当前位置:网站首页>High performance mysql (Third Edition) notes
High performance mysql (Third Edition) notes
2022-07-06 16:57:00 【Xiaoxiamo】
One 、MySQL Architecture and history
MySQL Logical architecture
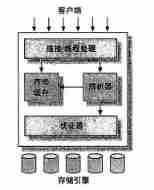
- The top services are not MySQL Unique , Most web based clients / Server tools or services have similar architectures . For example, connection processing 、 Authorized certification 、 Safety and so on.
- The second tier architecture is MySQL The more interesting part . majority MySQL The core service functions are all in this layer , Including query parsing 、 analysis 、 Optimize 、 Caching and all built-in functions ( for example , date 、 Time 、 Math and encryption functions ), All cross-storage engine functionality is implemented in this layer : stored procedure 、 trigger 、 View etc.
- The third layer contains the storage engine . The storage engine is responsible for MySQL The storage and extraction of data in . and GNU/Linux All kinds of file systems under are the same , Every storage engine has its advantages and disadvantages . Server pass API Communicating with the storage engine . These interfaces mask the differences between different storage engines , Make these differences transparent to the query process of the upper layer . Storage engine API Contains dozens of underlying functions , Used to perform tasks such as “ Start a transaction ” perhaps . Extract a row of records according to the primary key " Wait for the operation . But the storage engine doesn't parse SQL sex , Different storage engines don't communicate with each other , And simply respond to requests from the upper server
Optimization and execution
MySQL Will parse query , And create an internal data structure ( The parse tree ), And then optimize it , Including rewriting queries 、 Determine the read order of the table , And choosing the right index . Users can prompt through special keywords (hint) Optimizer , The decision-making process that affects it . You can also ask the optimizer to explain (explain) The elements of the optimization process , So that users can know how the server makes optimization decisions , And provide - A reference , It is convenient for users to reconstruct query and schema、 Modify the relevant configuration , Make the application run as efficiently as possible
The optimizer doesn't care what storage engine the table uses , But storage engines have an impact on optimizing queries . The optimizer will request the storage engine to provide capacity or cost information for a specific operation , And statistical information of table data
about SELECT sentence , Before parsing the query , The server will check the query cache first (Query Cache), If you can find the corresponding query , The server no longer has to perform query parsing 、 The whole process of optimization and execution , Instead, it directly returns the result set in the query cache
concurrency control
MySQL Achieve concurrency control at two levels : Server tier and storage engine tier
When dealing with concurrent read or write , The problem can be solved by implementing a system consisting of two kinds of locks . These two kinds of locks are often called Shared lock and exclusive lock , Otherwise known as Read lock and write lock . Read locks are shared , Or they don't block each other , Multiple customers can read the same data at the same time . And writing locks is exclusive , Only one user can write at a time , And prevent other users from reading the data being written
Lock granularity Refers to the size of the locked object . obviously , The smaller the size of the lock , The higher the efficiency of concurrency control . Various operations of lock , Including getting a lock 、 Check the lock, release the lock, etc , Will increase system overhead . therefore , If the system spends a lot of time managing locks , Instead of getting data , It will affect the system performance
There are two common shrink strategies , Table lock and row lock . Table locking costs less , But concurrency control is not good . Row level locking can well realize concurrency control , But it costs a lot
The so-called lock strategy , It is to find a balance between the cost of locks and the security of data , This balance will certainly affect performance . Most commercial database systems do not offer more choices , Generally, row level locks are applied to tables (row-level lock), And in a variety of complex ways to achieve , In order to provide better performance as much as possible when there are many locks . and MySQL There are many options . Each of these MySQL The storage engine can implement its own lock strategy and lock granularity
Business
Transactions take several operations as a whole , Or all , Or give it all up . Four characteristics of transactions ACID:
- Atomicity (atomicity): A transaction must be treated as an indivisible minimum unit of work , All operations in the whole transaction are either committed successfully , Either all failures roll back , For a transaction , It is impossible to perform only some of these operations
- Uniformity (consistency): The database always changes from one consistent state to another , For example, there is a transaction that includes four steps , From zero plus one , From one plus one , From two plus one , From three plus one , Then according to the principle of consistency , The end result must be 0 perhaps 4, Transition from one state to another
- Isolation, (isolation): Changes made by a transaction are made before the final submission , Is invisible to other transactions
- persistence (durability): Once the transaction is committed , The changes are permanently stored in the database
Isolation level
stay SQL The standard defines Four levels of isolation , Each level specifies the changes made in a transaction , Which are visible within and between transactions , What is invisible . A lower level of isolation can usually perform higher concurrency , The cost of the system is also lower
- READ UNCOMMITTED ( Uncommitted read ): stay READ UNCOMITTED Level , Changes in transactions , Even if it's not submitted , It is also visible to other transactions . Transactions can read uncommitted data , This is also called Dirty reading (Dirty Read)
- READ COMITTED ( Submit to read ): When a transaction begins , Only submitted modifications can be seen , And the changes are not visible to other transactions . One problem with this kind of existence is It can't be read repeatedly , It means business A After reading a record , Business B It was modified , When A When reading the data again, you will find that the result is different from the previous reading
- REPEATABLE READ ( Repeatable ): Repeatable reading solves , The problem that data cannot be read repeatedly , But it still can't solve unreal reading , So-called Fantasy reading , When a transaction is reading a range of records , Another transaction inserts a new record in the scope , When the previous transaction reads the records of this range again , Will produce Magic line (Phantom Row). This is a mysql Default level for ,mysql You can also use MVCC+ Clearance lock Solve the phantom reading problem
- SERIALIZABLE ( Serializable ): Transactions are executed serially , And lock each row of data , There may be a lot of timeout and lock contention problems
Four isolation levels and avoidable operations
- Read uncommitted【 The lowest level , Nothing can be avoided 】
- Read committed【 Avoid dirty reading 】
- Repeatable read【 Avoid dirty reading , It can't be read repeatedly 】
- Serializable【 Avoid dirty reading , It can't be read repeatedly , Virtual reading 】
Dirty reading 、 No repetition or unreal reading ( Virtual reading )
- Dirty reading : A transaction reads uncommitted data from another transaction
- It can't be read repeatedly : One transaction reads the committed data of another transaction , That is to say, one transaction can see the changes made by other transactions
- Fantasy reading ( Virtual reading ): It refers to the data inserted by other transactions in a transaction , Leading to inconsistent reading before and after
Deadlock
Two or more transactions occupy each other on the same resource , And request to lock the resources occupied by the other party , Which leads to a vicious circle
Transaction log
When the storage engine modifies the data of the table, it only needs to modify its memory copy , Record the modification to the transaction log persistent on the hard disk , Instead of persisting the modified data to disk every time . After the transaction log is persisted , The modified data in memory can be slowly flashed back to the disk in the background , It's called a write ahead log (Write-Ahead Logging), If data changes have been logged to the transaction log and persisted , But the data itself has not been written back to disk , At this point the system crashes , The storage engine can automatically recover this modified data when it is restarted . The specific recovery method depends on the storage engine .MySQL Provides two transactional storage engines : InnoDB and NDB Cluster, There are also some third-party storage engines
Multi version concurrency control
MySQL Most of the transactional storage engines implemented are not simple row level locks . Based on the consideration of improving concurrent performance , They generally implement multi version concurrency control at the same time (MVCC). It can be said that MVCC It's a variant of row lock , But it avoids lock operation in many cases , So the cost is lower . Although most engines have different implementation mechanisms , But most of them realize non blocking read operation , Write only locks the necessary lines . The typical ones are optimistic (optimistic) concurrency control and Pessimism (pessimistic) concurrency control
MVCC The implementation of the , It is achieved by saving a snapshot of the data at a certain point in time , And only in REPEATABLE READ and READ COMMITTED Working at two isolation levels . The other two isolation levels are the same as MVCC Are not compatible , because READ UNCONMITTED Always read the latest data lines , Instead of data lines that match the current transaction version . and SERIALIZABLE Will lock all read lines
MySQL Storage engine for
In the file system ,MySQL Put each database ( It can also be called schema) Save as a subdirectory of the data directory . Create table time ,MySQL A table with the same name will be created in the database subdirectory frm Definition of file preservation table . have access to SHOW TABLE STATUS LIKE ‘tablename’ \G Display information about the table 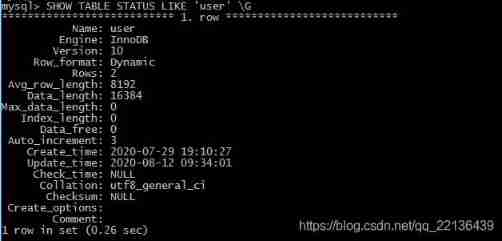
- Name: Table name
- Engine: The engine used by the table
- Version: Table version information
- Row_format: Line format , It usually contains variable length fields , Such as VARCHAR or BLOB
- Rows: Number of rows in the table
- Avg_row_ length: Average number of words per line
- Data_ length: The size of the table data
- Max_ data_ length: Maximum capacity of the table , This value is related to the storage engine
- Index_length: The size of the index
- Data_free: about MyISAM surface , Indicates the space allocated but not currently used
- Auto_ increment: next AUTO_ INCREMENT Value ,
- Create_time: Table creation time
- Update_ time: Last modification time of the table
- Check_ time: Use CKECK TABLE Order or myisamchk Time of last tool check list
- Col lation: Table's default character set and character column collation
- Checksum:: If enabled , Save the real-time checksum of the whole table
- Create_options: Other options specified when creating the table
- Comment : Comments when creating tables
InnoDB Storage engine
InnoDB yes MySQL The default transactional engine for , And most importantly 、 The most widely used storage engine .InnoDB Performance and auto crash recovery features , This makes it popular in the demand of non transactional storage . Unless there is a very, very special reason to use other storage engines , Otherwise, priority should be given to InnoDB engine
InnoDB use MVCC To support high concurrency , Well and achieved Four standard isolation levels . The default level is REPEATABLE READ ( Repeatable ), And through Clearance lock (next-key locking) Strategies to prevent the emergence of unreal reading . The gap lock makes InnoDB It's not just about locking the rows involved in the query , It also locks the gaps in the index , To prevent the insertion of phantom lines
InnoDB A lot of optimization has been done inside , Including the data collected when reading from the disk Predictability preview , Can automatically create... In memory hash Index to speed up read operations adaptive hash index (adaptive hash index), And can speed up the plug-in operation Plug into the buffer (insert buffer) etc. . These will be discussed in more detail later
MyISAM Storage engine
stay MySQL 5.1 And previous versions ,MyISAM It's the default storage engine .MyISAM There are a lot of features , Include full text index 、 Compress 、 Space function (GIS) etc. , but MyISAM Transaction and row level locks are not supported , And there is no doubt that the defect is Can't recover safely after a crash . therefore MySQL 5.1 Later version MySQL It is not used by default MyISAM The engine is on , be relative to InnoDB That little increase in concurrency ( Need some conditions ), These shortcomings let us not default the engine to MyISAM, For more than 90% of the cases, we need InnoDB,MyISAM Most of its advantages can be found in InnoDB Find an alternative , The same is true of other engines , therefore , If it's not a very special requirement , We mostly use InnoDB engine ,MyISAM Existing features
- Lock and concurrent :MyISAM Lock the whole watch , Not for the line
- Repair : about MyISAM surface ,MySQL Check and repair operations can be performed manually or automatically , But the concepts of repair, transaction recovery and crash recovery are different . Performing table repair may cause some data loss , And the repair operation is very slow
- Indexes : Support the index , And support full-text word segmentation index
MyISAM performance
MyISAM The engine design is simple , Data is stored in a compact format , So the performance is good in some scenarios , such as , Data is read-only , The table is relatively small , Can tolerate the failure of repair , In the scene of . Don't believe it easily “MyISAM Than InnoDB fast ” Saying things like, , In many scenarios , This conclusion is wrong , even to the extent that InnoDB It's faster than MyISAM so far behind that one can only see the dust of the rider ahead , For example, when using clustered indexes
Other engines
MySQL Some more Special purpose storage engine . In the new version , Some may no longer be supported for some reasons , It's not going to be explained one by one . that , There are so many engines , How should we choose , In a word :“ Unless you need to use something InnoDB Features not available , And there's no alternative to , Otherwise, we should give priority to InnoDB engine ." Easily switch engines , Turn to make things complicated and difficult , The worst thing is to overturn and run
Two 、MySQL The benchmark
The benchmark (benchmark) Also translated Standard inspection procedures , yes MySQL A basic skill that both novices and experts need to master . In short , Benchmarking is a kind of stress test for system design . The usual goal is to master the behavior of the system . For tuning , Accurate testing is quite important , Only when the test is correct can we know what the problem is , Can be improved
Benchmark the work done
- Verify some assumptions based on the system , Confirm whether these assumptions are in line with the actual situation
- Reproduce some abnormal behavior in the system , To resolve these exceptions
- Test the current operation of the system
- Simulate a higher load than the current system , To find out the scalability bottlenecks that the system may encounter as the pressure increases
- Planning for future business growth
- Test the application's ability to adapt to variable environments
- Testing different hardware 、 Software and operating system configuration
- Prove whether the newly purchased equipment is configured correctly
Benchmarking strategy
There are two main strategies for benchmarking : The first is the overall test of the whole system , The other is a separate test MySQL. These two strategies are also known as Integrated (ull-stack) as well as Single component (single-component) The benchmark . Do integrated test for the whole system , Instead of testing alone MySQL The main reasons are as follows :
- Users focus on the overall performance
- MySQL Not always a performance bottleneck
- Do the overall test , To find the problems caused by the caching between various parts
What kind of indicators to test
- throughput : The number of transactions per unit time , The common test unit is transactions per second (TPS), Or transactions per minute (TPM)
- Response time or delay : The overall time required for the test task , According to the specific application , The time unit of the test may be microseconds 、 millisecond 、 Seconds or minutes . The percentage response time is usually used (percentile response time) Instead of the maximum response time
- concurrency : What we need to pay attention to is the concurrent operation at work , Or the number of threads or connections working at the same time , Record... During the test MySQL Database Threads_running The status value
- Extensibility : Double the work of the system , In an ideal situation, it would be twice as effective ( That is, the throughput is doubled ), Very useful for capacity specifications , It can provide information that other tests cannot provide , To help find bottlenecks in the application
Benchmarking methods
When designing test conditions , Try to make the test process close to the real application scenario , A common mistake in benchmarking
- Use a subset of real data instead of a complete set
- Using the wrong data distribution
- In a multi-user scenario , Only do single user testing
- Testing distributed applications on a single server
- Does not match real user behavior
- Repeat the same query , Cause all or part of the cache
- No check for errors
- Ignoring system warm-up (warm up) The process of
- Use the default server configuration
- The test time is too short
- The test information collected is not complete
Some suggestions for benchmarking
- Specifications should be established to document parameters and results , Every round of testing must be recorded in detail
- Benchmarks should run long enough , It needs to be tested and observed in a steady state
- When performing benchmarking , Need to collect as much information as possible about the system under test
- Automated benchmarking prevents testers from occasionally missing steps , Or misoperation , It also helps to document the entire testing process , You can choose shell、php、perl etc.
