaN undefined这三个值有什么区别
【医学分割】attention-unet
Imitate the choice of enterprise wechat conference room
Inner monologue of accidental promotion
深度监听 数组深度监听 watch
ByteDance Android gold, silver and four analysis, Android interview question app
[Android -- data storage] use SQLite to store data
Laravel changed the session from file saving to database saving
最新Android高级面试题汇总,Android面试题及答案
typescript ts 基础知识之类型声明
os、sys、random标准库主要功能
面向接口编程
Laravel post shows an exception when submitting data
Tragedy caused by deleting the console statement
目标跟踪常见训练数据集格式
JS modularization
three. JS create cool snow effect