- Try to automate all testing processes as much as possible , Including loading data 、 Warm up the system 、 Perform the test 、 Record the results, etc
3、 ... and 、 Server performance analysis
Introduction to performance optimization
- performance , A measure of the time required to complete a task , Performance is response time
- If the goal is to reduce response time , You need to understand why the server takes so much time to execute the query , Then reduce or eliminate the unnecessary work for obtaining the query results . If you can't measure it, you can't optimize it effectively
- Performance analysis (profiling) It's the main way to measure and analyze where time is spent , There are generally two steps : Measure the time spent on the task , Count and sort the results
Performance profiling of applications
Possible factors that affect performance bottlenecks
- External resources
- Applications need to deal with a lot of data
- Performing expensive operations in a loop
- Using inefficient algorithms
Diagnose intermittent problems
Intermittent problems such as system Pause occasionally perhaps The slow query , It's hard to diagnose . Some phantom problems occur only when they are not noticed , And it's impossible to confirm how to reproduce , Diagnosing such problems often takes a lot of time , Attention should be paid to :
- Try not to solve problems by trial and error , If you can't locate it for a while , Maybe it's the wrong way to measure , Or the measurement point is wrong , Or the tools used are not appropriate
- Determine whether there is a single query problem or a server problem
- Capture as much diagnostic data as possible
Other points to note
- The most effective way to define performance is response time
- If you can't measure, you can't effectively optimize , So performance optimization needs to be based on high quality 、 Comprehensive and complete response time measurement
- The best starting point for measurement is the application , Not a database . Even if the problem lies in the underlying database , Problems can also be easily found with good measurements
- Most systems cannot completely measure , Measurement sometimes has wrong results
- A complete measurement will produce a large amount of data to be analyzed , So you need an parser
- There are two time consuming operations : Work or wait
- Optimization and promotion are two different things . When the cost of continuing to increase exceeds the benefits , Optimization should stop
On the whole , Solutions to performance problems , The first is to clarify the problem , Then choose the right technology to answer these questions .
Four 、Schema With data type optimization
Good logical and physical design is the cornerstone of high performance , It should be designed according to the query statement that the system will execute schema, This often requires a balance of factors . for example , Anti normal design can speed up some types of queries , But it can also slow down other types of queries
Choose the optimized data type
MySQL Many data types are supported , Choosing the right data type is critical to achieving high performance . Here are some suggestions :
- Smaller ones are usually better : In general , Try to use the smallest data type that can store data correctly . Smaller data types are usually faster , Because they take up less disk 、 Memory and CPU cache , And what's needed to deal with it CPU There are fewer cycles
- Simple is good : Simple data type operations usually require less CPU cycle . for example , Integer is cheaper than character comparison
- Try to avoid NULL: A lot of tables contain can be NULL ( Null value ) The column of , Even if the application doesn't need to be saved NULL So it is with , This is because it can be NULL Is the default property of the column . In general, it's best to specify NOT NULL, Unless you really need storage NULL value . If the query contains NULL The column of , Yes MySQL Harder to optimize , Because it can be NULL The column makes the index 、 Index statistics and value comparisons are more complex . for NULL The columns of will use more storage space , stay MySQL It also needs special treatment
When selecting a data type for a column , The first step is to identify the appropriate large type : Numbers 、 character string 、 Time and so on , The second step is to choose the precision of the type
Integer types
MySQL Integer can specify width , Such as int(11), For most applications, it doesn't make sense : It doesn't limit the legal range of values , It's just a rule MySQL Some of the interactive tools used to display the number of characters . For storage and Computing ,int(20) and int(1) It's the same
Real number type
Because of the extra space and computational overhead , So try to use it only when calculating decimals decimal. When the amount of data is large , Consider using bigint Instead of decimal, Multiply the stored unit by the corresponding multiple according to the number of decimal places . for example : The financial data stored by the bank is accurate to 1 / 10000 , Then you can multiply all the amounts by one million , Then store the results in BIGINT in , In this way, we can avoid both imprecision and DECIMAL The high cost of accurate calculation
String type
CHAR Suitable for storing short short strings , Or all values are close to the same length . For frequently changing data ,CHAR Is better than VARCHAR good , Because of the fixed length CHAR It's not easy to produce fragments . For very short strings ,CHAR Is better than VARCHAR Better , because VARCHAR It also needs to be 1 or 2 Extra bytes to store string length .VARCHAR It is suitable for data with variable length and large range
Enumerations can be used instead of commonly used string types , Enumerations can store some non repeating strings into predefined collections . Enumeration fields are sorted by internally stored integers rather than strings . The bad thing about enumeration is when adding fields to enumeration , Need to use ALTER TABLE Statement to modify . therefore , For strings that may change in the future , Using enumerations is not a good idea
Date and time type
You should always try to use TIMESTAMP, It is better than DATETIME More efficient space , If you need to save the time to the millisecond level , have access to BIGINT
Bit data type
MySQL There are a few types of storage that use compact bits to store data . All these bit types , Regardless of the underlying storage format and processing , Technically speaking, they are all string types
have access to BIT Column stores one or more true/false value .BIT(1) Define a field containing a single bit ,bit(2) Store two bits .bit Columns store up to 64 bits MySQL take BIT As a string type , Not a number type . When searching bit(1) when , The result is a binary containing 0 or 1 String of values , instead of ASCII The code "0" or "1". then , When retrieving in a digital context , The result will be a number converted to a string
Select the identifier
If storage UUID value , Should be removed “-” Symbol ; Or better yet , use UNHEX() Function conversion .UUID The value is 16 Byte number , And stored in a BINARY(16) In the column . When searching, you can use HEX() Function to format in hexadecimal format
About object relational mapping (ORM) System
It's badly written schema Migration program , Or automatically schema The program , Will lead to serious performance waste . Some programs store everything using a lot VARCHAR Column , Object relation mapping (ORM) System ( And the way to use them “ frame ”) Is another common performance nightmare , some ORM The system will store any type of data into any type of back-end data store , This usually means that it is not designed to use better data types to store data. This design is very attractive to developers , Because this allows them to work in an object-oriented way , No need to think about how data is stored . However ,“ Hide complexity from developers ” The application of is usually not well extended . We recommend that you consider carefully before swapping performance for developer efficiency , And always in a real-size dataset . Do a test on , In this way, it will not be too late to find performance problems
MySQL schema Traps in design
- Too many columns : Too many columns , Not many columns are required , It is easy to cause conversion problems
- Too many connections :mysql Limit the maximum number of associations 61 A watch , A single query is suggested in 12 Within a table
- Omnipotent enumeration : Take care to prevent overuse of enumerations
- Enumeration in disguise : enumeration (ENUM) And collection (SET) Don't mix
- Not this invention (Not Invent Here) Of NULL: Avoid using NULL, And it is suggested to consider alternatives as much as possible , But if except NULL value , When there is no better substitute value , Make the most of it NULL Well , Because of the forced use of substitute values , There may be some procedural problems
Paradigms and anti paradigms
The advantages and disadvantages of paradigms
The normal updating operation is usually faster than the anti normal updating operation
When the data is well normalized , There is little or no duplicate data , So you just need to modify less data
The normalized table is usually smaller , Can be better placed in memory , So it's faster
Few redundant data means less need to retrieve list data DISTINCT perhaps GROUP BY sentence
Designed in a normal way schema The disadvantage is that there is usually a need for correlation . Slightly more complex query statements are in line with the paradigm schema It may need at least one connection , Maybe more . It's not only expensive , It may also invalidate some indexing strategies . for example , Paradigmatization may store columns in different tables , And if these columns are in - A table could belong to the same index
The advantages and disadvantages of anti paradigm
Avoid Correlation
Avoid random I/O
Use indexing strategies more effectively
The disadvantage of anti paradigm is that it is easy to cause data redundancy , And if there are too many columns in the table , Not much , It will waste query conversion performance
The fact is that , Complete normalization and complete anti normalization schema It's all in the lab : It is rare in the real world to use... So extreme . In practical application, it is often necessary to mix , It's possible to use some of the paradigmatic schema、 Cache table , And other techniques
Cache table 、 Summary and count sheets
Cache table It means that those can be stored simply from schema Other tables get data from tables .
The summary table Save is to use GROUP BY Statement aggregate data table , The reason for using summary tables is , Real time calculation and statistics are expensive operations , Because you either need to scan most of the data in the table , Or it can only run effectively on some indexes
Counter table It is a table used to count the number of operations , We can define a table named cnt To indicate the number of operations , Then add... After each operation 1. however , Add 1 Update operation is required to complete , Get the lock of the record every time you update , So concurrency efficiency is not high . Solve this problem , We can add some more fields slot As random slots , For example, increase 100 individual slot Field , Every time you perform an operation , We use random numbers to select a slot, And carry out +1 to update ( Only lock some data , So it's more efficient ). Add up all the records during the final statistics
Write more slowly , Faster reading
In order to improve the speed of reading query , You often need to build some extra indexes , Add redundant columns , Even creating cache tables and summary tables . These methods increase the burden of writing queries , Additional maintenance tasks are also required , But when designing high-performance databases , These are common skills : Even though writing is getting slower , But it significantly improves the performance of read operations
To speed up the ALTER TABLE Speed of operation
MySQL Of ALTER TABLE The performance of the operation is a big problem for large tables .MySQL The way to perform most operations to modify the table structure is , Lock the watch , Then create an empty table with the new structure , Find out all data from the old table and insert it into the new table , Then delete the old table . This operation may take a long time , If the memory is insufficient and the table is large , And this is especially true in the case of many indexes . generally speaking , Most of the ALTER TABLE Operation will result in MySQL Service interruption , Here are two DDL Operation skills , Avoid this situation :
- One is to execute on a machine that does not provide services ALTER TABLE operation , And then switch to the main library that provides the service
- Two is through “ Shadow copy ”, Create a new table , Then exchange two tables and the data in them by renaming and deleting tables
5、 ... and 、 Create high performance indexes
Indexes ( stay MySQL Also known as “ key (key)") It is a data structure used by the storage engine to quickly find records . Index optimization should be the most effective way to optimize query performance . Indexes can easily improve query performance by several orders of magnitude .
Index basis
The index of a database is similar to the index of a book , When actually looking for a value , First search by value , Then return the data row containing the value . An index can contain the values of one or more columns , If the index contains more than one column , Then the order of columns is also very important , The index sorts multiple columns based on CREATE TABLE Define the order of the index , therefore MySQL Only the leftmost prefix column of the index can be used efficiently , What we should pay attention to here is , Create an index with multiple columns , It's quite different from creating multiple indexes with only one column
ORM Tools can produce logical 、 Legitimate inquiries , Unless it's just generating very basic queries ( For example, query only according to the primary key ), Otherwise, it's hard to generate queries that are suitable for indexing
Type of index
There are many types of indexes , Can provide better performance for different scenarios . stay MySQL in , Indexes are implemented at the storage engine level, not at the server level . therefore , There is no uniform index standard : Different storage engines work differently , Not all storage engines support all types of indexes . Even if multiple storage engines support the same type of index , The underlying implementation may be different
B-Tree Indexes
What people usually call an index . In fact, many storage engines use B+Tree. here B-Tree The index applies to Full key value 、 Key range or Key prefix lookup ,B-Tree It usually means that all values are stored in order , And the distance from each leaf to the root is the same
type , Index with multiple columns key(last_name, first_name, dob) For example :
- Full match : Specify the person to query fitst_name, last_name and dob
- Match the leftmost prefix : Find the specified last_name The record of
- Match column prefix : Matches the beginning of the value of a column , such as last_name With J start
- Match range value : Match the value between some two indexes , for example Allen and Barrymore Between people
- Exactly match one column and range to another : lookup last_name by Allen, also first_name With k At the beginning
- Queries that only access the index :B-Tree Generally, it can support index only queries , That is, the query only needs to access the index , Without having to access the data lines
Because the nodes in the index tree are ordered , So in addition to searching by value , The index can also be used for ORDER BY operation ( Find in order ). Generally speaking , If B-Tree You can find values in some way , Then it can also be used to sort in this way . therefore , If ORDERBY Clause satisfies the query types listed above , Then this index can also meet the corresponding sorting requirements
B-Tree Some of the limitations of :
- If you don't search from the leftmost column , Index cannot be used . For example, unable to find only specified first_name perhaps dob The record of
- You can't skip columns in an index : You cannot specify only last_name and dob, that dob No index
- If there is a query range of a column when querying , Then all columns on the right cannot be searched by index optimization . For example, yes. last_name Used like, that first_name and dob Index will not be used
Hash index
Hash index (hash index) Implementation based on hash table , Only exact match Index all columns Is valid . For each row of data , The storage engine calculates a hash code for all index columns (hash code), The hash code is a smaller value , And the hash codes calculated by the lines with different key values are also different . Hash index stores all hash codes in the index , At the same time, store the pointer to each data row in the hash table , Because the index itself only needs to store the corresponding hash value , So the structure of the index is very compact , This also makes hash index lookup very fast . However , Hash index also has its limitations :
- Hash index only contains hash value and row pointer , Instead of storing field values , So you can't use the values in the index to avoid reading rows . however , Access to rows in memory is very fast , So in most cases, the impact on performance is not obvious
- Hash index data is not stored in the order of index values , So it can't be used for sorting
- Hash index also does not support partial index column matching lookup , Because the hash index always uses the entire content of the index column to calculate the hash value . for example , In the data column (A,B) Create a hash index on , If the query has only columns of data A, The index cannot be used
- Hash index only supports equivalent comparison query , Include =、IN()、<=> ( Be careful <> and <=> It's a different operation ). No scope queries are supported , for example WHERE price > 100
- Accessing hash index data is very fast , Unless there are many hash conflicts ( Different index column values have the same hash value ). When there is a hash conflict , The storage engine will store the values in the linked list , So at this time, you must traverse all row pointers in the linked list , Compare line by line , Until you find all the right lines
- If there are many hash conflicts , Some index maintenance operations are also expensive . The more conflicts , The more it costs
Because of these restrictions , Hash index is only suitable for some specific situations . And once it's fit for a hash index , The performance improvement it brings will be very significant .
Spatial data index (R-Tree)
MyISAM Tables support spatial indexes , It can be used as a geographic data store
Full-text index
Full text index is a special type of index , It looks for keywords in the text , Instead of comparing the values in the index directly . Full text search and other types of index matching is completely different . It has many details to pay attention to , Such as stop words 、 Stem and plural 、 Boolean search, etc . Full text indexing is more like what search engines do , Not simply WHERE Matching conditions . Create both full-text index and value-based index on the same column B-Tree No index conflicts , Full text index is suitable for MATCH AGAINST operation , Not the ordinary WHERE Conditional operation
There are also many third-party storage engines that use different types of data structures to store indexes , Such as typing tree index
The advantages of indexing
Index allows the server to quickly locate the specified location of the table . But that's not the only function of the index , So far we can see , Depending on the data structure in which the index is created , Indexes also have some other additional functions . To sum up, index has three advantages :
- Indexing greatly reduces the amount of data that the server needs to scan
- Indexes can help the server avoid sorting and temporary tables
- Index can be random I/O Change to order I/O
Index system
- The index puts the relevant records together to get a star
- If the order of the data in the index is the same as that in the search, two stars are obtained
- If the columns in the index contain all the columns needed in the query, then get Samsung
For small tables , Using full table scanning is more efficient ; For medium to large tables , Using indexes is very effective . For extra large tables , The cost of building and using indexes will increase . In this case, you can use partitions to find a set of data , Instead of matching one by one
High performance index strategy
MySQL EXPLAIN
EXPLAIN Command is a tool for querying table information , We can make the correct optimization behavior according to the query information , Therefore, it is necessary to add an introduction to its use 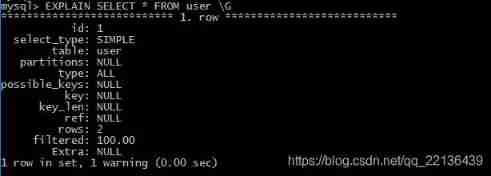
- id: Execution number , identification select What line you belong to . If there is no subquery or associated query in the statement , There is only one select, Each line will show 1. otherwise , The inner layer of the select Statements are usually sequentially numbered , Corresponds to its position in the original statement
- select_type:SELECT type , It can be any of the following
- SIMPLE: Simple SELECT( Don't use UNION Or subquery )
- PRIMARY: The outermost SELECT
- UNION:UNION The second or later of SELECT sentence
- DEPENDENT UNION:UNION The second or later of SELECT sentence , Depends on external queries
- UNION RESULT:UNION Result
- SUBQUERY: First in subquery SELECT
- DEPENDENT SUBQUERY: First in subquery SELECT, Depends on external queries
- DERIVED: Export table's SELECT(FROM A subquery of a clause )
- table: Access which table to refer to ( Quote a query , Such as “user”)
- type: Connection type . Here are the various connection types , Sort from the best type to the worst type :
- system: The watch has only one line (= The system tables ). This is a const A special case of a join type
- const: The table has at most one matching row , It will be read at the beginning of the query . Because there is only one line , The column values in this row can be considered constant by the rest of the optimizer .const The watch is fast , Because they only read once !
- eq_ref: For each row combination from the previous table , Read a row from the table . This is probably the best type of join , except const type
- ref: For each row combination from the previous table , All rows with matching index values are read from this table
- ref_or_null: The join type is like ref, But added MySQL You can search specifically for NULL Row of values
- index_merge: The join type indicates that the index merge optimization method is used
- unique_subquery: This type replaces the following form of IN The subquery ref: value IN (SELECT primary_key FROM single_table WHERE some_expr) unique_subquery Is an index lookup function , You can completely replace subqueries , More efficient
- index_subquery: The join type is similar to unique_subquery. Can replace IN Subquery , But it is only suitable for non unique indexes in sub queries of the following forms : value IN (SELECT key_column FROM single_table WHERE some_expr)
- range: Retrieve only rows in the given range , Use an index to select rows
- index: The connection type is the same as ALL identical , Except that only index trees are scanned . This is usually better than ALL fast , Because index files are usually smaller than data files
- ALL: For each row combination from the previous table , Do a full table scan
- possible_keys: Reveal which indexes might be helpful for efficient searching
- key: Show MySQL Actually decide which key to use ( Indexes ). If index is not selected , The key is NULL
- key_len: Show MySQL Determine the key length to use . If the key is NULL, The length of NULL
- ref: Shows which column or constant to use with key Select rows from the table together
- rows: Show MySQL The number of rows that it must check to execute the query . Multiplying the data between multiple rows can estimate the number of rows to process
- filtered: Shows the percentage estimate of the number of rows filtered by the condition
- Extra: This column contains MySQL Solve query details
- Distinct:MySQL Find the first 1 After a match line , Stop searching for more rows for the current row combination
- Not exists:MySQL Able to query LEFT JOIN Optimize , Find out 1 A match LEFT JOIN After the standard line , No longer check more rows in the table for the previous row combination
- range checked for each record (index map: #):MySQL No good index can be found , But found that if the column value from the previous table is known , Maybe some indexes can be used
- Using filesort:MySQL Need an extra pass , To find out how to retrieve rows in sort order
- Using index: To retrieve column information in a table from an actual row that uses only the information in the index tree without further search
- Using temporary: To solve the query ,MySQL You need to create a temporary table to hold the results
- Using where:WHERE Clause is used to restrict which row matches the next table or is sent to the customer
- Using sort_union(…), Using union(…), Using intersect(…): These functions show how to index_merge Join type merge index scan
- Using index for group-by: Similar to accessing tables Using index The way ,Using index for group-by Express MySQL Found an index , It can be used to check Inquiry GROUP BY or DISTINCT All columns of the query , Don't search the hard disk extra to access the actual table
Independent columns
If the columns in the lookup are not independent , be MySQL No index . Independent columns are index columns that cannot be part of an expression , It can't be an argument to a function
Prefix index and index selectivity
Indexing long strings will make the index larger and slower . It is usually possible to index only the characters at the beginning , This saves index space , So as to improve the efficiency of indexing . The disadvantage is that it will reduce the selectivity of the index . Index selectivity refers to the ratio of the index value without repetition to the total number of records , Obviously, the bigger the better . therefore , We need to choose a prefix long enough to ensure selectivity , At the same time, it cannot be too long to reduce the index space
We can use statements
select count(distinct left(col_name, 3)) / count(*) from tbl_name;
To count the use 3 Prefix selectivity of characters , Similarly, we can calculate 4 individual ,5 Wait a moment . Last , Choose a reasonable prefix length . After selecting the length, you can set the index of the specified length as follows :
alter table add key(col_nane(4));
Multi column index
Many people don't understand the multi column index enough . A common mistake is , Create a separate index for each column , Or create a multi column index in the wrong order
Building an independent single column index on multiple columns doesn't improve in most cases MySQL Query performance of .MySQL5.0 And newer versions introduced a “ Index merging ”(index merge) The strategy of , To some extent, multiple single column indexes on the table can be used to locate the specified row . Earlier versions of MySQL Only one of the single column indexes can be used , However, in this case, no independent single column index is very effective
But in MySQL 5.0 And updated version , Queries can be scanned using both single column indexes at the same time , And merge the results . There are three variations of this algorithm :OR Union of conditions (union) ,AND Intersection of conditions (intersection), Combine the Union and intersection of the first two cases .
Index merging strategies are sometimes the result of optimization , But more often than not, it shows that the index on the table is poorly built :
- When multiple indexes are intersected by the server ( There are usually multiple AND Conditions ), It usually means that you need a multi column index with all the related columns , Instead of multiple independent single column indexes .
- When the server needs to combine multiple indexes ( There are usually multiple OR Conditions ), It usually takes a lot of CPU And memory resources in the algorithm cache 、 Sorting and merging operations . Especially when the selectivity of some indexes is not high , When you need to merge a large amount of data returned by scanning
- what's more , The optimizer doesn't compute these into “ Query cost ”(cost) in , The optimizer only cares about random page reads . This will reduce the cost of the query “ underestimate ”, As a result, the implementation plan is not as good as a full table scan . Not only will it consume more CPU And memory resources , It may also affect the concurrency of queries , But if you run such a query alone, you often ignore the impact on concurrency . Generally speaking , It's better to be like MySQL4.1 Or in earlier times , Rewrite the query to UNION It's often better
If in EXPLAIN See index merge... In , You should check the structure of the query and table , See if it's the best . You can also use parameters optimizer_ switch To turn off index merging . You can also use IGNORE INDEX Prompt the optimizer to ignore some indexes
Select the appropriate index order
If you want to build an index on multiple columns , In addition to the above questions , You should also consider the order of columns in the index you build . such as , Yes col1, col2 Index two columns of data , Then our order should be specified as (col1, col2) still (col2, col1) Well . We need to know first , In a multi column B-Tree Index , The order of index columns means that the index is first sorted by the leftmost column , Next is the second column , wait . therefore , In the absence of special requirements , We can use selectivity to solve this problem , We can take the column with high selectivity as the first column of the index , The other column is the second column , And so on
Cluster index
Cluster index is not a separate index type , It's a kind of Data storage mode . The details depend on how it is implemented , but InnoDB The cluster index of is actually stored in the same structure B-Tree Index and data rows
When a table has a clustered index , Its data rows are actually stored in the leaf page of the index (leaf page) in . The term “ Clustering ” Indicates that data rows and adjacent key values are tightly stored together . Because you can't put rows in two different places at the same time , therefore A table can only have one clustered index
Because the storage engine is responsible for indexing , Therefore, not all storage engines support clustered indexes . Here we focus on InnoDB, But the principles discussed here are applicable to any storage engine that supports clustered indexing .
The following figure shows how records in a clustered index are stored . be aware , The leaf page contains all the data of the row , But the node page contains only index columns . In this case , The index column contains integer values , The index column in the figure is the primary key column 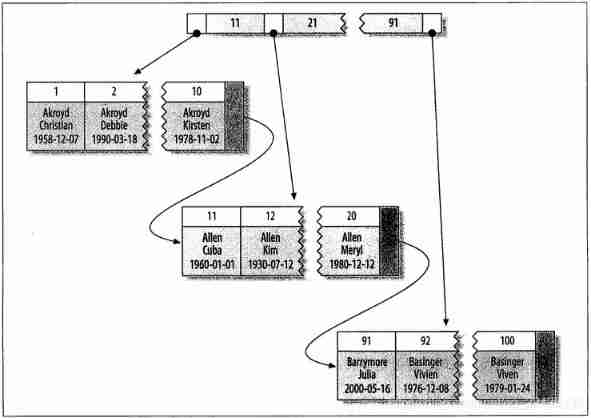
If there is no primary key defined ,InnoDB Will choose a unique non empty index instead of . If there is no such index ,InnoDB A primary key is implicitly defined as a clustered index .InnoDB Records that only aggregate on the same page . Pages with adjacent key values can be far apart
Clustered primary keys may be helpful for performance , But it can also lead to serious performance problems . Therefore, clustering index needs to be carefully considered , In particular, the storage engine of the table from InnoDB When you change to another engine ( And vice versa )
Aggregated data has some important advantages :
- You can save the relevant data together . For example, when implementing e-mail , According to the user ID To aggregate data , In this way, you only need to read a few data pages from the disk to get all the mail of a user . If clustering index is not used , Each message may result in a disk I/O
- Data access is faster . Clustering index keeps index and data in the same B-Tree in , Therefore, getting data from a clustered index is usually faster than looking up in a non clustered index
- Queries scanned with overlay index can directly use the primary key value in the page node
If you can make full use of the above advantages when designing tables and queries , That can greatly improve performance . meanwhile , Clustered indexes also have some disadvantages :
- Clustering data maximizes I/O Performance of intensive applications , But if all the data is in memory , The order of access is less important , Clustering index has no advantage
- The insertion speed depends heavily on the insertion order . Insert in the order of primary key is to load data into InnoDB The fastest way in the table . But if you don't load the data in primary key order , So it's best to use after loading OPTIMIZE TABLE Order to reorganize the table
- Updating clustered index columns is expensive , Because it forces InnoDB Move each updated row to a new location
- The table based on cluster index is inserting new rows , Or when the primary key is updated and the row needs to be moved , May face “ Page splitting (page split)” The problem of . When the primary key value of a row requires that the row be inserted into a full page , The storage engine will split the page into two pages to hold the row , This is a page splitting operation . Page splitting causes tables to take up more disk space
- Clustered indexes can slow down full table scans , Especially the rows are sparse , Or when data storage is discontinuous due to page splitting
- Secondary indexes ( Nonclustered index ) Maybe bigger than you think , Because the leaf node of the secondary index contains the primary key column of the reference row
- Secondary index access requires two index lookups , Not once
The last point may be puzzling , Why does a secondary index need two index lookups ? The answer lies in “ Row pointer ” The essence of . Remember , The secondary index leaf node does not hold a pointer to the physical location of the row , It's the primary key value of the row
This means finding rows through the secondary index , The storage engine needs to find the leaf node of the secondary index to obtain the corresponding primary key value , Then, according to this value, find the corresponding row in the cluster index . Repeated work has been done here : two B-Tree Find instead of once . about InnoDB, Adaptive hash index can reduce such duplication of work
InnoDB and MyISAM Data distribution comparison of
The data distribution of clustered index is different from that of non clustered index , And the data distribution of the corresponding primary key index and secondary index is also different , It usually makes people feel confused and unexpected . Let's see InnoDB and MyISAM How to store the following table :
CREATE TABLE layout_test (
col1 int NOT NULL,
col2 int NOT NULL,
PRIMARY KEY(col1),
KEY(col2)
);
Suppose the primary key value of the table is 1 ~ 10 000, Insert and use in random order OPTIMIZE TABLE The command is optimized . let me put it another way , The storage mode of data on disk has been optimized , But the order of rows is random . Column col2 The value of is from 1 ~ 100 Random assignment between , So there are many duplicate values
MyISAM Data distribution of
MyISAM The data distribution is very simple , So first introduce it .MyISAM Stored on disk in the order of data insertion , As shown in the figure below 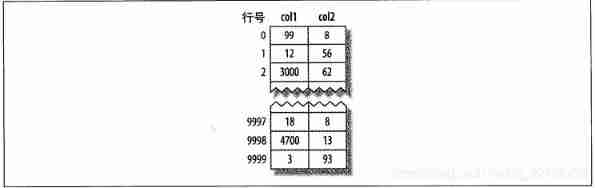
The line number is displayed next to the line ( Can be understood as address ), from 0 Began to increase . Because the line is fixed , therefore MyISAM You can skip the required bytes from the beginning of the table to find the required row (MyISAM Not always use the “ Line number ”, Instead, different strategies are used depending on whether the row is fixed or variable )
This distribution makes it easy to create indexes . The series of figures shown below , Hide the physical details of the page , Show only the “ node ”, Each leaf node in the index contains “ Line number ”. The following figure shows the primary key of the table 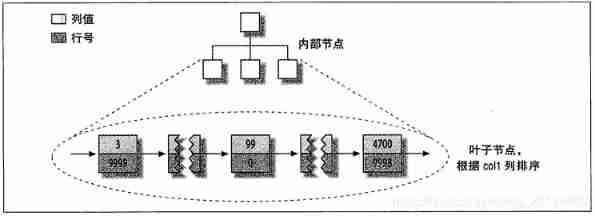
Some details are omitted here , For example, the previous B-Tree How many internal nodes does the node have , However, this does not affect the understanding of the basic data distribution of non clustered storage engines
that col2 What about the index on the column ? Is there anything special ? The answer is no difference , The image below shows col2 Index on column 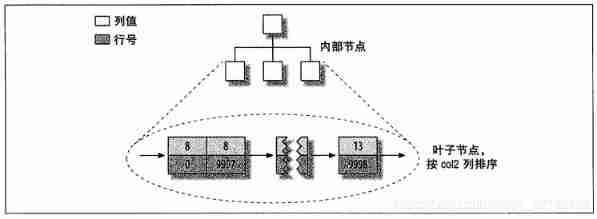
in fact ,MyISAM There is no structural difference between the primary key index and other indexes in . A primary key index is an index named PRIMARY Unique non empty index for
InnoDB Data distribution of
because InnoDB Support clustering index , So store the same data in very different ways .InnoDB Store data as shown in the following figure 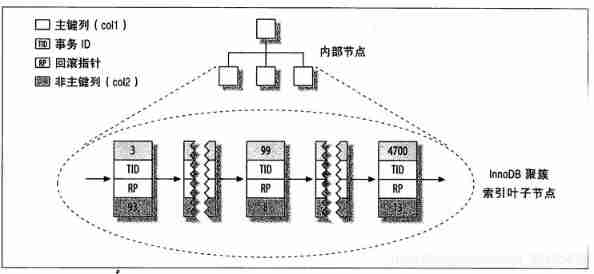
At first glance , Feel the figure and the previous MyISAM The primary key distribution diagram is no different , But look at the details carefully , Notice that the figure shows the entire table , Not just the index . Because in InnoDB in , Cluster index “ Namely ” surface , So it's not like MyISAM That requires independent row storage
Each leaf node of the clustered index contains Primary key value 、 Business ID、 For business and MVCC Of rollback pointer And all Remaining columns ( In this case, yes col2). If the primary key is a column prefix index ,InnoDB It will also contain the complete primary key column and other remaining columns
There's a little bit more and MyISAM The difference is that the ,InnoDB The secondary index of is very different from the clustered index .InnoDB The leaf node of the secondary index does not store “ Row pointer ”, It's the primary key value , And use this as a pointer to the line “ The pointer ” This strategy reduces the maintenance of secondary indexes in case of row movement or data page splitting . Using the primary key value as a pointer will make the secondary index occupy more space , The benefit is ,InnoDB There is no need to update this in the secondary index when moving rows “ The pointer ”
The following figure shows the col2 Indexes . Each leaf node contains index columns ( Here is col2), Next is the primary key value (col1). And shows B-Tree Leaf node structure , But we deliberately omit details such as non leaf nodes .InnoDB The non leaf node of contains the index column and a pointer to the subordinate node ( The next level node can be a non leaf node , It can also be a leaf node ). This applies to both clustered indexes and secondary indexes 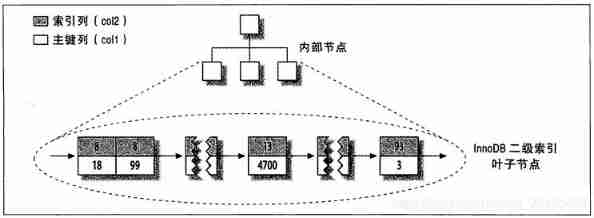
The following figure describes InnoDB and MyISAM How to store Abstract diagrams of tables . It is easy to see from the figure InnoDB and MyISAM The difference between saving data and indexing 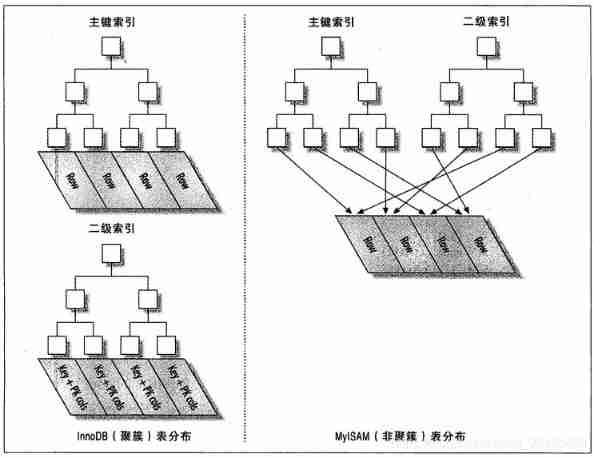
stay InnoDB Insert rows in the table in primary key order
If in use InnoDB And there's no data to aggregate , Then you can define a proxy key (surrogate key) A primary key , This kind of primary key data should have nothing to do with the application , The easiest way is to use AUTO_ INCREMENT On the column . This ensures that data rows are written in order , The performance of association operation based on primary key will also be better
It's better to avoid random ( Discontinuous and the distribution of values is very large ) Cluster index , Especially for 1/O Intensive application . for example , In terms of performance , Use UUID To be a clustered index would be bad : It makes the insertion of cluster index completely random , This is the worst case scenario , Make the data have no aggregation characteristics , Here are some shortcomings :
- The target page written may have been flushed to disk and removed from the cache , Or it hasn't been loaded into the cache yet ,InnoDB You have to find and read the target page from the disk to the memory before inserting . This will lead to a lot of randomness I/O
- Because writing people is out of order ,InnoDB We have to do page splitting frequently , To allocate space for new rows . Page splitting can lead to the movement of large amounts of data , At least three pages need to be modified at a time instead of one page
- Due to frequent page splits , Pages become sparse and filled irregularly , So eventually the data will be fragmented
After loading these random values into the clustered index , Maybe you need to do it once OPTIMIZE TABLE To rebuild tables and optimize page filling . It's not hard to see. , Use InnoDB You should insert data in primary key order as much as possible , And try to insert new rows by monotonically increasing the value of the cluster key
Overlay index
If an index contains the values of all the fields to be queried , It is called overlay index . Overlay index is to get query results directly from the index , To use overlay indexes, you need to pay attention select The query column is included in the index column , There is no need to query the table for the second time , So it's very fast ;where The condition contains the leading column of index column or composite index ; The field length of the query result should be as small as possible
Use Delayed correlation Solve the problem that the index cannot be overwritten : The following solutions are not absolute for improving efficiency
SELECT * FROM products WHERE actor = 'SEAB CARREY' AND title like '%APPOLO%'
above SQL All columns to be queried in , And we don't cover the index of all columns , Therefore, the index is not overwritten . in addition ,like Operation cannot use index , because like The operation can only use the index if it matches the left prefix
We can solve the problem like this :
SELECT * FROM products
JOIN (SELECT prod_id FROM products
WHERE actor = 'SEAB CARREY' AND title like '%APPOLO%')
AS t1 ON (t1.prod_id = products.prod_id)
here , You need to create (actor, title, prod_id) Indexes . We first find the matching in the sub query prod_id, Then match with the data in the outer layer to obtain all column values . When in line with where The number of conditional data is much smaller than actor When filtering out the amount of data , Its efficiency is particularly high . because , According to the subquery where After filtering out the data, it is associated with the outer query , The latter uses actor After reading the data , Reuse title Association . The former requires less data to be read
Sort by index scan
Two ways to generate ordered results : Sort , Scan in index order . When explain Out of type by index when , Description use index scanning to sort .MySQL You can use an index to satisfy both sorting , And satisfy the search . Only if the column order of the index and ORDER BY Consistent clause order , And the sorting directions of columns are the same , To sort the results by index
Redundant and duplicate indexes
MySQL Allows multiple indexes to be created on the same column , Whether intentionally or unintentionally . But a duplicate index refers to an index of the same type created in the same order on the same column . You should avoid creating duplicate indexes like this , It should also be deleted after discovery . Common mistakes are :
- When using primary keys and unique constraints, it conflicts with existing ones , Because the primary key and unique constraint are implemented by index , If the index is redefined, it will be redundant , for example : Inadvertently add an index to the primary key
- If an index is created (A,B) Then create the index (A) Then redundancy , Index (B,A) and (B) No , because (B) Not the leftmost prefix , Therefore, we should try to expand the existing index rather than create a new index
Index and lock
InnoDB Rows are locked only when they are accessed , The index can reduce the number of rows accessed , So indexing can reduce the number of locks
Maintain indexes and tables
That is, create the table with the correct type and add the appropriate index , The work is not over : You also need to maintain tables and indexes to make sure they work . The maintenance table has three main purposes : Find and fix the damaged table , Maintain accurate index statistics , Reduce debris
- CHECK TABLE Check the table for damage ,ALTER TABLE innodb_tb1 ENGINE=INNODB; Repair table
- records_in_range() Pass in two boundary values to the storage engine to get how many records there are in this range , about innodb Imprecise
- info() Returns various types of data , Including the cardinality of the index
- have access to SHOW INDEX FROM Command to see the cardinality of the index
- B-Tree Indexes can be fragmented , This reduces the efficiency of the query
6、 ... and 、 Query performance optimization
Why is the query speed slow
- If you want to optimize the query , Actually optimize its subtasks , Or eliminate some of the subtasks , Or reduce the number of subtasks performed , Or make subtasks run faster
- The lifecycle of the query can be viewed roughly in order : From the client , To the server , And then parse it on the server , Generate execution plan , perform , And return the result to the client
Slow query Foundation : Optimizing data access
Two analysis steps
- Verify that the application is retrieving more data than it needs
- confirm MySQL Whether the server layer is analyzing a large number of more than needed data rows
Whether unnecessary data is requested from the database
- Search for unnecessary records
- Associate multiple tables and return all columns
- Always take out all columns
- Repeatedly query the same data
MySQL Are additional records being scanned
- There are three indicators of query cost : response time 、 Number of lines scanned 、 Number of rows returned
- response time : The sum of service time and queuing time ,“ Fast upper bound estimation ” Law
- Number of lines scanned : Shorter rows get faster access , Rows in memory are also more accessible than rows on disk It's much faster
- Access type :EXPLAIN Medium type Column reflects the type of access ; By adding an appropriate index
- Three ways to apply WHERE Conditions : Use... In indexes WHERE Condition to filter mismatched records ; Use index overlay scan (Extra It appears that Using index) To return the record , Filter unwanted records directly from the index and return hit results ; Return data from a data table , Then filter the records that do not meet the conditions (Extra It appears that Using Where)
- Optimization techniques that scan a large amount of data but return only a few rows : Use index overlay scan , Change the library table structure , Rewrite complex queries
How to refactor the query
- MySQL By design, connecting and disconnecting are lightweight , Very efficient in returning a small query result
- Syncopation query , Divide big query into small query , Every query function is exactly the same , Only a small part of it , Only a small number of query results are returned at a time , You can avoid locking up a lot of data 、 Full transaction log 、 Drain system resources 、 Block a lot of small but important queries
- The advantage of decomposing Association query :
- Make caching more efficient
- After decomposing the query , Performing a single query reduces lock contention
- Making connections in the application layer , It's easier to split the database , It's easier to be high-performance and scalable
- Query itself may also be more efficient
- It can reduce the query of redundant records
- It is equivalent to realizing hash Association in the application , Instead of using MySQL Nested loop Association of
- Decompose the scenario of associated query
- When an application can easily cache the results of a single query
- Data can be distributed to different MySQL On the server
- When you can use IN() Instead of associated queries
- When using the same data table in a query
The basis of query execution
- Query execution path
- The client sends a query to the server
- The server first checks the query cache , If hit, return immediately , Otherwise move on to the next stage
- On the server side SQL analysis 、 Preprocessing , Then the optimizer generates the corresponding execution plan
- MySQL According to the execution plan generated by the optimizer , To invoke the storage engine API To execute the query
- Returns the result to the client
- MySQL The communication protocol between client and server is “ Half duplex ” Of , You can't cut a message into small pieces and send it independently , No flow control , Once a message starts to appear at one end , The other end has to receive the entire message to respond to it
- MySQL Usually, you need to wait until all the data has been sent to the client to release the resources occupied by this query , So receiving all the results and caching them usually reduces the pressure on the server
- State of the query ,SHOW FULL PROCESSLIST Command view :
- Sleep, The thread is waiting for the client to send a new request
- Query, The thread is executing the query or sending the result to the client
- Locked, stay MySQL Server layer , The thread is waiting for a table lock
- Analyzing and statistics, The thread is collecting statistics for the storage engine , And generate an execution plan for the query
- Copying to tmp table [on disk], The thread is executing the query , And copy the result set to a temporary table , Or you're doing GROUP BY operation , Either a file sort operation , Or is it UNION operation
- Sorting result, The thread is sorting the result set
- Sending data, Threads can transfer data between multiple states , Or generate a result set , Or returning data to the client
- Syntax parser and preprocessor , Pass the keyword will SQL Statement parsing , And generate a corresponding “ The parse tree ”, The parser will use MySQL Syntax rules validate and parse queries , The preprocessor is based on some MySQL The rule further checks that the parse tree is legal
- Query optimizer , Find the best execution plan , Use the basic cost optimizer , Will try to predict the cost of a query using an execution plan , And choose the one with the lowest cost , Use SHOW STATUS LIKE ‘Last_query_cost’; See how many data pages you need for random lookup
- Lead to MySQL The reason for the query optimizer selection error :
- The statistics are not accurate ,Innodb Unable to maintain accurate statistics of the number of rows in a data table, the cost estimation in the implementation plan is not equal to the actual implementation cost
- MySQL It's probably not the same as you think
- MySQL Never consider other queries executed concurrently
- MySQL It's not always cost based optimization
- MySQL Will not consider the cost of operations beyond its control
- Sometimes the optimizer can't estimate all the possible execution plans
- MySQL Types of optimizations that can be handled
- Redefine the order of the associated tables
- Convert external links into internal links
- Use the equivalent transformation rule
- Optimize COUNT()、MIN() and MAX(), stay EXPLAIN Can be seen in “Select tables optimized away”
- Estimate and convert to constant expression , When it is detected that an expression can be converted to a constant , The expression will always be optimized as a constant
- Overwrite index scan , When the columns in the index contain all the columns that need to be used in the query , You can use the index to return the data you need , You don't need to query the corresponding data row
- Sub query optimization
- Terminate query ahead of time , When it is found that the query requirements have been met ,MySQL Always be able to terminate the query immediately
- Equivalent transmission , If the values of two columns are related by an equation , that MySQL Can put one of the columns into WHERE Pass the condition to another column
- list IN() Comparison ,MySQL take IN() Sort the data in the list first , Then the binary search method is used to determine whether the values in the list meet the conditions
- There are query optimizers in the server layer , It doesn't save statistics on data and indexes , Statistics are implemented by the storage engine , Different storage engines may store different statistics
- stay MySQL in , Every query , Every fragment ( Include subqueries , Even single table based SELECT) It could be a connection
- about UNION Inquire about ,MySQL First, put a series of single query results into a temporary table , Then read out the temporary table data again to complete UNION Inquire about
- MySQL Do... For any association “ Nested loop Association ” operation , namely MySQL First, loop out a single piece of data in a table , Then nest it in the next table to find the matching row , Go down in turn , Until you find the matching behavior in all tables
- All outer joins can't be done by nested loops and backtracking , When no matching row is found in the associated table , It is possible that the association starts from a table that does not have any matches ,MySQL External connection not supported
- Association query optimizer , An attempt is made to select the one with the lowest cost in all association orders to generate the execution plan tree , If possible , The optimizer will traverse each table and then do a nested loop one by one to calculate the cost of each possible execution tree , Finally, an optimal execution plan is returned
- If there is more than n Association of tables , Then it needs to be checked n The order of factorial Association of , be called “ search space ”, Search space is growing very fast
- In any case, sorting is a costly operation , So in terms of performance , Try to avoid sorting or sorting large amounts of data as much as possible
- When the index cannot be used to generate sort results ,MySQL You need to sort it yourself , If the amount of data is small, it is stored in memory , If you have a large amount of data, you need to use disk ,MySQL Call this process file sorting (filesort), This is true even when there are no disk files needed for a full memory sort
MySQL Limitations of the query optimizer
- Associated subquery :MySQL The subquery of is poorly implemented , The worst kind of query is WHERE Conditions include IN() Subquery statement of , Use GROUP_CONCAT() stay IN() Construct a comma separated list in , Or use EXISTS() To rewrite
- UNION The limitation of : Sometimes ,MySQL It's not possible to remove restrictions from the outer layer “ Push down ” To the inner layer , This makes it impossible to apply the conditions that can limit some of the returned results to the optimization of inner layer query
- MySQL You can't take advantage of the multi-core feature to execute queries in parallel
- MySQL Hash association is not supported ,MariaDB Hash correlation has been implemented
- MySQL Loose index scanning is not supported ,5.0 Later versions can use loose index scanning when they need to find the maximum and minimum value of grouping in grouping query
- about MIN() and MAX() Inquire about ,MySQL The optimization of is not good
Query optimizer tips
- HIGH_PRIORITY and LOW_PRIORITY, When multiple statements access a table at the same time , Which statements have higher priority 、 Which statements have a lower priority
- DELAYED, Yes INSERT and REPLACE It works , The statement that uses the prompt is immediately returned to the client , And put the inserted row data into the buffer , Then write the data in batch when the table is idle , Not all storage engines support , And the hint causes the function LAST_INSERT_ID() Not working properly
- STRAIGHT_JOIN, It can be placed in SELECT Of the statement SELECT After keyword , It can also be placed between the names of any two associated tables . The first usage is to associate all tables in the query in the order they appear in the statement , The second rule is to fix the order of the two tables
- SQL_SMALL_RESULT and SQL_BIG_RESULT, Only right SELECT Statement is valid , They tell the optimizer to GROUP BY perhaps DISTINCT Query how to use temporary tables and sort
- SQL_BUFFER_RESULT, Tell the optimizer to put the query results into a temporary table , Then release the watch lock as soon as possible
- SQL_CACHE and SQL_NO_CACHE, tell MySQL Whether the result set should be cached in the query cache
- SQL_CALC_FOUND_ROWS, I'll calculate and remove LIMIT The total number of result sets to be returned by this query after clause , And actually just return to LIMIT Required result set , You can do this through a function FOUND_ROW() Get this value
- FOR UPDATE and LOCK IN SHARE MODE, Main control SELECT The lock mechanism of the statement , But only for storage engines that implement row level locking , only InnoDB Support
- USE INDEX、IGNORE INDEX and FORCE INDEX, Tell the optimizer which indexes to use or not to use to query records
- MySQL5.0 The new parameters used to control the behavior of the optimizer :
- optimizer_search_depth, Control the limits of the optimizer in exhaustive execution
- optimizer_prune_level, Let the optimizer decide whether to skip some execution plans according to the number of rows to scan
- optimizer_switch, Contains some open / Turn off flag bits for optimizer features
Optimize specific types of queries
- Optimize COUNT() Inquire about
- COUNT() It's a special function , There are two very different functions : You can count the number of values in a column , You can also count the number of rows , The column value is required to be non empty when calculating the column value ( No statistics NULL)
- COUNT(*) It's not going to expand to all the columns as we thought , actually , It ignores all columns and counts all rows directly , When MySQL Confirm that the expression value in brackets cannot be empty , It's actually counting lines
- MyISAM Of COUNT() Function only has no WHERE Under the condition of COUNT(*) Very fast
- Use an approximation , Such as EXPLAIN The resulting optimizer estimates the number of rows
- Use index overlay
- Use summary tables
- Using an external caching system
- Optimize associated queries
- Make sure ON perhaps USING There is an index on the column in the clause
- Make sure that any GROUP BY and ORDER BY The expression in involves only columns in a table
- When upgrading MySQL Need to pay attention to : Relevance grammar 、 Operator priority and other places that may change
- Optimize subqueries
- If possible, use association queries instead of , If you use MySQL5.6 Above or MariaDB You can ignore this suggestion
- Optimize GROUP BY and DISTINCT
- Use index optimization
- When the index is not available ,GROUP BY Use two strategies to accomplish : Use temporary tables or file sorting to group
- As far as possible, will WITH ROLLUP( Super aggregation ) Functions are handled in mobile applications
- Optimize LIMIT Pagination
- The easiest way to do this is to use the index overlay scan as much as possible , Instead of querying all columns , Then do an association operation as needed and return the required columns ,select id,name,…… from table innert join (select id from table order by xxx limit 5000,5) as table1 USING(id);
- offset It can lead to MySQL Scan a lot of unnecessary lines and discard them , If you can record the location of the data taken last time , Next time you can start scanning directly from the position of the record , Can be avoided offset
- Use a pre calculated summary , Or related to a redundant table
- Optimize UNION Inquire about
- Execute... By creating and populating temporary tables UNION Inquire about , So many optimization strategies are UNION It doesn't work well in queries , It is often necessary to manually put WHERE、LIMIT、ORDER BY I'm going to go down to UNION In each subquery of
- Unless you really need the server to eliminate duplicate rows , Otherwise, we must use UNION ALL
7、 ... and 、MySQL Advanced features
Partition table
For users , Partition table is a separate logical table , But the underlying layer is made up of multiple physical child tables , It's actually a handle object to a set of underlying tables (Handler Object) Encapsulation
Applicable scenario :
- The table is so large that it can't all be in memory , Or just have hot data at the end of the table , The rest is historical data
- Partition table data is easier to maintain
- The data of partition table can be distributed on different physical devices , So as to efficiently utilize multiple hardware devices
- You can use partition tables to avoid some special bottlenecks
- if necessary , You can also back up and restore separate partitions
Usage restriction :
- A watch can only have at most 1024 Zones
- stay MySQL5.1 in , The partition expression must be an integer , Or an expression that returns an integer . stay MySQL5.5 in , In some scenarios, columns can be used directly to partition
- If the partition field has a primary key or a unique index column , Then all primary key columns and unique index columns must be included
- Foreign key constraints cannot be used in partition tables
Use partition table
When the amount of data is huge ,B-Tree The index won't work , Except for index overlay queries , Otherwise, the database server needs to return the table according to the result of index scanning , Check all the records that meet the requirements , If there's a lot of data , There will be a lot of random I/O
Two strategies to ensure the scalability of large amounts of data :
- I scan the data , Don't index anything
- Index data , And separate the hot spots
The problem of partition strategy :
- NULL Value invalidates partition filtering
- Partition column does not match index column
- The cost of choosing a zone can be high
- The cost of opening and locking all the underlying tables can be high
- The cost of maintaining partitions can be high
- All partitions must use the same storage engine
- There are also some restrictions on the functions and expressions that can be used in partition functions
- Some storage engines don't support partitioning
- about MyISAM The partition table , No more use LOAD INDEX INTO CACHE operation
- about MyISAM surface , You need to open more file descriptors when using partition tables
Query optimization
It's important to be in WHERE The partition column is brought into the condition
You can filter partitions only when you compare the columns themselves using partition functions , Instead of filtering the partition based on the value of the expression , Even if this expression is a partition function, it doesn't work
View
- The view itself is a virtual table , Don't store any data , The data returned is MySQL Generated from other tables
- MySQL Two algorithms are used : Merge algorithm (MERGE) And temporary table algorithm (TEMPTABLE), Will use the merge algorithm as much as possible
- If the view contains GROUP BY、DISTINCT、 Any aggregate function 、UNION、 The subquery etc. , As long as it is impossible to establish one-to-one mapping between the original table record and view record ,MySQL Will use the temporary table algorithm to implement the view
- Updatable view (updatable view) It means that the related tables involved in the view can be updated by updating the view ,CHECK OPTION Represents any row updated by the view , Must conform to the view itself WHERE Condition definition
- In refactoring schema You can use views when you want to , When modifying the underlying table structure of the view , The application code may continue to run without error
- MySQL Materialized views are not supported in ( It refers to storing the view result data in a table that can be viewed , And periodically refresh the data from the original table into this table )
- The original view definition is not saved SQL sentence
Foreign key constraints
- There is a cost in using foreign keys , It is usually required to perform one more lookup operation in another table every time the data is modified
- If you want to make sure that two related tables always have consistent data , So using a foreign key is much better than checking consistency in an application , In the deletion and update of related data , It's also more efficient than maintenance in applications
- Foreign keys can bring a lot of extra cost
stay MySQL Internal storage code
MySQL Allow through triggers 、 stored procedure 、 Function to store code , from 5.1 At the beginning, you can also store code in timing tasks , This timed task is also known as “ event ”. Stored procedures and stored functions are collectively referred to as “ Storage program ”
The advantages of storing code :
- It executes inside the server , Closest to the data , In addition, executing on the server can also save bandwidth and network latency
- This is a kind of code reuse , Business rules can be easily unified , Make sure that certain actions are consistent , So it can also provide some security for applications
- It simplifies code maintenance and version updates
- Can help improve security , For example, provide more fine-grained permission control
- The server can cache the execution plan of the stored procedure , This is for procedures that need to be called repeatedly , It will greatly reduce consumption
- Because it's deployed on the server side , So backup 、 Maintenance can be done on the server side
- Better division of labor between application developers and database developers
The disadvantages of storing code :
- MySQL It doesn't provide a good development and debugging tool
- Compared to the application code , Storing code is a little less efficient
- Storing code can add extra complexity to the deployment of application code
- Because stored programs are deployed in the server , So there may be security risks
- Stored procedures put extra pressure on the database server , The scalability of database server is much worse than that of application server
- MySQL There are no options to control resource consumption of stored programs , So a small error in the stored procedure , Maybe drag the server to death
- Store code in MySQL There are also many limitations to the implementation of —— Execution plan caching is connection level , The materialization of cursors is the same as that of temporary tables , Exception handling is also very difficult
- debugging MySQL The stored procedure of is a very difficult thing
- It doesn't work well with statement based binary projection log replication
For the above reasons, Alibaba manual forbids the use of stored procedures SQL
Restrictions on stored procedures and functions :
- The optimizer cannot use keywords DETERMINISTIC To optimize multiple calls to stored functions in a single query
- The optimizer cannot evaluate the execution cost of the storage function
- Each connection has its own cache of execution plans for stored procedures
- Stored programs and replication are a weird combination
trigger : It allows you to perform INSERT、UPDATE perhaps DELETE When , Perform certain operations , Can be in MySQL Is specified in SQL Whether a statement is triggered before execution or after execution , You can use triggers to enforce some restrictions , Or some business logic , otherwise , You need to implement this logic in your application
Attention and limitations of triggers :
- For every event in every table , At most one trigger can be defined
- Only support “ Row based triggering ”, in other words , A trigger is for a record , Not for the whole SQL Of the statement , If the changed data set is very large , It's going to be inefficient
- Triggers can mask the work behind the server
- Triggers can mask the work behind the server , A simple SQL There may be a lot of invisible work behind the sentence
- The trigger problem is also very difficult to check , If a performance problem is related to triggers , It's going to be hard to analyze and position
- Triggers can cause deadlocks and lock waits
- Triggers don't guarantee the atomicity of updates
The use of triggers :
Implement some constraints 、 System maintenance tasks , And when we update the anti paradigm data
Record data change log
event : Be similar to Linux Scheduled tasks for , Appoint MySQL Perform a section at some point SQL Code , Or at regular intervals SQL Code
The cursor
- MySQL Provide read-only... On the server side 、 One way cursor , And only in stored procedures or lower level clients API Use in , The objects pointed to are all stored in the temporary table instead of the data actually queried , So it's always read-only
- There will be additional performance overhead
- Client cursors are not supported
Bound variable
When you create a bound variable SQL when , The client sent a... To the server SQL The prototype of the statement . The server receives this SQL After the statement frame , Parse and store this SQL Part of the statement execution plan , Return to the client a SQL Statement handle . Every time this kind of query is executed in the future , The client specifies to use this handle
Can execute a large number of repeated statements more efficiently :
- On the server side, it only needs to be resolved once SQL sentence
- On the server side, some optimization items only need to be performed once , Because it caches part of the execution plan
- Send only parameters and handles in binary mode , Than sending it every time ASC2 Code text is more efficient
- Just parameters —— Instead of the entire query statement —— It needs to be sent to the server , So the network overhead will be smaller
- MySQL When storing parameters , Store it directly in the cache , No more copying in memory
Binding variables is relatively safe . There is no need to deal with escape in the application , One is simpler , Two also greatly reduced SQL The risk of injection and attack
The main purpose is to use... In stored procedures , Build and execute “ dynamic ” Of SQL sentence
Restrictions on bound variables :
Binding variables are session level , So the binding variable handle cannot be shared between connections
stay 5.1 Before the release , Bound variable SQL You can't use query caching
It's not always better to use bound variables
If you always forget to release the bound variable resource , Then it is easy to generate resources on the server side “ leak ”
Some operations , such as BEGIN, Cannot complete in bound variable
User defined functions
- User defined functions (UDF) It has to be compiled in advance and dynamically linked to the server , This platform relevance makes UDF Powerful in many ways , But an error is also likely to crash the server directly , Even disrupt the server's memory or data
plug-in unit
Plugins can be downloaded from MySQL New startup options and status values in , You can also add INFORMATION_SCHEMA surface , Or in MySQL And so on
stay 5.1 Post supported plug-in interfaces :
Stored procedure plug-in
Background plug-ins , You can make the program in MySQL Run in , You can monitor your own network 、 Perform your regular tasks
INFORMATION_SCHEMA plug-in unit , Provide a new memory INFORMATION_SCHEMA surface
Full text parsing plug-in , Provides a way to process text , You can segment a document according to your own needs
Audit plug-ins , Some fixed points are called during query execution , Can record MySQL The event log for
Authentication plug-in , It can be in MySQL The client can also be on its server side , You can use plug-ins like this to extend MySQL The authentication function of
Character sets and proofreading
- Character set is a kind of mapping from binary code to some kind of character symbol , You can refer to how to use a byte to represent English letters .“ proofreading ” A set of collations for a character set
- Each character set can have a variety of proofreading rules , And there is a default proofing rule , Each proofing rule is for a specific character set , It has nothing to do with other character sets
- MySQL There are many options for controlling the character set , It's easy to confuse these options with character sets , Only character based values are really “ Yes ” The concept of character sets
- MySQL Two types of settings : Default settings when creating objects 、 Server and client communication settings
- If the character sets of the two strings being compared are different ,MySQL It will be converted to the same character set and then compared
- Something to pay attention to :
- weird character_set_database Set up , When changing the default database , This variable will change as well , So when you connect to MySQL When the database to be used is not specified on the instance , The default value will be the same as character_set_server identical
- LOAD DATA INFILE, When used , The database always sorts the characters in the file according to the character set character_set_database Parsing
- SELECT INTO OUTFILE,MySQL The result will be written to the file without any transcoding
- Embedded escape sequence ,MySQL Will be based on character_set_client To parse the escape sequence
- Some character sets and proofing rules may require more CPU operation , It may consume more memory and storage space , It will even affect the normal use of the index
- Conversion between different character sets and proofing rules may cause additional overhead
- Only when the character set required by the sort query is the same as that of the server data , To sort with indexes
- In order to be able to adapt to a variety of character sets , Including the client character set 、 The character set explicitly specified in the query ,MySQL Character set conversion will be done when needed
Full-text index
- MyISAM The target of full-text index is “ Full text collection ”, This could be a column in a data table , It could be multiple columns
- According to WHERE In Clause MATCH AGAINST To distinguish whether a query uses a full-text index
- When sorting with full-text index ,MySQL You can no longer use index sorting , If you don't want to use file sorting , Don't use it in queries ORDER BY Clause
- In Boolean search , Users can customize the relevance of a searched word in the query , It's possible to customize the search with some prefix modifiers
- Full text index in INSERT、UPDATE、DELETE The operation cost in is very high
- Full text indexing affects index selection 、WHERE Clause 、ORDER BY etc. :
- If... Is used in the query MATCH AGAINST Clause , And there is a full-text index available on the corresponding column , that MySQL I will definitely use this full-text index
- Full text index can only be used for full-text search matching
- Full text index does not store the actual value of the index column , It can't be used as an index overlay scan
- In addition to correlation ranking , Full text index cannot be used as other sort
- Full text index configuration and optimization :
- Regular use OPTIMIZE TABLE To reduce debris , If it is I/O Intensive regular full-text index reconstruction
- Make sure the index cache is large enough
- Provide a good stop list
- Ignore some words that are too short
- When importing large amounts of data , Better by order DISABLE KEYS To disable full-text indexing , Then use... After importing ENABLE KEYS To build a full-text index
- If the data set is particularly large , You need to manually partition the data , Then distribute the data to different nodes , And do parallel searches
Distributed (XA) Business
- XA There needs to be a transaction coordinator in the transaction to ensure that all transaction participants have completed the preparatory work . If the coordinator receives a message that all participants are ready , It tells you that all transactions are ready to commit ,MySQL In this XA Act as a participant in the transaction process , Not the coordinator
- Because communication delays and participants themselves may fail , So the outside XA Transactions are more expensive than internal consumption
The query cache
MySQL The query cache holds the full results returned by the query , When the query hits the cache ,MySQL The result will be returned immediately , Skipped parsing 、 Optimization and execution phase
MySQL The way to determine cache hits is simple : The cache is placed in a reference table , Reference... By a hash value , This hash value includes the following factors , That is, the query itself 、 The current database to query 、 The version of the client protocol and other information that may affect the returned results
When judging whether the cache is hit ,MySQL No resolution 、“ regularization ” Or parameterized query statements , But directly SQL Statement and other raw information sent by the client . Any difference in character , Such as spaces 、 notes —— Will cause cache misses
When there is some uncertain data in the query statement , Will not be cached , For example, include functions NOW() perhaps CURRENT_DATE() Will not be cached , Just include any user-defined functions 、 Storage function 、 User variables 、 A temporary table 、mysql The system table in the library , Or any table with column level permissions , Will not be cached
Opening query cache will bring extra consumption to both read and write operations :
Read queries must check whether they hit the cache before they start
If this read query can be cached , So when it's done ,MySQL If this query is not found in the query cache , The results will be stored in the query cache , This leads to additional system consumption
When writing data to a table ,MySQL All caches of the corresponding table must be disabled , If the query cache is very large or fragmented , This operation may bring a lot of system consumption
For queries that consume a lot of resources, they are usually very suitable for caching
Cache miss :
- Query statement cannot be cached
- MySQL Never processed this query
- The query cache is out of memory
- Query cache has not finished preheating
- The query statement has never been executed before
- Too many cache invalidation operations
Cache parameter configuration :
- query_cache_type, Whether to open query cache
- query_cache_size, Total memory used by query cache
- query_cache_min_res_unit, The minimum unit of memory allocated in the query cache , Can help reduce memory space waste caused by fragmentation
- query_cache_limit,MySQL The maximum query results that can be cached
- query_cache_wlock_invalidate, If a table is locked by another connection , Whether the results are still returned from the query cache
InnoDB And query caching
- Whether a transaction can access the query cache depends on the current transaction ID, And whether there is a lock on the corresponding data table
- If there are any locks on the table , Then any query statement to this table cannot be cached
General query cache optimization :
- Replacing a large table with multiple small tables is good for query caching
- Only one cache invalidation is needed for batch write , So it is more efficient than single write
- Because the cache space is too large , In the case of expired operations, it may cause the server to freeze , Control the size of the cache space
- Query caching cannot be controlled at the database or table level , But it can go through SQL_CACHE and SQL_NO_CACHE To control something SELECT Whether the statement needs to be cached
- For write intensive applications , Directly disabling query caching may improve system performance
- Because of the competition for mutex semaphores , Sometimes it's good for read intensive applications to turn off the query cache directly
8、 ... and 、 Optimize server settings
MySQL How configuration works
- Any settings that you plan to use for a long time should be written to the global configuration file , Instead of specifying on the command line , The command line specifies that after restarting the service , The configuration will disappear
- Common variables and the effect of dynamically modifying them :
- key_buffer_size, It can be a key buffer at one time (key buffer, Also called key cache key cache) Allocate all specified space
- table_cache_size, It will not take effect immediately —— It will be delayed until the next time a thread opens the table , If the value is greater than the number of tables in the cache , The thread can put the newly opened table into the cache , If it's smaller than the number of tables in the cache , Infrequently used tables will be removed from the cache
- thread_cache_size, It will not take effect immediately —— Will have an effect the next time a connection is closed , Check if there is still space in the cache to cache threads , If there's room , Then cache the thread for the next connection , If there's no space , The thread will be destroyed without caching
- query_cache_size, Allocate and initialize this memory at once
- read_buffer_size, Memory is allocated to the cache only when a query needs to be used
- read_rnd_buffer_size, Memory is allocated to the cache only when a query needs to be used , And will only allocate the required memory size, not all the specified size
- sort_buffer_size, Memory will only be allocated to the cache when there are queries that need to be sorted
- For connection level settings , Don't easily increase their values at the global level , Unless you're sure it's right
- Be careful when setting variables , It's not that the greater the value, the better , And if the value is set too high , It may be easier to cause problems : Server memory swapping may occur due to insufficient memory , Or beyond the address space
- Don't expect to build a benchmark , Then iteratively verify the modification of configuration items to find the best configuration scheme , And spend time checking the backup 、 Monitoring changes in implementation plans and things like that , It might make more sense
What should not be done
- Don't base on some “ ratio ” To tune : For example, the cache hit rate has nothing to do with whether the cache is too large or too small
- Don't use tuning scripts
- Don't believe the popular memory consumption formula
establish MySQL The configuration file
- MySQL The default settings for compilation are not always reliable , Although most of them are suitable
- It's better to start with a security value that's a little bigger than the default value, but not too big ,MySQL Memory utilization is not always predictable : It can depend on a lot of factors , For example, the complexity and concurrency of queries
- The preferred way to configure the server : Understand what's going on inside , And how the parameters interact with each other , Then decide how to configure
- open_files_limit, stay Linux Set as large as possible on the system , If the parameter is not big enough , There will be 24 Wrong number “ Too many open files (too many open files)”
- every other 60 Seconds to see the incremental change of state variables :mysqladmin extended-status ri60
Configure memory usage
To configure MySQL Proper use of memory is critical to high performance , Memory consumption falls into two categories : Controllable memory and uncontrolled memory
Configure memory :
Determine the maximum amount of memory that can be used
Identify each connection MySQL How much memory is needed
Determine how much memory the operating system needs
Give the rest of the memory to MySQL The cache of
MySQL Keep a connection ( Threads ) Only a small amount of memory is needed , It also requires a basic amount of memory to execute any given query , You need to reserve enough memory for a large number of queries to be executed during peak periods , otherwise , Query execution may be inefficient or fail due to lack of memory
Just like a query , The operating system also needs to reserve enough memory for it to work , If no virtual memory is swapping (Paging) To disk , Is the best indication that the operating system has enough memory
If the server only runs MySQL, All memory that doesn't need to be reserved for the operating system and query processing can be used for MySQL cache
Most of the time, the most important cache :
- InnoDB Buffer pool
- InnoDB Log files and MyISAM Operating system caching of data
- MyISAM Key cache
- The query cache
- Cache that cannot be manually configured , For example, operating system caching of binary log and table definition files
InnoDB Buffer pools don't just cache indexes : It also caches row data 、 adaptive hash index 、 Insert buffer (Insert Buffer)、 lock , And other internal data structures , Buffer pools are also used to help delay writes ,InnoDB Heavily dependent on buffer pools
If you know in advance when you need to shut down InnoDB, Can be modified at run time innodb_max_dirty_pages_pct Variable , Reduce the value , Wait to refresh purebred clean buffer pool , Then close when the number of dirty pages is small , Can monitor the Innodb_buffer_pool_pages_dirty State variables or use innotop To monitor SHOW INNODB STATUS To see how much dirty pages refresh
MyISAM Key caching is also called key caching , There is only one key cache by default , But you can also create multiple ,MyISAM It only caches the index itself , Don't cache data , The most important configuration item is key_buffer_size, Don't exceed the total size of the index , Or less than the total memory reserved by the operating system cache 25%-50%, Whichever is smaller
understand MyISAM How much disk space does the index actually take up , Inquire about INFORMATION_SCHEMA Tabular INDEX_LENGTH Field , Add their values , You can get the index storage footprint
Block size is also important ( Especially write intensive loads ), Because it affects MyISAM、 Operating system cache , And the interaction between file systems , If the cache block is too small , You may encounter read on write
The thread cache holds threads that are not currently associated with a connection but are ready to serve a new connection later , When a new connection is created , If there are threads in the cache ,MySQL Remove a thread from the cache , And assign it to this new connection , When the connection is closed , If there's room for thread caching ,MySQL It puts the thread back into the cache , If there's no space ,MySQL Will destroy this thread
thread_cache_size The variable specifies MySQL The number of threads that can be kept in the cache , Generally, you don't need to configure this value , Unless the server has a lot of connection requests
Table cache (Table Cache) Similar to the concept of thread caching , But stored objects represent tables , The cache object contains related tables .frm The parsing result of the file , Plus other data . Table caching can reuse resources , Let the server avoid modification MyISAM File header to mark the table “ In use ”, Yes InnoDB It's much less important
The disadvantage of table caching is , When the server has many MyISAM Table time , May cause a long shutdown time , Because the index block must be refreshed before shutdown , Tables must be marked as no longer open
InnoDB The data dictionary (Data Dictionary),InnoDB Your own table cache , When InnoDB Open a table , Add a corresponding object to the data dictionary
InnoDB There is no persistence of Statistics , It's recalculated every time the table is opened ,5.6 You can open it later innodb_use_sys_stats_table Option to persist statistics to disk
It can be turned off InnoDB Of innodb_stats_on_metadata Option to avoid time-consuming table statistics refresh
If possible , It's better to innodb_open_files The value of is set large enough for the server to keep all .ibd Open the file at the same time
To configure MySQL Of I/O Behavior
- InnoDB I/O To configure
- InnoDB Not only does it allow control over how to recover , It also allows you to control how to open and refresh data ( file ), This has a huge impact on recovery and overall performance
- For common applications , The most important little part is InnoDB Log file size 、InnoDB How to refresh its log buffer , as well as InnoDB How to execute I/O
- The overall log file size is controlled by innodb_log_file_size and innodb_log_files_in_group Two parameters , Very important for write performance
- Usually you don't need to set the log buffer very large , The recommended range is 1MB-8MB, Unless you have to write a lot of pretty big BLOB Record
- It can pass the inspection SHOW INNODB STATUS In the output of LOG Part of it to monitor InnoDB Of the log and the log buffer I/O performance , Through observation Innodb_os_log_written State variables to see InnodDB How much data is written to the log file . The full size of the log file , It should be enough to hold one hour of active content on the server
- If you care more about performance than persistence , You can modify innodb_flush_log_at_trx_commit Variable to control the frequency of log buffer refresh
- Use innodb_flush_method Options can be configured InnoDB How to interact with the file system
- InnoDB Using a table space is not just about storing tables and indexes , The rollback log is also saved 、 Insert buffer (Insert Buffer)、 Double write buffer (Doublerite Buffer) And other internal data structures
- To control the write speed , You can set innodb_max_purge_lag The variable is a value greater than 0 Value , This value represents InnoDB Start delaying the following statements before updating the data , The maximum number of transactions that can wait to be cleared
- The double write buffer is a special reserved area of the table space , It's enough to save... In some continuous blocks 100 A page , Essentially a backup copy of the most recently written page , When InnoDB When a page is flushed from the buffer pool to disk , First, write them down ( Or refresh ) To double write buffer , And then write them to the data area they belong to , This ensures that the writing of each page is atomic and persistent
- Set up innodb_doublewrite by 0 To turn off the double write buffer
- sync_binlog Options control MySQL How to refresh binary log to disk
- Binary log , If you want to use expire_logs_days Option to automatically clean up old binary logs , Don't use rm Order to delete
- MyISAM Of I/O To configure
- MyISAM Usually, after each write operation, the index changes are flushed to the disk , Batch operation will be faster
- By setting delay_key_write Variable , The write of index can be delayed , The modified key buffer is not refreshed until the table is closed
- myisam_recover Options control MyISAM How to find and fix errors
- Memory mapping makes MyISAM Directly through the operating system page cache access .MYD file , Avoid the overhead of system calls ,5.1 You can go through myisam_use_mmap Option to open memory mapping
To configure MySQL Concurrent
InnoDB Concurrent configuration
InnoDB Have their own “ Thread scheduler ” Controls how threads enter the kernel to access data , And what they can do in the kernel at once , The basic way to limit concurrency is to use innodb_thread_concurrency Variable , It limits how many threads can enter the kernel at a time
Concurrent value = CPU Number * Number of disks * 2, It's better to use smaller values in practice
MyISAM Concurrent configuration
Even though MyISAM Is the table level lock , It can still read at the same time , Add new lines at the same time , In this case, you can only read all the data at the beginning of the query , The newly inserted data is not visible , This can avoid inconsistent reading
By setting concurrent_insert This variable , You can configure the MyISAM Open concurrent insert
Give Way INSERT、REPLACE、DELETE、UPDATE The priority of a statement is higher than SELECT The sentence is lower , Set up low_priority_updates The options are right
Workload based configuration
- When the server is running at full load , Please try to record all the query statements , Because this is the best way to see which type of query statement takes up the most resources , Create at the same time processlist snapshot , adopt state perhaps command Fields to aggregate them
- Optimize BLOB and TEXT scene
- BLOB There are several limitations that make the server handle it differently from other types , Can't store in memory temporary table BLOB value , Efficiency is very low
- adopt SUBSTRING() Function to convert the value to VARCHAR
- Make temporary tables faster : On a memory based file system
- If you are using InnoDB, It can also be increased InnoDB Log buffer size
- The big fields are InnoDB It could waste a lot of space
- Extended storage disables adaptive hashing , Because you need to compare the entire length of the column completely , To find out if it's the right data
- Too long a value may make the query as WHERE Condition cannot use index
- If there are many big fields in a table , It's better to combine them and save them in a single column
- Sometimes you can use big fields COMPRESS() Compress and save as BLOB, Or send it to MySQL Before compression in the application
- Optimization of sorting (Filesorts): When MySQL It has to be sorted BLOG or TEXT A field , It only uses prefixes , Then ignore the rest of the values
Complete the basic configuration
- tmp_table_size and max_heap_table_size, These two settings control Memory How much memory can the engine's temporary memory table use
- max_connections, This setting works like an emergency brake , To ensure that the server will not be overwhelmed by the proliferation of applications , The setting is able to accommodate the normal possible load , And be safe enough , It's guaranteed to allow you to log in and manage the server
- thread_cache_size, By observing the activity of the server for a period of time , To calculate a reasonable value ,250 The upper limit of is a good estimate
- table_cache_size, It should be set big enough , To avoid always having to re open and re resolve the definition of the table , Maybe through observation Open_tables And its change over time
Safe and stable settings
- expire_logs_days, If binary logging is enabled , This option should be turned on , You can let the server clean up the old binary log after a specified number of days
- max_allowed_packet, Prevent the server from sending too large a packet , It also controls how large packets can be received
- max_connect_errors, If you know that the server can fully resist brute force attacks , You can set this value very large , To effectively disable the host blacklist
- skip_name_resolve, Another network related and authentication related trap has been disabled :DNS lookup
- sql_mode, Modification is not recommended
- sysdate_is_now, Options that may cause backward incompatibility with the expected application
- read_only, Users without privileges are forbidden to make changes in the standby database , Only accept changes transferred from the main library , Do not accept changes from application , You can set the standby library to read-only mode
- skip_slave_start, prevent MySQL Trying to start replication automatically
- slave_net_timeout, Control the waiting time before the standby database finds that the connection with the primary database has failed and needs to be reconnected , Set to one minute or less
- sync_master_info、sync_relay_log、sync_relay_log_info,5.5 Later versions are available , It solves the long-standing problem of backup database in replication : Don't synchronize their status files to disk , So after the server crashes, people may need to guess where the copy is actually located in the main library , And maybe in the relay log (Relay Log) There's damage in it
senior InnoDB Set up
- innodb, If set to FORCE, Only in InnoDB When you can start , The server will start
- innodb_autoinc_lock_mode, control InnoDB How to generate auto increment primary key value
- innodb_buffer_pool_instances, stay 5.5 in the future , You can split the buffer pool into segments , Lifting on high load multicore machines MySQL An important way of scalability
- innodb_io_capacity, Sometimes it needs to be set quite high , To refresh dirty pages steadily
- innodb_read_io_threads and innodb_write_io_threads, Controls how many background threads can be I/O Operation and use
- innodb_strict_mode, Give Way MySQL In some cases, change the warning to throw the wrong , Especially ineffective or potentially risky CREATE TABLE Options
- innodb_old_blocks_time, Specify a page from LRU Linked list “ young ” Part of it goes to “ aged ” The number of milliseconds that must pass before the part , The default is 0, Set to 1000 millisecond (1 second ) Very effective
Nine 、 Operating system and hardware optimization
What limits MySQL Performance of
- When data can be stored in memory or read from disk fast enough ,CPU There may be bottlenecks , Put a large number of data sets into a large amount of memory , With the current hardware conditions, it is completely feasible
- I/O bottleneck , It usually happens when the data needed for work is far more than the effective memory capacity , If the application is distributed over the network , Or if there are a lot of queries and low latency requirements , Bottlenecks may shift to the network
How to MySQL choice CPU
- It can pass the inspection CPU Use rate to judge whether it is CPU Intensive workloads , We need to see CPU Usage and most important queries I/O Balance between , And pay attention CPU Whether the load is evenly distributed
- When you meet CPU Intensive work ,MySQL It's usually from faster CPU Benefit from , But it also depends on the load and CPU Number
- MySQL Replication can also be done at high speed CPU I'm working very well under the weather , More CPU It doesn't help much to copy
- many CPU In online transaction processing (OLTP) It's very useful in the scenario of the system , In such an environment , Concurrency can be a bottleneck
Balance memory and disk resources
- The ultimate goal of configuring large amounts of memory is to avoid disk I/O, The key is to balance the size of the disk 、 Speed 、 Cost and other factors , In order to provide high performance performance for the workload
- Well designed database cache ( Such as InnoDB Buffer pool ), It's usually more efficient than the operating system's cache , Because the OS cache is designed for common tasks
- The database server uses both sequential and random I/O, Random I/O Benefit most from caching
- Every application has a data “ The working set ”—— That's the data that this job really needs
- The working set includes data and indexes , So we should use cache units to count , A cache unit is the smallest unit of data that the storage engine works on
- Find a good memory / The best way to scale disks is through experimentation and benchmarking
- Hard drive selection considerations : storage capacity 、 transmission speed 、 Access time 、 Spindle speed 、 Physical dimensions
- MySQL How to scale to multiple disks depends on the storage engine and workload ,InnoDB Well scalable to multiple hard drives , However ,MyISAM The table lock limits its write scalability , So the heavy work of writing is added to MyISAM On , You may not be able to benefit from multiple drives
Solid state storage
High quality flash devices have :
It has better random read and write performance than hard disk
Better sequential read and write performance than hard disk
It supports concurrency better than hard disk
Upgrade random I/O And concurrency
The most important feature of flash memory is that it can read many small units quickly , But writing is more challenging . Flash memory can't rewrite a cell without erasing (Cell), And you have to erase one chunk at a time . The erase cycle is slow , And eventually wear out the whole block
Garbage collection is important to understand flash memory . To keep some blocks clean and writable , The device needs to recycle dirty pieces . This requires some free space on the device
Many devices start to slow down when they're full , The speed drop is caused by having to wait for erasure to complete when there are no free blocks
Solid state storage is most suitable for use in any system with a large number of random I/O In the workload scenario , Random I/O It's usually because the data is larger than the server's memory , Flash devices can greatly alleviate this problem
Single threaded workload is another potential application scenario of flash memory
Flash can also be a huge help for server consolidation
Flashcache, The combination of disk and memory technology , Suitable for reading oriented I/O Intensive load , And the working set is too large , Memory optimization is not economical
Optimize... On solid state storage MySQL
- increase InnoDB Of I/O Capacity
- Give Way InnoDB The log file is bigger
- Transfer some files from flash to RAID
- Disable read ahead
- To configure InnoDB Refresh algorithm
- The possibility of disabling double write buffering
- Limit the insert buffer size , The insert buffer is designed to reduce the randomness caused by non unique indexes that are not in memory when updating rows I/O
- InnoDB Page size of
- Optimize InnoDB Page validation (Checksum) An alternative algorithm for
Select hardware for standby Library
- It usually needs the same configuration as the main library
RAID performance optimization
- RAID Can help with redundancy 、 Expand storage capacity 、 cache , And accelerate
- RAID 0: If it's just a simple assessment of cost and performance , It's the lowest cost and highest performance RAID To configure
- RAID 1: Provides good read performance in many cases , And redundant data between different disks , So there's good redundancy , It's very suitable for keeping logs or similar work
- RAID 5: Distribute data to multiple disks through distributed parity , If the data of any disk fails , Can be reconstructed from parity blocks , But if two disks fail , The data of the whole volume cannot be recovered , The most economical redundant configuration . Random writing is expensive , Storing data or logs is an acceptable option , Or reading based business
- RAID 10: It's a great choice for data storage , It's made up of segmented images , Good scalability for both reading and writing
- RAID 50: By banding RAID 5 form
SAN and NAS
- SAN(Storage Area Network) and NAS(Network-Attached Storage) It's a way to load two external file storage devices into the server , visit SAN Device through the block interface ,NAS Devices access through file based protocols
- SAN Allows the server to access a very large number of hard drives , And it is usually configured with large capacity intelligent cache to buffer writes
- Which jobs are put in SAN It's not right : Do a lot of random I/O Single threaded task of
- SAN Application :
- Backup , You can just back up SAN
- Simplify capacity planning
- Storage consolidation or server consolidation
- High availability
- Interaction between servers
- cost
Using multiple disk volumes
- The real advantage of binary log and data file separation , It is to reduce the possibility of losing both data and log files in an accident
- If there are many disks , Investing some in transaction logging might benefit
The network configuration
- Enable... On the production server skip_name_resolve It's a good idea , Damaged or slow DNS Parsing is a problem for many applications , Yes MySQL Especially serious , If enabled skip_name_resolve Options ,MySQL Will not do anything DNS Looking for jobs
- Can pass MySQL Of back_log Options control MySQL The introduction of TCP The size of the connection queue , In an environment where many connections are created and destroyed every second , The default value is 50 It's not enough.
- Network physical isolation is also an important factor , It's wise to avoid real-time cross data center operations as much as possible
Choose the operating system
- General enterprise level deployment MySQL Mostly in class UNIX On the operating system
Choose File System
- If possible , It's best to use the log file system , Such as ext3、ext4、XFS、ZFS perhaps JFS
- You can adjust the read ahead behavior of the file system , Because it may also be superfluous
Select the disk queue scheduling policy
- stay GUN/Linux On , Queue scheduling determines the order in which requests to block devices are actually sent to underlying devices , By default cfq(Completely Fair Queueing, Completely fair line up ) Strategy , stay MySQL The workload type of ,cfq It can lead to poor response time , Because it will delay some unnecessary requests in the queue
- cfq The other two options are suitable for server level hardware ,noop Scheduling is suitable for devices without their own scheduling algorithm ,deadline On the other hand RAID The controller and the direct disk are working well
Threads
- MySQL Use one thread per connection , There are also internal processing threads 、 Special purpose threads , And all the threads created by the storage engine
- MySQL It really needs kernel level thread support , Not just user level threads , In this way, you can use multiple users more effectively CPU, In addition, we also need effective synchronous atoms
Memory swap
- Memory swap pairs MySQL The performance impact is terrible , It destroys the purpose of caching in memory , And compared to using a small amount of memory for caching , The performance of using switch area is worse
- stay GNU/Linux On , It can be used vmstat To monitor memory swapping , It's better to check si and so Column reports memory swapping I/O Activities , It's better than watching swpd Column reported swap utilization is more important , The best is 0
- Set up /proc/sys/vm/swappiness For a very small value
- Modify how the storage engine reads and writes data , Use innodb_flush_method=0_DIRECT reduce I/O pressure
- Use MySQL Of memlock Configuration item , You can put MySQL Locked in memory
Operating system status
vmstat
- vmstat 5, every other 5 Refresh every second
- procs,r Column shows how many processes are waiting CPU,b Column shows how many processes are sleeping without interruption
- memory,swpd Column shows how many blocks have been swapped out to disk , The remaining three columns show how many blocks are free 、 How many blocks are being used as buffers , And how much is being used as a cache for the operating system
- swap, Show page exchange activity
- io, Shows how many blocks are read from the block device ( bi) And write (bo)
- system, Shows interrupts per second (in) And context switch (cs) The number of
- cpu, Show all CPU Percentage of time spent on various operations
iostat
iostats -dx 5, Every time 5 seconds
rrqm/s and wrqm/s, Combined read and write requests per second , It means that the operating system takes out multiple logical requests from the queue and merges them into one request to the actual disk
r/s and w/s, Read and write requests sent to the device per second
rsec/s and wsec/s, The number of sectors read and written per second
avgrq-sz, Number of sectors requested
avgqu-sz, The number of requests waiting in the device queue
await, Number of milliseconds spent on disk exclusion
svctm, The number of milliseconds the service request took , Excluding exclusion time
%util, Percentage of time spent with at least one active request
CPU Dense machines ,vmstat The output is usually in us Column will have a very high value , Or maybe sy Column has a high value
I/O Under intensive workload ,vmstat It shows that many processors are sleeping without interruption (b Column ) state , also wa The value of this column is very high
The memory swapping machine may be in swpd Column has a very high value
Ten 、 Copy
Copy Overview
MySQL Two ways of replication are supported : Line based replication and statement based replication , It's all through recording binary logs in the main library 、 Replay logs in the standby database to achieve asynchronous data replication
Replication usually does not increase the cost of the main library , This is mainly the overhead of enabling binary logging , But for backup or timely recovery from a crash , This cost is also necessary
Through replication, the read operation can be directed to the standby library to obtain better read expansion , But for write operations , Unless it's designed right , Otherwise, it is not suitable to extend write operations by write replication
Copy the problem solved :
The data distribution
Load balancing
Backup
High availability and failover
MySQL Upgrade test
How replication works
Record the data update to the binary log on the main database (Binary Log) in
The standby database copies the logs on the primary database to its own relay logs (Relay Log) in
The standby database reads the events in the relay log , Put it back on the standby database data
Configure replication
- Create a replication account on each server
- The account used to monitor and manage replication needs REPLICATION CLIENT jurisdiction , And it's easier to use the same account for both purposes
- If you set up an account in the main library , Then clone the data from the master database to the slave database , The standby database is set up —— The configuration needed to become the main library
- Configure the main database and the standby database
- You must explicitly specify a unique server ID
- Sometimes only binary logs are turned on , But it didn't turn on log_slave_updates, There may be some strange phenomena
- If possible , Best use read_only configuration option , Will prevent any thread without privileges from modifying data
- Notify the standby database to connect to the primary database and copy data from the primary database
- Recommended replication configuration
- sync_binlog =1, The binary log is synchronized to disk before the transaction is committed , Ensure that no events are lost in the event of a server crash
- If you can't tolerate server crash causing table corruption , Recommended InnoDB
- It is recommended to specify the name of the binary log ,log_bin=/var/lib/mysql/mysql-bin
- Specify the absolute path for the relay log on the standby database ,relay_log
- If in use 5.5 And don't mind the extra fsync() The resulting performance overhead , The best setting is :sync_master_info,sync_relay_log,sync_relay_log_info
The principle of replication
Statement based replication
- 5.0 Previously, only statement based replication was supported ( Also called logical replication ), The main library records queries that cause data changes , When the standby reads and replays these events , In fact, it's just the execution of SQL Execute it again
- The advantage is that the implementation is quite simple , The logs are more compact , It won't take up too much bandwidth
- The problem is that the statement based approach may not be as convenient as it seems , There are still some that can't be copied properly SQL, The update must be serial, which requires more locks
Line based replication
5.1 Start supporting , The actual data is recorded in the binary log , Compare with the implementation of other databases
The advantage is that you can copy every line correctly , Some statements can be copied more efficiently
If you use full table update , It's going to cost a lot , Because every row of data will be recorded in the binary log , This makes binary log events very large , And it will add extra load to logging and replication on the main library , Slower logging reduces concurrency
Based on lines or statements : Which is better
- The advantages of statement based replication : When the active and standby modes are different , Logical replication can work in a variety of situations ; The process of executing replication based on statements is basically execution SQL sentence
- Disadvantages of statement based replication mode : In many cases, it is impossible to copy correctly through the statement based mode , If you are using triggers or stored procedures , Don't use statement based replication mode , Unless it's clear that you won't encounter replication
- The advantages of row based replication : There are few scenarios that line based replication cannot handle ; May reduce the use of locks , This strong serialization is not required to be repeatable ; Records data changes ; Take up less CPU; It can help to find and solve the problem of data failure faster
- Disadvantages of the row based replication model : It's impossible to judge what has been executed SQL; There's no way to know what the server is doing ; In some cases , For example, when the row to be modified cannot be found , Row based replication can cause replication to stop
Copy file
mysql-bin.index, Binary log file
mysql-relay-bin-index, Index file of relay log
master.info, Save the information needed for the secondary library to connect to the primary library
relay-log.info, Contains the binary log and relay log coordinates of the current backup database replication
5. Send replication events to other backup libraries :log_slave_updates, You can make the standby database the main database of other servers
6. Copy filtering options
- Filtering events recorded in the binary log on the main library
- Filter the events recorded to the relay log on the standby database
Replication topology
The basic principle of :
One MySQL A standby database instance can only have one primary database
Each standby database must have a unique server ID
A primary library can have multiple secondary libraries
If it's on log_slave_updates Options , A standby database can propagate data changes on its primary database to other standby databases
One master database, multiple standby databases
Take the initiative - Primary replication in active mode :auto_increment_increment and auto_increment_offset It can make MySQL Automatically for INSERT Statement selection does not conflict with each other
Take the initiative - Active replication in passive mode : One of the servers is a read-only passive server
It has the main structure of the standby library : Added redundancy , It can eliminate the problem of site single point failure
Circular replication : Each server is the backup database of the server before it , It's the main database of the server after it
The distribution master library is actually a backup library , Extract and provide the binary log of the main library
Trees or pyramids : Reduce the burden of the main library , But any error in the middle tier will affect multiple servers
Customized replication solutions
Selective replication : To configure replicate_wild_do_table
Separation function :OLTP、OLAP
Data archiving : Keep the deleted data on the primary database on the standby database
Use the standby library as a full-text search
Read only backup :read_only Options
Simulate multi master replication
Create a log server : Create a log server without data , It's easier to replay and / Or filter binary log events
Replication and capacity planning
- Writing is usually the bottleneck of replication , And it's hard to extend write operations with replication
- When building a large application , Intentionally make the server underutilized , It should be a smart and pervasive way , Especially when using replication , Servers with extra capacity can handle load spikes better , There is also more ability to handle slow queries and maintenance work , And can better keep up with replication
Replication management and maintenance
- On the main warehouse , have access to SHOW MASTER STATUS Command to view the binary log location and configuration of the current main library
- From the library , Use SHOW SLAVE STATUS
11、 ... and 、 Extended MySQL
What is scalability
- Scalability shows that when more resources are needed to perform more work, the system can get a cost-effective equivalent improvement (equal bang for the buck) The ability of , After the turning point of diminishing returns, the system that lacks the ability to expand , There will be no further growth
- Scalability is the ability to increase capacity by increasing resources
Expand MySQL
- The most difficult part of planning for scalability is to estimate how much load to take , You also need to estimate the schedule roughly and correctly , Need to know where the bottom line is
- The preparatory work that can be done : Optimize performance 、 Buy more powerful hardware
- Expand up ( Vertical expansion ) It means buying more powerful hardware
- To expand outward ( Horizontal scaling 、 Horizontal expansion ): Copy 、 Split 、 Data fragmentation
- Split by function ( Split up according to duty ), Different nodes perform different tasks
- Data fragmentation , Split the data into small pieces , Or a small piece , Then it's stored in different nodes
- Select the partition key (partitioning key)
- Multiple partition keys
- Cross slice query , Use C or Java Write an auxiliary application to execute the query and aggregate the result set , You can also use the summary table to perform
- Assign data 、 Shards and nodes
- Extend... With multiple instances
- Expand... Through clustering
- MySQL Cluster(NDB Cluster)
- Clustrix
- ScaleBase
- GenieDB
- Akiban
- To expand inward , Archive and clean up data that is no longer needed
- Keep active data independent
Load balancing
- Average the load as much as possible in a server cluster , Usually, a load balancer is set at the front end of the server
Twelve 、 High availability
What is high availability
- High availability is not absolute , Only relatively higher availability ,100% The availability of is not possible
- Every little increase in usability , The cost will be much higher than before , The ratio of the effect of availability to the cost is not linear
Causes of downtime
- Operational environmental issues , The most common problem is running out of disk space
- Performance issues , The most common reason is that it works badly SQL, Or servers BUG Or wrong behavior
- Perishing Schema And index design
- Replication problems are usually caused by inconsistent primary and secondary data
- Data loss is usually due to DROP TABLE The misoperation of leads to , And it's always accompanied by a lack of available backup
How to achieve high availability
- You can achieve high availability by doing the following two steps at the same time
- Try to reduce downtime by avoiding the causes of downtime
- Try to make sure that you can recover quickly in case of downtime
- Increase the mean time to failure (MTBF)
- The lack of system change management is the most common cause of all downtime events
- Lack of rigorous assessment
- Not properly monitored MySQL Information about
- Reduce the average recovery time (MTTR)
- All downtime is caused by a combination of failures , It can be avoided by using appropriate methods to ensure the safety of a single point
Avoid single point failure
- Any non redundant part of the system is a single point of failure
- There are two ways to add redundancy to the system : Increase spare capacity and duplicate components
- Shared storage or disk replication
- Ability to decouple database server and storage , It's usually used SAN
- Two advantages : It can avoid the data loss caused by the failure of any other components except storage , It is possible to build redundancy for non storage components
- MySQL Synchronous replication
- When using synchronous replication , Only when a transaction on the primary database is committed on at least one of the standby databases can it be considered as completed
- Two goals have been achieved : When the server crashes, uncommitted transactions are lost , And at least one standby database has a real-time copy of the data
- MySQL Cluster
- Percona XtraDB Cluster
- Replication based redundancy
- Replication manager is using standard MySQL Copy to create redundant tools
Fail over and recovery
- Redundancy doesn't increase availability or reduce downtime at all , Combined with fail over, it can help recover faster , The most important part of failover is failback
- Upgrade the standby database or switch roles
- fictitious IP Address or IP To take over
- Middleware solutions , You can use agents 、 Port forwarding 、 Network address translation or hardware load balancing to achieve fail over and recovery
- Dealing with failover in applications
13、 ... and 、 In the clouds MySQL
The advantages of the cloud 、 Shortcomings and related misunderstandings
advantage :
The cloud is a way to outsource infrastructure without having to manage it yourself
The cloud is generally paid on a pay as you go basis
As suppliers launch new services and lower costs , The value of the cloud is growing
The cloud can help you easily prepare servers and other resources
The cloud represents another way of thinking about infrastructure —— As by API To define and control resources —— Support more automation
2. shortcoming :
Resources are shared and unpredictable
There is no guarantee of capacity and availability
Virtual shared resources make troubleshooting more difficult
MySQL Economic value in the cloud
- Cloud hosting is more suitable for enterprises in the initial stage , Or companies that are constantly exposed to new concepts and are essentially application-oriented
- The strategy of mass use is to develop and distribute applications as quickly and cheaply as possible
- Running infrastructure that's not very important
In the clouds MySQL Scalability and high availability of
- Database is usually the main or only stateful and persistent component in an application system
- MySQL It does not have the ability to migrate between peer role servers in a shared cluster
Four basic resources
- CPU Usually less. Wait a minute
- Internal size is limited
- I/O Throughput 、 Latency and consistency are limited
- The network performance is quite good
MySQL Performance on the virtual machine
- A workload that requires high concurrency is not very suitable for Cloud Computing
- Those need a lot of I/O Your workload doesn't always perform well in the cloud
MySQL Database as a service (DBaaS)
- Use the database itself as a cloud resource
fourteen 、 Application layer optimization
- common problem
- What's consuming every host in the system CPU、 disk 、 The Internet , And memory resources ? Whether these values are reasonable ? If it's not reasonable , Do a basic inspection of the application , See what's taking up resources
- Do applications really need all the data they get ?
- Are applications dealing with things that should be handled by the database , Or vice versa ?
- Too many queries are executed by the application ?
- Too few queries are executed by the application ?
- Applications create unnecessary MySQL Is it connected ?
- Apply to a MySQL Too many instances create connections ?
- Applications do too much “ The garbage ” Inquire about ?
- Does the app use connection pooling ? It could be a good thing , It could be a bad thing
- Whether the application uses long connections ?
- Whether the application remains connected and torn when not in use ?
Web Server problem
The most common problem is to keep its process alive (alive) drawn-out , Or it can be mixed for various purposes , Instead of optimizing different types of work separately
If you use a general purpose Apache Configuration is directly used for Web service , Finally, it is likely to produce many heavyweight Apache process
Do not use Apache To do static content services , Or at least different from dynamic services Apache example
Strategy of shortening process lifetime :
Don't let Apache Spoon feed service client
open gzip Compress
Do not use for long distance connections Apache Configure enable Keep-Alive Options
cache
Passive caching does nothing but store and return data ; Active caching does some extra work when access misses
The application can cache some calculation results , So the application level cache may be more effective than the lower level cache , It can save two aspects of work : Obtain data and calculate based on these data , The point is that the cache hit rate may be lower , And may use more memory
Application layer cache :
Local cache
Local shared memory cache
Distributed memory cache
Cache on disk
Cache control strategy
TTL(time to live, Survival time )
Explicit failure , If dirty data cannot be accepted , Then the process needs to invalidate the cache when updating the original data
Read time failure , When changing old data , In order to avoid invalidating the derived dirty data at the same time , You can save some information in the cache , When reading data from the cache, you can use this information to determine whether the data has expired
You can request some pages in advance in the background , And save the result as a static page , benefits :
The application code has no complex hit and miss processing paths
When the processing path of miss is unacceptably slow , This scheme can work well
Pre generated content can avoid the avalanche effect caused by cache misses
MySQL substitute
- Search for :Lucene and Sphinx
- Simple key value storage :Redis
- Unstructured data :Hadoop
15、 ... and 、 Backup and recovery
Why backup
- disaster recovery
- People change their minds
- Audit
- test
Define recovery requirements
- When planning backup and recovery strategies , There are two important requirements : Recovery point objectives (PRO) And recovery time objectives (RTO)
Design MySQL Backup plan
Suggest
In production practice , For large databases , Physical backup is required : Logical backup is too slow and limited by resources , Recovering from a logical backup takes a long time
Keep multiple backup sets
From logical backup on a regular basis ( Or physical backup ) Extract data from the database for recovery test
Save binary logs for recovery based on the point in time of failure
The backup tool itself is completely not used to monitor the backup and the backup process
Test backup and recovery by rehearsing the entire recovery process
Think carefully about safety
If possible , close MySQL Backup is the simplest and safest , You need to consider : Lock time 、 Backup time 、 Backup load 、 recovery time
Advantages of logical backup :
You can use an editor or something like grep and sed Such commands to view and operate ordinary files
Recovery is very simple
It is possible to backup and restore through the network
Can be in similar Amazon RDS This is used in systems that cannot access the underlying file system
Very flexible
It's not about the storage engine
Helps avoid data corruption
Disadvantages of logical backup :
The database server must complete the work of generating logical backup
Logical backup is larger than the database file itself in some scenarios
There is no guarantee that the same data will be restored after Export
Restoring from a logical backup requires MySQL Load and interpret statements
Advantages of physical backup :
File based backup , Just copy the required files to other places
It's easy to recover
InnoDB and MyISAM Physical backup of is very easy to cross platform
Disadvantages of physical backup :
InnoDB The original file of is usually much larger than the corresponding logical backup
Physical backup is not always cross platform
Unless tested , Don't assume that backups are normal
It is recommended to mix physical and logical methods for backup
MySQL Several points to consider for backup :
- Non significant data
- Code
- Replication configuration
- Server configuration
- Selected operating system
Differential backup is to back up all the changed parts since the last full backup , Incremental backup is the backup of all modifications made since the last backup of any type
differences 、 Suggestions for incremental backup :
- Use Percona XtraBackup and MySQL Enterprise Backup Incremental backup feature in
- Back up binary logs , After every backup FLUSH LOGS
- Do not back up tables that have not changed
- Do not back up unchanged rows
- Some data does not need to be backed up at all
- Back up all the data , Then send it to a destination with de duplication feature
Data consistency : When backing up , You should consider whether you need data to be consistent at a specified point in time
File consistency : Internal consistency of each file
The biggest advantage of backing up from the standby database is that it does not interfere with the primary database , Deliberately delaying a standby database for a period of time is very useful for some disaster scenarios
Manage and back up binary logs
- expire_log_days Variable MySQL Clean up logs regularly
The backup data
Generate logical backup
SQL export :mysqldump The way
Symbol delimited file backup : Use SELECT INTO OUTFILE Create a logical backup of data in a symbol delimited file format
File system snapshot
- File systems and devices that support snapshots include FreeBSD File system 、ZFS file system 、GNU/Linux Logical volume management (LVM), And many SAN System and file storage solutions
restore from backup
Recovery steps :
stop it MySQL The server
Record server configuration and file permissions
Move data from backup to MySQL Data directory
Change configuration
Change file permissions
Restart the server in restricted access mode , Wait for the startup to complete
Load the logical backup file
Check and replay binary logs
Detect the restored data
Restart the server with full privileges
Backup and recovery tools
- MySQL Enterprise Backup
- Percona XtraBackup
- mylvmbackup
- Zmanda Recovery Manager
- mydunper
- mysqldump
sixteen 、MySQL User tools
Interface tools
- MySQL Workbench
- SQLyog
- phpMyAdmin
- Adminer
Command line toolset
- Percona Toolkit
- Maatkit and Aspersa
- The openark kit
- MySql workbench
SQL Practical collection
- common_schema
- mysql-sr-lib
- MySQL UDF Warehouse
- MySQL Forge
Monitoring tools
Open source monitoring tools
Nagios
Zabbix
Zenoss
OpenNMS
Groundwork Open Source
MRTG
Cacti
Ganglia
Munin
Commercial monitoring system
MySQL Enterprise Monitor
MONyog
New Relic
Circonus
Monitis
Splunk
Pingdom
Innotop Command line monitoring
边栏推荐
- [unsolved] 7-15 shout mountain
- Fdog series (III): use Tencent cloud SMS interface to send SMS, write database, deploy to server, web finale.
- DS18B20数字温度计系统设计
- Shell_ 04_ Shell script
- Error occurred during initialization of VM Could not reserve enough space for object heap
- LeetCode 1020. Number of enclaves
- Tencent interview algorithm question
- GCC error: terminate called after throwing an instance of 'std:: regex_ error‘ what(): regex
- LeetCode 1562. Find the latest group of size M
- ~70 row high
猜你喜欢
汇编课后作业

Full record of ByteDance technology newcomer training: a guide to the new growth of school recruitment

~68 Icon Font introduction
Fdog series (III): use Tencent cloud SMS interface to send SMS, write database, deploy to server, web finale.
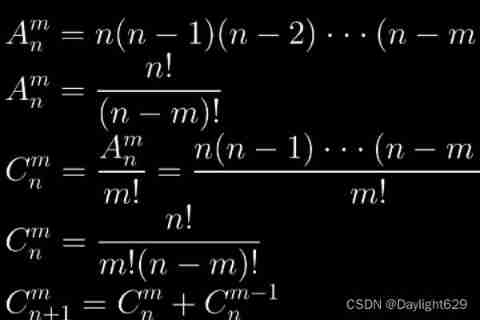
LeetCode 1641. Count the number of Lexicographic vowel strings
7-10 punch in strategy
算数运算指令

亮相Google I/O,字节跳动是这样应用Flutter的
Soft music -js find the number of times that character appears in the string - Feng Hao's blog

谢邀,人在工区,刚交代码,在下字节跳动实习生
随机推荐
~71 abbreviation attribute of font
Record the error reason: terminate called after throwing an instance
I'm "fixing movies" in ByteDance
Saw local status change event StatusChangeEvent [timestamp=1644048792587, current=DOWN, previous=UP]
Monomer application concept
Solr new core
字节跳动技术面试官现身说法:我最想pick什么样的候选人
7-5 blessing arrived
7-10 punch in strategy
Design of DS18B20 digital thermometer system
was unable to send heartbeat
LeetCode 1558. Get the minimum number of function calls of the target array
LeetCode 1566. Repeat the pattern with length m at least k times
「博士毕业一年,我拿下 ACL Best Paper」
LeetCode 1984. Minimum difference in student scores
TypeScript基本操作
搭建flutter环境入坑集合
LeetCode 1640. Can I connect to form an array
8086 分段技术
Data config problem: the reference to entity 'useunicode' must end with ';' delimiter.